

sktimeはPythonでよく使われている機械学習ライブラリsklearn(scikit-learn)と同じインターフェースで提供されているPythonの時系列ライブラリです。
sktimeでは2022.7.4時点で時系列の4つの時系列機械学習の問題を解くことができます。
| 問題名 | データの種類 | 内容 |
| 1. 時系列予測 Forecasting |
目的変数のみの時系列データ | 過去の時系列データが与えられたときの将来の予測です。 |
| 2. 時系列クラスタリング Time Series Clustering |
特徴量(説明変数)のみの時系列データ | 複数の時系列データを、いくつかの類似のグループに分けます。 |
| 3. 時系列分類 Time Series Classification |
目的変数と特徴量(説明変数)のある時系列データ | 特徴量と目的変数が与えられた分類問題のうち、特徴量に時間的もしくはデータの順番に意味があるときに使います。sktimeでは二値分類および多値分類に対応しています。 |
| 4. 時系列回帰 Time Series Regression |
特徴量と目的変数が与えられたとき、目的変数が時系列かつ連続データであるときの目的変数の予測です。 |
このsktimeを使うためには、sktimeをPythonにインストールし呼び出さなければなりません。
前回は、sktimeによる時系列予測(Forecasting)について説明しました。
Python ライブラリー「sktime」で学ぶ らくらくビジネス時系列機械学習 Web講座 – 第3回:時系列予測 –
今回は時系列クラスタリングの方法を説明します。複数の時系列データをいくつかの類似グループに分ける問題です。教師データはありません。
- 時系列予測 ⇒ 前回
- 時系列クラスタリング ⇒ 今回
- 時系列分類
- 時系列回帰
Contents
事前準備
まずはJupyter Notebookを開いておきます。
次のコマンドで必要なモジュールをインポートします。
from sktime.datasets import load_arrow_head from sklearn.model_selection import train_test_split from sktime.clustering.k_means import TimeSeriesKMeans import matplotlib.pyplot as plt
