
前回の記事では、minimize() を使って最適化問題を解く方法を紹介しました。
今回は、その応用とも言える 「カーブフィッティング(曲線あてはめ)」 を紹介します。
データ分析の現場では、散らばったデータ点に対して「このデータはどんな傾向を持っているのか?」を知りたい場面がたくさんあります。
カーブフィッティングは、データ点に最も近い曲線を見つけ出し、データの傾向を数式で表現する技術です。
今回は、SciPyの curve_fit() 関数を使って、データにフィッティングを行う方法を紹介します。
Contents
カーブフィッティングとは?
カーブフィッティング(curve fitting) とは、散らばったデータ点に最もよく合う曲線(または直線)を見つけることです。
たとえば、あるECサイトの月ごとの売上データがあったとします。
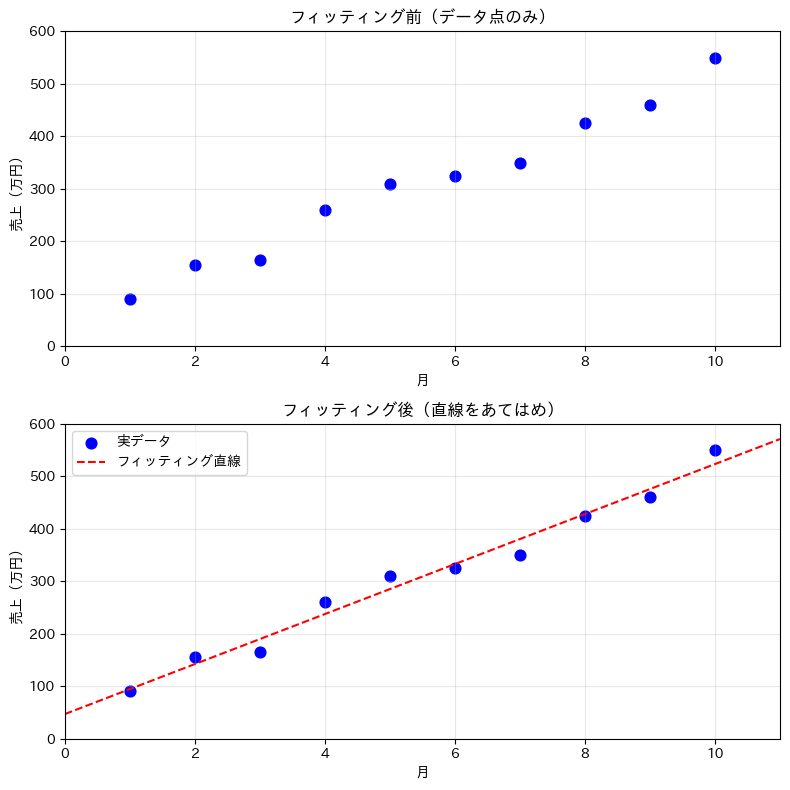
データ点だけを見ると傾向がつかみにくいですが、曲線をあてはめることで全体像が見えてきます。
以下のコードで、「フィッティング前」と「フィッティング後」を並べて確認してみましょう。
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
# 売上データ
months = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
sales = np.array([90, 155, 165, 260, 310, 325, 350, 425, 460, 550])
fig, axes = plt.subplots(2, 1, figsize=(8, 8))
#
# 上:データ点のみ(フィッティング前)
#
axes[0].scatter(
months, sales,
color='blue', s=60
)
axes[0].set_title('フィッティング前(データ点のみ)')
axes[0].set_xlabel('月')
axes[0].set_ylabel('売上(万円)')
axes[0].set_xlim(0, 11)
axes[0].set_ylim(0, 600)
axes[0].grid(True, alpha=0.3)
#
# 下:フィッティング後(直線を重ねる)
#
# フィッティング直線の計算
z = np.polyfit(months, sales, 1)
p = np.poly1d(z)
x_smooth = np.linspace(0, 11, 100)
# データ点のみ
axes[1].scatter(
months, sales,
color='blue', s=60, label='実データ'
)
# フィッティング直線
axes[1].plot(
x_smooth, p(x_smooth),
color='red', linestyle='--', label='フィッティング直線'
)
axes[1].set_title('フィッティング後(直線をあてはめ)')
axes[1].set_xlabel('月')
axes[1].set_ylabel('売上(万円)')
axes[1].set_xlim(0, 11)
axes[1].set_ylim(0, 600)
axes[1].legend()
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('fitting_before_after.png', dpi=150)
plt.show()
以下、実行結果です。
このような線が見つかれば、たとえば以下のようなことができるようになります。
- トレンド把握 → データの全体的な傾向を一目で理解できる
- 将来予測 → 曲線を延長して11月、12月の売上を予測できる
- モデル化 → 「売上 = ○○ × 月 + △△」のような数式で表現できる
- ノイズ除去 → データの細かなばらつきを平滑化できる
curve_fit() の基本的な考え方
curve_fit() は、内部で以下のような処理を行っています。
