
前回の記事では、curve_fit() を使ってデータにフィッティング(曲線あてはめ)を行う方法を紹介しました。
フィッティングがデータの「全体の傾向」をつかむ技術だとすれば、今回紹介する「補間(ほかん)」 は、データの 「隙間を埋める」 技術です。
データ分析の現場では、センサーの不具合やシステム障害などで、一部のデータが欠損していることがよくあります。
こうしたデータの穴を、周囲のデータから推測して埋めるのが補間の役割です。
今回は、SciPyの scipy.interpolate モジュールに含まれる interp1d 関数を使って、欠損データを補間する方法を、できるだけ簡単に解説します。
Contents
補間とは?
ひとことで言うと
補間(interpolation) とは、既知のデータ点の「間」にある未知の値を、周囲のデータから推測して求めることです。
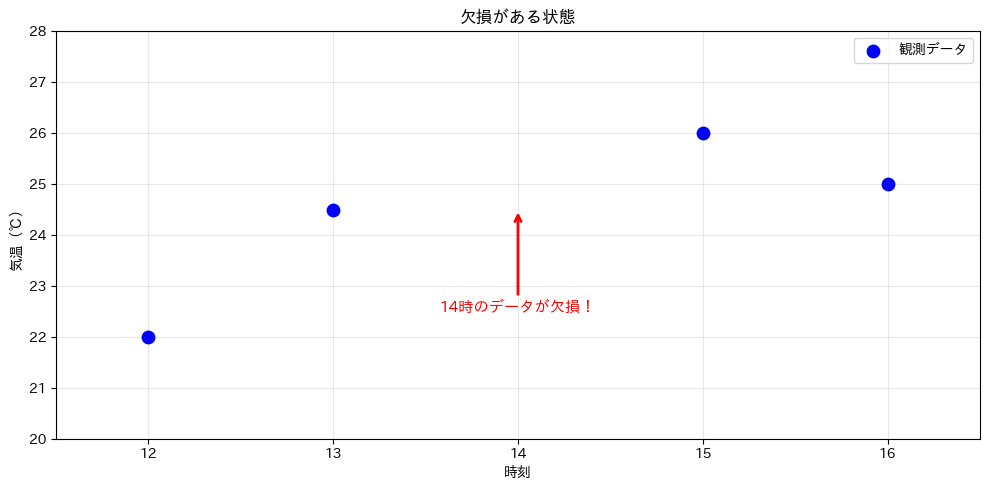
たとえば、ある都市の1時間ごとの気温データがあったとします。しかし、14時のデータだけが欠損していました。
| 時刻 | 12時 | 13時 | 14時 | 15時 | |
|---|---|---|---|---|---|
| 気温(℃) | 22.0 | 24.5 | ??? | 26.0 | 25.0 |
13時が24.5℃、15時が26.0℃なので、14時はその間あたりの値(約25.3℃くらい)ではないかと推測できます。これが補間の基本的な考え方です。
補間のイメージをグラフで確認してみましょう。
まず、欠損のあるデータを作り、表示します。
以下、コードです。
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
# データ準備:時刻と気温(14時のデータは欠損)
hours = np.array([12, 13, 15, 16]) # 観測がある時刻(14時は欠損)
temps = np.array([22.0, 24.5, 26.0, 25.0]) # 各時刻の気温データ
# 図と軸を用意
fig, ax = plt.subplots(figsize=(10, 5))
# 観測済みのデータ点を散布図で描画
ax.scatter(
hours, # x座標(時刻)
temps, # y座標(気温)
color='blue', # 青色で表示
s=80, # 点のサイズ
zorder=5,
label='観測データ'
)
# 欠損している14時を×印で示す(位置の目安としてNaNを指定)
ax.scatter(
[14], # x座標(14時)
[np.nan], # y座標(欠損値)
color='red', # 赤色で強調
s=100, # ×印のサイズ
marker='x', # ×印
zorder=5
)
# 欠損の注釈(矢印付きで説明テキストを追加)
ax.annotate(
'14時のデータが欠損!', # 注釈テキスト
xy=(14, 24.5), # 注釈の対象位置
fontsize=11, # フォントサイズ
color='red', # 赤色で強調
ha='center', # 水平方向の配置(中央揃え)
arrowprops=dict(
arrowstyle='->', # 矢印の形状
lw=2, # 線の太さ
color='red' # 矢印の色
), # 矢印のスタイル
xytext=(14, 22.5) # テキストの表示位置
)
# 軸ラベルや表示範囲などの体裁を調整
ax.set_title('欠損がある状態')
ax.set_xlabel('時刻')
ax.set_ylabel('気温(℃)')
ax.set_xlim(11.5, 16.5)
ax.set_ylim(20, 28)
ax.legend()
ax.grid(True, alpha=0.3)
# レイアウトを整えて表示
plt.tight_layout()
plt.show()
以下、実行結果です。
欠損の個所に簡単な補間処理を実施します。
以下、コードです。
# 14時の補間値(仮に線形補間で推測)
hour_missing = 14 # 欠損している時刻を指定
# 13時と15時の値から線形補間で14時の気温を計算(線形補間の公式)
temp_interpolated = 24.5 + (26.0 - 24.5) * (14 - 13) / (15 - 13)
# 描画用の図と軸を作成
fig, ax = plt.subplots(figsize=(10, 8)) # 図のサイズを指定
# 観測データの散布図を描画
ax.scatter(
hours, # x座標(時刻)
