

前回(前編)、ドラッグストアの150店舗データに全変数を投入した重回帰分析を行い、「有意でない変数が混在している」「偏回帰係数をそのまま比較できない」「新しいデータへの予測力が未検証」という3つの問題点を特定しました。
今回(後編)では、Lasso回帰による変数選択、標準化偏回帰係数による影響度比較、交差検証によるモデルの安定性評価を経て、新規出店候補地の売上予測まで一気に駆け抜けます。
Contents
- 前回のおさらいと準備
- Lasso回帰 ── 「効かない変数」を自動で削ぎ落とす
- Lasso回帰の考え方
- LassoCVで最適なαを自動決定する
- どの変数が選ばれ、どの変数が除外されたか
- Lasso係数を棒グラフで可視化する
- 選択された変数で最終モデルを構築する
- Lassoで選ばれた変数だけで重回帰分析
- 採用された変数と、除外された変数の「入れ替え」について
- 最終モデルの詳細を確認する
- 標準化偏回帰係数
- 影響度の「公平な比較」
- 係数の大小=「打ち手の優先度」ではない
- モデルの予測精度を評価する
- 主な評価指標
- 訓練データとテストデータに分割して評価
- 予測値 vs 実測値の散布図
- 交差検証(クロスバリデーション)
- なぜ交差検証が必要なのか
- 新規出店候補地の売上予測
- 分析結果を「意思決定」に結びつける
- まとめ
前回のおさらいと準備
後編に入る前に、前回(前編)で作成したデータと前処理を再現しておきましょう。
前回と同じ手順で、ライブラリのインポート → 架空データ生成 → 全変数モデルの構築までを一括で実行します。
以下、コードです。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib
import statsmodels.api as sm
from sklearn.preprocessing import StandardScaler
from statsmodels.stats.outliers_influence import variance_inflation_factor
# 読み込むCSVファイル名
csv_path = 'drugstore_data.csv'
# データの読み込み(CSVからDataFrameを作成)
df = pd.read_csv(csv_path)
# 説明変数Xと目的変数yを設定
X = df.drop(['monthly_sales','store_id'], axis=1)
y = df['monthly_sales']
# statsmodelsで回帰分析(定数項を追加して実行)
X_const = sm.add_constant(X)
model_full = sm.OLS(y, X_const).fit()
print("【全変数モデルの結果(抜粋)】")
print(f"R²: {model_full.rsquared:.4f}")
print(f"自由度調整済みR²: {model_full.rsquared_adj:.4f}")
print(
f"F統計量: {model_full.fvalue:.2f} "
f"(p値: {model_full.f_pvalue:.2e})"
)
以下、実行結果です。
【全変数モデルの結果(抜粋)】 R²: 0.9724 自由度調整済みR²: 0.9704 F統計量: 490.19 (p値: 4.14e-103)
今回(後編)で使うライブラリで、足りないものを追加で読み込みます。
以下、コードです。
from sklearn.linear_model import (
LinearRegression,
LassoCV
)
from sklearn.model_selection import (
train_test_split,
cross_val_score
)
from sklearn.metrics import (
mean_squared_error,
mean_absolute_error,
r2_score
)
ここから後編の本題に入ります。
Lasso回帰 ── 「効かない変数」を自動で削ぎ落とす
Lasso回帰の考え方
前回の全変数モデルでは、p値が大きい(統計的に有意でない)変数がいくつか見つかりました。
ここで、Lasso回帰を使って、本当に重要な変数を自動的に選び出します。
Lasso回帰の最大の特徴は、重要でない変数の係数を正確にゼロにするスパース化の性質です。
通常の重回帰分析では係数がゼロになることはありませんが、Lassoはペナルティ項を加えることで、不要な変数を自動的にモデルから除外します。
数式で確認しましょう。Lasso回帰は次の目的関数を最小化します。
$$
L(\boldsymbol{\beta}) = \sum_{i=1}^{n}(y_i – \hat{y}_i)^2 + \alpha \sum_{j=1}^{p}|\beta_j|
$$
第1項は通常の残差二乗和で、第2項がL1正則化項(ペナルティ)です。
\alpha(アルファ)は正則化の強さを制御するパラメータで、\alpha が大きいほど多くの係数がゼロになります。\alpha = 0 のときは通常の重回帰分析と一致します。重要なのは、Lasso回帰を適用する前にデータを標準化しておくことです。
変数のスケールが異なると、ペナルティの効き方が不公平になってしまいます。
たとえば人口密度(数千〜数万の値)と競合店数(0〜10程度の値)では、スケールの大きい人口密度の係数が先にゼロに押されやすくなるのです。
LassoCVで最適なαを自動決定する
データを標準化し、交差検証(クロスバリデーション)付きのLasso回帰(LassoCV)で最適な \alpha を自動決定します。