- ユーザーが「あてはめたい関数の形」を指定する(例:y = a × x + b)
curve_fit()が、データとの「ズレ」が最も小さくなるパラメータ(a, b の値)を自動で探す- 最適なパラメータが見つかる(例:a = 42.3, b = 65.1)
つまり、「y = 42.3x + 65.1 がデータに最もよく合う直線」という結論が得られます。
ここで言う「ズレ」とは、各データ点と曲線の距離のことです。
以下のコードで、ズレ(残差)を視覚的に確認してみましょう。
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
# データ
x_data = np.array([1, 2, 3, 4, 5, 6])
y_data = np.array([2.1, 4.8, 6.2, 8.9, 10.5, 13.1])
# 直線の式
def linear(x, a, b):
return a * x + b
# フィッティング(学習)
popt, _ = curve_fit(linear, x_data, y_data)
y_fit = linear(x_data, *popt)
# ズレ(残差)を可視化
plt.figure(figsize=(8, 5))
plt.scatter(x_data, y_data, color='blue', s=80, zorder=5, label='実データ')
plt.plot(x_data, y_fit, color='red', linestyle='--', label='フィッティング直線')
for i in range(len(x_data)):
plt.plot(
[x_data[i], x_data[i]],
[y_data[i], y_fit[i]],
color='green', linewidth=2, linestyle=':'
)
plt.annotate(
f'ズレ={y_data[i]-y_fit[i]:+.1f}',
xy=(x_data[i]+0.1, (y_data[i]+y_fit[i])/2),
fontsize=9, color='green'
)
plt.xlabel('x')
plt.ylabel('y')
plt.title('curve_fit() の仕組み:データとフィッティング直線のズレ(残差)')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('residual_image.png', dpi=150)
plt.show()
以下、実行結果です。
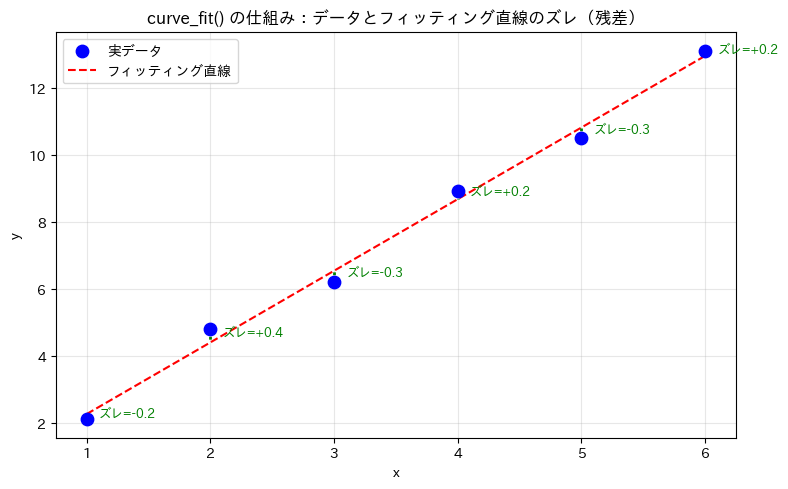
curve_fit() は、この緑の線(ズレ)の合計が最小になるパラメータを見つけてくれます。
実践①:直線フィッティング(線形回帰)
ある店舗の月ごとの売上データに、直線をあてはめてみましょう。
以下、コードです。
import numpy as np
from scipy.optimize import curve_fit
# ===== ① データを用意する =====
# 月(1月〜10月)
months = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
# 売上(万円):少しばらつきのあるデータ
sales = np.array([102, 155, 190, 248, 280, 335, 362, 410, 448, 505])
# ===== ② あてはめたい関数の形を定義する =====
# 直線:y = a * x + b
def linear(x, a, b):
return a * x + b
# ===== ③ curve_fit() でフィッティング =====
popt, pcov = curve_fit(linear, months, sales)
# ===== ④ 結果を表示 =====
print(f"最適パラメータ:a = {popt[0]:.2f}, b = {popt[1]:.2f}")
