

前回(第1回)では、欠損値には MCAR・MAR・MNAR という3つのメカニズムがあり、それぞれに応じた処理が必要だ、という話をしました。
では、実際のデータを手にしたとき、まず何をすべきでしょうか?
答えは 「欠損の現状を正確に把握すること」 です。
どの列に、どれくらいの欠損があり、どんなパターンで発生しているのか?
これらを見える化して初めて、適切な処理方針が立てられます。
今回は、Titanic(タイタニック) データセットを題材に、pandas での基本的な欠損検出から、missingno というライブラリを使った欠損パターンの可視化までを、ステップバイステップで紹介していきます。
Contents
- 使用するデータセット
- ステップ1:欠損の有無を確認する
- info() でデータ全体を俯瞰する
- isnull() で欠損の場所を特定する
- ステップ2:欠損率を計算する
- 欠損率を%で算出する
- 欠損件数と欠損率をまとめた表を作る
- ステップ3:欠損パターンを可視化する
- missingno のインストール
- matrix:欠損の位置をマトリクスで表示
- bar:欠損率を棒グラフで表示
- heatmap:欠損の相関を見る
- dendrogram:欠損の階層クラスタリング
- ステップ4:欠損のメカニズムを推定するヒント
- MAR の兆候を探る:他の変数との関係を見る
- グループ別欠損率を可視化する
- MNAR の兆候を見つけるのは難しい
- まとめ
使用するデータセット
欠損値処理の例として広く使われている Titanic データセット を使います。
1912年に沈没したタイタニック号の乗客情報をまとめたデータで、欠損値が含まれた現実的な題材として最適です。
seaborn ライブラリには Titanic データセットが組み込まれているので、ダウンロードなしですぐに使えます。
以下、コードです。
import pandas as pd
import numpy as np
import seaborn as sns
# Titanicデータセットの読み込み
df = sns.load_dataset('titanic')
print(f"データの形状: {df.shape}")
print(f"\n列の一覧:")
print(df.columns.tolist())
print(f"\nデータの先頭5行:")
print(df.head())
sns.load_dataset('titanic'):seaborn に組み込まれた Titanic データをDataFrameとして読み込みますdf.shape:データの行数と列数を(行数, 列数)のタプルで返しますdf.columns.tolist():列名をリスト形式で取得します
以下、実行結果です。
データの形状: (891, 15)
列の一覧:
['survived', 'pclass', 'sex', 'age', 'sibsp', 'parch', 'fare', 'embarked', 'class', 'who', 'adult_male', 'deck', 'embark_town', 'alive', 'alone']
データの先頭5行:
survived pclass sex age sibsp parch fare embarked class \
0 0 3 male 22.0 1 0 7.2500 S Third
1 1 1 female 38.0 1 0 71.2833 C First
2 1 3 female 26.0 0 0 7.9250 S Third
3 1 1 female 35.0 1 0 53.1000 S First
4 0 3 male 35.0 0 0 8.0500 S Third
who adult_male deck embark_town alive alone
0 man True NaN Southampton no False
1 woman False C Cherbourg yes False
2 woman False NaN Southampton yes True
3 woman False C Southampton yes False
4 man True NaN Southampton no True
891行15列のデータが読み込まれ、survived(生存)、age(年齢)、fare(運賃)、embarked(乗船港)などの列があることが確認できます。
ステップ1:欠損の有無を確認する
最初にやるべきことは、「そもそも欠損があるのか、どの列に何件あるのか」を確認することです。
pandas には便利なメソッドがいくつか用意されています。
info() でデータ全体を俯瞰する
info() メソッドは、データフレームの全体像を一覧で表示してくれます。
各列の 非欠損数 と データ型 が一目でわかるので、欠損の確認にはまずこれを使います。
以下、コードです。
df.info()
以下、実行結果です。