各関数は次の用途で使われます
| 関数(ライブラリ) | 用途 |
| load_arrow_head(sktime) | 今回使うデータセットです。矢じりの輪郭情報を時系列データとして取り扱ったものです。 |
| train_test_split(sklearn) | データを分割する関数です。もとは学習用と検証用に分けるものですが、今回は学習用と予測用に分けるために使います。 |
| TimeSeriesKMeans(sktime) | sktimeの時系列データに対するクラスタリングのアルゴリズム、k-means法です。 |
| pyplot(matplotlib) | データをプロットするためのモジュールです。 |
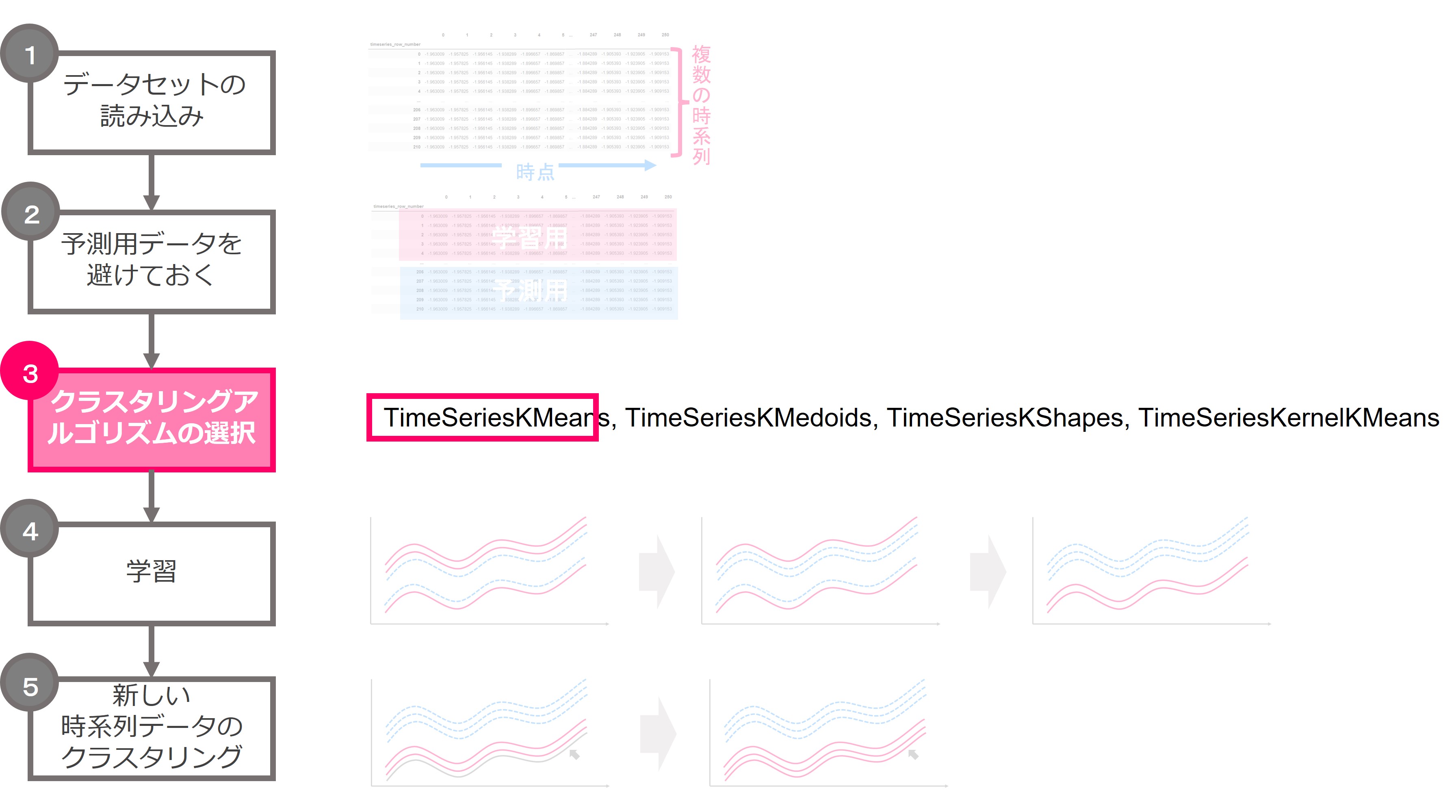
クラスタリングの流れ
クラスタリングの流れです。データセットを読み込み、予測用データを準備、学習用データで学習し予測するというシンプルな流れです。

では、それぞれについて説明していきます。
1.データセットの読み込み
まずはデータセットを読み込みます。今回はsktime.datasetsに用意されているload_arrow_headというデータセットを使います。これは矢じりの形を分類したデータセットです。

このデータセットは、複数の矢じりの輪郭を角度法(Angle Based Method)という画像処理の手法で計測点と位置の情報に分解して特徴量としています。矢じりは0,1,2の3つの種類が存在しますのでそれを目的変数(Class)としています。
ただし、今回はクラスタリングですので目的変数は使いません。特徴量Xは計測点と位置で、計測点を時間、位置を観測値とみなして時系列データとして取り扱います。
次のコマンドでデータセットを読み込みます。
X,y = load_arrow_head()
次のコマンドでXにデータが格納されていることを確認します。
X
実行結果です。
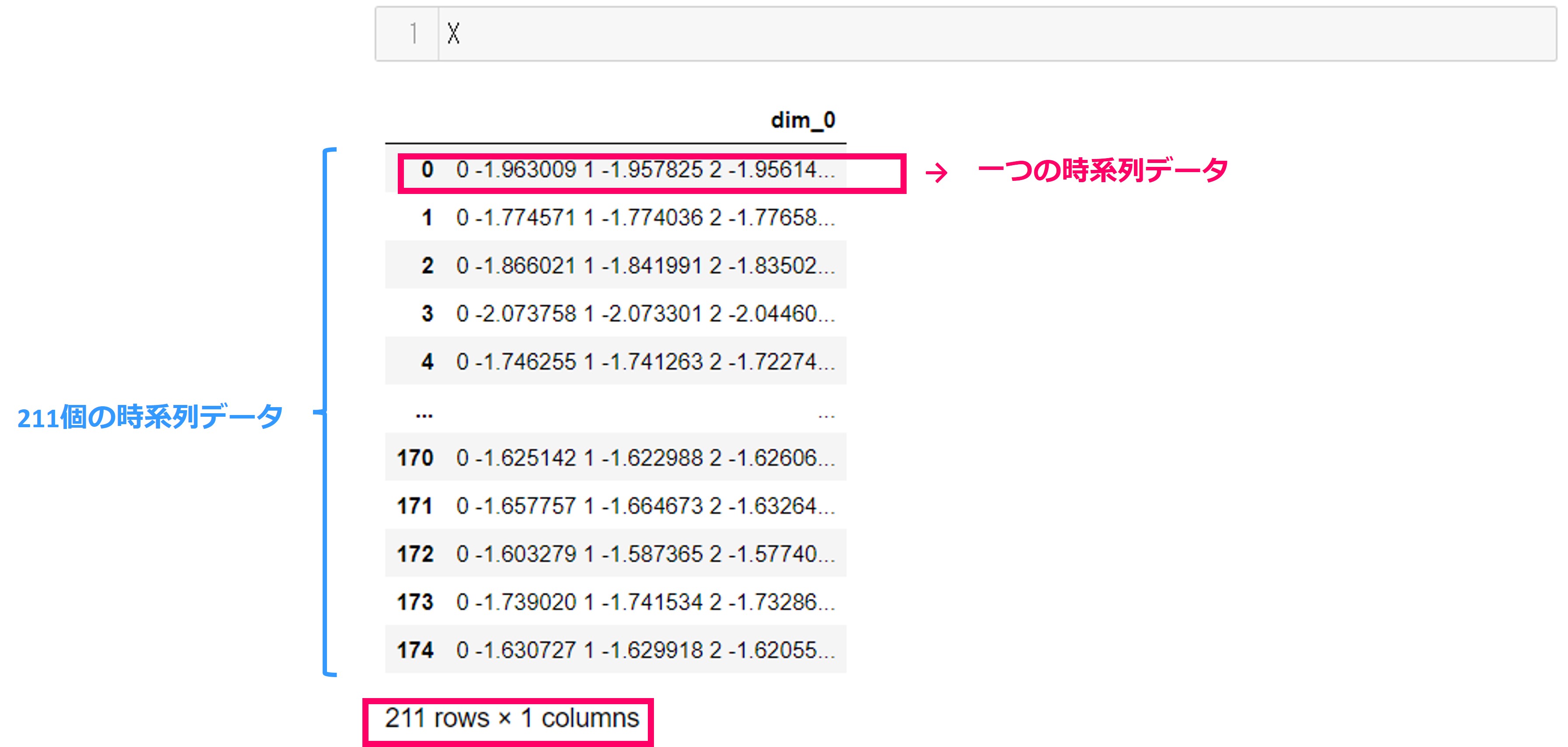
211行×1列のデータフレームです。このデータはPandasのDataFrame形式の中にPandasのSeries形式の時系列データが各行に格納されています。
つまり、211の時系列データを取得しました。矢じりのデータなので、211個の矢じりの情報が格納されていることが分かります。
ここで、データの構造が普通のデータフレームとは異なることにお気づきでしょうか。