交差検証(クロスバリデーション)とは、データを複数のグループに分けて「一部で学習、残りで評価」を繰り返す手法で、過学習を防ぎながらモデルの汎化性能を評価できます。
以下、コードです。
# データの標準化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# LassoCVで最適なαを自動決定(5分割交差検証)
lasso_cv = LassoCV(
cv=5, # 交差検証の分割数
random_state=42, # 乱数シードを固定
max_iter=10000 # 収束するまでの最大反復回数
)
lasso_cv.fit(X_scaled, y)
print("【LassoCV の結果】")
print(f"最適なα: {lasso_cv.alpha_:.4f}")
print(f"R²スコア: {lasso_cv.score(X_scaled, y):.4f}")
以下、実行結果です。
【LassoCV の結果】 最適なα: 14.9141 R²スコア: 0.9720
LassoCVは交差検証を使って最適な \alpha を自動的に選んでくれます。
どの変数が選ばれ、どの変数が除外されたか
Lasso回帰で得られた係数を確認し、どの変数が選択(残存)され、どの変数がゼロになったかを一覧で表示します。
以下、コードです。
# Lassoで得られた係数をデータフレームにまとめる
lasso_coefs = pd.DataFrame({
'variable': X.columns,
'Lasso係数(標準化)': lasso_cv.coef_
})
# 係数が0かどうかで、特徴量が選択されたかを判定
lasso_coefs['selected'] = lasso_coefs['Lasso係数(標準化)'] != 0
# 係数の絶対値が大きい順に並べ替え(影響度の大きい順)
lasso_coefs = lasso_coefs.sort_values(
'Lasso係数(標準化)',
key=lambda s: s.abs(),
ascending=False
).reset_index(drop=True)
# 結果の表示
print("【Lasso回帰の係数(標準化データ)】")
for _, row in lasso_coefs.iterrows():
status = "✓ 選択" if row['selected'] else "✗ 除外"
# ブール値は明示的に文字列化するか、ステータスのみ表示
print(
f" selected={str(row['selected']):5s}: "
f"{row['Lasso係数(標準化)']:>8.2f} "
f"{status:>4s} "
f"{row['variable']}"
)
# 選択された特徴量の数をカウントして表示
n_selected = int(lasso_coefs['selected'].sum())
print(f"\n選択された変数: {n_selected}個 / {len(X.columns)}個")
# ついでに選択された特徴量の一覧も出力
selected_features = lasso_coefs.loc[
lasso_coefs['selected'],
'variable'
].tolist()
print("選択された特徴量:", selected_features)
以下、実行結果です。
【Lasso回帰の係数(標準化データ)】 selected=True : 1258.94 ✓ 選択 pop_density selected=True : 581.98 ✓ 選択 staff_count selected=True : 415.49 ✓ 選択 sales_area selected=True : 266.59 ✓ 選択 household_income selected=True : -221.93 ✓ 選択 competitor_count selected=True : 100.23 ✓ 選択 parking_slots selected=False: 0.00 ✗ 除外 station_passengers selected=False: 0.00 ✗ 除外 business_hours selected=False: 0.00 ✗ 除外 building_age selected=False: 0.00 ✗ 除外 signboard_size 選択された変数: 6個 / 10個 選択された特徴量: ['pop_density', 'staff_count', 'sales_area', 'household_income', 'competitor_count', 'parking_slots']
Lasso回帰の係数がゼロになった変数は、他の変数の兼ね合いから売上への影響が小さいと判断されモデルから自動的に除外されたものです。
注意が必要なのは、除外されたからといっても、売上への影響が小さいとは限らない、ということです。
たとえば、相関の強い2つの変数から1つの変数が除外された場合、除外された変数が売上への影響が小さいから除外されたのではなく、相関の強い他の変数が採用された(除外されていない)ために除外されたのです。
係数の絶対値が大きい変数ほど、売上への影響が大きいことを示しています。
標準化データで計算しているので、変数間のスケールの違いに影響されず、純粋に影響度を比較できます。
Lasso係数を棒グラフで可視化する
Lasso回帰の係数を棒グラフで可視化します。
青色は売上にプラスの影響、赤色はマイナスの影響、灰色(係数がゼロ)は「不要」と判断された変数を示します。
以下、コードです。
# グラフのサイズなどの設定
fig, ax = plt.subplots(figsize=(10, 6))