temps, # y座標(気温)
color='blue', # 点の色
s=80, # 点の大きさ
zorder=5, # 前面に表示
label='観測データ' # 凡例用ラベル
)
# 補間した14時の点を赤いひし形で描画
ax.scatter(
[hour_missing], # x座標(14時)
[temp_interpolated], # y座標(補間値)
color='red', # 点の色
s=100, # 点の大きさ
marker='D', # ひし形マーカー
zorder=5, # 前面に表示
label=f'補間値({temp_interpolated:.1f}℃)' # 凡例用ラベル
)
# 補間点を含む折れ線(12〜16時)を描画
ax.plot(
[12, 13, 14, 15, 16], # xの並び(12〜16時)
[22.0, 24.5, temp_interpolated, 26.0, 25.0],# yの並び(補間値を含む)
color='gray', # 線の色
linestyle='--', # 破線
alpha=0.5 # 透明度
)
# 体裁設定(タイトル・軸ラベル・範囲・凡例・グリッド)
ax.set_title('補間後') # タイトル
ax.set_xlabel('時刻') # x軸ラベル
ax.set_ylabel('気温(℃)') # y軸ラベル
ax.set_xlim(11.5, 16.5) # x軸の表示範囲
ax.set_ylim(20, 28) # y軸の表示範囲
ax.legend() # 凡例を表示
ax.grid(True, alpha=0.3) # グリッドを薄めに表示
plt.tight_layout() # 余白の自動調整
plt.show() # 図を表示
以下、実行結果です。

interp1d とは?
interp1d(インターポレーション・ワンディー)は、SciPyの scipy.interpolate モジュールに含まれる 1次元データの補間関数です。
名前の意味を分解すると、以下のようになります。
- interp = interpolation(補間)
- 1d = 1 dimension(1次元)
つまり、「1次元のデータ(xとyの組)を補間する関数」です。
以下、コードです。
import numpy as np
from scipy.interpolate import interp1d
# 既知のデータ点
x = np.array([0, 1, 2, 3, 4, 5])
y = np.array([0, 2, 1, 3, 2, 4])
# 補間関数を作成(線形補間)
f = interp1d(x, y)
# 補間関数を使って、データ点の間の値を求める
x_new = 2.5
y_new = f(x_new)
print(f"x = {x_new} のときの補間値:y = {y_new}")
from scipy.interpolate import interp1d:SciPyのinterpolateモジュールからinterp1dを読み込みますx = np.array([0, 1, 2, 3, 4, 5]):既知のデータ点のx座標(横軸)ですy = np.array([0, 2, 1, 3, 2, 4]):既知のデータ点のy座標(縦軸)ですf = interp1d(x, y):xとyのデータを渡して 補間関数fを作成します。このfは、新しい関数として使えるようになりますy_new = f(x_new):作成した補間関数fに新しいxの値を渡すと、補間されたyの値が返されます
以下、実行結果です。
x = 2.5 のときの補間値:y = 2.0
x = 2 のとき y = 1、x = 3 のとき y = 3 なので、その中間の x = 2.5 では y = 2.0 と推測されました。
複数の点を一度に補間する
補間関数には、1つの値だけでなく配列を渡すこともできます。
以下、コードです。
import numpy as np
from scipy.interpolate import interp1d
x = np.array([0, 1, 2, 3, 4, 5])
y = np.array([0, 2, 1, 3, 2, 4])
f = interp1d(x, y)
# 複数の点を一度に補間
x_new = np.array([0.5, 1.5, 2.5, 3.5, 4.5])
y_new = f(x_new)
for xi, yi in zip(x_new, y_new):
print(f" x = {xi:.1f} → y = {yi:.2f}")
以下、実行結果です。