特徴量Xの最初の1~3行目を見てみます。それぞれの行は1つのセルだけで、それぞれのセルに複数の値が0,1,2,…と採番されて格納されていることがわかります。
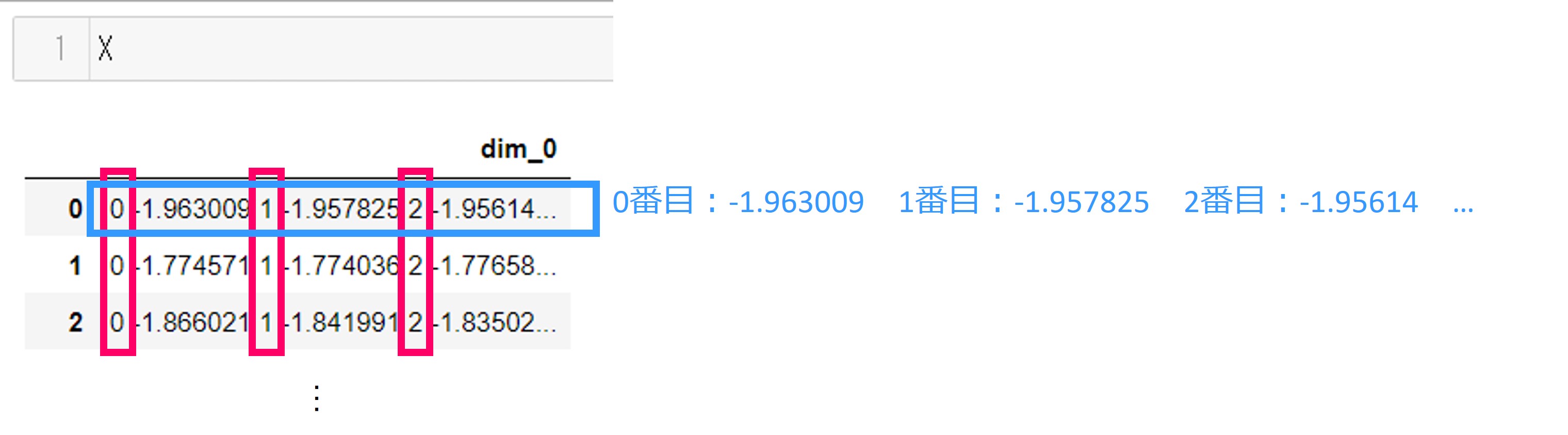
これは、データフレーム(pandas.DataFrame)の中にシリーズ(pandas.Series)が入れ子になっていることを示します。
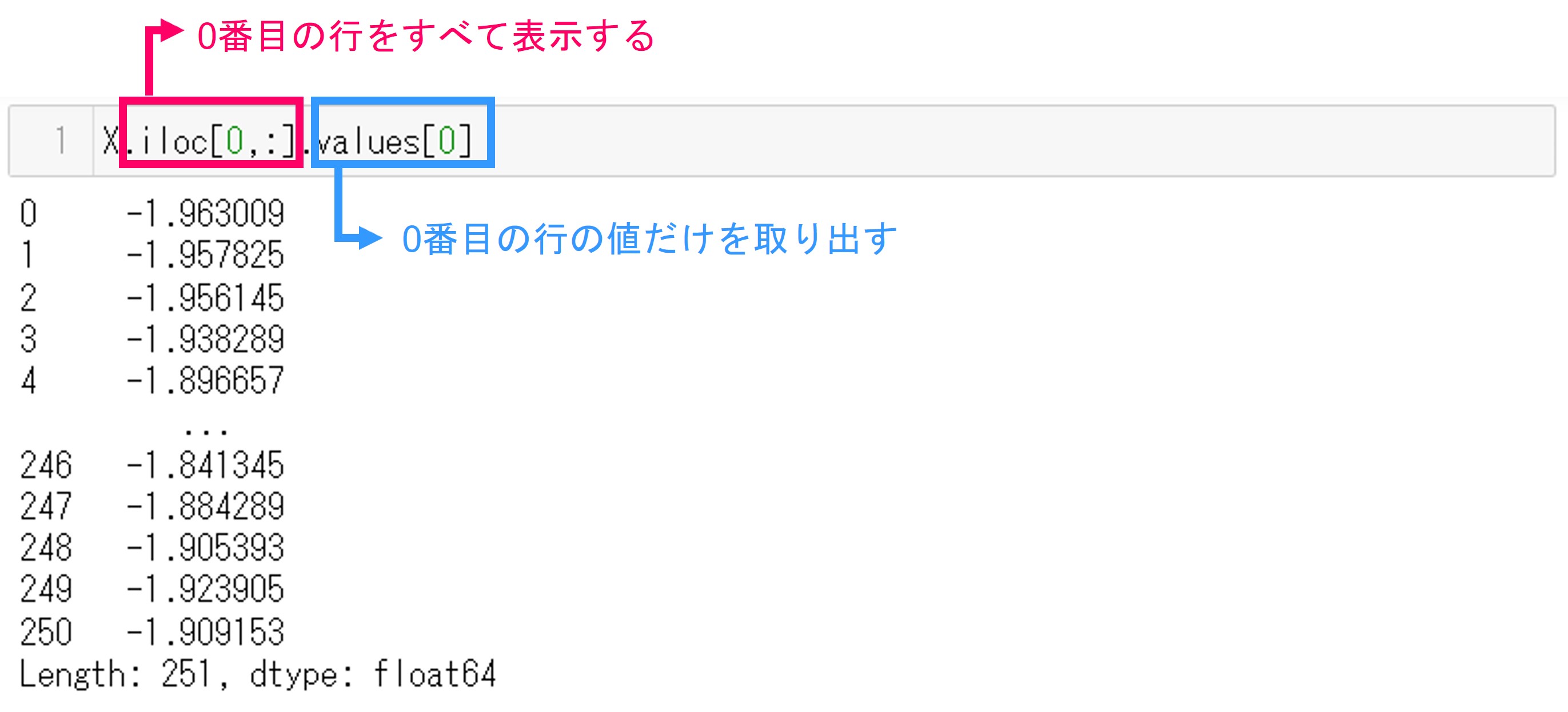
1行目のセルからシリーズとして格納されている時系列データを抜き出してみます。コマンドです。
X.iloc[0,:].values[0]
コマンドの説明です。
ilocコマンドはデータフレームの行と列を指定してデータを表示します。今回はインデックス0の列をすべて(:)表示します。さらに見やすいように値だけを.values[0]コマンドで表示させます。そうするとpandas.Series形式で表示されます。
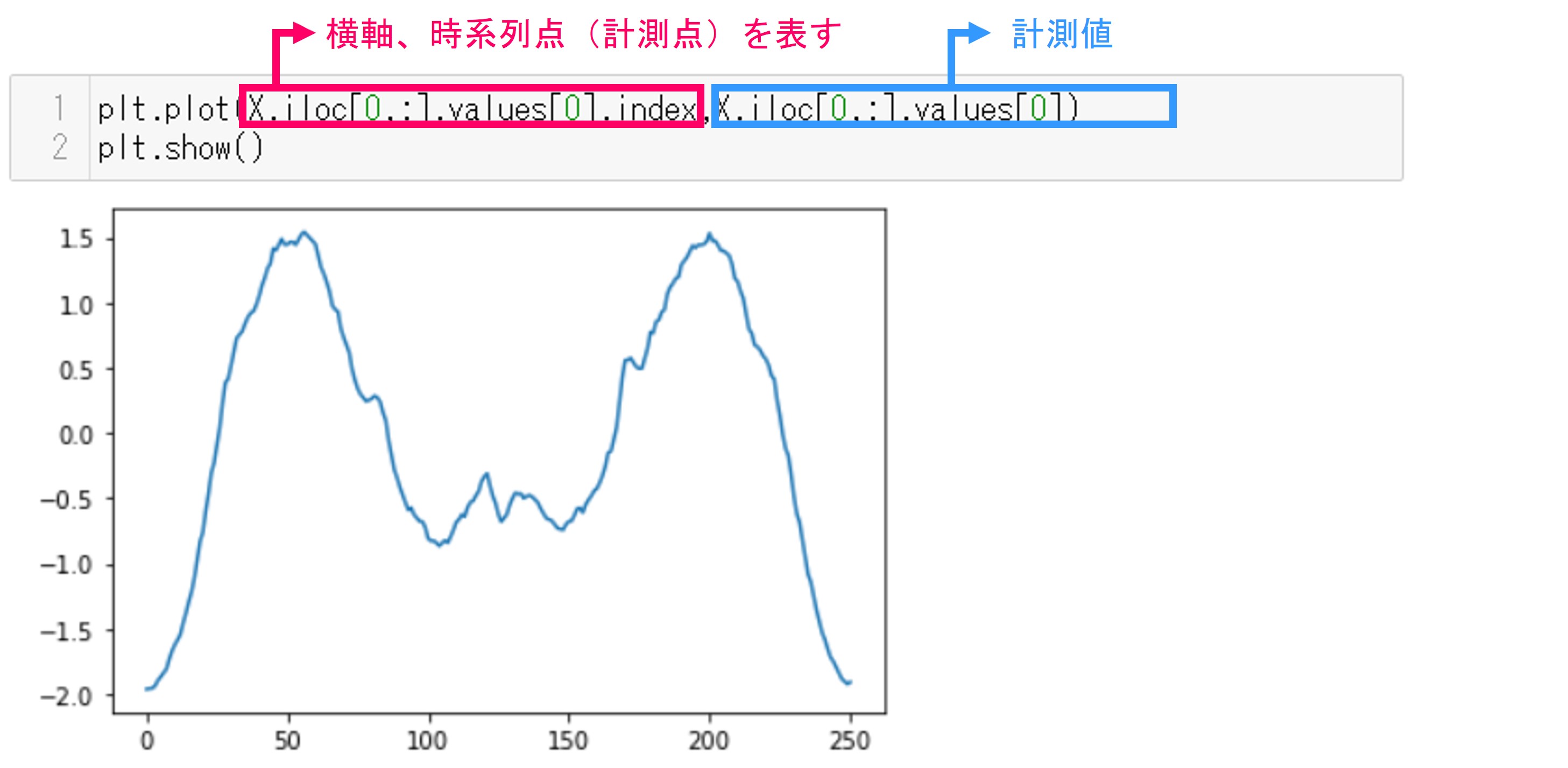
さらに今回のデータをプロットしてみましょう。matplotlibのpyplotを使います。
plt.plot(X.iloc[0,:].values[0].index,X.iloc[0,:].values[0]) plt.show()
実行結果です。横軸が計測点(時間と考える)を表し、縦軸が値です。
このような、sktimeのためのデータの作り方は別の回で説明します。
次に目的変数yの中身も見てみましょう。コマンドです。
y
実行結果です。矢じりの種類が0,1,2で表されていることがわかります。

ただし、今回は目的変数yを使いません。目的変数の情報を使うことなく、時系列データであるXだけでクラスタリングします。
2.予測用データを避けておく
次に、読み込んだデータから学習用と予測用に分けておきます。
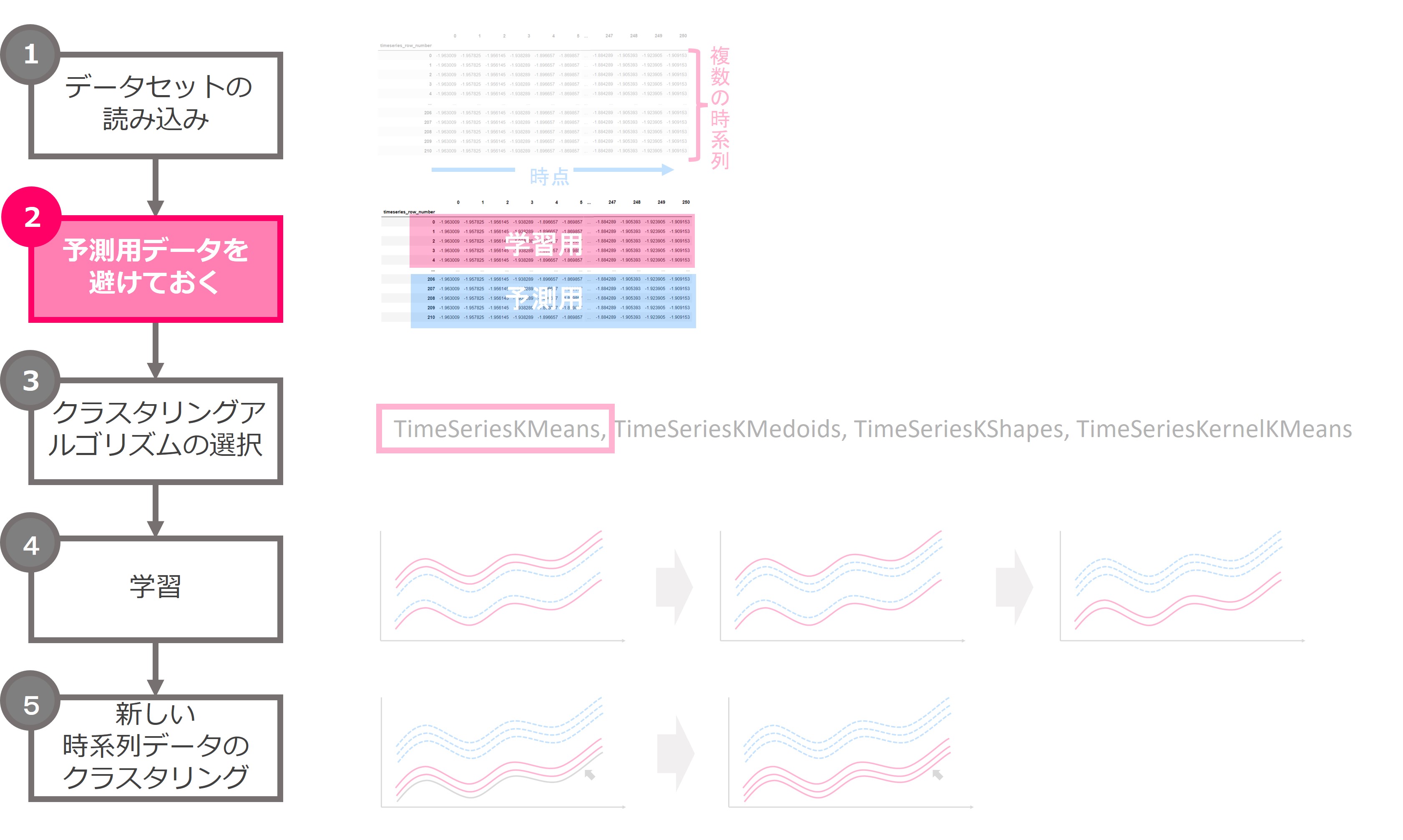
今回は複数の時系列データがあり、その複数の時系列データをランダムに抽出しても良いので、scikit-learnのtrain_test_splitを使います。25%を予測用とします。
X_train,X_pred = train_test_split(X, test_size=0.25)
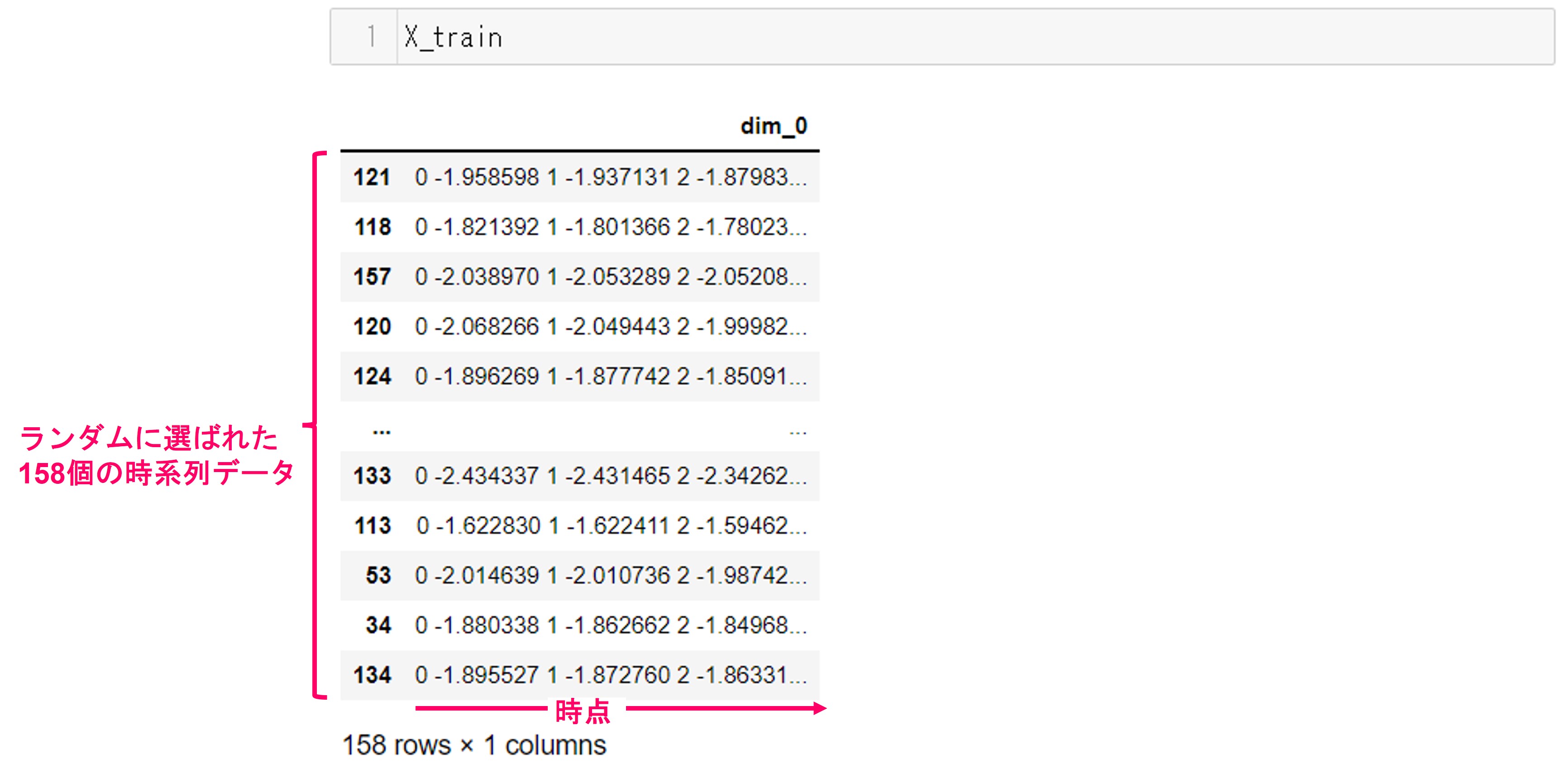
