

第3回・第4回では「欠損のある行や列を削除する」戦略を紹介しました。
今回からはいよいよ、欠損値処理のもう一つの大きな柱である 補完(imputation) に入っていきます。
補完にはさまざまな方法がありますが、まず押さえておきたいのが 定数補完。
欠損箇所を「あらかじめ決めた特定の値」で埋めるシンプルな手法です。
「単純すぎて実用的ではないのでは?」と思うかもしれませんが、実は実務で頻繁に使われる重要なテクニックです。
今回は、pandas の fillna() と scikit-learn の SimpleImputer の使い方を比較しながら、列ごとに異なる補完値を適用する ColumnTransformer まで、ステップバイステップで説明します。
Contents
そもそも「補完」とは?
補完(imputation) とは、欠損値を何らかの 推定値 で埋める処理のことです。
「インピュテーション」とカタカナで呼ぶこともあります。
第3回・第4回の削除戦略と比べると、補完には次のようなメリットがあります。
- サンプル数が減らない:行や列を捨てないので、データのサイズを保てる
- すべての列が揃った状態を保てる:機械学習モデルへの入力が容易
- 欠損による情報損失を最小化できる:特に MCAR でない場合は、削除より補完のほうがバイアスを抑えやすい
もちろん、補完にも難点はあります。
埋めた値はあくまで推定値であり、真の値ではない ため、補完の方法を間違えると分析結果が歪みます。
だからこそ、適切な手法を選ぶ目利きが大切なのです。
単変量補完と多変量補完の違い
補完は大きく 単変量補完(univariate imputation) と 多変量補完(multivariate imputation) に分けられます。
| 種類 | 仕組み | |
|---|---|---|
| 単変量補完 | その列の値だけを使って補完値を決める | 平均値、中央値、最頻値、定数 |
| 多変量補完 | 他の列の情報も使って補完値を決める | KNN、MICE、MissForest |
定数補完とは?
定数補完(constant imputation) とは、欠損値を あらかじめ決めた1つの値 で一律に置き換える方法です。
たとえば次のようなケースです。
- カテゴリ列の欠損を
'Unknown'で埋める - 数値列の欠損を
0で埋める - ドメイン知識から「妥当な代表値」(たとえば成人の平均身長 170cm)を入れる
「どんな値を入れるか」は ドメイン知識 や データの意味 に強く依存します。
安易にゼロで埋めると分布が大きく歪むこともあるため、慎重に選ぶ必要があります。
サンプルデータの準備
これまで通り、seaborn の Titanic データセットを使います。
以下、コードです。
import pandas as pd
import numpy as np
import seaborn as sns
# Titanicデータセットの読み込み
df = sns.load_dataset('titanic')
# 欠損のある列を確認
missing = df.isnull().sum()
print("欠損のある列:")
print(missing[missing > 0])
以下、実行結果です。
欠損のある列: age 177 embarked 2 deck 688 embark_town 2 dtype: int64
age(177件)、embarked(2件)、deck(688件)、embark_town(2件)に欠損があることが確認できます。
pandas の fillna() で定数補完
最もシンプルな実装は、pandas の fillna() メソッドです。
単一列に定数を入れる
まず、単一列に定数を入れる例を示します。
以下、コードです。
# embarked 列の欠損を 'S' で埋める
df_filled = df.copy()
df_filled['embarked'] = df_filled['embarked'].fillna('S')
print(
f"補完前の欠損数: "
f"{df['embarked'].isnull().sum()}"
)
print(
f"補完後の欠損数: "
f"{df_filled['embarked'].isnull().sum()}"
)
df.copy():元のデータフレームを変更しないようコピーを作成fillna('S'):欠損を'S'で埋めた Series を返します
以下、実行結果です。
補完前の欠損数: 2 補完後の欠損数: 0
補完前は欠損2件あった embarked 列が、補完後は欠損ゼロになっています。
'S' を選んだのは Titanic データで embarked の最頻値が 'S'(Southampton)だからですが、これは厳密には「最頻値補完」です。
ここでは「ドメイン知識から 'S' という定数を選んだ」と解釈してください。
列ごとに異なる定数を辞書で指定
次に、列ごとに異なる定数を辞書で指定する例を示します。
fillna() には 辞書 を渡すこともでき、列ごとに異なる値で一気に補完できます。