print(f"フィッティング式:y = {popt[0]:.2f} × x + {popt[1]:.2f}")
months = np.array([1, 2, ..., 10]):横軸のデータ(月)をNumPy配列で用意しますsales = np.array([102, 155, ..., 505]):縦軸のデータ(売上)をNumPy配列で用意しますdef linear(x, a, b)::あてはめたい関数の形を定義します。第1引数は必ず x(データ)で、それ以降がフィッティングで求めたいパラメータ(ここでは a と b)ですpopt, pcov = curve_fit(linear, months, sales):フィッティングを実行します
curve_fit() に渡す引数は以下の3つです。
| 引数 | 意味 | |
|---|---|---|
| 第1引数 | あてはめたい関数 | linear(直線の関数) |
| 第2引数 | xデータ(横軸) | months(月) |
| 第3引数 | yデータ(縦軸) | sales(売上) |
curve_fit() が返す2つの値の意味は以下のとおりです。
| 変数名 | |
|---|---|
popt |
最適パラメータ(parameter optimal の略)。フィッティングで求まったパラメータの値が配列で返されます |
pcov |
共分散行列(parameter covariance の略)。パラメータの推定精度に関する情報です(後述) |
以下、実行結果です。
最適パラメータ:a = 43.48, b = 64.33 フィッティング式:y = 43.48 × x + 64.33
この結果は、「売上は毎月約43.48万円ずつ増加しており、初月の基準値は約64.33万円」 ということを意味します。
実践②:フィッティング結果をグラフで確認する
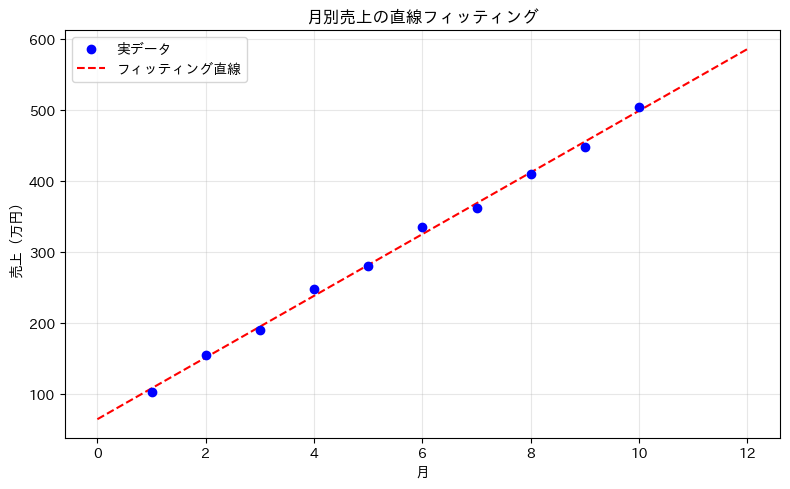
フィッティングの結果は、グラフで視覚的に確認することが大切です。
データ点とフィッティング曲線を重ねて描画してみましょう。
以下、コードです。
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
# データ
months = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
sales = np.array([102, 155, 190, 248, 280, 335, 362, 410, 448, 505])
# フィッティング用の関数(直線)
def linear(x, a, b):
return a * x + b
# フィッティング(学習)
popt, pcov = curve_fit(linear, months, sales)
# ===== グラフを描画 =====
# フィッティング曲線用のxデータ(滑らかに描くため細かく刻む)
x_smooth = np.linspace(0, 12, 100)
y_smooth = linear(x_smooth, *popt)
plt.figure(figsize=(8, 5))
plt.scatter(
months, sales,
color='blue',
label='実データ'
)
plt.plot(
x_smooth, y_smooth,
color='red', linestyle='--',
label='フィッティング直線'
)
plt.xlabel('月')
plt.ylabel('売上(万円)')
plt.title('月別売上の直線フィッティング')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('linear_fit.png', dpi=150)
plt.show()
print(f"フィッティング式:y = {popt[0]:.2f}x + {popt[1]:.2f}")
