

第2回までで、欠損値の検出と可視化ができるようになりました。
次のステップは、いよいよ「実際にどう処理するか」です。
欠損値への対処法は大きく分けて 削除(deletion) と 補完(imputation) の2種類があります。
今回はそのうち、もっともシンプルな リストワイズ削除(listwise deletion)、別名「完全ケース分析(Complete Case Analysis、CCA) 」を取り上げます。
「シンプル」というと安易な手法のように聞こえますが、実は 使うべき場面と避けるべき場面の見極め こそがデータサイエンティストの腕の見せどころです。
pandas の dropna() の使い方を一通り押さえつつ、削除のメリット・デメリットも整理していきましょう。
Contents
リストワイズ削除(CCA)とは?
リストワイズ削除 とは、欠損値を1つでも含む行を、データセットからまるごと削除する方法です。
残るのは「すべての列に値が入っている行」だけ、つまり完全な観測ケースだけを使った分析 になるので、完全ケース分析(CCA) とも呼ばれます。
CCA を使うべき場面・避けるべき場面
CCA は実装が極めて簡単で、削除した後のデータは 「すべての列が揃った完全なデータ」 になるため、その後の分析が非常にスムーズに進むという利点があります。
一方で、行を捨てるという性質上、サンプル数の減少 と バイアス(偏り)の混入 という2つのリスクを常に抱えています。
| CCA の適否 | |
|---|---|
| 欠損率が小さく(5%未満)、MCAR が想定される | 適している |
| 欠損率が高い(30%超)または MAR / MNAR が想定される | 避けるべき |
| サンプル数が十分多く、削除しても統計的検出力が落ちない | 適している |
| サンプル数が少なく、1件ずつが貴重 | 避けるべき |
第1回でお話しした通り、MCAR(完全にランダムな欠損)であれば、欠損行を削除しても残ったデータは元の集団の縮小版とみなせるため、バイアスは生じにくいです。
しかし、MAR や MNAR の場合は、削除によって特定の属性を持つサンプルだけが偏って失われ、分析結果が歪む可能性があります。
サンプルデータの準備
実際のコードに入っていきましょう。前回と同じ、seaborn の Titanic データセットを使います。
以下、コードです。
import pandas as pd
import numpy as np
import seaborn as sns
# Titanicデータセットの読み込み
df = sns.load_dataset('titanic')
print(f"元データの形状: {df.shape}")
print(f"\n欠損のある列と欠損率:")
print(
(df.isnull().mean() * 100) # 欠損率の計算
.round(2) # 小数点第2位まで表示
.sort_values(ascending=False) # 欠損率の降順に並び替え
.head(6) # 上位6件を表示
)
以下、実行結果です。
元データの形状: (891, 15) 欠損のある列と欠損率: deck 77.22 age 19.87 embarked 0.22 embark_town 0.22 sex 0.00 pclass 0.00 dtype: float64
データは891行15列で、deck が約77%、age が約20%、embarked と embark_town が約0.22% の欠損率を持つことが確認できます。
1. 全列を対象にした dropna():もっとも単純な使い方
dropna() を 何もオプションを指定せずに 呼び出すと、1つでも欠損を含む行をすべて削除 します。
これがリストワイズ削除の最も基本的な動作です。
以下、コードです。
# すべての欠損を含む行を削除
df_drop_all = df.dropna()
print(f"削除前: {df.shape}")
print(f"削除後: {df_drop_all.shape}")
print(f"残存率: {len(df_drop_all) / len(df) * 100:.1f}%")
df.dropna():欠損を1つでも含む行を削除した新しいデータフレームを返しますdf.shape:データの形状を(行数, 列数)で返します
以下、実行結果です。
削除前: (891, 15) 削除後: (182, 15) 残存率: 20.4%
891行あったデータが わずか182行(残存率約20%)まで減ってしまうことがわかります。