以下、コードです。
# 列ごとに別々の定数を指定
# ここでは欠損値を埋めるために、列ごとに代表値を設定します
fill_values = {
'embarked': 'S', # 最頻カテゴリである'S'で補完
'embark_town': 'Southampton', # 'embarked'に対応する都市名で補完
'age': 30, # 年齢の欠損は30歳で補完(例)
'deck': 'C' # デッキは'C'で補完(例)
}
# 辞書で指定した値を用いて欠損値を一括補完
df_filled = df.fillna(fill_values)
# 補完後に、まだ欠損が残っている列があるかを確認
print("補完後の欠損数:")
print(
df_filled.isnull().sum()
[df_filled.isnull().sum() > 0]
)
fillna(辞書):辞書のキーが列名、値が補完値になります- 辞書に含まれない列は変更されません
以下、実行結果です。
補完後の欠損数: Series([], dtype: int64)
4つの列の欠損がそれぞれ指定した値で埋められ、すべての列で欠損がゼロになります。
scikit-learn の SimpleImputer
SimpleImputer は scikit-learn が提供する補完用クラスで、学習データから補完値を学習し、テストデータにも同じ値を適用する 仕組みを持っています。
これは データ漏洩(data leakage) を防ぐうえで重要です。
fit と transform の考え方
scikit-learn の前処理クラスはどれも、次の2つのメソッドを持っています。
fit(X):学習データXから補完に必要な情報(=補完値)を学習するtransform(X):学習した補完値を使ってデータを変換する
学習データには fit と transform を一度に行う fit_transform()、テストデータには学習済みの値を適用する transform() を使うのが基本パターンです。
単一列を SimpleImputer で補完
まず、シンプルに embarked 列だけを補完してみましょう。
以下、コードです。
from sklearn.impute import SimpleImputer
from sklearn.model_selection import train_test_split
# 学習用とテスト用に分割
df_train, df_test = train_test_split(
df, # 元データ
test_size=0.2, # データの20%をテスト用に確保
random_state=42 # 乱数シード
)
# 定数 'S' で欠損を埋めるインピュータを作成
# (カテゴリ欠損に単一値を代入)
imputer = SimpleImputer(
strategy='constant', # 一定値で補完
fill_value='S' # 補完に使う値
)
# 学習データでfitしてからtransform(学習データから補完ルールを学習)
# 元データを保護するためコピー
df_train_imputed = df_train.copy()
# 2次元配列を渡し、結果は1次元にravelで整形
df_train_imputed['embarked'] = imputer.fit_transform(
df_train[['embarked']]
).ravel()
# テストデータには学習済みのインピュータでtransformのみ
# (情報漏洩を防ぐ)
df_test_imputed = df_test.copy()
df_test_imputed['embarked'] = imputer.transform(
df_test[['embarked']]
).ravel()
# 欠損が解消されたかを確認
print(
f"学習データの欠損: "
f"{df_train_imputed['embarked'].isnull().sum()}"
)
print(
f"テストデータの欠損: "
f"{df_test_imputed['embarked'].isnull().sum()}"
)
SimpleImputer(strategy='constant', fill_value='S'):定数'S'で補完するインピュータを作成df_train[['embarked']]:二重括弧で データフレーム形式 を保ちます(SimpleImputerは2次元配列を期待するため).ravel():返ってきた2次元配列を1次元配列にして、列に代入できる形にします
以下、実行結果です。
学習データの欠損: 0 テストデータの欠損: 0
学習データ・テストデータの両方で embarked の欠損がゼロになります。
ColumnTransformer で列ごとに異なる補完を適用する
実務では、カテゴリ列はカテゴリ列の補完戦略で、数値列は数値列の戦略で 扱いたいことがほとんどです。
これを実現するのが、scikit-learn の ColumnTransformer です。
以下、コードです。
