時系列データ分析は、特定の期間における変化を捉え、将来の動向を予測するための重要な手法です。 前回の記事では、mlforecastライブラリを使用して基本的な時系列予測モデルを構築する方法と、モデル性能を向上させるための...
データの海に潜む異彩の輝き、それが「外れ値」です。 多くの人がノイズとして見過ごしがちなこの存在こそ、実はデータ分析における貴重な宝石なのです。 ビッグデータ時代の今だからこそ注目すべき外れ値の重要性と、それを見つけ出す...
データ分析や機械学習などで、カテゴリ変数の扱いに頭を悩ませていませんか? 特に、高カーディナリティ(カテゴリの種類が多い状態)に直面すると、どうすればいいか分からなくなってしまいますよね。 でも大丈夫! 今回は、高カーデ...
データ分析における効率性と柔軟性は、高品質なインサイトを生み出す鍵です。 PythonのPandasライブラリはその強力な味方となりますが、その中でも特にapply関数とlambda式の組み合わせは、データサイエンスの作...
機械学習モデルを構築する際、利用可能なデータセットを学習データとテストデータに分割することが一般的です。 学習データはモデルの訓練に使用され、モデルがデータからパターンを学ぶためのものです。 一方、テストデータはモデルが...
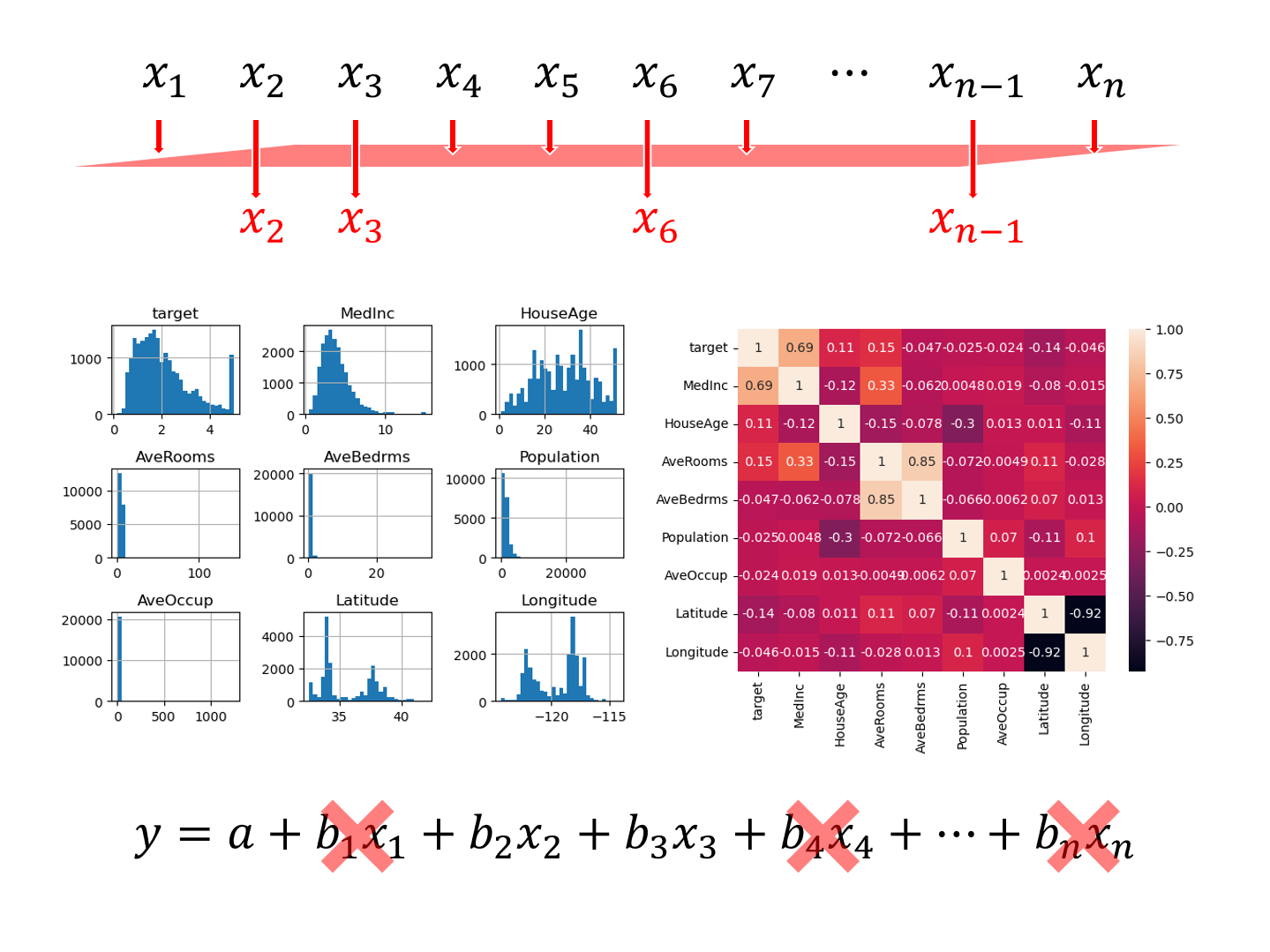
特徴量選択(変数選択)は、機械学習系の予測モデルなどを構築するとき、最初に行う重要なステップの1つです。 予測に寄与しない特徴量(説明変数)を取り除くことで、よりシンプルな予測モデルを構築を目指します。 色々な考え方や手...
売上などのビジネス系のデータの多くは、時間概念が紐付いた時系列データです。 時間概念を取っ払ったテーブルデータと異なり、時系列データは、過去の値に大きく依存する、という特徴があります。 そのため、一工夫必要になります。例...
Pythonに幾つかの自動特徴量エンジニアリング(Automatic Feature Engineering)のためのパッケージがあります。 その中の1つに「AutoFeat」というものがあります。回帰問題と分類問題で利...
数理モデルを作る上で特徴量エンジニアリング(Feature Engineering)は地味に重要です。 例えば、より精度の高い予測モデルを構築したいのであれば、アルゴリズムのパラメータチューニングとともに特徴量エンジニア...
数理モデルを作る上で特徴量エンジニアリング(Feature Engineering)は地味に重要です。 例えば、より精度の高い予測モデルを構築したいのであれば、アルゴリズムのパラメータチューニングとともに特徴量エンジニア...