これは、deck 列の欠損率が77% と非常に高いため、その影響で大半の行が削除されてしまうためです。
2. subset で対象列を絞る
実用上、最も役立つのが subset パラメータ です。
これを使うと、「特定の列に欠損がある行だけを削除する」という、より柔軟な削除ができます。
単一列を対象にする
たとえば、embarked 列の欠損(2件しかない)だけを削除してみましょう。
以下、コードです。
# embarked 列に欠損がある行だけを削除
df_drop_embarked = df.dropna(subset=['embarked'])
print(f"削除前: {df.shape}")
print(f"削除後: {df_drop_embarked.shape}")
print(f"削除された行数: {len(df) - len(df_drop_embarked)}件")
subset=['embarked']:embarked列に欠損がある行だけを削除対象にします- 他の列(
ageやdeck)に欠損があっても、それらの行は残ります
以下、実行結果です。
削除前: (891, 15) 削除後: (889, 15) 削除された行数: 2件
削除されるのは embarked の欠損 2件だけで、残り889行はそのまま保持されます。
これは、欠損率が極めて低い列に対する CCA の理想的な使い方です。
複数列を対象にする
subset にはリストを渡せるので、複数の列を同時に指定できます。
以下、コードです。
# embarked と age の両方を対象に削除
df_drop_two = df.dropna(subset=['embarked', 'age'])
print(f"削除前: {df.shape}")
print(f"削除後: {df_drop_two.shape}")
print(f"削除された行数: {len(df) - len(df_drop_two)}件")
以下、実行結果です。
削除前: (891, 15) 削除後: (712, 15) 削除された行数: 179件
embarked と age の どちらか一方でも欠損している行 が削除されます。
age の欠損率が約20% なので、削除される行数もやや大きくなります。
3. how パラメータで削除条件を変える
subset で複数列を指定したとき、「どれか1つでも欠損なら削除」するのか「すべて欠損のときだけ削除」するのかを選べるのが、how パラメータです。
how の値 |
|
|---|---|
'any'(デフォルト) |
指定列のうち1つでも欠損があれば削除 |
'all' |
指定列がすべて欠損のときだけ削除 |
how='any':1つでも欠損があれば削除
以下、コードです。
# どちらかが欠損なら削除(デフォルト動作)
df_any = df.dropna(
subset=['age', 'embarked'],
how='any'
)
print(f"how='any': {df_any.shape}")
以下、実行結果です。
how='any': (712, 15)
これは先ほどと同じ動作で、age または embarked のどちらかでも欠損していれば削除されます。
how='all':すべて欠損のときだけ削除
以下、コードです。
# 両方とも欠損のときだけ削除
df_all = df.dropna(
subset=['age', 'embarked'],
how='all'
)
print(f"how='all': {df_all.shape}")
以下、実行結果です。
how='all': (891, 15)
age と embarked が 両方 欠損している行だけが削除されます。
Titanic データではそういう行はほとんどないため、削除される行はごくわずかです。
4. thresh パラメータ:「○個以上の値があれば残す」
thresh(threshold=閾値の略)パラメータは、「非欠損の値が○個以上ある行は残す」 という、より柔軟な指定ができます。
まず、非欠損数を各行ごとに求め、非欠損数ごとに何行あるのか数えてみます。データの列数(変数の数)は15です。
以下、コードです。
# 各行の非欠損数を数える例
print("各行の非欠損数の分布:")
print(
df.notnull() # 各要素が非欠損かどうかの真理値
.sum(axis=1) # 各行の非欠損数を数える
.value_counts() # 非欠損数ごとの行数を数える
.sort_index() # 非欠損数でソート
)