np.linspace(0, 12, 100):0から12の範囲を100等分した滑らかなx座標を生成します。これにより、フィッティング曲線がカクカクせずに滑らかに描画されますlinear(x_smooth, *popt):*poptは配列を展開して関数に渡す記法です。popt = [43.35, 62.53]なので、linear(x_smooth, 43.35, 62.53)と同じ意味になりますplt.scatter():データ点を散布図として描画しますplt.plot():フィッティング曲線を線グラフとして描画します
以下、実行結果です。
実践③:曲線フィッティング(2次関数)
直線だけでなく、曲線をあてはめることもできます。データが曲線的な傾向を持っている場合に有効です。
ある製品の広告費と売上の関係を調べたところ、広告費を増やすほど売上は伸びるが、次第に伸びが鈍化する傾向が見られました。
こうしたデータには、2次関数(放物線) をあてはめてみましょう。
まず、データの散布図を確認し、直線と2次関数の両方でフィッティングして比較します。
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
# 広告費(万円)
ad_cost = np.array([10, 20, 30, 40, 50, 60, 70, 80, 90, 100])
# 売上(万円):広告費が増えるほど伸びが鈍化
revenue = np.array([80, 150, 205, 250, 290, 320, 345, 365, 378, 390])
# ===== 直線であてはめ =====
# フィッティング用の関数(直線)
def linear(x, a, b):
return a * x + b
# フィッティング(学習)
popt_lin, _ = curve_fit(linear, ad_cost, revenue)
# ===== 2次関数であてはめ =====
# フィッティング用の関数(2次関数)
def quadratic(x, a, b, c):
return a * x ** 2 + b * x + c
# フィッティング(学習)
popt_quad, _ = curve_fit(quadratic, ad_cost, revenue)
# ===== グラフで比較 =====
# フィッティング曲線用のxデータ(滑らかに描くため細かく刻む)
x_smooth = np.linspace(5, 110, 200)
# グラフのサイズを設定
plt.figure(figsize=(8, 5))
# 実データをプロット
plt.scatter(
ad_cost, revenue,
color='blue', s=70, zorder=5,
label='実データ'
)
# フィッティング曲線(直線)をプロット
plt.plot(
x_smooth, linear(x_smooth, *popt_lin),
color='orange', linestyle='--', linewidth=2,
label='直線フィッティング'
)
# フィッティング曲線(2次関数)をプロット
plt.plot(
x_smooth, quadratic(x_smooth, *popt_quad),
color='red', linewidth=2,
label='2次関数フィッティング'
)
plt.xlabel('広告費(万円)')
plt.ylabel('売上(万円)')
plt.title('直線 vs 2次関数:どちらがよくフィットするか?')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('linear_vs_quadratic.png', dpi=150)
plt.show()
# ===== 残差の2乗和を比較 =====
# 直線の残差の2乗和
residual_lin = np.sum(
(revenue - linear(ad_cost, *popt_lin)) ** 2
)
# 2次関数の残差の2乗和
residual_quad = np.sum(
(revenue - quadratic(ad_cost, *popt_quad)) ** 2
)
print("【フィッティング結果】")