x = 0.5 → y = 1.00 x = 1.5 → y = 1.50 x = 2.5 → y = 2.00 x = 3.5 → y = 2.50 x = 4.5 → y = 3.00
補間の種類:線形補間とスプライン補間
interp1d では、補間の方法(kind)を指定することができます。主に使う2つの方法を紹介します。
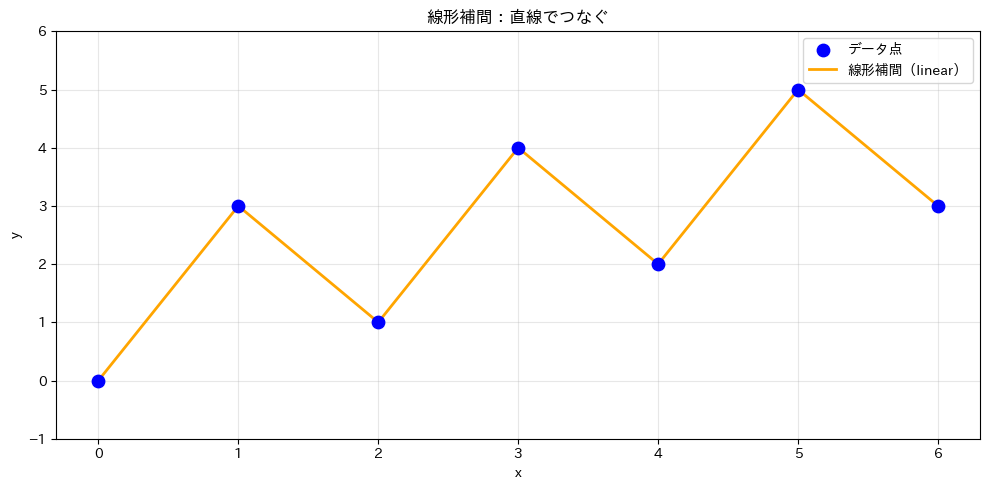
① 線形補間(linear)
線形補間 は、隣り合うデータ点を直線で結ぶ最もシンプルな方法です。interp1d のデフォルト設定です。
メリットとして計算が速くシンプルで理解しやすい点があります。デメリットはデータ点の接続部分がカクカクする(滑らかでない)点です。
以下、コードです。
# 既知のデータ点
x = np.array([0, 1, 2, 3, 4, 5, 6])
y = np.array([0, 3, 1, 4, 2, 5, 3])
# 細かいx座標(補間結果を滑らかに描画するため)
x_dense = np.linspace(0, 6, 300)
# 線形補間の関数を作成
f_linear = interp1d(x, y, kind='linear')
# 描画用の図と軸を作成
fig, ax = plt.subplots(figsize=(8, 5))
# データ点
ax.scatter(
x, # x座標
y, # y座標
color='blue',
s=80,
zorder=5,
label='データ点'
)
# 線形補間の曲線
ax.plot(
x_dense, # x座標
f_linear(x_dense), # y座標
color='orange',
linewidth=2,
label='線形補間(linear)'
)
ax.set_title('線形補間:直線でつなぐ')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.legend()
ax.grid(True, alpha=0.3)
ax.set_ylim(-1, 6)
plt.tight_layout()
plt.show()
以下、実行結果です。
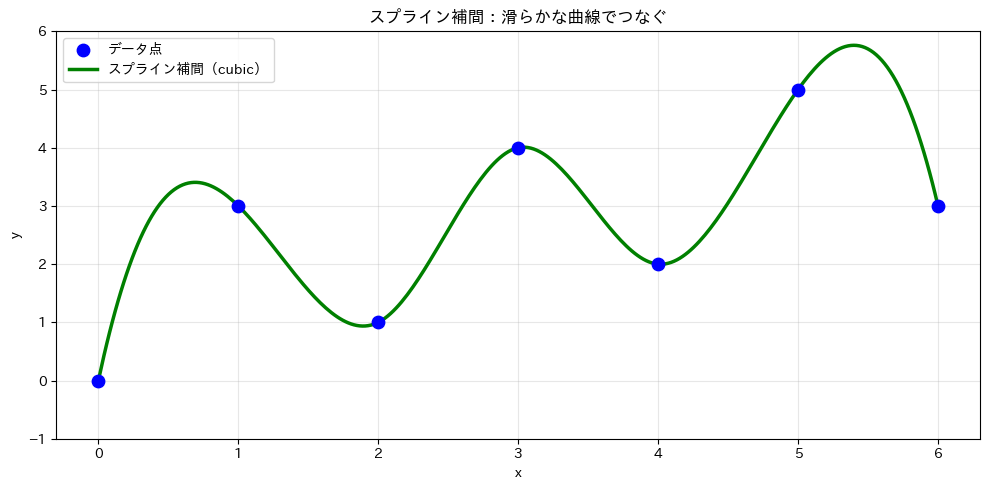
② スプライン補間(cubic)
スプライン補間 は、データ点を滑らかな曲線で結ぶ方法です。kind='cubic'(3次スプライン)を指定します。
メリットとして滑らかな曲線が得られる点があります。デメリットはデータの端で不自然な振る舞いをすることがある点です。
以下、コードです。
# スプライン補間(3次)
f_cubic = interp1d(x, y, kind='cubic')
# 描画用の図と軸を作成
fig, ax = plt.subplots(figsize=(8, 5))
# データ点
ax.scatter(
x, # x座標
y, # y座標
color='blue',
s=80,
zorder=5,
label='データ点'
)
# スプライン補間の曲線
ax.plot(
x_dense, # x座標
f_cubic(x_dense), # y座標
color='green',
linewidth=2.5,
label='スプライン補間(cubic)'
)
ax.set_title('スプライン補間:滑らかな曲線でつなぐ')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.legend()
ax.grid(True, alpha=0.3)
ax.set_ylim(-1, 6)
plt.tight_layout()
plt.show()
以下、実行結果です。
kind パラメータ
| kind の値 | 補間の方法 | 特徴 |
|---|---|---|
'linear' |
線形補間(デフォルト) | |
'nearest' |
最近傍補間 | 最も近いデータ点の値をそのまま使う |
'quadratic' |
2次スプライン補間 | 2次式で滑らかに結ぶ |
'cubic' |
3次スプライン補間 | 3次式で滑らかに結ぶ。最もよく使われる |
補間例
時系列データの欠損値を補間する
ある店舗の日別売上データで、3日分のデータが欠損しています。補間で欠損を埋めてみましょう。
まず、欠損のあるデータセットを作ります。
以下、コードです。
import numpy as np
import matplotlib.pyplot as plt
from scipy.interpolate import interp1d
