
次の Python コードの出力はどれでしょうか?
Python コード:
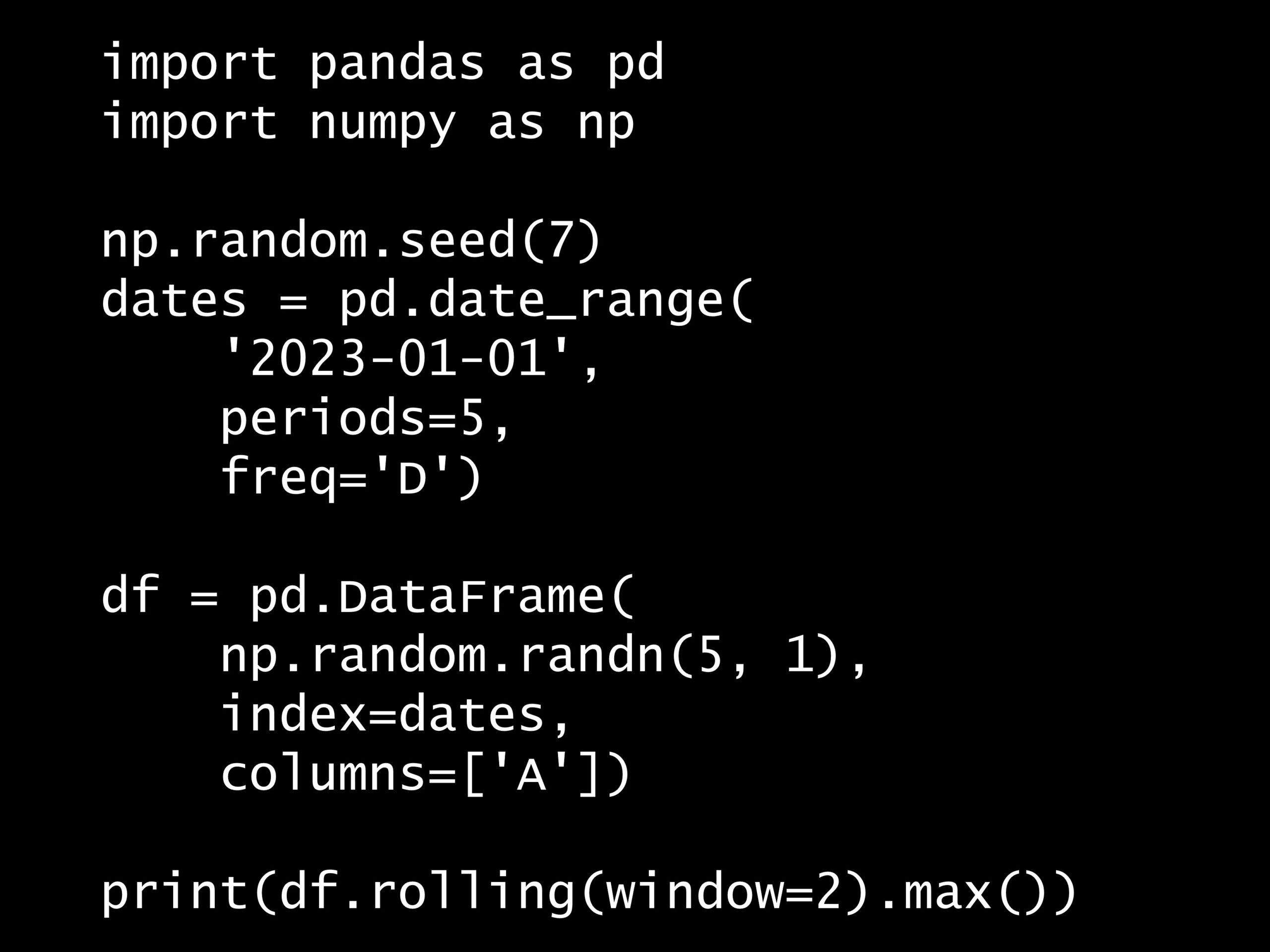
import pandas as pd
import numpy as np
np.random.seed(7)
dates = pd.date_range(
'2023-01-01',
periods=5,
freq='D')
df = pd.DataFrame(
np.random.randn(5, 1),
index=dates,
columns=['A'])
print(df.rolling(window=2).max())
回答の選択肢:
(A) 各日の最大値
(B) 2日間のウィンドウでの最大値
(C) 全期間の最大値
(D) 2日間のウィンドウでの最小値
出力例:
A 2023-01-01 NaN 2023-01-02 1.690526 2023-01-03 0.032820 2023-01-04 0.407516 2023-01-05 0.407516
正解:
(B)
解説:
このコードはランダムな値を持つ時系列データフレームを作成し、そのデータに対して移動窓を適用して最大値を計算しています。
詳しく説明します。
日付の範囲を作成しています。範囲は’2023-01-01’から始まり、5つの期間(’D’は日を意味します)を含みます。
dates = pd.date_range(
'2023-01-01',
periods=5,
freq='D')
datesに格納されているデータは次のようになっています。
DatetimeIndex(['2023-01-01', '2023-01-02', '2023-01-03', '2023-01-04',
'2023-01-05'],
dtype='datetime64[ns]', freq='D')
この日付範囲をインデックスとして使用し、5行1列のランダムな値を持つデータフレームを作成します。このデータフレームの列名は’A’です。
df = pd.DataFrame(
np.random.randn(5, 1),
index=dates,
columns=['A'])
例えば、dfに格納されているデータは次のようになっています。ランダムな値を入れているため、人によって値は異なります。
A 2023-01-01 1.690526 2023-01-02 -0.465937 2023-01-03 0.032820 2023-01-04 0.407516 2023-01-05 -0.788923
最後に、データフレームの `rolling` メソッドを利用して、2つのデータポイント(これが窓の大きさを定義します)ごとに移動窓を作成します。そして、この窓内の最大値を計算します。最初のデータポイントのウィンドウが完全ではないため、その結果はNaN(欠損値)です。
print(df.rolling(window=2).max())
結果として、2つのデータポイント毎の最大値が表示されます。これは、データが2日ごとに最大値を計算した結果を示しています。
A 2023-01-01 NaN 2023-01-02 1.690526 2023-01-03 0.032820 2023-01-04 0.407516 2023-01-05 0.407516