学習用データの中身を見てみましょう。コマンドです
X_train
実行結果です。もとの時系列データが211個あり、そのうち約75%の158個が学習用データとしてランダムに選ばれました。
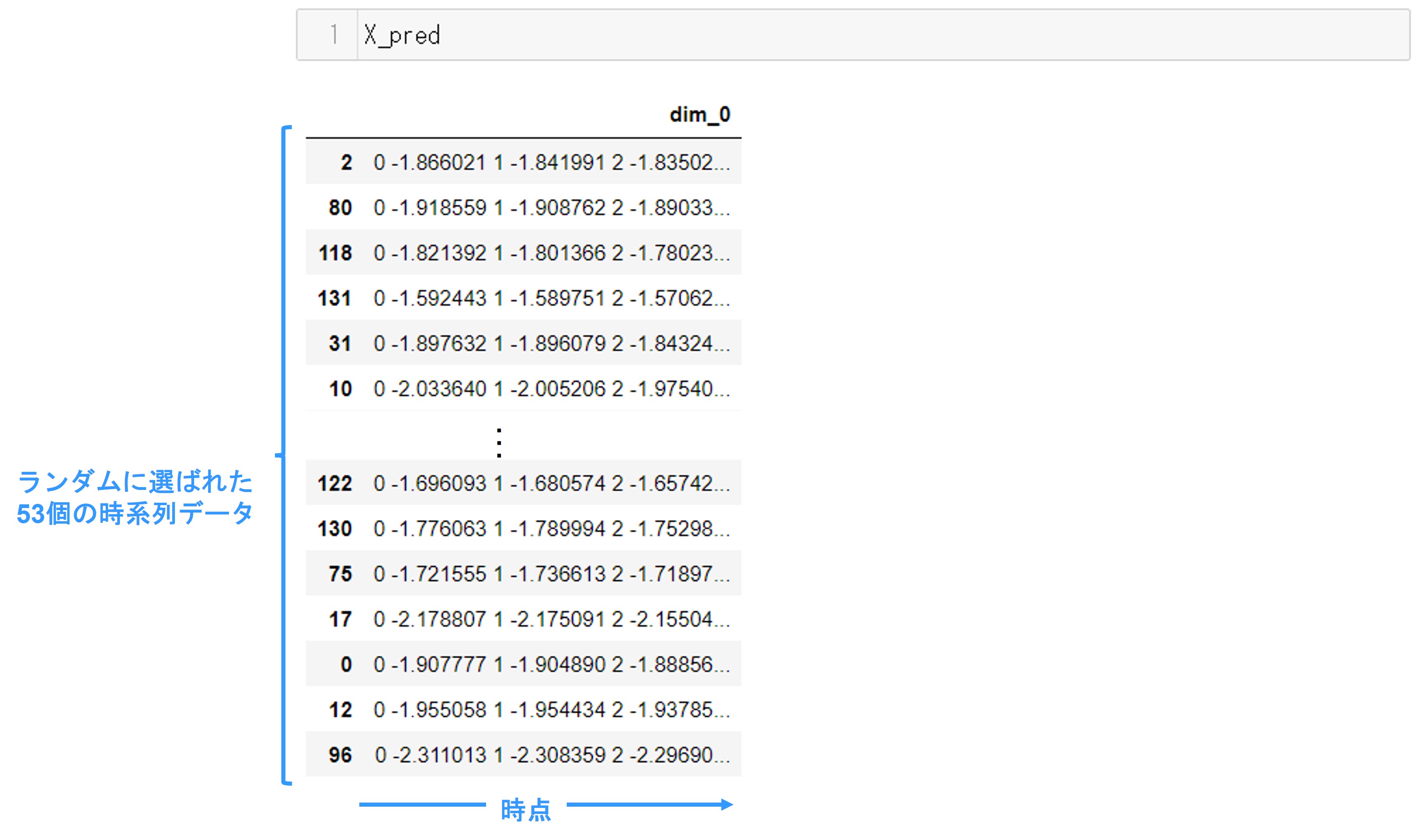
予測用データは次のコマンドで確認できます。
X_pred
実行結果です。学習用データを除いた残り約25%、53個の時系列データが格納されています。
このあとは、X_trainでクラスタリングして、X_predのクラスタ予測をするという流れになります。
3.クラスタリングアルゴリズムの選択
次はクラスタリングに使うアルゴリズムを選択します。
アルゴリズムの一覧です。各アルゴリズムの詳細は別の回で紹介します。
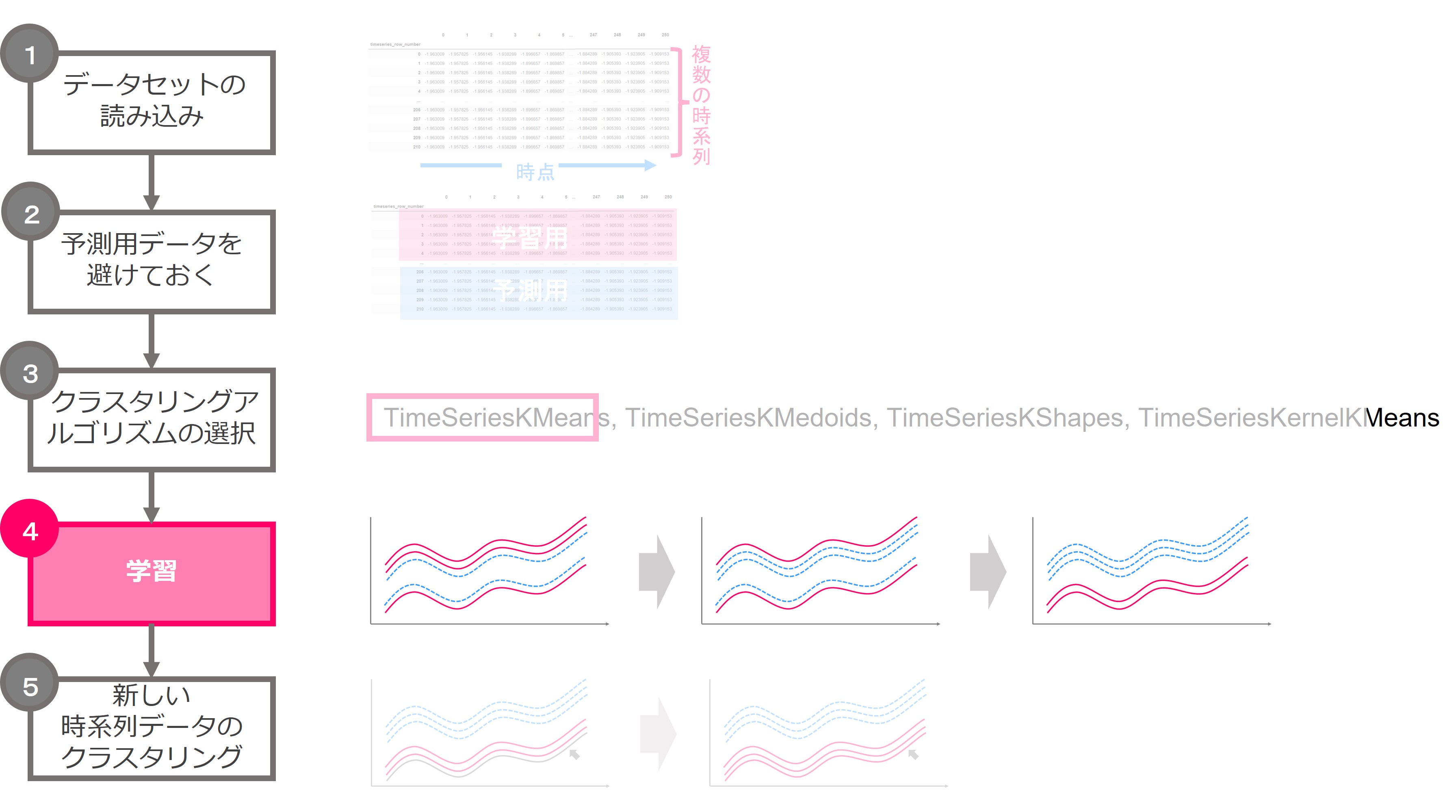
今回はTimeSeriesKMeansを使うことにします。TimeSeriesKMeansとは、その名のとおり時系列データに対するk-means法です。
時系列k-means法のアルゴリズムは次の手順で行われます。
- クラスタ数を決める
- クラスタリングの対象となる時系列データをランダムにクラスタに割り当てる
- 割り付けられたクラスタで、時系列点ごとにクラスタ中心を計算する。時系列点ごとのクラスタ中心の集まりが時系列データのクラスタ中心となる
- 時系列データとクラスタ中心の距離を計算し、近いクラスタに再度割り当てる
- 3~4を繰り返す
参考文献:Time Series Clustering and Classification (Champman & Hall/Computer Science & Data Analysis)
では、TimeSeriesKMeansのインスタンスを生成します。
model = TimeSeriesKMeans(verbose = True, random_state=123)
ランダムシードrandom_stateと、学習の様子を出力するverboseを設定してます。引数verboseをTrueに設定すると学習の様子が出力されます。ハイパーパラメータはすべて初期値を使います。クラスタ数は初期値では8です。
modelの中身を見てみましょう。
model
実行結果です。TimeSeriesKMeansが設定されていることがわかります。

次のセクションで、学習をします。
4.学習
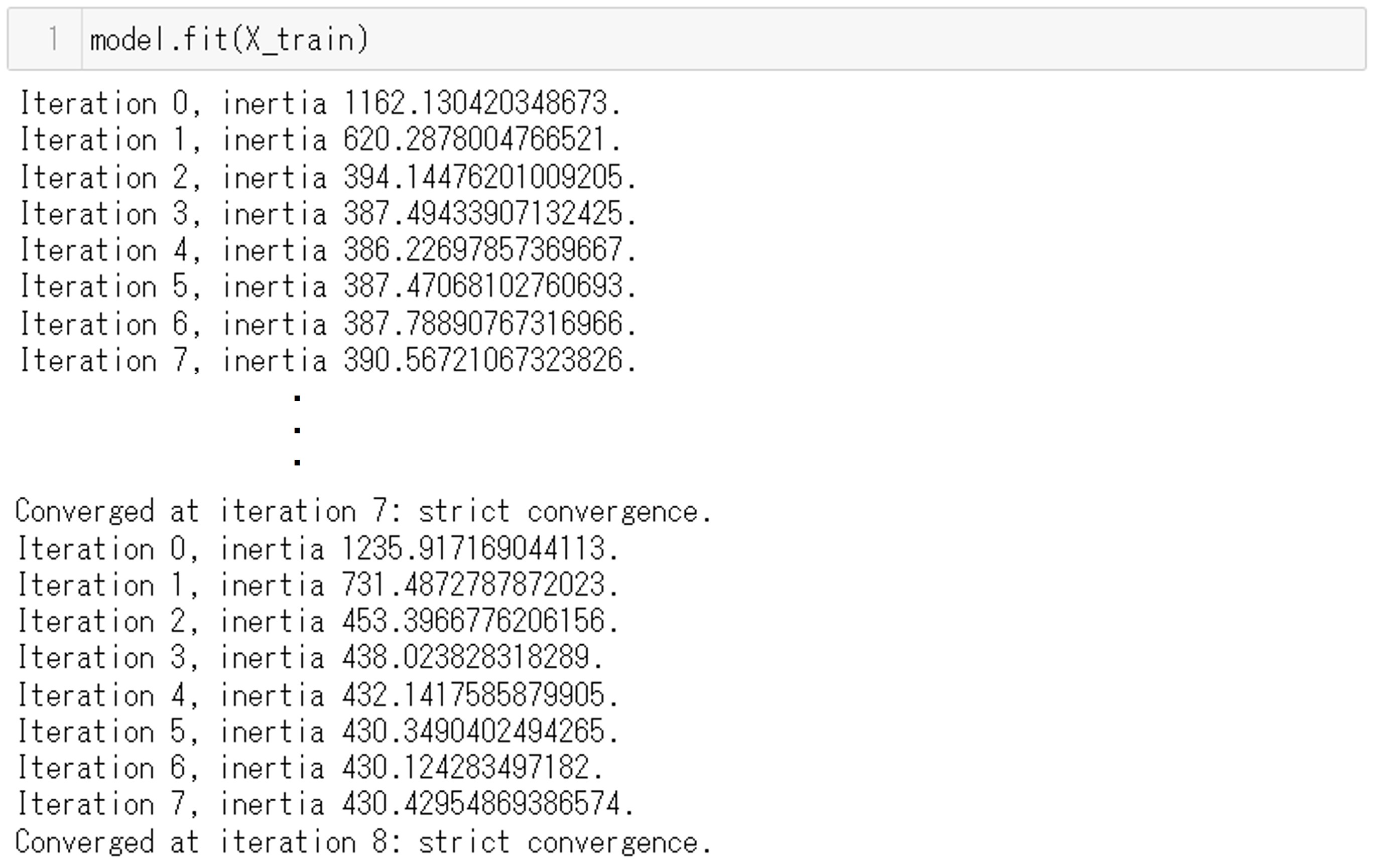