<class 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Data columns (total 15 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 survived 891 non-null int64 1 pclass 891 non-null int64 2 sex 891 non-null object 3 age 714 non-null float64 4 sibsp 891 non-null int64 5 parch 891 non-null int64 6 fare 891 non-null float64 7 embarked 889 non-null object 8 class 891 non-null category 9 who 891 non-null object 10 adult_male 891 non-null bool 11 deck 203 non-null category 12 embark_town 889 non-null object 13 alive 891 non-null object 14 alone 891 non-null bool dtypes: bool(2), category(2), float64(2), int64(4), object(5) memory usage: 80.7+ KB
各列の Non-Null Count(非欠損数)が表示されます。
データ全体は891件なので、これより少ない列には欠損があることになります。
age が714件、deck が203件など、いくつかの列で欠損が見られます。
isnull() で欠損の場所を特定する
isnull() メソッドは、各セルが欠損かどうかを True / False で返します。
これを sum() と組み合わせると、列ごとの欠損件数が計算できます。
以下、コードです。
# 列ごとの欠損件数 missing_count = df.isnull().sum() print(missing_count)
df.isnull():データフレームと同じ形状の真偽値データフレームを返します(欠損ならTrue).sum():列ごとにTrueの数(=欠損件数)を合計します
以下、実行結果です。
survived 0 pclass 0 sex 0 age 177 sibsp 0 parch 0 fare 0 embarked 2 class 0 who 0 adult_male 0 deck 688 embark_town 2 alive 0 alone 0 dtype: int64
各列の欠損件数の一覧です。age に177件、embarked に2件、deck に688件、embark_town に2件の欠損があることがわかります。
ステップ2:欠損率を計算する
欠損の 件数 だけでなく、全体に対する割合(欠損率) を見ることも重要です。
欠損率が低ければ削除でも対処できますが、高ければ補完や列削除を検討する必要があります。
欠損率を%で算出する
以下、コードです。
# 欠損率(%)の計算 missing_pct = df.isnull().mean() * 100 print(missing_pct.round(2))
df.isnull().mean():列ごとにTrue(欠損)の割合(0〜1の値)を計算します* 100:%表記に変換します.round(2):小数点第2位で丸めます
以下、実行結果です。
survived 0.00 pclass 0.00 sex 0.00 age 19.87 sibsp 0.00 parch 0.00 fare 0.00 embarked 0.22 class 0.00 who 0.00 adult_male 0.00 deck 77.22 embark_town 0.22 alive 0.00 alone 0.00 dtype: float64
deck 列が約77%、age 列が約20%、embarked 列と embark_town 列が約0.22% という欠損率が確認できます。
欠損件数と欠損率をまとめた表を作る
実務では、件数と割合をまとめて表にすると判断しやすくなります。
以下、コードです。
# 欠損のサマリーテーブルを作成
missing_summary = pd.DataFrame({
'missing_count': df.isnull().sum(),
'missing_pct': (df.isnull().mean() * 100).round(2)
})
# 欠損のある列だけを抽出して、欠損率の高い順にソート
missing_summary = missing_summary[
missing_summary['missing_count'] > 0
]
missing_summary = missing_summary.sort_values(
'missing_pct', ascending=False
)
print(missing_summary)