# 日別売上データ(一部欠損あり)
# 3日目、7日目、12日目のデータが欠損している
all_days = np.arange(1, 15) # 1日〜14日
# 欠損を除いた既知のデータ
known_days = np.array([
1, 2, 4, 5, 6, 8, 9, 10, 11, 13, 14
])
known_sales = np.array([
50, 55, 70, 68, 75, 90, 85, 92, 95, 88, 82
])
# 欠損している日
missing_days = np.array([3, 7, 12])
欠損を補間します。
以下、コードです。
# ===== 線形補間で欠損を埋める =====
f_linear = interp1d(
known_days, # 既知の日付
known_sales, # 既知の売上
kind='linear' # 線形補間を指定
)
# 欠損日の値を線形で補間
filled_linear = f_linear(missing_days)
# ===== スプライン補間で欠損を埋める =====
f_cubic = interp1d(
known_days, # 既知の日付
known_sales, # 既知の売上
kind='cubic' # 3次スプライン補間を指定
)
# 欠損日の値をスプラインで補間
filled_cubic = f_cubic(missing_days)
# 結果を表示
print("【欠損値の補間結果】")
print(f"{'日':>4s} {'線形補間':>8s} {'スプライン補間':>12s}")
print("-" * 32)
# 各欠損日についてループ
for i, day in enumerate(missing_days):
print(
f"{day:>4d}日 " # 日付
f"{filled_linear[i]:>8.1f} " # 線形補間の結果
f"{filled_cubic[i]:>12.1f}" # スプライン補間の結果
)
以下、実行結果です。
【欠損値の補間結果】 日 線形補間 スプライン補間 -------------------------------- 3日 62.5 64.7 7日 82.5 86.0 12日 91.5 92.8
結果をグラフで描画します。
以下、コードです。
# なめらかに描画するための細かいx
x_dense = np.linspace(1, 14, 300)
# 図のサイズ
plt.figure(figsize=(10, 5))
# 既知データをプロット
plt.scatter(
known_days, # x座標(既知の日)
known_sales, # y座標(既知の売上)
color='blue',
s=70,
zorder=5,
label='既知データ'
)
# 補間結果をプロット(線形補間)
plt.scatter(
missing_days, # x座標(欠損日)
filled_linear, # y座標(線形で補間した値)
color='orange',
s=100,
marker='D',
zorder=5,
label='線形補間で復元'
)
# 補間結果をプロット(3次スプライン補間)
plt.scatter(
missing_days, # x座標(欠損日)
filled_cubic, # y座標(スプラインで補間した値)
color='green',
s=100,
marker='s',
zorder=5,
label='スプライン補間で復元'
)
# 線形補間の曲線をプロット
plt.plot(
x_dense, # 補間用のx(連続軸)
f_linear(x_dense), # 補間結果(線形)
color='orange',
linestyle='--',
alpha=0.5
)
# スプライン補間の曲線をプロット
plt.plot(
x_dense, # 補間用のx(連続軸)
f_cubic(x_dense), # 補間結果(スプライン)
color='green',
linestyle=':',
alpha=0.5
)
# 欠損日にハイライト(縦線で位置を示す)
for day in missing_days:
plt.axvline(
x=day, # 縦線の位置(欠損日)
color='red',
linestyle=':',
alpha=0.5
)
plt.xlabel('日')
plt.ylabel('売上(万円)')
plt.title('欠損した日別売上データの補間')
plt.legend()
plt.tight_layout()
plt.show()
以下、実行結果です。