コマンドです。学習データX_trainを使って、先ほどアルゴリズムを設定した変数modelのfit関数で学習します。
model.fit(X_Train)
実行結果です。試行の数Iterationと属するクラスタ中心からの距離の二乗誤差の合計inertiaが出力されています。繰り返し(Iteration)が進むにつれて、inertiaが変化しているのがわかります。
学習が終わりました。属性(Attribute)で学習結果のパラメータをいくつか確認することができます。属性はいくつか存在します。
- inertia_ … クラスタ中心からの距離の二乗の合計。これか小さくなるようにクラスタ中心が決まる。
- labels_ … 学習に使ったそれぞれの時系列データの属するクラスタ
- cluster_centers_ … 各クラスタのクラスタ中心。時系列データで表される。
- n_iter_ … 学習の繰り返しの回数
それぞれの属性値を見てみましょう。まずはinertia_です。コマンドです。
model.inertia_
実行結果です。

例えば、クラスタの数を変えていってこのinertia_の値を見て、最もinertia_が小さくなるクラスタを選ぶというエルボー法というクラスタ数決定の方法があります。実際は分析の目的に応じて選ぶことになります。
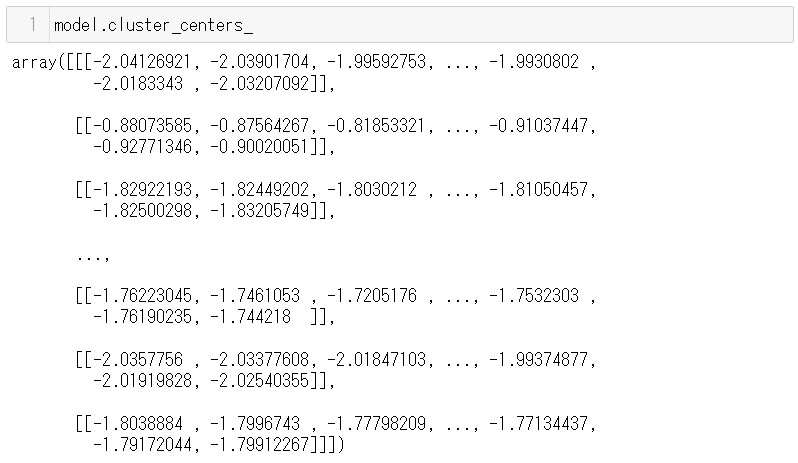
次にクラスタ中心です。コマンドです。
model.cluster_centers_
実行結果です。こちらは8行×251列の配列となっています。行数がクラスタ数(今回は指定していないので初期値の8)、列数が時系列データのデータ数です。
for c in range(8):
x = model.cluster_centers_[c][0] # c番目のクラスタ中心(時系列データ)
plt.plot(x) # プロット
plt.title('{}-th cluster'.format(c))
plt.show()
実行結果です。8つのクラスタ中心はこのようになっています。
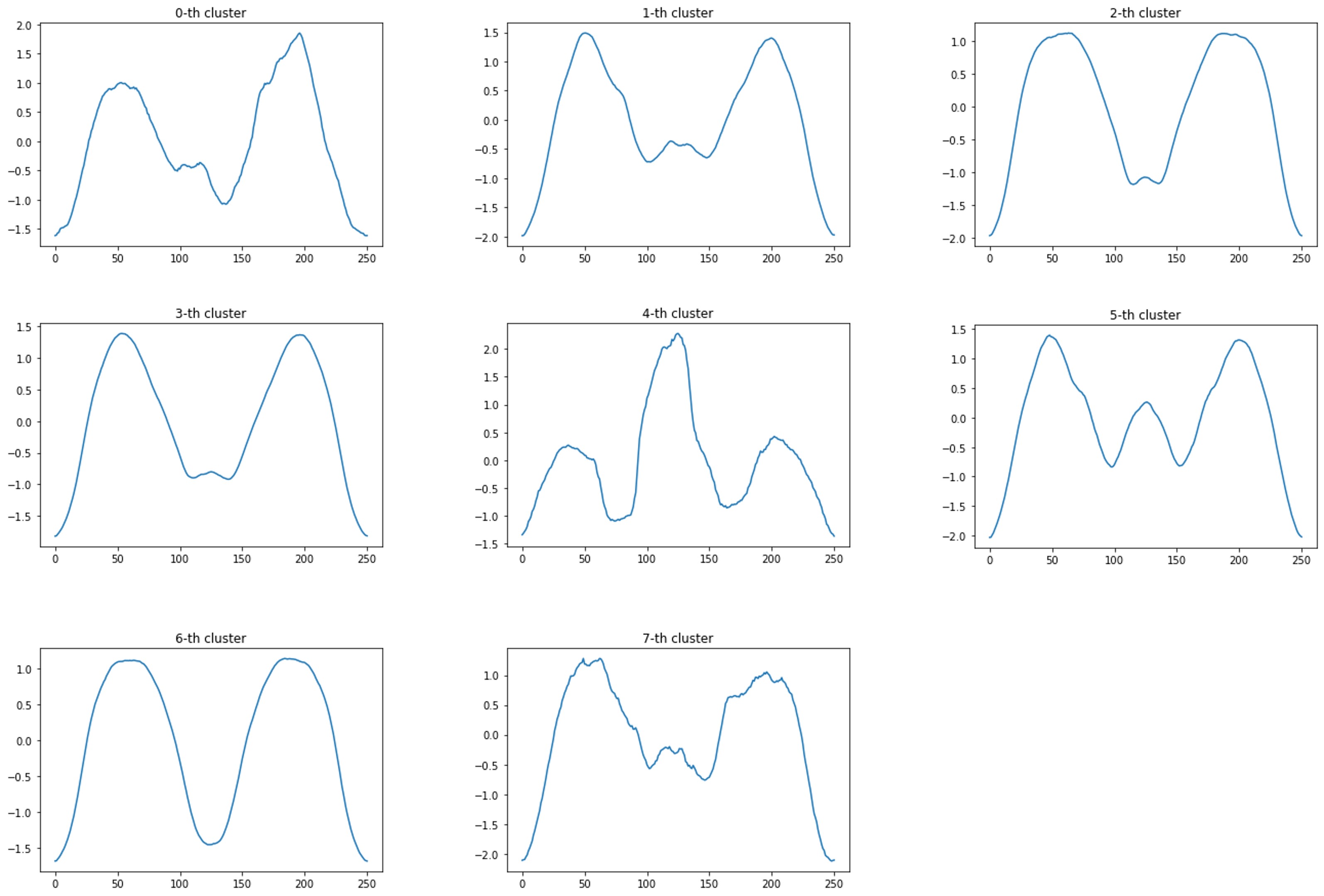
labels_も見てみます。コマンドです。
model.labels_
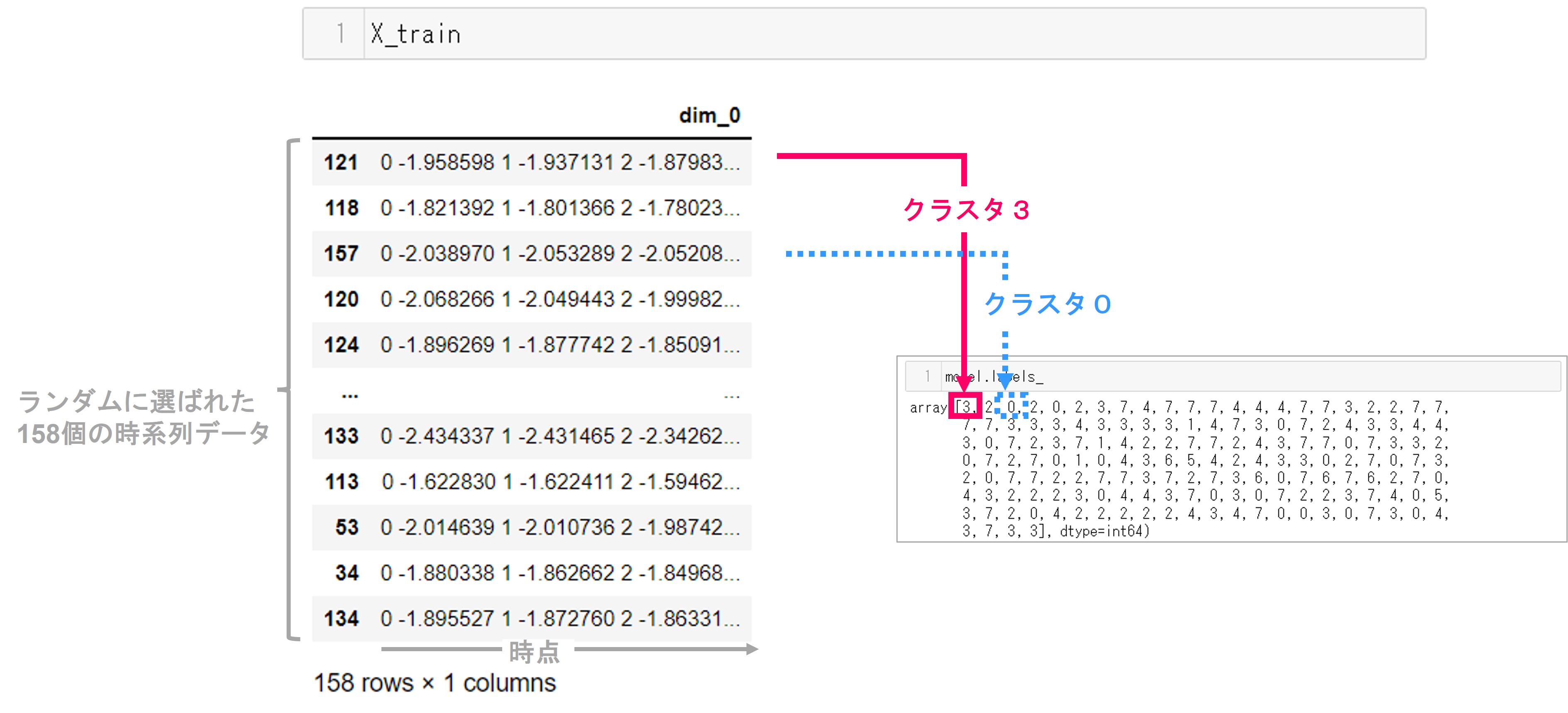
実行結果です。

