
- 問題
- 答え
- 解説
Python コード:
import numpy as np
import pandas as pd
from arch import arch_model
from statsmodels.datasets import get_rdataset
data = get_rdataset(
'AirPassengers', 'datasets').data.value
data_diff = data.diff().dropna()
model = arch_model(data_diff,vol='Garch',p=1,q=1)
results = model.fit(disp='off')
forecast = results.forecast(horizon=10)
print(forecast.variance.values.T)
回答の選択肢:
(A) ボラティリティクラスタリング
(B) カルマンフィルター
(C) ホドリック・プレスコットフィルター
(D) ボラティリティモデル
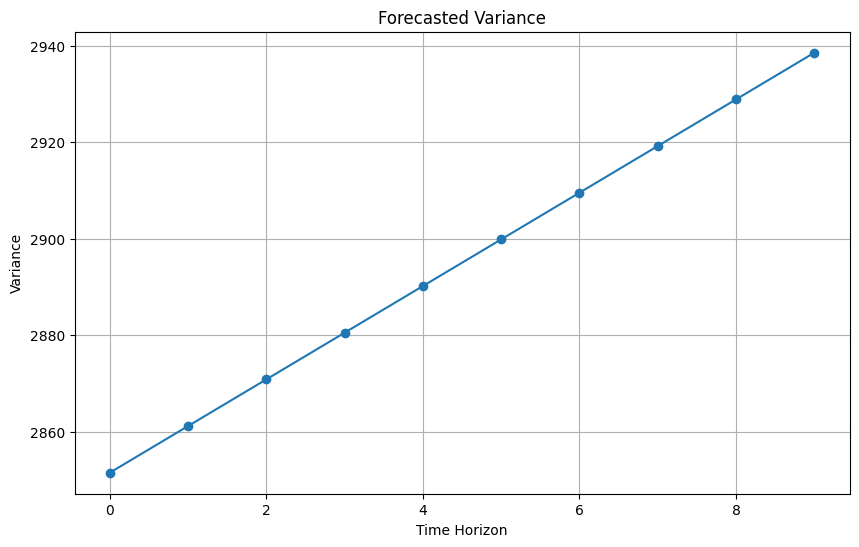
[[2851.50488539] [2861.18045699] [2870.85602859] [2880.53160019] [2890.20717178] [2899.88274338] [2909.55831498] [2919.23388658] [2928.90945818] [2938.58502977]]
正解: (D)
回答の選択肢:
(A) ボラティリティクラスタリング
(B) カルマンフィルター
(C) ホドリック・プレスコットフィルター
(D) ボラティリティモデル
- コードの解説
-
このコードは、時系列データの分散を推定するためにボラティリティモデルを使用しています。具体的には、GARCH(Generalized Autoregressive Conditional Heteroskedasticity)モデルを用いています。
import numpy as np import pandas as pd from arch import arch_model from statsmodels.datasets import get_rdataset data = get_rdataset( 'AirPassengers', 'datasets').data.value data_diff = data.diff().dropna() model = arch_model(data_diff,vol='Garch',p=1,q=1) results = model.fit(disp='off') forecast = results.forecast(horizon=10) print(forecast.variance.values.T)詳しく説明します。
データセットを取得します。この例では、
AirPassengersデータセットを使用しています。data = get_rdataset('AirPassengers', 'datasets').data.valuedataに格納されているのは、以下のようなデータです。0 112 1 118 2 132 3 129 4 121 ... 139 606 140 508 141 461 142 390 143 432 Name: value, Length: 144, dtype: int64
データの差分を計算し、欠損値を削除します。差分を取ることで、データを定常化します。data_diff = data.diff().dropna()
data_diffに格納されているのは、以下のようなデータです。1 6.0 2 14.0 3 -3.0 4 -8.0 5 14.0 ... 139 -16.0 140 -98.0 141 -47.0 142 -71.0 143 42.0 Name: value, Length: 143, dtype: float64
GARCHモデルを定義し学習します。この例では、GARCH(1,1)モデルを使用しています。model = arch_model(data_diff, vol='Garch', p=1, q=1) results = model.fit(disp='off')
予測を行います。この例では、10ステップ先までの分散を予測しています。
forecast = results.forecast(horizon=10)
予測された分散を出力します。
print(forecast.variance.values.T)
[[2851.50488539] [2861.18045699] [2870.85602859] [2880.53160019] [2890.20717178] [2899.88274338] [2909.55831498] [2919.23388658] [2928.90945818] [2938.58502977]]
- ボラティリティモデルとは?