df.notnull():欠損でないセルをTrueとするデータフレーム.sum(axis=1):行方向に合計(=各行の非欠損数)
以下、実行結果です。
各行の非欠損数の分布: 13 160 14 549 15 182 Name: count, dtype: int64
Titanic データの15列のうち、15列すべて埋まっている行数が182行です。
ほとんどの行で14列以上が埋まっています。いくつかの行では13列しか埋まっていません。
以下、コードです。
# 非欠損が14個以上ある行だけを残す
df_thresh = df.dropna(thresh=14)
print(f"削除前: {df.shape}")
print(f"削除後(thresh=14): {df_thresh.shape}")
以下、実行結果です。
削除前: (891, 15) 削除後(thresh=14): (731, 15)
非欠損が13個以下の行(=欠損が2個以上ある行)だけが削除されます。
subset ほど明示的に列を指定しないため、コードはシンプルですが、どの列が削除条件に効いているかが見えにくい という欠点があります。
実務では subset を使うほうが意図が伝わりやすいでしょう。
5. CCA の前後を比較する:分布のチェック
CCA を実行したあと、残ったデータが元のデータと似た性質を持っているか を確認することが大切です。
これによって、削除によるバイアスが大きいか小さいかを推測できます。
数値変数の分布を比較する
age 列に欠損のある行を削除したあと、age 以外の重要な変数(fare や pclass)の分布が元と変わっていないかを見てみましょう。
以下、コードです。
# age を含む CCA
df_cca = df.dropna(subset=['age'])
print("【pclass の割合(%)】")
print("削除前:")
print(
# pclass の割合を計算
(df['pclass'].value_counts(normalize=True) * 100)
.round(2) # 小数点第2位まで表示
.sort_index() # インデックス順に並び替え
)
print("\n削除後:")
print(
# pclass の割合を計算
(df_cca['pclass'].value_counts(normalize=True)*100)
.round(2) # 小数点第2位まで表示
.sort_index() # インデックス順に並び替え
)
value_counts(normalize=True):各値の出現割合(合計1)を返します.sort_index():インデックス順(ここでは pclass 順)に並べます
以下、実行結果です。
【pclass の割合(%)】 削除前: pclass 1 24.24 2 20.65 3 55.11 Name: proportion, dtype: float64 削除後: pclass 1 26.05 2 24.23 3 49.72 Name: proportion, dtype: float64
削除前は1等が約24%、2等が約21%、3等が約55% であるのに対し、削除後は1等が約26%、2等が約24%、3等が約50% に変化しています。
3等船室の乗客が削除によって減っている のがわかります。これは第2回で確認した「3等船室で age の欠損率が高い」という MAR の兆候と一致します。
つまり、CCA によって 3等船室の乗客が選択的に失われ、残ったデータは「裕福な乗客に偏った集団」になっているのです。
可視化で違いを確認する
数値だけでは差が伝わりにくいので、ヒストグラムで比較してみましょう。
以下、コードです。
import matplotlib.pyplot as plt
# グラフサイズとレイアウトの設定
fig, axes = plt.subplots(2, 1, figsize=(6, 8))
# 比率データ(0-1)を計算
before_prop = df['pclass'].value_counts(normalize=True).sort_index()
after_prop = df_cca['pclass'].value_counts(normalize=True).sort_index()
# プロット(上段: Before)
before_prop.plot(
kind='bar', # 棒グラフ
ax=axes[0], # 上段のグラフにプロット
color='skyblue',
edgecolor='white'
)