こちらは158個の配列で、学習に使った158個の時系列データがどのクラスタに属するかを表したものです。
学習データX_trainとの対応をとると次のようになります。
試行回数も見てみましょう。コマンドです。
model.n_iter_
実行結果です。今回は300回試行しました。

5.新しい時系列データのクラスタリング
最後に、セクション2で避けておいた予測データで予測をします。

予測はかんたんです。
次のコマンドで、学習済のモデルを使って予測します。学習済となったモデル(model)に予測用のデータX_predを投入して、予測します。
model.predict(X_pred)
実行結果です。

予測用データとの対応は次のようになります。
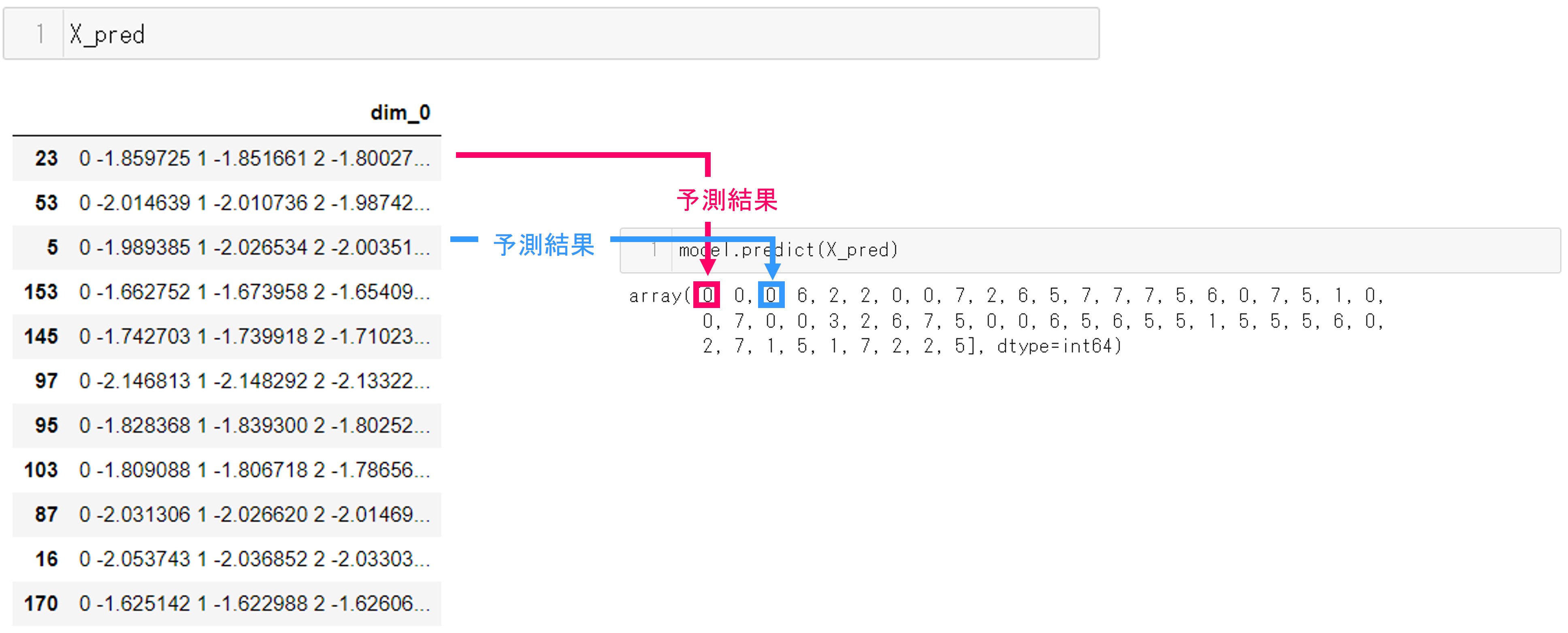
それぞれのクラスタに分類された時系列データと、クラスタ中心をプロットしてみることにします(ソースコードの説明は割愛します)。
cluster_list=list(range(8))
cluster_pred = model.predict(X_pred)
colors = ['tab:blue','tab:orange','tab:green','tab:red','tab:purple','tab:brown','tab:pink','tab:olive']
for c in cluster_list:
cluster_list = list(range(0,8))
x_preds = X_pred.reset_index(drop=True).iloc[cluster_pred==c]
plt.figure(figsize=(15,3))
for i in range(len(x_preds)):
plt.plot(x_preds.values[i][0], c=colors[c], alpha=0.2)
plt.plot(model.cluster_centers_[c][0], c='k')
plt.title('{}-th cluster'.format(c))
plt.show()
実行結果です。
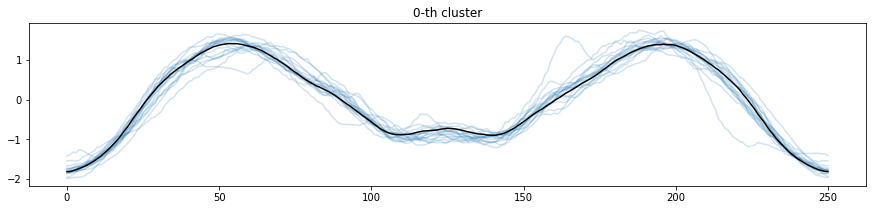
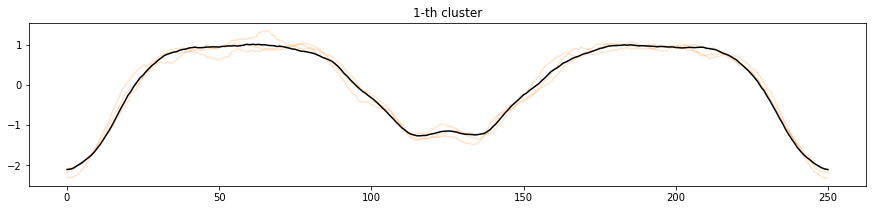
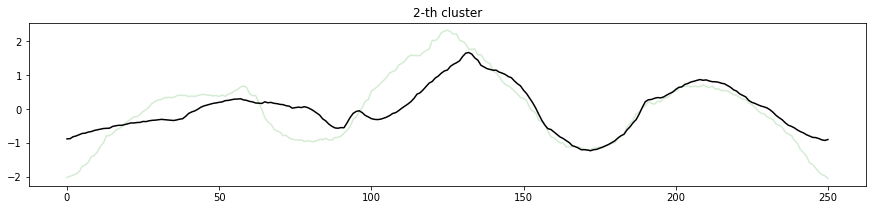
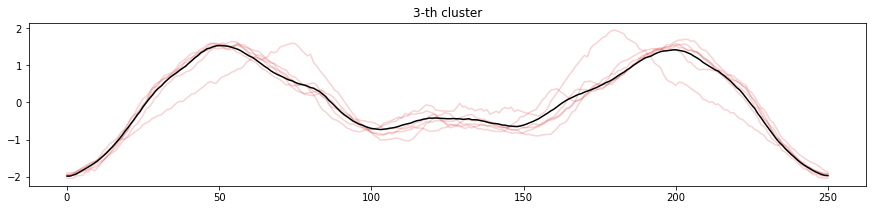