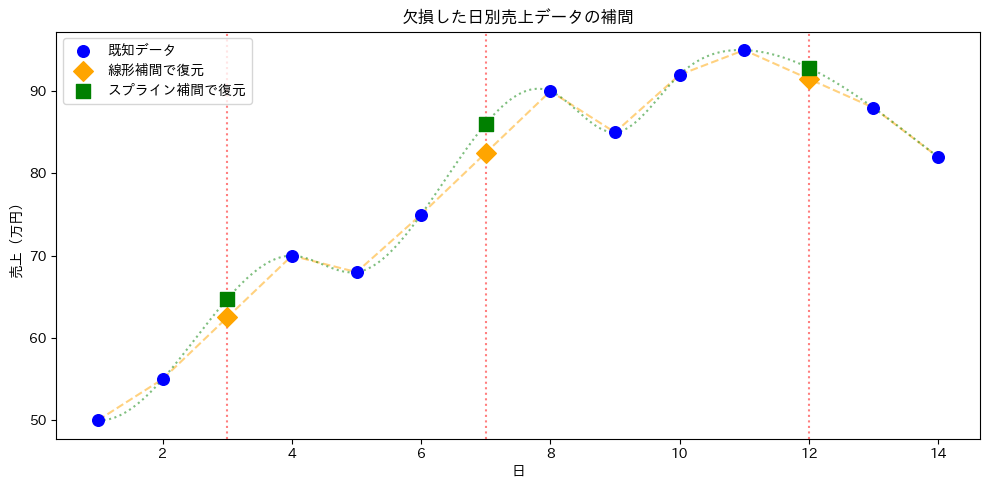
線形補間とスプライン補間で、値がわずかに異なることがわかります。これは補間の計算方法の違いによるものです。
グラフを見ると、線形補間は直線的に値を推測しているのに対し、スプライン補間はデータの曲線的な傾向も考慮して推測しています。
センサーデータの高解像度化
補間は欠損値を埋めるだけでなく、粗いデータをより細かく滑らかにする(データの高解像度化)にも使えます。
1時間ごとに記録されたセンサーの温度データを、10分間隔のデータに変換します。
まず、1時間ごとに記録されたセンサーの温度データを作ります。
以下、コードです。
import numpy as np
import matplotlib.pyplot as plt
from scipy.interpolate import interp1d
# 1時間ごとのセンサーデータ(0時〜12時)
hours = np.array([
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12
])
temp = np.array([
15.0, 14.5, 14.0, 13.8, 14.2, 15.5, 17.0,
19.5, 22.0, 24.5, 26.0, 26.5, 26.0
])
10分間隔のデータを欠損と考え、補間することで、1時間間隔のデータを10分間隔のデータにします。
以下、コードです。
# スプライン補間で10分間隔のデータを生成
f_cubic = interp1d(hours, temp, kind='cubic')
hours_fine = np.arange(0, 12.01, 1/6) # 10分 = 1/6時間
temp_fine = f_cubic(hours_fine)
print(f"元のデータ点数 : {len(hours)} 点(1時間ごと)")
print(f"補間後のデータ点数: {len(hours_fine)} 点(10分ごと)")
print()
print("【補間されたデータの一部(6時〜8時)】")
for h, t in zip(hours_fine, temp_fine):
if 6.0 <= h <= 8.0:
hour_int = int(h)
minute = int((h - hour_int) * 60)
print(
f" {hour_int:02d}:{minute:02d} → {t:.1f}℃"
)
以下、実行結果です。
元のデータ点数 : 13 点(1時間ごと) 補間後のデータ点数: 73 点(10分ごと) 【補間されたデータの一部(6時〜8時)】 06:00 → 17.0℃ 06:09 → 17.4℃ 06:19 → 17.8℃ 06:30 → 18.2℃ 06:39 → 18.6℃ 06:49 → 19.1℃ 07:00 → 19.5℃ 07:09 → 19.9℃ 07:19 → 20.3℃ 07:30 → 20.8℃ 07:39 → 21.2℃ 07:49 → 21.6℃ 08:00 → 22.0℃
13点のデータが73点に増え、より細かい時間変化を把握できるようになりました。
結果をグラフで描画します。
以下、コードです。
# 図のサイズ
plt.figure(figsize=(10, 5))
# 元データ(1時間ごと)の散布図
plt.scatter(
hours, # x: 時刻(時)
temp, # y: 気温(℃)
color='blue', # 点の色を青に
s=80, # 点の大きさ
zorder=5, # 前面に表示
label='元データ(1時間ごと)'
)
# 補間後(10分ごと)のスプライン曲線
plt.plot(
hours_fine, # x: 10分刻みの時刻
temp_fine, # y: 補間された気温
color='green', # 線の色を緑に
linewidth=2, # 線の太さ
label='スプライン補間(10分ごと)'
)
# x軸の目盛り表示を0〜12時に設定
plt.xticks(
range(13), # 0〜12の整数
[f'{h}時' for h in range(13)] # 目盛りラベル(0時, 1時, ...)
)
plt.xlabel('時刻(時)')
plt.ylabel('気温(℃)')
plt.title('センサーデータの高解像度化(1時間→10分間隔)')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
以下、実行結果です。
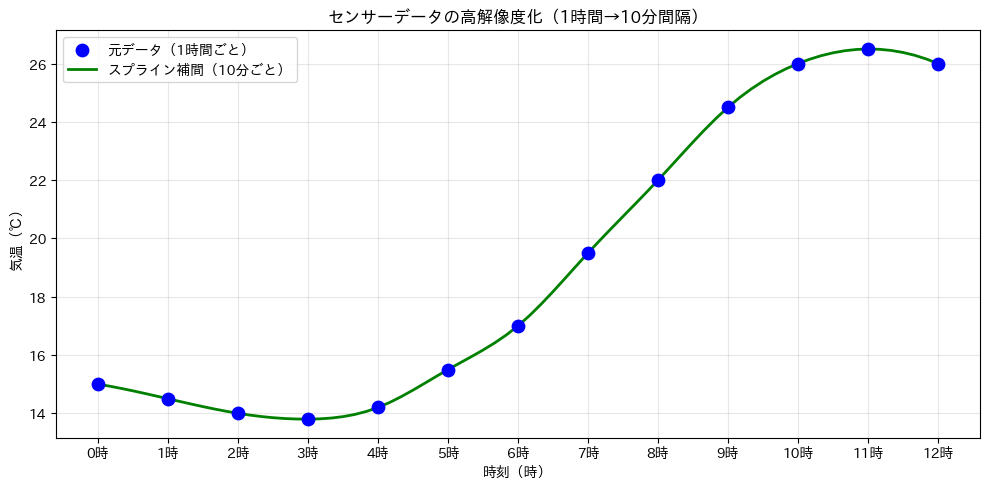
補間方法による違いを比較する