-
ボラティリティモデルとは、時系列データの変動性(ボラティリティ)をモデル化するための統計的手法です。特に金融データにおいて、価格の変動性を予測するために広く使用されます。
以下に代表的なボラティリティモデルをいくつか紹介します。
ARCHモデル(Autoregressive Conditional Heteroskedasticity)
- 1982年にRobert Engleによって提案されたモデル。
- 時系列データの分散が過去の誤差項の大きさに依存することを前提としています。
- 分散が時間とともに変動することを捉えるために使用されます。
GARCHモデル(Generalized ARCH)
- 1986年にTim Bollerslevによって提案されたモデル。
- ARCHモデルを一般化したもので、過去の分散も考慮に入れることで、より柔軟なモデル化が可能です。
- GARCH(p, q)モデルでは、pは過去の分散のラグ数、qは過去の誤差項のラグ数を示します。
EGARCHモデル(Exponential GARCH)
- GARCHモデルの一種で、分散の対数をモデル化することで、非対称なショック(例えば、価格の急激な上昇や下落)を捉えることができます。
TGARCHモデル(Threshold GARCH)
- GARCHモデルの一種で、特定の閾値を超えた場合に異なる分散構造を持つことを許容します。
これらのモデルは、金融市場の価格変動やリスク管理、ポートフォリオの最適化などにおいて重要な役割を果たします。
ボラティリティモデルを使用することで、将来の価格変動の予測やリスク評価が可能となり、投資戦略の策定やリスク管理に役立ちます。
- GARCHモデルとは?
-
GARCHモデル(Generalized Autoregressive Conditional Heteroskedasticityモデル)について説明します。
GARCHモデルは、時系列データの分散(ボラティリティ)が時間とともに変動することを捉えるための統計的手法です。特に金融データにおいて、価格の変動性を予測するために広く使用されます。
GARCHモデルは、ARCHモデル(Autoregressive Conditional Heteroskedasticityモデル)を一般化したもので、過去の分散も考慮に入れることで、より柔軟なモデル化が可能です。
GARCHモデルの基本的なアイデアは、現在の分散が過去の誤差項と過去の分散の線形結合で表されるというものです。具体的には、GARCH(p, q)モデルでは、pは過去の分散のラグ数、qは過去の誤差項のラグ数を示します。
GARCH(1,1)モデルの数式は以下の通りです。
平均方程式
\displaystyle y_t = \mu + \epsilon_tここで、 y_t は時系列データ、 \mu は定数、 \epsilon_t は誤差項です。
分散方程式
\displaystyle \sigma_t^2 = \alpha_0 + \alpha_1 \epsilon_{t-1}^2 + \beta_1 \sigma_{t-1}^2ここで、 \sigma_t^2 は時点tにおける分散、 \alpha_0 、 \alpha_1 、 \beta_1 はモデルのパラメータです。
GARCHモデルの利点は、金融市場の価格変動やリスク管理、ポートフォリオの最適化などにおいて重要な役割を果たすことです。
ボラティリティモデルを使用することで、将来の価格変動の予測やリスク評価が可能となり、投資戦略の策定やリスク管理に役立ちます。
- GARCHモデルの構築手順
-
実際のサンプルデータを使用して、SARIMAXモデルとGARCHモデルを適用する手順を示します。
ここでは、statsmodelsライブラリに含まれているデータセットを使用します。具体的には、日次のS&P500株価データを例に説明します。
- データの読み込みと前処理
- SARIMAXモデルの適用
- 残差の確認とARCH効果の検定
- GARCHモデルの適用
- 条件付き分散のプロット
この手順では、SARIMAXモデルを適用して自己相関と季節性を除去し、残差にGARCHモデルを適用することでボラティリティをモデル化します。
先ずは、必要なライブラリのインポートをします。
以下、コードです。
import pandas as pd import numpy as np import matplotlib.pyplot as plt import pmdarima as pm import statsmodels.api as sm from statsmodels.stats.diagnostic import het_arch from arch import arch_model