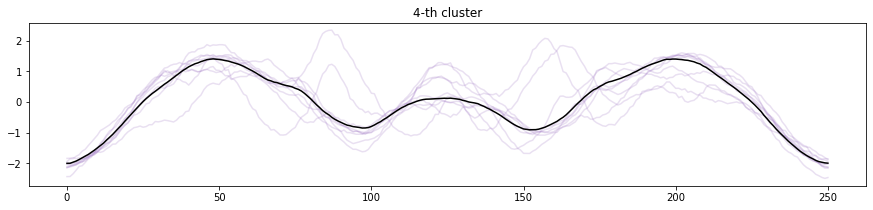

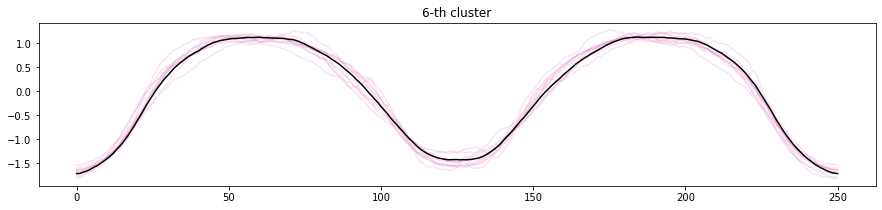

各時系列データを分類されたクラスタで色分けし、それぞれのクラスタ中心を黒いラインで表現しています。0番目、1番目、5番目、6番目はクラスタに分類されたそれぞれの時系列とクラスタ中心の形が似ていることがわかります。
2番目、3番目、4番目、7番目はややクラスタ中心からずれている時系列データが見られます。クラスタに分類しきれていなかったり、少ないデータ量しか分類されていない場合は、クラスタ数を変更することを検討しても良いでしょう。
ソースコード全体
今回使ったソースコードの全体像です。
#
# 必要なモジュールのインポート
#
from sktime.datasets import load_arrow_head
from sklearn.model_selection import train_test_split
from sktime.clustering.k_means import TimeSeriesKMeans
import matplotlib.pyplot as plt
#
# 1.データセットの読み込み
#
X,y = load_arrow_head()
X
X.iloc[0,:].values[0]
plt.plot(X.iloc[0,:].values[0].index,X.iloc[0,:].values[0])
plt.show()
y
#
# 2.予測用データを避けておく
#
X_train,X_pred = train_test_split(X, test_size=0.25)
X_train
X_pred
#
# 3.クラスタリングアルゴリズムの選択
#
model = TimeSeriesKMeans(verbose = True, random_state=123)
model
#
# 4.学習
#
model.fit(X_train)
model.inertia_
model.cluster_centers_
for c in range(8):
x = model.cluster_centers_[c][0] # c番目のクラスタ中心(時系列データ)
plt.plot(x) # プロット
plt.title('{}-th cluster'.format(c))
plt.show()
model.labels_