4種類の補間方法をすべて重ねて描画し、違いを確認してみましょう。
まず、例示用のデータを作成します。
以下、コードです。
import numpy as np import matplotlib.pyplot as plt from scipy.interpolate import interp1d # 少ないデータ点(例示用) x = np.array([0, 1, 3, 4, 6, 7]) # x座標 y = np.array([1, 3, 2, 5, 4, 6]) # y座標
欠損したいる箇所を、4種類の補間方法で補間します。
以下、コードです。
# なめらかに描画するための細かいx
x_dense = np.linspace(0, 7, 300)
# 比較する補間方法(4種類)
# 補間の種類
kinds = ['nearest', 'linear', 'quadratic', 'cubic']
# 各線の色
colors = ['gray', 'orange', 'purple', 'green']
# 凡例用ラベル
labels = [
'最近傍補間(nearest)',
'線形補間(linear)',
'2次スプライン(quadratic)',
'3次スプライン(cubic)'
]
# 4行1列のサブプロット
fig, axes = plt.subplots(4, 1, figsize=(10, 10))
# 1次元配列に整形
axes = axes.flatten()
# 各補間方法で曲線を描画
for i, (kind, color, label) in enumerate(zip(kinds, colors, labels)):
# 補間関数を作成
f = interp1d(x, y, kind=kind)
# 元データ点
axes[i].scatter(
x, y,
color='blue', s=80, zorder=5,
label='データ点'
)
# 補間曲線
axes[i].plot(
x_dense, f(x_dense),
color=color, linewidth=2,
label=label
)
axes[i].set_title(label)
axes[i].set_xlabel('x')
axes[i].set_ylabel('y')
axes[i].legend()
axes[i].grid(True, alpha=0.3)
axes[i].set_ylim(-0.5, 7.5)
plt.tight_layout()
plt.show()
以下、実行結果です。
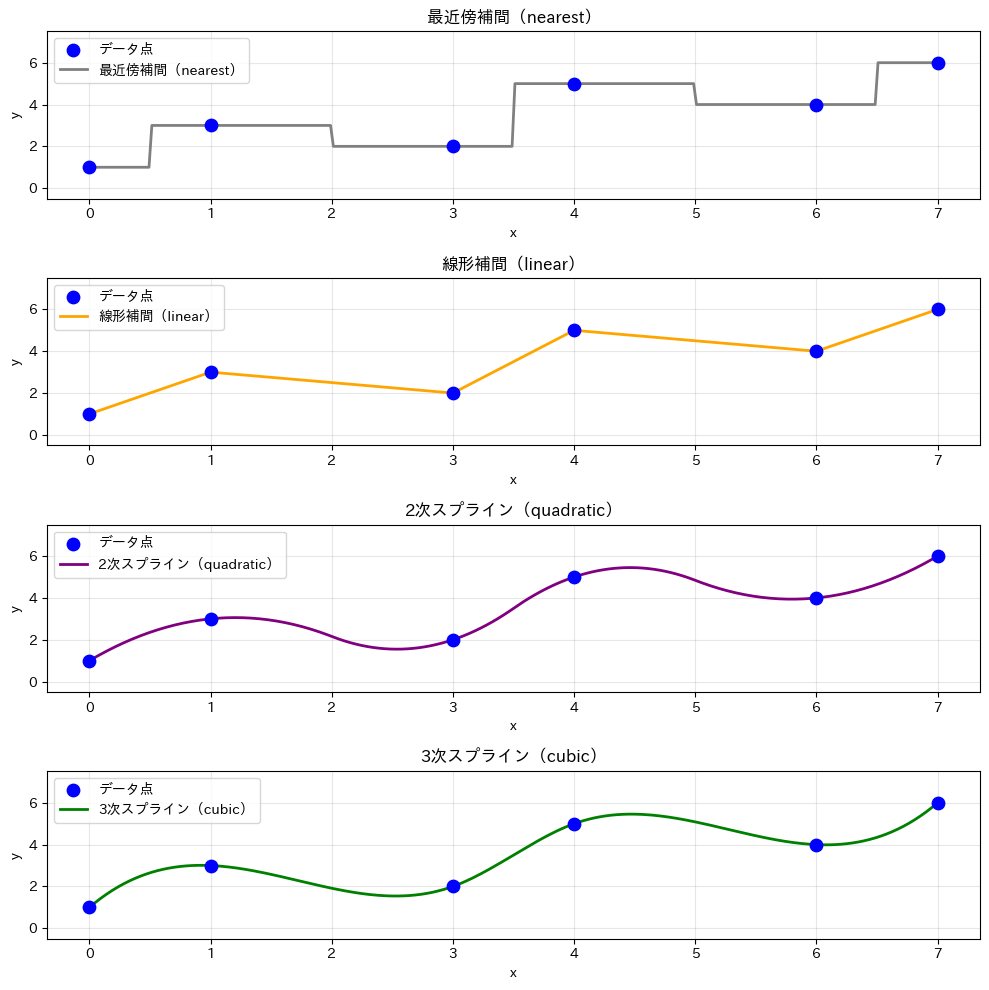
4つのグラフを比較すると、それぞれの特徴が見えてきます。
- 最近傍補間(nearest):最も近いデータ点の値をそのまま使うので、階段状になります。値が離散的(段階的)な場合に向いています
- 線形補間(linear):隣り合う点を直線で結びます。シンプルで多くの場面で使えます
- 2次スプライン(quadratic):2次式で滑らかに結びます。cubicよりやや簡素です
- 3次スプライン(cubic):3次式で最も滑らかに結びます。自然現象のデータに向いています
補間の範囲に注意(外挿と内挿)
補間で重要な注意点として、データの範囲外には補間できないというルールがあります。
| 用語 | 意味 | |
|---|---|---|
| 内挿(ないそう) | データ点の「範囲内」の値を推測する | 高い |
| 外挿(がいそう) | データ点の「範囲外」の値を推測する | 低い(危険) |
interp1d はデフォルトで、データの範囲外の値を求めようとするとエラーを出します。
以下、コードです。
import numpy as np
from scipy.interpolate import interp1d
x = np.array([1, 2, 3, 4, 5])
y = np.array([10, 20, 30, 40, 50])
f = interp1d(x, y)
# データ範囲内(1〜5)→ 正常に動作
print(f"x=3.5 → y={f(3.5):.1f}")
# データ範囲外 → エラーが発生
try:
print(f"x=6.0 → y={f(6.0):.1f}")
except ValueError as e:
print(f"エラー発生:{e}")
以下、実行結果です。
x=3.5 → y=35.0 エラー発生:A value (6.0) in x_new is above the interpolation range's maximum value (5).