from sklearn.compose import ColumnTransformer
from sklearn.impute import SimpleImputer
# 補完対象の列を整理(カテゴリ列と数値列)
categorical_cols = ['embarked', 'deck'] # カテゴリ列
numerical_cols = ['age'] # 数値列
# 列ごとに異なるインピュータを定義
preprocessor = ColumnTransformer(
transformers=[
(
'cat', # カテゴリ列用のトランスフォーマー名
SimpleImputer(
strategy='constant', # 一定値で補完
fill_value='Unknown' # 欠損は 'Unknown' で埋める
),
categorical_cols # 対象列
),
(
'num', # 数値列用のトランスフォーマー名
SimpleImputer(
strategy='constant', # 一定値で補完
fill_value=0 # 欠損は 0 で埋める
),
numerical_cols # 対象列
),
],
remainder='passthrough' # 上記以外の列はそのまま通す
)
ColumnTransformer(transformers=[...]):列ごとの変換ルールをリストで指定- 各タプルは
(任意の名前, 変換器, 対象列)の3要素 remainder='passthrough':指定しなかった列は そのまま残す(デフォルトの'drop'だと削除されます)
このように定義しておけば、あとは fit_transform と transform を呼ぶだけで、複数列の補完が一気に進みます。
以下、コードです。
# 実行:学習データで fit_transform(学習データから補完ルールを学ぶ)
train_array = preprocessor.fit_transform(
df_train[categorical_cols + numerical_cols] # 対象列のみ抽出
)
# テストデータには transform のみ(情報漏洩を防ぐ)
test_array = preprocessor.transform(
df_test[categorical_cols + numerical_cols] # 同じ列順で適用
)
# 配列をデータフレームに戻して確認(列名を付与)
train_imputed_df = pd.DataFrame(
train_array,
columns=categorical_cols + numerical_cols
)
# 先頭数行を確認
print(train_imputed_df.head())
# 欠損が解消されているか確認
print(
f"\n補完後の欠損: "
f"\n{train_imputed_df.isnull().sum()}"
)
preprocessor.fit_transform(...):学習データから補完値を学び、変換した NumPy 配列を返しますpreprocessor.transform(...):テストデータに同じ補完を適用pd.DataFrame(配列, columns=...):返ってきた配列を再びデータフレームに変換
以下、実行結果です。
embarked deck age 0 S C 45.5 1 S Unknown 23.0 2 S Unknown 32.0 3 S Unknown 26.0 4 S Unknown 6.0 補完後の欠損: embarked 0 deck 0 age 0 dtype: int64
embarked と deck は 'Unknown' で、age は 0 で埋められた配列が返ってきます。
3列とも欠損がゼロになっていることが確認できます。
列ごとに違う定数を使う実例
より実践的な例を紹介します。
embarked、deck、age、fare の4列に、それぞれ別の定数を割り当てる例です。
以下、コードです。
# 各列に違う定数を入れるインピュータを4つ用意
# embarked 列は欠損を 'S' で埋める
embarked_imputer = SimpleImputer(
strategy='constant',
fill_value='S'
)
# deck 列は欠損を 'T20' で埋める(例示用の定数)
deck_imputer = SimpleImputer(
strategy='constant',
fill_value='T20'
)
# age 列は欠損を 30 で埋める(例示用の定数)
age_imputer = SimpleImputer(
strategy='constant',
fill_value=30
)
# fare 列は欠損を 8 で埋める(例示用の定数)
fare_imputer = SimpleImputer(
strategy='constant',
fill_value=8
)
# ColumnTransformer で統合
# 列ごとに対応するインピュータを適用し、その他の列は落とす
preprocessor = ColumnTransformer(