model.n_iter_
#
# 5.新しい時系列データのクラスタリング
#
model.predict(X_pred)
# ここからクラスタ予測の描画
cluster_list=list(range(8))
cluster_pred = model.predict(X_pred)
colors = ['tab:blue','tab:orange','tab:green','tab:red','tab:purple','tab:brown','tab:pink','tab:olive']
for c in cluster_list:
cluster_list = list(range(0,8))
x_preds = X_pred.reset_index(drop=True).iloc[cluster_pred==c]
plt.figure(figsize=(15,3))
for i in range(len(x_preds)):
plt.plot(x_preds.values[i][0], c=colors[c], alpha=0.2)
plt.plot(model.cluster_centers_[c][0], c='k')
plt.title('{}-th cluster'.format(c))
plt.show()
まとめ
今回は時系列クラスタリングの方法を説明しました。複数の時系列データをいくつかの類似グループに分ける問題です。教師データはありません。
前回と次回は、時系列予測と時系列クラスタリングの簡単な実行例を通し、sktimeの使い方の流れの一例を説明してきました。
より複雑もしくは難易度の高い時系列モデルを構築するには、sktimeで取り扱うデータの種類(scitype)の概要を理解しておく必要があります。
sktimeで取り扱うデータの種類(scitype)には3つあります。
- 1. 時系列データ(Series)
- 2. パネル時系列データ(Panel)
- 3. 階層時系列(Hierarchical)
次回は、sktimeで使うデータの構造について説明します。
Python ライブラリー「sktime」で学ぶ らくらくビジネス時系列機械学習 Web講座 – 第5回:sktimeのデータ構造 –
データ構造を飛ばし時系列分類については知りたい方は、以下からお願いします。
Python ライブラリー「sktime」で学ぶ らくらくビジネス時系列機械学習 Web講座 – 第8回:時系列分類 –