# 係数の符号で色分け(正:青 / 負:赤 / 0:グレー)
colors = [
'#2E86AB' if c > 0
else '#E94F37' if c < 0
else '#CCCCCC'
for c in lasso_coefs['Lasso係数(標準化)']
]
# 水平バーの描画
ax.barh(
range(len(lasso_coefs)),
lasso_coefs['Lasso係数(標準化)'].values,
color=colors
)
# 0基準線とグリッド
ax.axvline(x=0, color='black', linewidth=0.5)
ax.set_yticks(range(len(lasso_coefs)))
ax.set_yticklabels(lasso_coefs['variable'].values, fontsize=11)
ax.set_xlabel('標準化Lasso係数', fontsize=12)
ax.set_title('Lasso回帰による変数重要度', fontsize=14)
ax.grid(True, alpha=0.3, axis='x')
ax.invert_yaxis() # 縦軸を反転
plt.tight_layout()
plt.show()
以下、実行結果です。
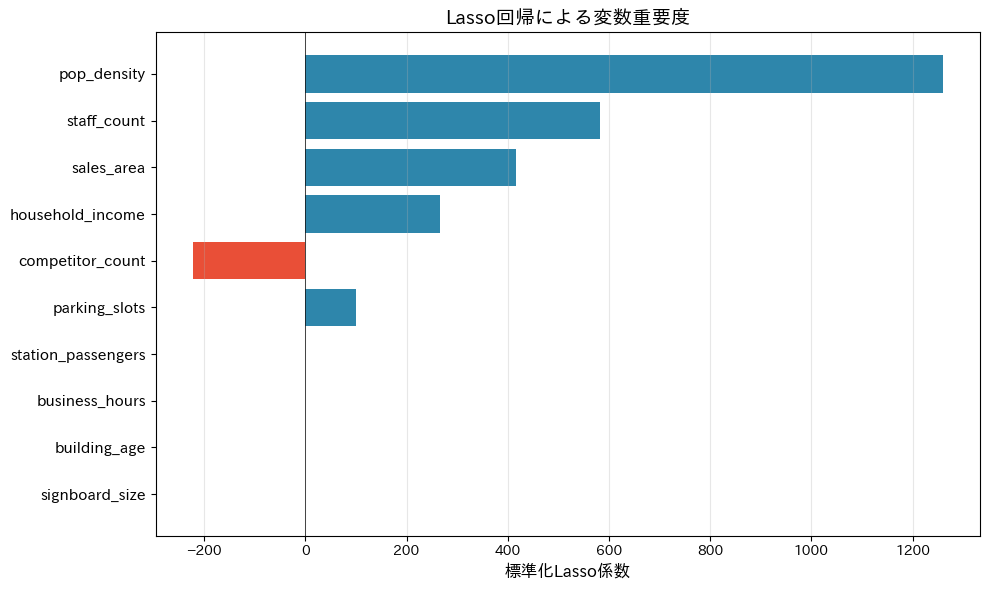
このグラフを見れば、「売上に効く要因」と「効かない要因」が一目で伝わります。
係数0は「このモデル設定(正則化の強さ)では、その変数を入れても予測精度の改善が小さいので、入れない方が良い」という判断です。
言い換えると、係数0は次のどれか(または複合)を表します。特に実務では2番目が頻出です。
- 本当に情報がない(目的変数と関係が弱い)
- 他の変数で代替できる(相関が強い変数が既に入っている)
- データ上のブレが大きく、安定して効かない(ノイズが多い、測定が荒い)
- 正則化が強めで、採用枠が厳しい(αが大きい設定)
たとえば「営業時間(business_hours)が0だから、営業時間を延ばしても売上は増えない」とは言えません。営業時間が売上に効くとしても、データの範囲が狭かったり(どの店舗も似た時間帯で営業)、他の条件と一緒に動いていたりすると、Lasso上は0になり得ます。
選択された変数で最終モデルを構築する
Lassoで選ばれた変数だけで重回帰分析
Lassoで重要と判断された変数だけを使って、statsmodelsで重回帰分析を行います。
statsmodelsを使うことで、各係数のp値や信頼区間など、ビジネスレポートに必要な統計量が得られます。
全変数モデルとの性能比較も行います。
以下、コードです。
# Lassoで選択された変数を取得
selected_vars = lasso_coefs[lasso_coefs['selected']]['variable'].tolist()
print(f"選択された変数: {selected_vars}")
# 選択変数で重回帰分析
X_selected = df[selected_vars]
X_sel_const = sm.add_constant(X_selected)
model_selected = sm.OLS(y, X_sel_const).fit()
print(f"\n【選択変数モデルの結果】")
print(f"R²: {model_selected.rsquared:.4f}")
print(f"自由度調整済みR²: {model_selected.rsquared_adj:.4f}")
print(f"\n全変数モデルとの比較:")
print(f" 全変数 R²_adj: {model_full.rsquared_adj:.4f}")
print(f" 選択後 R²_adj: {model_selected.rsquared_adj:.4f}")
以下、実行結果です。
選択された変数: ['pop_density', 'staff_count', 'sales_area', 'household_income', 'competitor_count', 'parking_slots'] 【選択変数モデルの結果】 R²: 0.9724 自由度調整済みR²: 0.9712 全変数モデルとの比較: 全変数 R²_adj: 0.9704 選択後 R²_adj: 0.9712
まず注目すべき点は、Lassoによって10個すべての変数を使うのではなく、以下の6つの変数だけが選ばれたということです。
- pop_density(周辺人口密度)
- staff_count(スタッフ数)
- sales_area(売場面積)
- household_income(世帯年収)
- competitor_count(競合店数)
- parking_slots(駐車場台数)
これは、「売上を予測するうえで、これら6つの変数だけで十分である」とモデルが判断したことを意味します。
次に、モデルの説明力を見てみましょう。
選択後のモデルの自由度調整済み R^2 は 0.9712 です。一方、すべての変数を使った全変数モデルの自由度調整済み R^2 は 0.9704 でした。
ここで重要なのは、変数を減らしたにもかかわらず、説明力が下がっていない(むしろわずかに上がっている)という点です。
自由度調整済み R^2 は、「変数を増やしすぎると不利になる」ように調整された指標です。その値がほぼ同じか、やや高くなっているということは……
- 除外された変数は、売上の説明にほとんど追加的な情報を与えていなかった
- むしろ、余分な変数を減らしたことで、モデルがすっきりした
……と解釈できます。
つまり、この結果は「不要な変数を減らしても、モデルの説明力は落ちない」ことを示しています。