print(f" 直線 : y = {popt_lin[0]:.2f}x + {popt_lin[1]:.2f}")
print(f" 2次関数 : y = {popt_quad[0]:.4f}x² + {popt_quad[1]:.2f}x + {popt_quad[2]:.2f}")
print()
print("【残差の2乗和(小さいほど良い)】")
print(f" 直線 : {residual_lin:.2f}")
print(f" 2次関数 : {residual_quad:.2f}")
def quadratic(x, a, b, c)::2次関数 y = ax² + bx + c を定義しています。パラメータが a, b, c の3つに増えましたpopt_lin, _ = curve_fit(...):_(アンダースコア)は「この値は使わない」という意味の慣例的な書き方です。共分散行列を使わない場合にこのように書きますnp.sum((revenue - linear(ad_cost, *popt_lin)) ** 2):残差の2乗和(実データとフィッティング値のズレの合計)を計算しています。この値が小さいほど、フィッティングがよくデータに合っていることを意味します
以下、実行結果です。
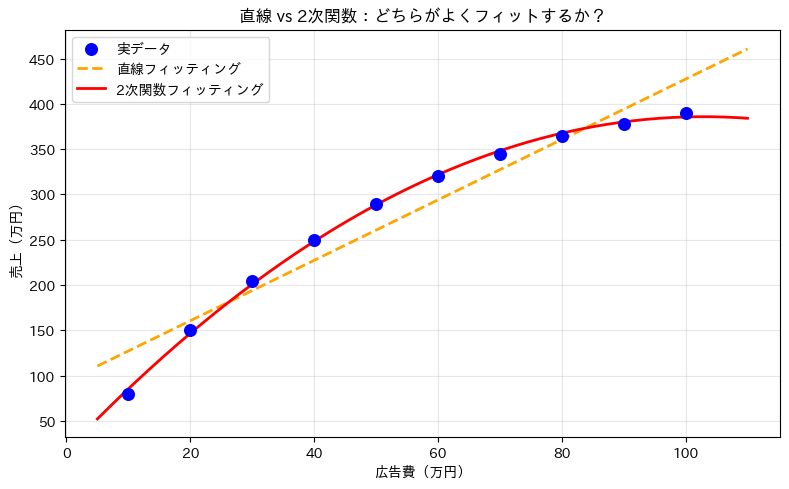
【フィッティング結果】 直線 : y = 3.33x + 93.93 2次関数 : y = -0.0348x² + 7.16x + 17.35 【残差の2乗和(小さいほど良い)】 直線 : 6506.10 2次関数 : 107.91
グラフを見ても数値を見ても、2次関数(107.91)のほうが直線(6506.10)よりも大幅にフィットが良いことがわかります。
実践④:指数関数フィッティング
データの増え方が「倍々に増えていく」ようなパターンには、指数関数をあてはめます。
ここで、あるWebサービスのユーザー数が急速に増加している様を表現したデータを使い、指数関数でフィッテングしてみます。
以下、コードです。
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
# 月(1〜8月)
months = np.array([1, 2, 3, 4, 5, 6, 7, 8])
# ユーザー数(人)
users = np.array([100, 160, 245, 400, 630, 1010, 1620, 2590])
# 指数関数:y = a * exp(b * x)
def exponential(x, a, b):
return a * np.exp(b * x)
# フィッティング(初期値を指定)
popt, pcov = curve_fit(exponential, months, users, p0=[50, 0.5])
print(f"最適パラメータ:a = {popt[0]:.2f}, b = {popt[1]:.4f}")
print(f"フィッティング式:y = {popt[0]:.2f} × exp({popt[1]:.4f} × x)")
print()
# フィッティング結果で将来予測
for m in [9, 10, 11, 12]:
predicted = exponential(m, *popt)
print(f" {m}月の予測ユーザー数:{predicted:,.0f} 人")
# ===== グラフで確認 =====
# フィッティング曲線用のxデータ(滑らかに描くため細かく刻む)
x_smooth = np.linspace(0.5, 12, 200)
# フィッティング曲線のy値を計算
y_smooth = exponential(x_smooth, *popt)
# グラフのサイズを設定
plt.figure(figsize=(8, 5))
# 実データをプロット
plt.scatter(
months, users,
color='blue', s=70,
label='実データ(1〜8月)'
)
# フィッティング曲線をプロット
plt.plot(