1. データの確認と前処理
S&P500のデータを
statsmodelsライブラリから読み込みます。以下、コードです。
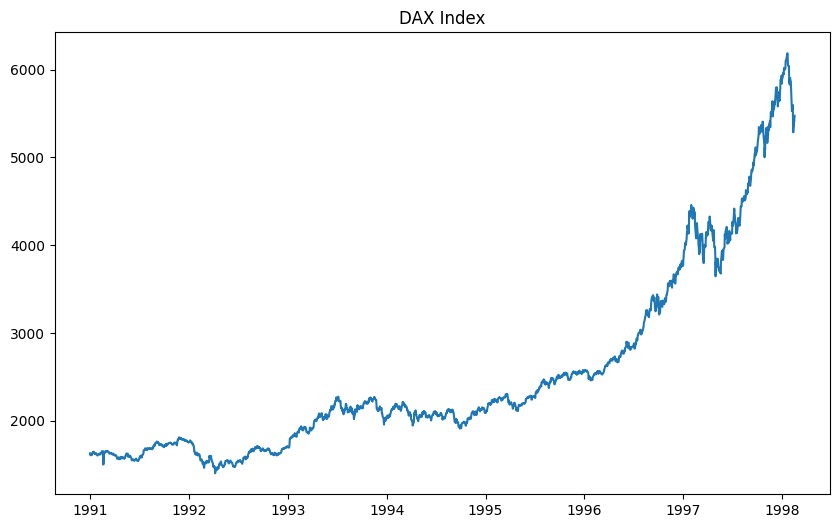
# データの読み込み df = sm.datasets.get_rdataset('EuStockMarkets', 'datasets').data # S&P500のデータを抽出し、インデックスを日付に設定 data = df['DAX'] data.index = pd.date_range(start='1991-01-01', periods=len(data), freq='B') # プロットしてデータを確認 plt.figure(figsize=(10, 6)) plt.plot(data) plt.title('DAX Index') plt.show()以下、実行結果です。
2. SARIMAXモデルの適用
SARIMAXモデル(Seasonal Autoregressive Integrated Moving Average with Exogenous variables)をデータに適用して、自己相関と季節性を除去します。
SARIMAXモデルは、自己相関、移動平均、季節性、および外因性変数を考慮するため、強力な時系列モデルです。
今回は、pmdarimaライブラリの
auto_arimaで自動構築します。以下、コードです。
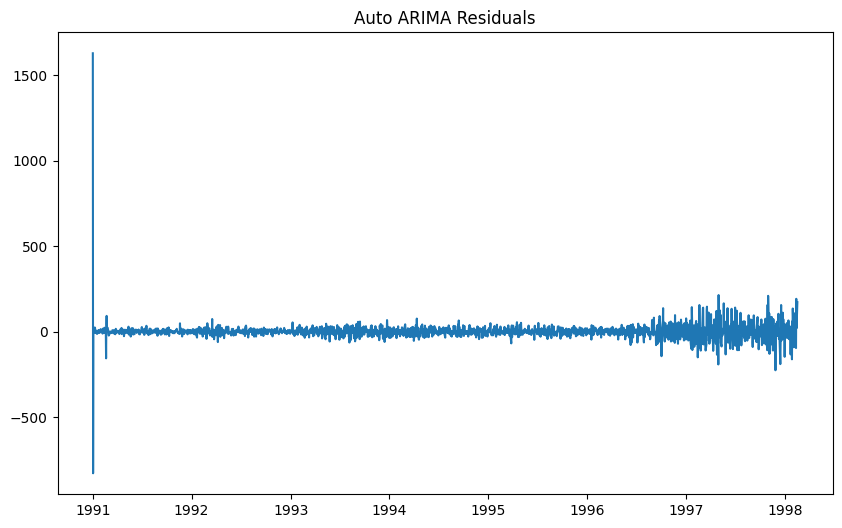
# Auto ARIMA モデルの適用 auto_model = pm.auto_arima( data, seasonal=True, m=12) # フィット結果の要約を表示 auto_model.summary() # 残差の抽出 residuals = auto_model.resid() # 残差のプロット plt.figure(figsize=(10, 6)) plt.plot(residuals) plt.title('Auto ARIMA Residuals') plt.show()以下、実行結果です。
3. 残差の確認とARCH効果の検定
残差に自己相関がないか確認し、ARCH効果があるか検定します。
ARCH効果とは、時系列データにおいて誤差項の分散が時間とともに一定でなく、過去の誤差項の影響を受けて変動する現象を指します。具体的には、ある時点でのデータの変動性(ボラティリティ)が、直前の誤差項の大きさに依存することを意味します。
ARCH検定の結果として得られるp値が小さい場合(一般的に0.05未満)、ARCH効果が存在することが示されます。
以下、コードです。
# ARCH効果の検定 arch_test = het_arch(residuals) print(f'ARCH test p-value: {arch_test[1]}')以下、実行結果です。
ARCH test p-value: 3.010085492535543e-72
4. GARCHモデルの適用
ARCH検定の結果より残差にARCH効果が確認されたので、GARCHモデルを適用します。
以下、コードです。
# GARCH(3,1)モデルのフィッティング garch_model = arch_model(residuals, vol='Garch', p=3, q=1) garch_results = garch_model.fit(disp='off') # 結果の表示 print(garch_results.summary())
以下、実行結果です。
Constant Mean - GARCH Model Results ============================================================================== Dep. Variable: None R-squared: 0.000 Mean Model: Constant Mean Adj. R-squared: 0.000 Vol Model: GARCH Log-Likelihood: -8644.61 Distribution: Normal AIC: 17301.2 Method: Maximum Likelihood BIC: 17334.4 