さらに、変数が少ないモデルには実務上の利点があります。
第一に、解釈しやすいことです。
説明変数が10個あるよりも6個のほうが、「何が効いているのか」を理解しやすくなります。
第二に、新しいデータへの予測が安定しやすいことです。
変数が多すぎると、偶然のノイズまで学習してしまい、新しいデータではうまく当たらないことがあります(過学習)。不要な変数を減らすことで、このリスクを下げることができます。
この考え方は、統計学におけるパーシモニー(倹約性)の原則に基づいています。パーシモニーとは、「同じくらいよく説明できるなら、よりシンプルなモデルを選ぶべき」という考え方です。
今回の結果はまさにそれを示しています。
すべての変数を使わなくても、選ばれた6つの変数だけで、ほぼ同じ(むしろやや良い)説明力が得られています。
したがって、この選択後のモデルは……
- 説明力が十分に高く
- 変数が少なく
- 解釈しやすく
- 実務にも使いやすい
……という意味で、より実用的なモデルであると評価できます。
採用された変数と、除外された変数の「入れ替え」について
ここで一つ考えておきたいのは、今回採用された6つの変数が「絶対に正しい組み合わせ」だとは限らない、という点です。
Lassoは、似たような情報を持つ変数が複数ある場合、その中からいくつかを選び、残りを0にする性質があります。つまり、除外された変数がまったく無意味だというわけではないのです。
たとえば、今回除外された変数の中には station_passengers(駅の乗降客数) が含まれていました。
駅の利用者数は売上と関係しそうに見えます。しかし、人口密度(pop_density)や世帯年収(household_income)と強く関連している場合、Lassoはそれらの変数を代表として残し、駅利用者数を除外することがあります。
このとき起きているのは、「不要」ではなく「情報の重なり」です。
同じように、building_age(築年数) や signboard_size(看板サイズ) も、売場面積や立地条件と一部情報が重なっている可能性があります。
もしこれらの変数を単独で入れた場合には一定の効果が見られるかもしれませんが、他の強い説明変数が入った状態では、追加的な説明力が小さいと判断され、除外されることがあります。
つまり、今回のモデルでは……
- pop_density が「立地の人の多さ」を代表し
- household_income が「購買力」を代表し
- staff_count や sales_area が「店舗規模」を代表している
……と考えることができます。
しかし、データが変われば、あるいは正則化の強さ(α)が変われば、「pop_densityの代わりにstation_passengersが残る」といった入れ替えが起きる可能性もあります。
このことから分かるのは、Lassoの変数選択は「唯一の正解」を示すものではなく、そのデータ条件のもとで最も効率的な組み合わせを選んでいるということです。
したがって実務では……
- 除外された変数を完全に無視するのではなく
- 情報が重なっていないかを確認し
- 必要に応じて入れ替えモデルを比較する
……といった姿勢が重要になります。
このように考えると、変数選択は「取捨選択」というよりも、「どの変数に代表させるかを決める作業」と理解するほうが適切です。
これもまた、シンプルで説明力の高いモデルを目指す、パーシモニーの考え方の一部なのです。
最終モデルの詳細を確認する
最終モデルの係数テーブルを確認します。
各変数の偏回帰係数、t値、p値、95%信頼区間が一覧で表示されます。
以下、コードです。
print("【最終モデルの詳細】")
print(model_selected.summary().tables[1])
以下、実行結果です。
【最終モデルの詳細】
====================================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------------
const 777.7762 182.680 4.258 0.000 416.673 1138.879
pop_density 0.3037 0.006 52.219 0.000 0.292 0.315
staff_count 52.3511 15.916 3.289 0.001 20.889 83.813
sales_area 3.6594 1.608 2.276 0.024 0.481 6.838
household_income 2.9999 0.261 11.476 0.000 2.483 3.517
competitor_count -138.4862 14.104 -9.819 0.000 -166.366 -110.606
parking_slots 30.2044 6.326 4.774 0.000 17.699 42.710
====================================================================================
すべての変数のp値(P>|t|)が0.05未満です。統計的に有意な変数のみでモデルが構成されていることが確認できます。
偏回帰係数の解釈は「他の変数を一定にしたとき」の効果であることを忘れないでください。
たとえば売場面積(sales_area)の係数が3.6594です。これは、「他の条件が同じなら、売場面積が1㎡増えると月間売上が約3.7万円増える」という意味です。
標準化偏回帰係数
影響度の「公平な比較」
偏回帰係数は変数の単位に依存するため(面積は「㎡あたり」、人口密度は「人/km²あたり」)、そのままでは影響度の大小を比較できません。