x_smooth, y_smooth,
color='red', linewidth=2,
label='指数関数フィッティング'
)
# 予測部分を強調
for m in [9, 10, 11, 12]:
pred = exponential(m, *popt)
plt.scatter(m, pred, color='red', s=70, marker='D')
plt.annotate(
f'{pred:,.0f}人',
xy=(m, pred), xytext=(m-1.2, pred+300),
fontsize=9, color='red'
)
# 予測部分の区切り線を追加
plt.axvline(
x=8.5,
color='gray', linestyle='-', alpha=0.5,
label='← 実データ | 予測 →'
)
plt.xlabel('月')
plt.ylabel('ユーザー数(人)')
plt.title('ユーザー数の指数関数フィッティングと将来予測')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('exponential_fit.png', dpi=150)
plt.show()
np.exp(b * x):ネイピア数 e(約2.718)のb * x乗を計算します。指数関数の増加を表現するときに使いますp0=[50, 0.5]:パラメータの初期値を指定しています。指数関数のように急激に増加する関数では、初期値を指定しないとうまくフィッティングできないことがありますplt.axvline(x=8.5, ...):実データ部分と予測部分の境界に縦の点線を引いています
以下、実行結果です。
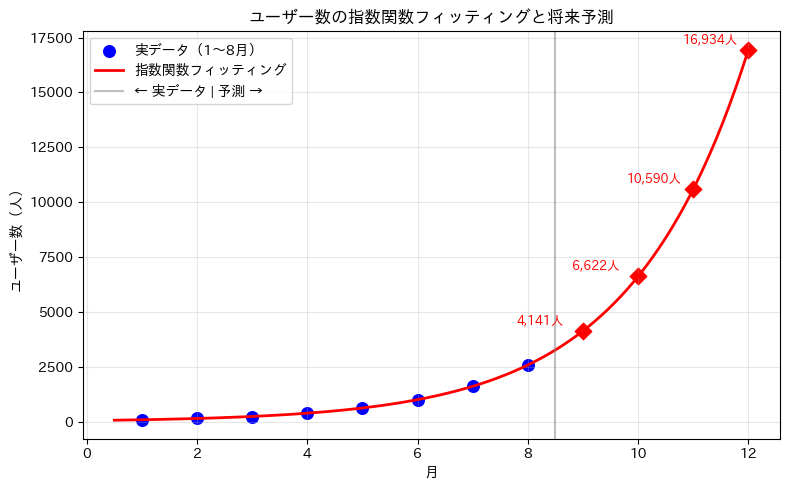
最適パラメータ:a = 60.55, b = 0.4695 フィッティング式:y = 60.55 × exp(0.4695 × x) 9月の予測ユーザー数:4,141 人 10月の予測ユーザー数:6,622 人 11月の予測ユーザー数:10,590 人 12月の予測ユーザー数:16,934 人
フィッティング結果を使って、9月以降のユーザー数を予測することもできました。
共分散行列からパラメータの信頼性を評価する
curve_fit() が返す2番目の値 pcov(共分散行列)を使うと、推定したパラメータがどれくらい信頼できるかを評価できます。
以下、コードです。
import numpy as np
from scipy.optimize import curve_fit
months = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
sales = np.array([102, 155, 190, 248, 280, 335, 362, 410, 448, 505])
def linear(x, a, b):
return a * x + b
popt, pcov = curve_fit(linear, months, sales)
# 共分散行列の対角成分の平方根 = パラメータの標準誤差
perr = np.sqrt(np.diag(pcov))
print(f"パラメータ a = {popt[0]:.2f} ± {perr[0]:.2f}")
print(f"パラメータ b = {popt[1]:.2f} ± {perr[1]:.2f}")
np.diag(pcov):共分散行列の対角成分(各パラメータの分散)を取り出しますnp.sqrt(...):平方根を取ることで、標準誤差(パラメータの推定精度を表す値)に変換します±以降の値が小さいほど、パラメータの推定精度が高いことを意味します
以下、実行結果です。
パラメータ a = 43.48 ± 0.78 パラメータ b = 64.33 ± 4.87
a = 43.48 ± 0.78 は、「傾き a は 43.48 で、誤差は ±0.78 程度」という意味です。
誤差が小さいので、このパラメータは信頼性が高いと判断できます。
どの関数をあてはめるべきか?
