

売上などのビジネス系のデータの多くは、時間概念が紐付いた時系列データです。
時間概念を取っ払ったテーブルデータと異なり、時系列データは、過去の値に大きく依存する、という特徴があります。
そのため、一工夫必要になります。例えば、予測モデルなどを構築するときです。
予測モデルなどを構築するとき、特徴量(説明変数)エンジニアリングは非常に重要です。適切な特徴量(説明変数)を作ることができれば、予測精度も解釈性も非常に向上します。
特徴量(説明変数)エンジニアリングとは、機械学習アルゴリズムを用いて構築した予測モデルの精度を高めるために、ドメイン知識(業界や現場の知識など)を用いて関連する特徴量(説明変数)を作成するプロセスの1つです。
今回は、「時系列データの5種類の特徴量(説明変数)」というお話しをします。
5種類の主な特徴量(説明変数)

以下、時系列データで予測モデルなどを構築するときに用いる、5種類の主な特徴量(説明変数)です。
- ドメイン固有特徴量
- カレンダー特徴量
- ラグ特徴量
- ローリング特徴量
- エクスパンディング特徴量
ドメイン固有特徴量

予測モデルを活用する業界や現場のプロフェッショナルの方の知識を、ドメイン知識と言います。現場に近いと言うか、現場にいる方が非常にいいです。
優れたドメイン知識は、ドメイン固有の特徴量を設計することができます。
現場の方と、予測モデルを構築するデータサイエンティストや機械学習エンジニアの方の、二人三脚が求められます。
ドメイン知識由来の特徴量(説明変数)は非常に重要ですが、このことはテーブルデータの予測モデルでも同様です。
時系列データ特有の特徴量(説明変数)としては、他の時系列データとの関連性などがあります。
例えば、雨が降ると小売店の売上が落ちる、寒い夏はビールの売上が下がる、などです。
大きく、先行指標特徴量(目的変数Yの変化の前に変化する他の特徴量など)や一致指標特徴量(目的変数Yとともに変化する他の特徴量など)などです。
ドメイン固有特徴量の作り方には、現場からの仮説をもとにデータで確認することもありますし、逆にデータから傾向をあぶり出して現場で確認してもらうケースもあります。
- 仮説ドリブンな特徴量作り
- データドリブンな特徴量作り
ドメイン固有特徴量以外でも、この考え方は共通します。最後は、現場やデータサイエンティストなど人が解釈し納得のいく特徴量を作ることが重要になります。
カレンダー特徴量

時系列データは、平日、週末、休日、季節、四半期、月の始まり、年の始まり、年の終わりなど、様々なカレンダー情報が紐付いています。
もう少し粒度の細かい時系列データ(例:時、分、秒など)であれば、午前、午後、昼、朝、夕方など一日のサイクル情報も重要になることでしょう。
このようなカレンダーや一日のサイクルなどに関する特徴量(説明変数)は、予測モデルの精度を高める上で、大きく寄与することがあります。
ラグ特徴量
例えば、t期の売上を予測したい場合、前月すなわちt-1期の売上を特徴量として使用したり、前々月すなわちt-2期の売上を特徴量として使用することがあります。
t-1期の売上やt-2期の売上をラグ特徴量と言います。
ラグ特徴量は、目的変数Yの値さえあれば作成できるのが特徴です。この特徴量(説明変数)だけでそれなりの予測精度のモデルを構築できることがあります。
どのくらいのラグ(どのくらい過去の目的変数Yを説明変数として使うのか)がいいのかを、ACF(自己相関関数、Autocorrelation)やPACF(偏自己相関関数、Partial Autocorrelation)などを出力し、検討したりします。
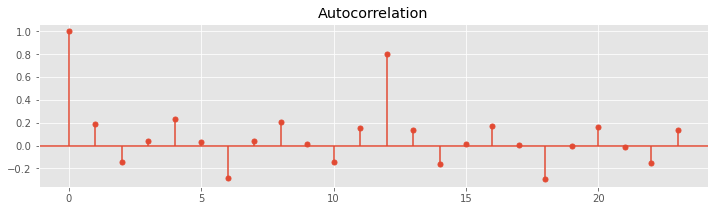
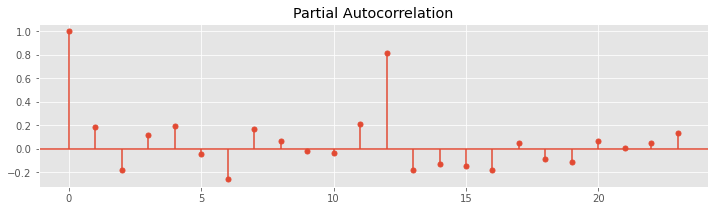
ローリング特徴量

ローリング特徴量とは、過去の一定期間(Rolling Window)の集計値を特徴量(説明変数)としたものです。
例えば、月単位の時系列データ。
t期の目的変数Yの特徴量として、過去3ヶ月間の目的変数Yの平均値や最大値、最小値、標準偏差などを特徴量(説明変数)とすることです。もちろん、目的変数Y以外の時系列データの過去3ヶ月間の平均値や最大値、最小値、標準偏差などでも構いません。
例えば、日単位の時系列データ。
t期の目的変数Yの特徴量として、過去1周間の目的変数Yや他の時系列データの平均値や最大値、最小値、標準偏差などを特徴量(説明変数)とすることです。
単純な集計ではなく、変化量などでも構いません。過去1周間とさらにその過去1周間の平均値などの比などです。
ローリング特徴量は、1つの期間(例:過去3ヶ月、過去1周間など)だけでなく、過去3ヶ月・過去半年・過去1年間など、複数の期間を定めて作ることが多いです。
エクスパンディング特徴量

エクスパンディング特徴量とは、過去すべての期間(Expanding Window)の集計値を特徴量(説明変数)としたものです。
ローリング特徴量と似ていますが、集計対象となる過去の期間が異なります。エクスパンディング特徴量は過去全期間で、ローリング特徴量は決められた一定期間です。
今回のまとめ
今回は、「時系列データの5種類の特徴量(説明変数)」というお話しをします。
売上などのビジネス系のデータの多くは、時間概念が紐付いた時系列データです。
時間概念を取っ払ったテーブルデータと異なり、時系列データは、過去の値に大きく依存する、という特徴があります。そのため、一工夫必要になります。例えば、予測モデルなどを構築するときです。
予測モデルなどを構築するとき、特徴量(説明変数)エンジニアリングは非常に重要です。適切な特徴量(説明変数)を作ることができれば、予測精度も解釈性も非常に向上します。
以下、時系列データで予測モデルなどを構築するときに用いる、5種類の主な特徴量(説明変数)です。
- ドメイン固有特徴量
- カレンダー特徴量
- ラグ特徴量
- ローリング特徴量
- エクスパンディング特徴量
時系列データで予測モデルなどを構築するときに参考にして頂ければと思います。