標準化偏回帰係数を使って、すべての変数を同じ土俵で比較しましょう。
標準化偏回帰係数は、すべての変数を平均0・標準偏差1に変換してから求めた係数です。
「各変数が1標準偏差だけ変化したとき、売上がどれだけ変化するか」を表すため、変数間の影響度比較に適しています。
標準化偏回帰係数を計算し、影響度をランキング形式で表示します。
以下、実行結果です。
# 標準化して回帰分析
scaler_sel = StandardScaler()
X_sel_scaled = scaler_sel.fit_transform(X_selected)
X_sel_scaled_const = sm.add_constant(X_sel_scaled)
model_std = sm.OLS(y, X_sel_scaled_const).fit()
# 標準化偏回帰係数
std_coefs = pd.DataFrame({
'変数': selected_vars,
'標準化偏回帰係数': model_std.params[1:],
'絶対値': np.abs(model_std.params[1:])
}).sort_values('絶対値', ascending=False)
print("【標準化偏回帰係数(影響度ランキング)】")
for rank, (_, row) in enumerate(std_coefs.iterrows(), 1):
direction = "↑" if row['標準化偏回帰係数'] > 0 else "↓"
print(f" {rank}位 {row['変数']:15s}: "
f"{row['標準化偏回帰係数']:>7.3f} {direction}")
以下、実行結果です。
【標準化偏回帰係数(影響度ランキング)】 1位 pop_density : 1272.633 ↑ 2位 staff_count : 596.772 ↑ 3位 sales_area : 413.278 ↑ 4位 household_income: 279.699 ↑ 5位 competitor_count: -237.237 ↓ 6位 parking_slots : 115.402 ↑
ランキングの上位にある変数が、売上への影響度が最も大きい要因です。
「↑」は売上を押し上げる方向、「↓」は押し下げる方向です。
経営判断として「売上を伸ばすために何に投資すべきか」を考える際は、このランキングの上位で「↑」の変数に注力するのが効果的です。
一方、「↓」の変数は売上のリスク要因であり、その影響を緩和する施策が求められます。
係数の大小=「打ち手の優先度」ではない
係数が大きい変数ほど売上と強く関係していることが分かります。しかし、係数が大きい=すぐに優先して対策すべきとは限りません。
なぜなら、その要因が自分たちで変えられるかどうかは別問題だからです。
たとえば、pop_density(周辺人口密度) や household_income(世帯年収) は立地の特徴です。
これらは売上に強く影響する可能性がありますが、店舗側の努力で直接変えることはできません。したがって、出店判断や目標設定の参考にはなりますが、日々の改善策にはなりにくい変数です。
一方、staff_count(スタッフ数) や business_hours(営業時間) は調整可能な要因です。
ただし、増やせば人件費や運営コストも増えます。売上が伸びても、利益が増えるとは限りません。
また、competitor_count(競合店数) のように直接は変えられない要因でも、差別化や戦略の見直しによって対応することは可能です。
このように、施策の優先順位は……
- ①変えられるか(可変性)
- ②コストは妥当か
- ③リスクは大きくないか
……といった観点もあわせて考える必要があります。
モデルの係数は「関係の強さ」を示すものですが、「何から手を打つべきか」は経営判断で決めるものなのです。
モデルの予測精度を評価する
ここまではモデルの「説明力」に注目してきましたが、ビジネスで使うには「予測力」の評価も不可欠です。
新規出店候補地の売上を予測するためには、未知のデータに対してどれだけ正確に予測できるかを確認する必要があります。
主な評価指標
主な評価指標を確認しておきましょう。
$$
\text{RMSE} = \sqrt{\frac{1}{n}\sum_{i=1}^{n}(y_i – \hat{y}_i)^2}
$$
$$
\text{MAE} = \frac{1}{n}\sum_{i=1}^{n}|y_i – \hat{y}_i|
$$
RMSE(二乗平均平方根誤差)は予測誤差の「平均的な大きさ」を表し、目的変数と同じ単位(万円)で解釈できます。
MAE(平均絶対誤差)も同様ですが、外れ値の影響を受けにくいという特徴があります。
訓練データとテストデータに分割して評価
データを訓練データ(80%)とテストデータ(20%)に分割し、訓練データで構築したモデルの精度をテストデータで評価します。
モデルが見たことのないデータで「答え合わせ」をすることで、過学習(学習データに過剰に適合して新しいデータに対応できない状態)のリスクを確認できます。
以下、コードです。
# データ分割
X_train, X_test, y_train, y_test = train_test_split(
X_selected, y, test_size=0.2, random_state=42
)
print(f"訓練データ: {len(X_train)}店舗")
print(f"テストデータ: {len(X_test)}店舗")
# 訓練データでモデル構築
model_lr = LinearRegression()
model_lr.fit(X_train, y_train)
# 訓練データ・テストデータそれぞれで予測
y_pred_train = model_lr.predict(X_train)