フィッティングの質は、あてはめる関数の選び方に大きく左右されます。
たとえば、以下の表を参考に、データの傾向に合った関数を選びましょう。
| 関数の種類 | 数式 | パラメータ数 | |
|---|---|---|---|
| 直線 | y = ax + b | 2 | 一定ペースで変化するデータ |
| 2次関数 | y = ax^2 + bx + c | 3 | 加速・鈍化するデータ |
| 指数関数 | y = a × e^{bx} | 2 | 急激に増加するデータ |
| 対数関数 | y = a × log(x) + b | 2 | 最初は急増し徐々に鈍化するデータ |
| べき乗関数 | y = a × x^b | 2 | スケール則に従うデータ |
判断の目安としては、一定のペースで増減しているなら直線、増減のペースが変わる(加速・鈍化)なら2次関数、倍々に急増しているなら指数関数、最初は急増しやがて頭打ちならロジスティック関数やS字カーブ、波のように上下を繰り返すなら三角関数が候補になります。
curve_fit() を使うときの注意点
① 初期値(p0)を適切に設定する
特に指数関数や三角関数など、複雑な関数では初期値が不適切だとフィッティングが失敗することがあります。
データの大まかな傾向から推測して初期値を設定しましょう。
② データ数はパラメータ数より十分多くする
パラメータが3つの関数(例:2次関数)に、データが3点しかないと、フィッティングの信頼性が非常に低くなります。
パラメータ数の5〜10倍以上のデータがあると安心です。
③ 過学習(かがくしゅう)に注意する
パラメータの多い複雑な関数を使うと、手元のデータには完璧にフィットするが、新しいデータには合わないという現象が起こります。
これを過学習(overfitting)と呼びます。
以下のコードで、適切なフィッティングと過学習の違いを視覚的に確認してみましょう。
import numpy as np
import matplotlib.pyplot as plt
# 元のデータ(ノイズ付き)
np.random.seed(42)
x = np.array([1, 2, 3, 4, 5, 6, 7, 8])
y_true = 2 * x + 3
y = y_true + np.random.normal(0, 1.5, len(x))
fig, axes = plt.subplots(2, 1, figsize=(8, 8))
x_smooth = np.linspace(0.5, 8.5, 200)
# 上:適切なフィッティング(直線)
z1 = np.polyfit(x, y, 1)
p1 = np.poly1d(z1)
axes[0].scatter(
x, y,
color='blue', s=70, zorder=5,
label='実データ'
)
axes[0].plot(
x_smooth, p1(x_smooth),
color='red', linewidth=2,