「x_new の値が補間範囲を超えている」というエラーが出ました。
これは interp1d が安全のために範囲外の推測を拒否しているためです。
範囲外にアクセスしたときの動作を変更するには、fill_value パラメータを使います。
まず、例示のためのデータを作ります。
以下、コードです。
import numpy as np from scipy.interpolate import interp1d # 元データ(xとyの対応) x = np.array([1, 2, 3, 4, 5]) y = np.array([10, 20, 30, 40, 50]) # 評価したいxの値(範囲内と範囲外を混ぜる) test_values = [0, 2.5, 6]
評価したいxの値(範囲内と範囲外)に対し、欠損を補間します。
以下、コードです。
# 範囲外は NaN(欠損値)で埋める
f_nan = interp1d(x, y, bounds_error=False, fill_value=np.nan)
# 範囲外は端の値で埋める(外挿しない安全な方法)
f_edge = interp1d(x, y, bounds_error=False, fill_value=(y[0], y[-1]))
# 範囲外も外挿する(注意が必要)
f_extrap = interp1d(x, y, fill_value='extrapolate')
test_values = [0, 2.5, 6]
print(f"{'x':>4s} {'NaN埋め':>8s} {'端の値':>8s} {'外挿':>8s}")
print("-" * 36)
for xv in test_values:
print(f"{xv:>4.1f} {f_nan(xv):>8.1f} {f_edge(xv):>8.1f} {f_extrap(xv):>8.1f}")
bounds_error=False, fill_value=np.nan:範囲外はNaN(欠損値)にするbounds_error=False, fill_value=(y[0], y[-1]):範囲外は両端の値で埋めるfill_value='extrapolate':範囲外も補間の延長で推測する(外挿)
以下、実行結果です。
x NaN埋め 端の値 外挿 ------------------------------------ 0.0 nan 10.0 0.0 2.5 25.0 25.0 25.0 6.0 nan 50.0 60.0
interp1d を使うときの注意点
① xデータは昇順に並べる
interp1d に渡す x データは 小さい順(昇順) に並んでいる必要があります。
並んでいないとエラーになります。
② データ点が少なすぎるとスプライン補間ができない
3次スプライン補間(kind='cubic')には最低4点のデータが必要です。
2次スプライン(kind='quadratic')には最低3点必要です。
データ点が少ない場合は線形補間を使いましょう。
③ ノイズの多いデータには不向き
補間はすべてのデータ点を「正確に」通る曲線を作ります。
そのため、ノイズ(測定誤差)が多いデータでは、ノイズまで忠実に再現してしまい、不自然な結果になることがあります。
ノイズの多いデータには、補間ではなく前回紹介したフィッティング(curve_fit)のほうが適しています。
以下のコードで、ノイズのあるデータに対する補間とフィッティングの違いを確認してみましょう。
import numpy as np
import matplotlib.pyplot as plt
from scipy.interpolate import interp1d
from scipy.optimize import curve_fit
# 乱数の再現性を確保する
np.random.seed(42)
# x軸のデータ点
x = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8])
# 真の関係(直線)
y_true = 0.5 * x + 1
# ノイズを加えた観測データ
y_noisy = y_true + np.random.normal(0, 0.8, len(x))
# なめらかに描画するための細かいx
x_dense = np.linspace(0, 8, 300)