axes[0].set_title('Before CCA')
axes[0].set_ylabel('Proportion')
axes[0].set_xticklabels(['1st', '2nd', '3rd'], rotation=0)
# 数値(%表記)をバーの上に表示
for p in axes[0].patches:
height = p.get_height()
axes[0].annotate(
f"{height*100:.1f}%",
(p.get_x() + p.get_width()/2, height),
ha='center', va='bottom', fontsize=10
)
# プロット(下段: After)
after_prop.plot(
kind='bar',
ax=axes[1],
color='pink',
edgecolor='white'
)
axes[1].set_title('After CCA (age column)')
axes[1].set_xlabel('Passenger Class')
axes[1].set_ylabel('Proportion')
axes[1].set_xticklabels(['1st', '2nd', '3rd'], rotation=0)
# 数値(%表記)をバーの上に表示
for p in axes[1].patches:
height = p.get_height()
axes[1].annotate(
f"{height*100:.1f}%",
(p.get_x() + p.get_width()/2, height),
ha='center', va='bottom', fontsize=10
)
plt.tight_layout()
plt.show()
以下、実行結果です。
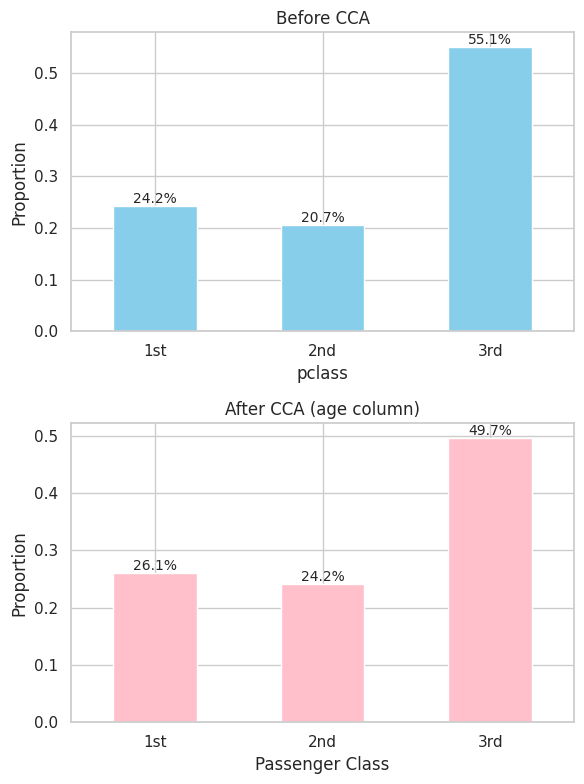
CCA 後は3等船室の比率が下がり、1等・2等の比率が上がっていることが視覚的に確認できます。
これが CCA が引き起こすバイアス の典型例です。
6. inplace=True の落とし穴
dropna() には inplace というパラメータがあり、True にすると 元のデータフレームから行を削除し直接書き換え ます。
以下、コードです。
df_copy = df.copy() df_copy.dropna(subset=['embarked'], inplace=True)
なんとなく、便利そうにも見えます。
しかし、以下の理由からinplace=True の使用は推奨されない方向に進んでいます。
- 元データが失われる:間違いに気づいても元に戻せない
- チェーンができない:
df.dropna().head()のような連鎖的な書き方ができない
- 将来的に非推奨化される可能性:pandas の開発方針として
inplace引数は段階的に減らされる傾向がある
なので、基本的には 新しい変数に代入する書き方 を覚えましょう。
以下、コードです。
# 推奨される書き方 df_clean = df.dropna(subset=['embarked'])
削除戦略のまとめ
CCA を使うかどうかは、欠損率と欠損メカニズムから判断します。
決まった正解はありませんが、おおよその判断基準を以下に示します。
| 状況 | |
|---|---|
| 欠損率が5%未満で、MCAR と推定される | dropna(subset=[...]) で対象列を絞って削除 |
| 欠損率が中程度(5〜30%)で、MAR と推定される | 削除よりも補完を優先 |
| 欠損率が高い(30%超) | 列の削除を検討 |
| 重要な変数で MNAR が疑われる | 専用のモデリング手法で対応 |
つまり、CCA は「欠損率が小さく、ランダム性が確認できる列」に限って使うべき手法 ということになります。
まとめ
今回のポイントを振り返りましょう。
- リストワイズ削除(CCA) は欠損値処理の最もシンプルな方法
- pandas の
dropna()で実装でき、複数のパラメータがある
subset:対象列を絞る(実務で最もよく使う)
how:'any'(1つでも欠損で削除)か'all'(すべて欠損で削除)
thresh:非欠損数の閾値で残すかどうかを判断
- CCA は 欠損率が小さく MCAR が想定される場合 に適している
- MAR / MNAR の場合は バイアスが残る ため、削除前後の分布を必ず確認する
inplace=Trueは避け、新しい変数に代入する書き方 を習慣にする