No. Observations: 1860 Date: Wed, Aug 07 2024 Df Residuals: 1859 Time: 03:37:46 Df Model: 1 Mean Model ======================================================================== coef std err t P>|t| 95.0% Conf. Int. ------------------------------------------------------------------------ mu 0.1449 0.421 0.344 0.731 [ -0.681, 0.971] Volatility Model =========================================================================== coef std err t P>|t| 95.0% Conf. Int. --------------------------------------------------------------------------- omega 12.8615 3.746 3.434 5.955e-04 [ 5.520, 20.203] alpha[1] 0.0630 2.863e-02 2.200 2.780e-02 [6.878e-03, 0.119] alpha[2] 0.0362 3.841e-02 0.942 0.346 [-3.909e-02, 0.111] alpha[3] 0.0503 3.207e-02 1.569 0.117 [-1.252e-02, 0.113] beta[1] 0.8366 1.895e-02 44.148 0.000 [ 0.799, 0.874] =========================================================================== Covariance estimator: robust5. 条件付き分散のプロット
条件付き分散のプロットは、GARCHモデルがどのようにボラティリティ(変動率)を捉えているかを視覚的に示すものです。
以下、コードです。
# 条件付き分散のプロット plt.figure(figsize=(10, 6)) plt.plot(garch_results.conditional_volatility) plt.title('Conditional Volatility from GARCH Model') plt.show()以下、実行結果です。
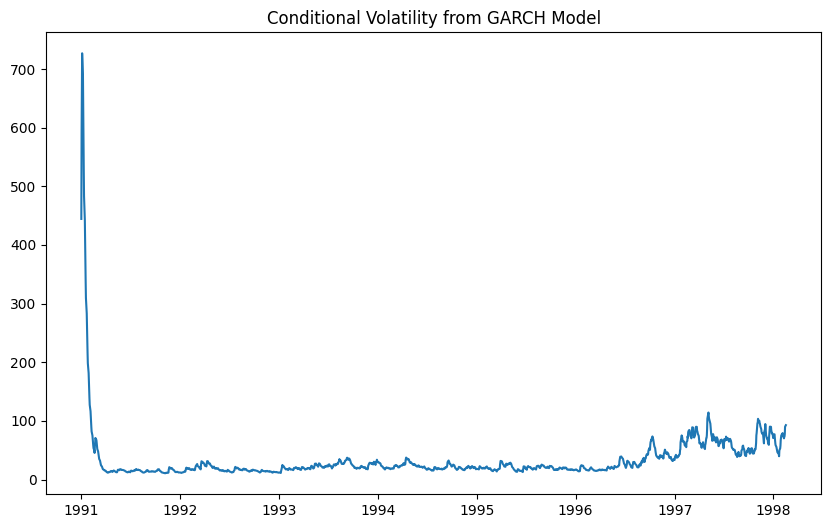
この条件付き分散のプロットを解釈します。初期の高いスパイク
- 1991年初頭に非常に高いスパイクが見られます。
- この期間は非常に高いボラティリティを示しており、市場に大きな変動があったことを示しています。
- これは、大規模な市場イベントやショックがあった可能性を示唆しています。
- その後、ボラティリティは急速に低下し、1991年後半から1992年にかけて安定しています。
安定した期間
- 1992年から1996年にかけて、条件付き分散は比較的低く、安定したボラティリティを示しています。
- この期間は市場が比較的静かで、安定していたことを示しています。
- ボラティリティの小さな変動は見られますが、大きなスパイクはほとんどありません。
ボラティリティの増加
- 1996年以降、条件付き分散が徐々に増加していることが見られます。
- 特に1997年から1998年にかけて、ボラティリティが明らかに増加しています。
- 1997年後半から1998年にかけて、いくつかのスパイクが見られます。
- これは市場の不安定さが増し、ボラティリティが高まったことを示しています。
まとめると以下のとなります。
- 1991年初頭: 非常に高いボラティリティが観察される。市場に大きな変動があった。
- 1992年から1996年: ボラティリティは低く、安定していた。
- 1996年以降: ボラティリティが徐々に増加し、特に1997年から1998年にかけて大きな変動が見られる。
このプロットは、GARCHモデルがデータのボラティリティのクラスタリングと時間的な変動をうまく捉えていることを示しています。
プロットを詳細に分析することで、市場の動向や重要なイベントの影響をより深く理解することができます。