# 補間(スプライン補間の関数を作成)
f_cubic = interp1d(x, y_noisy, kind='cubic')
# フィッティング(直線モデルを定義)
def linear(x, a, b):
# a: 傾き, b: 切片
return a * x + b
# 観測データに直線をフィット(最小二乗)
popt, _ = curve_fit(linear, x, y_noisy)
# 図を上下に2つ作成
fig, axes = plt.subplots(2, 1, figsize=(10, 10))
# 上段:補間(データ点を必ず通るのでノイズも拾う)
axes[0].scatter(
x, y_noisy,
color='blue', s=80, zorder=5,
label='ノイズ付きデータ'
)
axes[0].plot(
x_dense, f_cubic(x_dense),
color='green', linewidth=2,
label='スプライン補間'
)
axes[0].plot(
x, y_true,
color='gray', linestyle=':', alpha=0.5,
label='真の直線'
)
axes[0].set_title('補間:ノイズまで再現してしまう')
axes[0].set_xlabel('x')
axes[0].set_ylabel('y')
axes[0].legend()
axes[0].grid(True, alpha=0.3)
axes[0].set_ylim(-2, 7)
# 下段:フィッティング(ノイズを平均化して滑らかに)
axes[1].scatter(
x, y_noisy,
color='blue', s=80, zorder=5,
label='ノイズ付きデータ'
)
axes[1].plot(
x_dense, linear(x_dense, *popt),
color='red', linewidth=2,
label='直線フィッティング'
)
axes[1].plot(
x, y_true,
color='gray', linestyle=':', alpha=0.5,
label='真の直線'
)
axes[1].set_title('フィッティング:ノイズを平滑化できる')
axes[1].set_xlabel('x')
axes[1].set_ylabel('y')
axes[1].legend()
axes[1].grid(True, alpha=0.3)
axes[1].set_ylim(-2, 7)
plt.tight_layout()
plt.show()
以下、実行結果です。
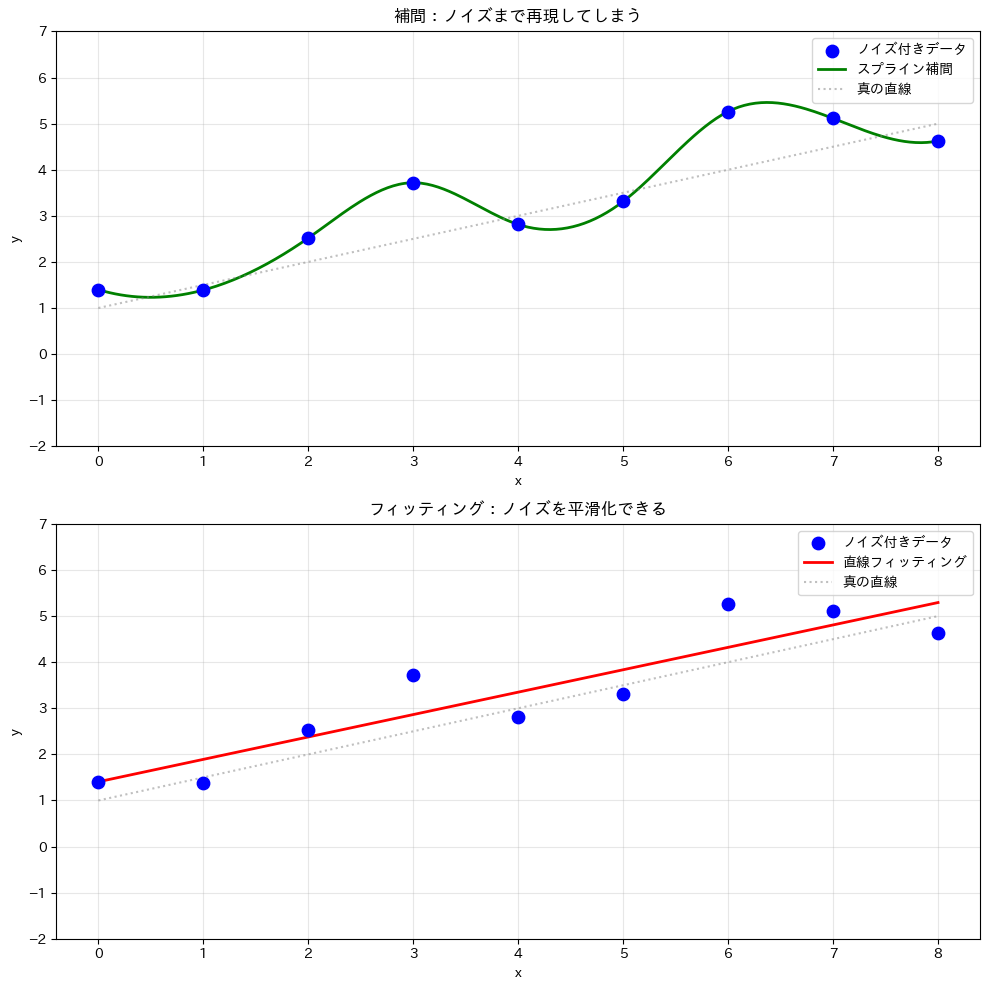
上のグラフでは、スプライン補間がノイズの山谷まで忠実に再現してしまい、波打った不自然な曲線になっています。
一方、下のグラフでは、フィッティングがノイズを無視して全体の傾向を捉えています。
データの性質を見極めて、補間とフィッティングを使い分けましょう。
| 状況 | おすすめの方法 | |
|---|---|---|
| 欠損値を手軽に埋めたい | 線形補間(linear) |
シンプルで安全 |
| 自然現象の滑らかなデータ | スプライン補間(cubic) |
滑らかな変化を再現 |
| 段階的に変わるデータ | 最近傍補間(nearest) |
不連続な変化を保つ |
| ノイズの多いデータ | フィッティング(curve_fit) |
ノイズを平滑化 |
| データの全体的な傾向を知りたい | フィッティング(curve_fit) |
数式で表現できる |
まとめ
今回の内容のポイントです。
- 補間 とは、既知のデータ点の間にある未知の値を推測すること
- SciPyの
interp1dで簡単に補間関数を作成できる
- 線形補間(
kind='linear')は直線で結ぶシンプルな方法
- スプライン補間(
kind='cubic')は滑らかな曲線で結ぶ方法 - 補間はデータの範囲内(内挿)で使い、範囲外(外挿)は基本的に避ける
- ノイズの多いデータには補間よりもフィッティング(curve_fit)が向いている
- データの性質を見極めて、補間とフィッティングを使い分けることが大切
次回は、「正規分布をscipy.statsで扱う」 をテーマに、確率分布の基本とSciPyでの使い方を紹介します。