label='直線(適切)'
)
axes[0].set_title('適切なフィッティング(直線)')
axes[0].set_xlabel('x')
axes[0].set_ylabel('y')
axes[0].legend()
axes[0].grid(True, alpha=0.3)
axes[0].set_ylim(-2, 25)
# 下:過学習(7次多項式)
z7 = np.polyfit(x, y, 7)
p7 = np.poly1d(z7)
axes[1].scatter(
x, y,
color='blue', s=70, zorder=5,
label='実データ'
)
axes[1].plot(
x_smooth, p7(x_smooth),
color='red', linewidth=2,
label='7次多項式(過学習)'
)
axes[1].set_title('過学習(7次多項式)')
axes[1].set_xlabel('x')
axes[1].set_ylabel('y')
axes[1].legend()
axes[1].grid(True, alpha=0.3)
axes[1].set_ylim(-2, 25)
plt.tight_layout()
plt.show()
以下、実行結果です。
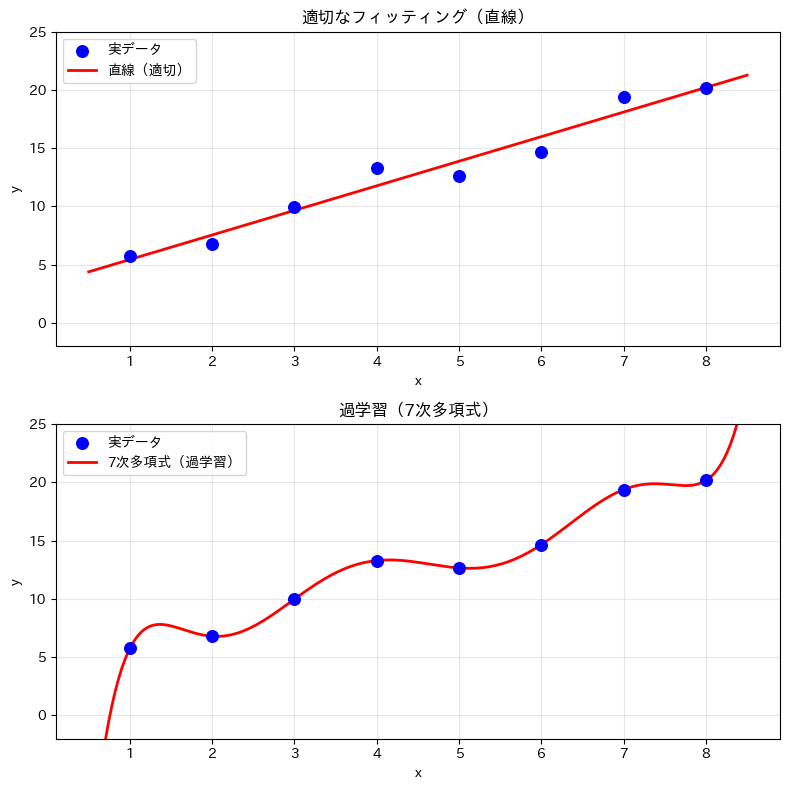
上のグラフは直線で滑らかにデータの傾向を捉えており、新しいデータにも対応できます。
一方、下のグラフは7次多項式でデータ点に過剰にフィットしており、データ点の間で大きく波打っています。新しいデータには合わない可能性が高く、これが過学習です。
シンプルな関数でデータの傾向を十分に捉えられるなら、わざわざ複雑な関数を使う必要はありません。
④ フィッティング結果は必ずグラフで確認する
数値だけでは分かりにくい問題も、グラフにすると一目瞭然です。
フィッティング後は必ず実データと曲線を重ねてプロットし、結果が妥当かどうかを視覚的に確認しましょう。
まとめ
このポイントを振り返りましょう。
- カーブフィッティング とは、散らばったデータ点に最もよく合う曲線を見つけること
- SciPyの
curve_fit()に「関数の形」「xデータ」「yデータ」を渡すだけで実行できる
popt(最適パラメータ) とpcov(共分散行列) の2つが返される- 直線・2次関数・指数関数など、データの傾向に合った関数を選ぶことが重要
- 残差の2乗和で、どの関数がよくフィットしているかを比較できる
pcovからパラメータの標準誤差(信頼性)を求めることもできる
- 過学習に注意し、シンプルな関数で十分かどうかを検討する
次回は、「scipy.interpolateで欠損データを補間する」 をテーマに、データの「隙間」を埋める技術を紹介していきます。
今回の「フィッティング」が全体の傾向をつかむ技術だとすれば、「補間」はデータ間の穴を埋める技術です。