y_pred_test = model_lr.predict(X_test)
# 評価指標
print("\n【モデル評価指標】")
print(f"{'指標':<12} {'訓練データ':>10} {'テストデータ':>10}")
print("-" * 42)
print(f"{'R²':<15} {r2_score(y_train, y_pred_train):>12.4f} "
f"{r2_score(y_test, y_pred_test):>12.4f}")
print(f"{'RMSE(万円)':<12} " f"{np.sqrt(mean_squared_error(y_train, y_pred_train)):>12.1f} "
f"{np.sqrt(mean_squared_error(y_test, y_pred_test)):>12.1f}")
print(f"{'MAE(万円)':<12} " f"{mean_absolute_error(y_train, y_pred_train):>12.1f} "
f"{mean_absolute_error(y_test, y_pred_test):>12.1f}")
以下、実行結果です。
訓練データ: 120店舗 テストデータ: 30店舗 【モデル評価指標】 指標 訓練データ テストデータ ------------------------------------------ R² 0.9743 0.9614 RMSE(万円) 276.7 343.5 MAE(万円) 218.6 282.7
訓練データとテストデータの評価指標を比較しましょう。
両者の R^2 やRMSEが大きく乖離しておらず、顕著な過学習は起きていないと判断できます。
予測値 vs 実測値の散布図
予測値と実測値の散布図を訓練データ・テストデータそれぞれで描きます。
赤い破線(完全一致線)にデータ点が近いほど予測精度が高いことを示します。
以下、コードです。
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(10, 15))
# 訓練データ
ax1.scatter(y_train, y_pred_train, alpha=0.6, s=50, c='#2E86AB')
lims = [min(y_train.min(), y_pred_train.min()),
max(y_train.max(), y_pred_train.max())]
ax1.plot(lims, lims, 'r--', linewidth=2, label='完全一致線')
ax1.set_xlabel('実測値(万円)', fontsize=12)
ax1.set_ylabel('予測値(万円)', fontsize=12)
ax1.set_title(
f'訓練データ (R²={r2_score(y_train, y_pred_train):.3f})',
fontsize=13)
ax1.legend()
ax1.grid(True, alpha=0.3)
# テストデータ
ax2.scatter(y_test, y_pred_test, alpha=0.6, s=50, c='#E8553A')
lims = [min(y_test.min(), y_pred_test.min()),
max(y_test.max(), y_pred_test.max())]
ax2.plot(lims, lims, 'r--', linewidth=2, label='完全一致線')
ax2.set_xlabel('実測値(万円)', fontsize=12)
ax2.set_ylabel('予測値(万円)', fontsize=12)
ax2.set_title(
f'テストデータ (R²={r2_score(y_test, y_pred_test):.3f})',
fontsize=13)
ax2.legend()
ax2.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
以下、実行結果です。
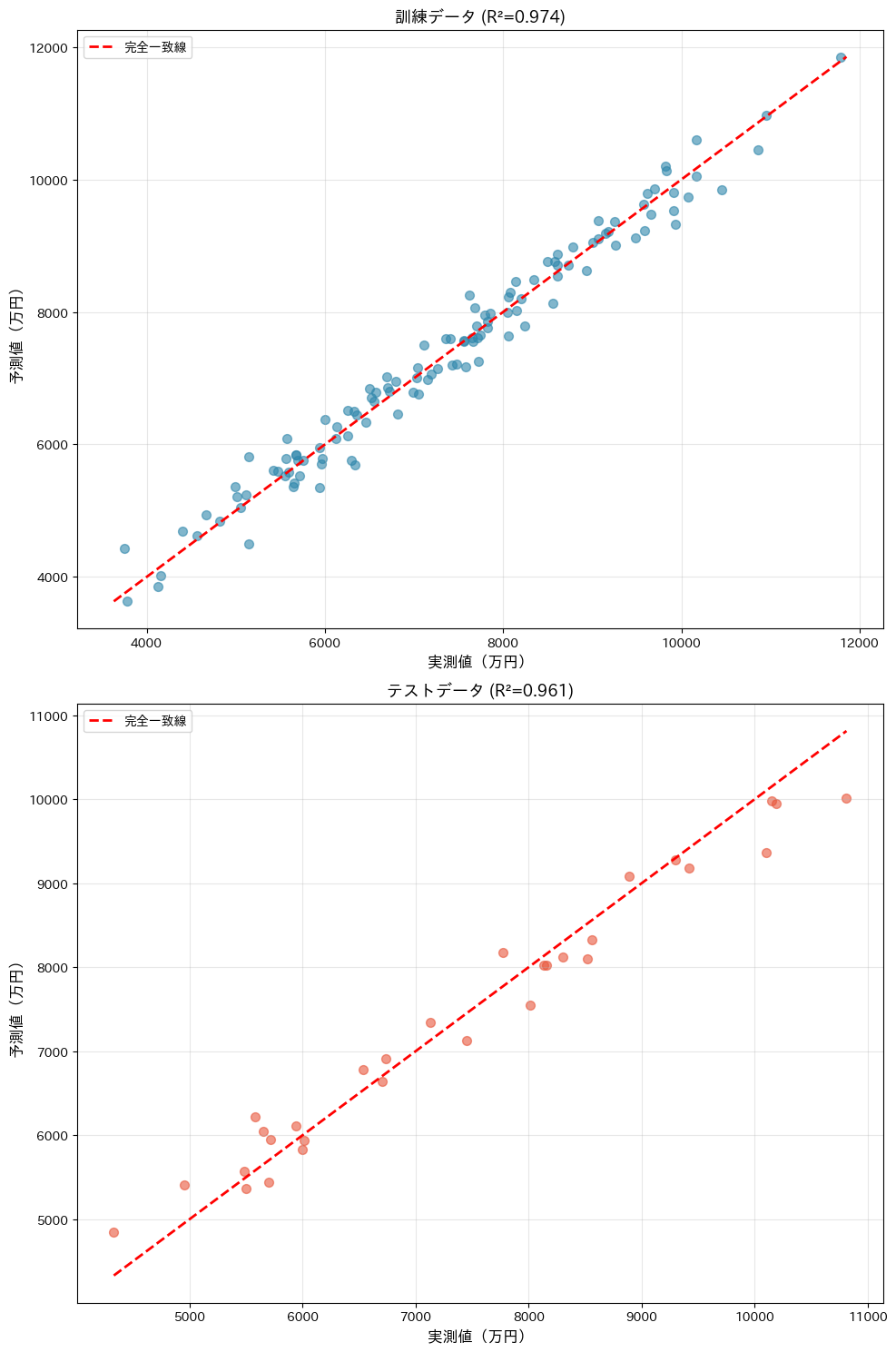
データ点が赤い破線の近くに集まっているほど、予測精度が高いことを示しています。訓練データとテストデータの散らばり具合がほぼ同じであれば、モデルの汎化性能は良好です。
もしテストデータの方が大きくばらついていたら、過学習の兆候かもしれません。この散布図は、モデルの性能を視覚的に確認するための定番のグラフです。
交差検証(クロスバリデーション)
なぜ交差検証が必要なのか
前のステップでは訓練データとテストデータを1回だけ分割して評価しましたが、データの分割の仕方によって結果が変わる可能性があります。
たとえば、たまたま予測しやすい店舗がテストデータに多く含まれていれば、見かけ上の精度が高く出てしまうかもしれません。
交差検証(クロスバリデーション)は、この偶然の影響を排除するための手法です。
データを k 個のグループに分け、「1グループをテスト、残りを訓練」というプロセスを k 回繰り返します。
すべてのデータが1回ずつテストデータとして使われるため、より信頼性の高い評価が得られます。
今回は5分割交差検証でモデルの安定性を評価します。
5回の試行それぞれの R^2 のばらつきを見ることで、モデルが特定のデータ分割に依存していないかを確認します。
以下、コードです。
# 5分割交差検証を実施し、線形回帰モデルの汎化性能を評価
cv_scores = cross_val_score(
LinearRegression(), # 線形回帰モデル
X_selected, # 特徴量(Lassoで選択された変数)