transformers=[
# embarked に embarked_imputer を適用
('embarked', embarked_imputer, ['embarked']),
# deck に deck_imputer を適用
('deck', deck_imputer, ['deck']),
# age に age_imputer を適用
('age', age_imputer, ['age']),
# fare に fare_imputer を適用
('fare', fare_imputer, ['fare']),
],
remainder='drop'
)
# 実行
# 対象列のみ抜き出して fit_transform し、結果を DataFrame に戻す
target_cols = ['embarked', 'deck', 'age', 'fare']
result_array = preprocessor.fit_transform(
df_train[target_cols]
)
result_df = pd.DataFrame(
result_array,
columns=target_cols
)
# 先頭を確認し、欠損が解消されているか確認
print(result_df.head())
print(f"\n各列の補完後の欠損数:\n{result_df.isnull().sum()}")
以下、実行結果です。
embarked deck age fare 0 S C 45.5 28.5 1 S T20 23.0 13.0 2 S T20 32.0 7.925 3 S T20 26.0 7.8542 4 S T20 6.0 31.275 各列の補完後の欠損数: embarked 0 deck 0 age 0 fare 0 dtype: int64
embarked、deck、age、fare の4列がそれぞれ 'S'、'T20'、30、8 で補完されます。
列ごとに別々のロジックを適用できる柔軟性 が ColumnTransformer の大きな強みです。
定数補完が分布に与える影響
最後に、定数補完が データの分布をどう変えてしまうか を可視化してみましょう。
以下、コードです。
import matplotlib.pyplot as plt
# age を 0 で補完したデータを準備(欠損は0に置換)
df_age_zero = df.copy()
df_age_zero['age'] = df_age_zero['age'].fillna(0)
# 元データ(ageの欠損を除外)と、0で補完したデータを比較可視化
fig, axes = plt.subplots(2, 1, figsize=(6, 6))
# 上段:欠損を除外した元の年齢分布
axes[0].hist(
df['age'].dropna(), # NaNを落とした年齢
bins=30, # ビン数
color='skyblue', # 棒の色
edgecolor='white' # 枠線の色
)
axes[0].set_title('Original (NaN dropped)')
axes[0].set_xlabel('Age')
axes[0].set_ylabel('Frequency')
# 下段:欠損を0で埋めた後の年齢分布
axes[1].hist(
df_age_zero['age'], # 0で補完後の年齢
bins=30,
color='coral',
edgecolor='white'
)
axes[1].set_title('After fillna(0)')
axes[1].set_xlabel('Age')
plt.tight_layout()
plt.show()
以下、実行結果です。
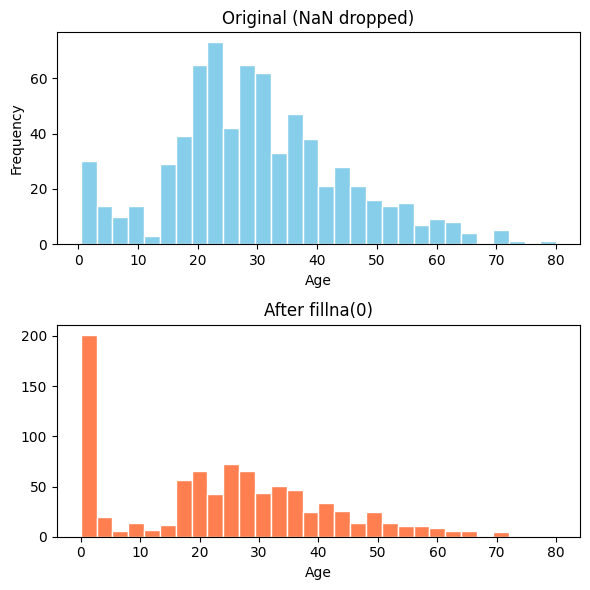
上図の元データはおよそ20〜40代を中心とした自然な分布なのに対し、下図のヒストグラムでは 左端(年齢0付近) に巨大な棒が出現します。
これは欠損177件すべてが 0 で埋められた結果です。
このように定数補完は、特定の値に質量が集中する不自然な分布 を作りやすいという欠点があります。
age = 0 は乳児を意味してしまうため、ロジスティック回帰のような線形モデルには悪影響を与えます。
まとめ
今回のポイントを振り返りましょう。
- 補完は欠損値処理のもう一つの柱で、サンプル数を減らさずに済むメリットがある
- 単変量補完 と 多変量補完 があり、今回は単変量補完の入口として 定数補完 を扱った
- pandas の
fillna()は手軽に定数補完できるが、パイプライン化には不向き - scikit-learn の
SimpleImputer(strategy='constant', fill_value=...)は学習・テスト間で一貫した補完が可能で、データ漏洩を防げる
ColumnTransformerを使えば列ごとに異なる補完戦略を適用できる- 数値変数の定数補完は 分布を歪めるリスク があるため、慎重に判断する