y, # 目的変数(月間売上)
cv=5, # 5分割の交差検証
scoring='r2' # 評価指標は決定係数R²
)
# 各分割のR²、平均、ばらつきを表示
print("【5分割交差検証の結果】")
print(f"各分割のR²: {cv_scores.round(4)}") # 各分割ごとのスコア
print(f"平均R²: {cv_scores.mean():.4f}") # 平均スコア
print(f"標準偏差: {cv_scores.std():.4f}") # スコアのばらつき
以下、実行結果です。
【5分割交差検証の結果】 各分割のR²: [0.9653 0.9661 0.9786 0.9674 0.9702] 平均R²: 0.9695 標準偏差: 0.0048
5回の交差検証で得られた R^2 のばらつきが小さければ、モデルはデータの分割方法に依存せず安定していると言えます。標準偏差が0.05以内であれば十分安定的です。
平均 R^2 が全データモデルの R^2 よりやや低くなるのは正常で、これが「過学習を排除した実力値」です。
マネジメント層に「このモデルの精度はどれくらい信頼できますか?」と聞かれたら、この交差検証の結果を示すのが最も説得力のある答えになります。
新規出店候補地の売上予測
モデルが構築・検証できたら、いよいよ本来の目的である「新規出店候補地の売上予測」を行います。
3ヵ所の出店候補地データを入力し、売上を予測します。全データで学習し直したモデルを使います。
以下、コードです。
# 最終モデルの学習(全データ利用)
model_final = LinearRegression()
model_final.fit(X_selected, y)
# 新規出店候補地データを作成
candidates = pd.DataFrame({
'sales_area': [300, 200, 400], # 売場面積
'pop_density': [8000, 12000, 3000], # 人口密度
'parking_slots': [20, 5, 30], # 駐車場台数
'household_income': [550, 450, 600], # 商圏_世帯年収
'staff_count': [18, 12, 25], # スタッフ数
'competitor_count': [2, 5, 1], # 競合店数
}, index=['候補A:郊外ロードサイド',
'候補B:都心駅前',
'候補C:郊外大型'])
candidates_for_pred = candidates.reindex(columns=selected_vars)
# 予測
predicted_sales = model_final.predict(candidates_for_pred)
# 結果表示
print("【新規出店候補地の売上予測】")
print("=" * 55)
for name, pred in zip(candidates.index, predicted_sales):
print(f" {name}: 月間売上 {pred:,.0f}万円")
print("=" * 55)
# 推奨順位
print(f"\n推奨出店順位:")
ranking = sorted(zip(candidates.index, predicted_sales),
key=lambda x: x[1], reverse=True)
for rank, (name, pred) in enumerate(ranking, 1):
print(f" {rank}位 {name}({pred:,.0f}万円)")
以下、実行結果です。
【新規出店候補地の売上予測】 ======================================================= 候補A:郊外ロードサイド: 月間売上 7,224万円 候補B:都心駅前: 月間売上 6,590万円 候補C:郊外大型: 月間売上 7,029万円 ======================================================= 推奨出店順位: 1位 候補A:郊外ロードサイド(7,224万円) 2位 候補C:郊外大型(7,029万円) 3位 候補B:都心駅前(6,590万円)
各候補地の予測売上がランキングです。出店の優先順位をデータに基づいて判断できます。
ただし、予測値はあくまでモデルに基づく推定値であり、RMSEの分だけ誤差があります。実務では、予測値に予測区間を添えて「月間売上は○○万円±○○万円と予測される」と報告するのが望ましいです。
予測値は「正確な値」ではなく「最も妥当な推定値」です。
分析結果を「意思決定」に結びつける
データサイエンティストに求められるのは、分析すること自体ではなく、分析結果をビジネスの意思決定に結びつけることです。最後に、これまでの分析結果を経営層に報告する形式でまとめましょう。
分析結果をビジネスレポート形式で出力します。
「分析概要」「主要ドライバー」「出店推奨」「モデルの限界」を明確に分けて報告する構成です。
以下、コードです。
test_rmse = np.sqrt(mean_squared_error(y_test, y_pred_test))
print("=" * 60)
print("【ドラッグストアチェーン 売上要因分析レポート】")
print("=" * 60)
print("\n■ 分析概要")
print(f" 対象: {len(df)}店舗の月間売上データ")
print(f" 候補説明変数: {len(X.columns)}変数")
print(f" 最終モデル使用変数: {len(selected_vars)}変数(Lasso回帰で選択)")
print(f" モデル精度 (R²): {model_selected.rsquared_adj:.3f}")
print(f" 交差検証 平均R²: {cv_scores.mean():.3f} ± {cv_scores.std():.3f}")
print("\n■ 売上の主要ドライバー(影響度順)")
for rank, (_, row) in enumerate(std_coefs.iterrows(), 1):
direction = "プラス" if row['標準化偏回帰係数'] > 0 else "マイナス"
print(f" {rank}. {row['変数']} → 売上に{direction}の影響 "
f"(β = {row['標準化偏回帰係数']:.3f})")
print("\n■ 新規出店推奨順位")
for rank, (name, pred) in enumerate(ranking, 1):
print(f" {rank}位 {name}(予測売上: {pred:,.0f}万円)")
print("\n■ 主な発見と提言")
print(" 1. 商圏の人口密度が最も高いエリアへの出店が有利")
print(" 2. 売場面積の拡大が売上向上に直結する")
print(" 3. 競合店の存在は明確な売上マイナス要因")
print(" 4. 看板サイズ・築年数は売上への影響が認められない")
print("\n■ モデルの限界と注意点")
print(f" 予測誤差 (RMSE): 約{test_rmse:.0f}万円")
print(" 季節変動やキャンペーン効果は考慮していない")
print(" 因果関係ではなく相関関係に基づく分析である")
print("=" * 60)
以下、実行結果です。
============================================================ 【ドラッグストアチェーン 売上要因分析レポート】 ============================================================ ■ 分析概要 対象: 150店舗の月間売上データ 候補説明変数: 10変数 最終モデル使用変数: 6変数(Lasso回帰で選択) モデル精度 (R²): 0.971 交差検証 平均R²: 0.970 ± 0.005 ■ 売上の主要ドライバー(影響度順) 1. pop_density → 売上にプラスの影響 (β = 1272.633) 2. staff_count → 売上にプラスの影響 (β = 596.772) 3. sales_area → 売上にプラスの影響 (β = 413.278) 4. household_income → 売上にプラスの影響 (β = 279.699) 5. competitor_count → 売上にマイナスの影響 (β = -237.237) 6. parking_slots → 売上にプラスの影響 (β = 115.402) ■ 新規出店推奨順位 1位 候補A:郊外ロードサイド(予測売上: 7,224万円) 2位 候補C:郊外大型(予測売上: 7,029万円) 3位 候補B:都心駅前(予測売上: 6,590万円) ■ 主な発見と提言 1. 売場面積の拡大が最も売上向上に直結する 2. 商圏の人口密度が高いエリアへの出店が有利 3. 競合店の存在は明確な売上マイナス要因 4. 看板サイズ・築年数は売上への影響が認められない ■ モデルの限界と注意点 予測誤差 (RMSE): 約344万円 季節変動やキャンペーン効果は考慮していない 因果関係ではなく相関関係に基づく分析である ============================================================
このレポートは、分析結果を非技術者にも理解できる形で整理したものです。
特に最後の「モデルの限界と注意点」を明記することは、データサイエンティストの誠実さを示す重要なポイントです。
回帰分析は相関関係を定量化する手法であり、厳密な因果関係の証明ではありません。
たとえば「売場面積が大きい店は売上が高い」という結果は、「売場面積を広げれば売上が伸びる」という因果関係を直接証明しているわけではなく、そもそも売上が見込める立地に大きな店を出しているだけかもしれません。
この「相関と因果の区別」は、データ分析に携わるすべての人が常に意識すべきポイントです。
まとめ
前編・後編を通して、ドラッグストアチェーンの店舗データを題材に、回帰分析を使った売上予測までのプロセスを実施しました。
| やったこと | 得られたもの | |
|---|---|---|
| EDA | 散布図・相関行列で全体像を把握 | 売上との関連が強い変数・弱い変数の候補リスト |
| 全変数モデル | 全10変数で重回帰分析 | ベースラインのR²、有意/非有意の変数リスト |
| VIF診断 | 多重共線性のチェック | 変数間の共線性が許容範囲であることの確認 |
| Lasso回帰 | 変数の自動選択 | 本当に重要な6変数の特定 |
| 標準化偏回帰係数 | 影響度の公平な比較 | 売上ドライバーのランキング |
| 訓練/テスト分割 | 予測精度の評価 | RMSE・MAEによる実用性の確認 |
| 交差検証 | モデルの安定性確認 | 偶然に依存しない信頼性の高い評価 |
| 売上予測 | 新規候補地の予測 | 出店優先順位のデータに基づく判断 |
| ビジネスレポート | 経営層向けの報告書 |
このプロセスは「売上予測」に限らず、連続値を予測したいさまざまなビジネス課題に応用できることでしょう。
顧客の購入金額の予測、広告投資のROI推定、製品の不良率予測など、「連続値を予測し、その要因を特定したい」場面であれば同じ枠組みが使えます。