pd.DataFrame({...}):辞書からデータフレームを作成します。キーが列名、値が列の中身になりますmissing_summary[missing_summary['missing_count'] > 0]:欠損のある列だけに絞り込みますsort_values('missing_pct', ascending=False):欠損率の高い順に並べ替えます(ascending=Falseで降順)
以下、実行結果です。
missing_count missing_pct deck 688 77.22 age 177 19.87 embarked 2 0.22 embark_town 2 0.22
deck(77.10%)、age(19.87%)、embarked と embark_town(各0.22%)の4列が、欠損率の高い順に並んでいます。
ステップ3:欠損パターンを可視化する
ここまでは「件数」や「割合」という数値での把握でした。
しかし、欠損には 「どの行とどの行が同時に欠損しているか」 という、行同士の関係性も重要な情報になります。
これを見るには可視化が一番です。
そこで便利なのが、missingno という欠損値専用の可視化ライブラリです。
missingno のインストール
まだインストールされていない方は、pipでインストールできます。
以下、コードです。
pip install missingno
利用するときは、ライブラリーを読み込みます。
以下、コードです。
import missingno as msno import matplotlib.pyplot as plt
matrix:欠損の位置をマトリクスで表示
msno.matrix() は、データの欠損位置を 白黒のマトリクス で表示します。
黒が非欠損、白が欠損で、行(=サンプル)ごとにどの列が欠損しているかが一目でわかります。
以下、コードです。
msno.matrix(df, figsize=(6, 5)) plt.show()
df:可視化したいデータフレームfigsize:図のサイズを(幅, 高さ)のインチで指定します
実行すると、横軸に列名、縦軸にサンプル(行)が並んだマトリクスが表示されます。
以下、実行結果です。
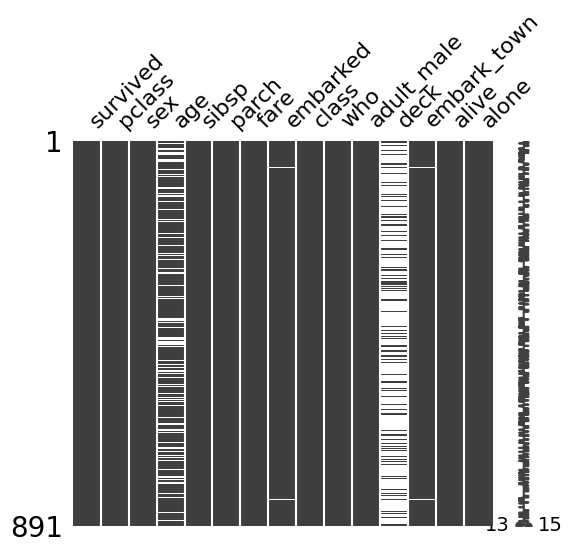
deck 列はほぼ全体が白(欠損が多い)、age 列は所々に白い線が入っている(欠損が散発的)、embarked 列はほぼ真っ黒(欠損がごくわずか)という様子が視覚的に確認できます。
右側には スパークライン(小さな折れ線)が付いており、各行で何列が非欠損だったかを示しています。すべての列が揃っている行ではスパークラインが右に伸び、欠損が多い行では左に縮みます。
bar:欠損率を棒グラフで表示
msno.bar() は、列ごとの 非欠損数 を棒グラフで表示します。
先ほど数値で確認した欠損率を、視覚的にざっくり把握できます。
以下、コードです。
msno.bar(df, figsize=(6, 5)) plt.show()
実行すると、各列の非欠損数が棒の高さで表示されます。
以下、実行結果です。
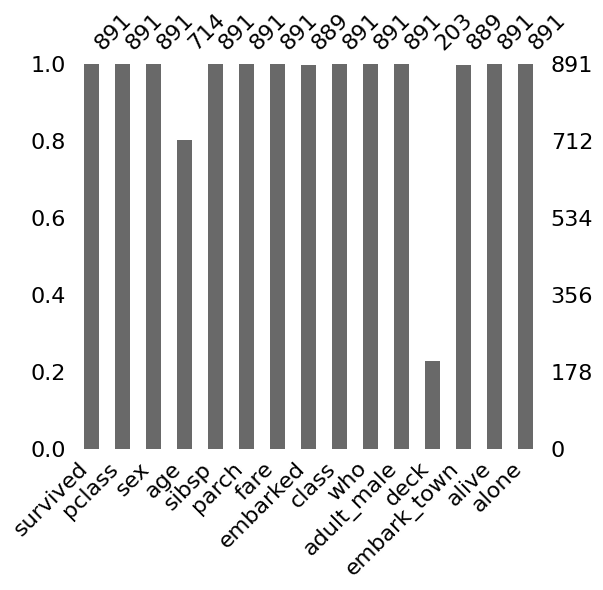
棒が短いほど欠損が多い列です。deck 列の棒が極端に短く、age 列もやや低めなのが一目でわかります。
heatmap:欠損の相関を見る
msno.heatmap() は、欠損の 相関 をヒートマップで表示します。
ここでいう相関とは、「ある列が欠損しているとき、別の列も欠損していやすいか?」という関係性のことです。
以下、コードです。
msno.heatmap(df, figsize=(6, 6)) plt.show()
実行すると、欠損のある列同士の相関係数(−1〜1)が色で表示されます。
- 正の相関(青系):片方が欠損していると、もう片方も欠損していやすい
- 負の相関(赤系):片方が欠損していると、もう片方は欠損しにくい
- 0に近い:両者の欠損は無関係
以下、実行結果です。
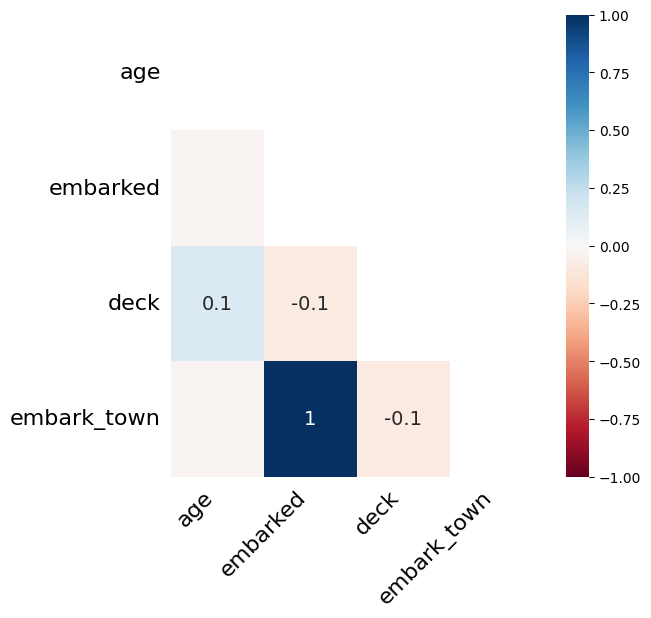
embarked と embark_town の相関が1.0 になっています。
これは「乗船港」と「乗船町」が同じ情報を表しているため、片方が欠損するともう片方も欠損する、という当然の関係を反映しています。
dendrogram:欠損の階層クラスタリング
msno.dendrogram() は、欠損のパターンが似ている列を 階層クラスタリング でまとめた図(樹形図)を描きます。
heatmap よりも多くの列を一度に俯瞰できるのが利点です。
以下、コードです。
msno.dendrogram(df, figsize=(6, 5)) plt.show()
実行すると、欠損パターンが近い列ほど近くにまとめられた樹形図が表示されます。
以下、実行結果です。

embarked と embark_town が一番近くにまとめられ、両者の欠損パターンがほぼ同じであることが確認できます。
ステップ4:欠損のメカニズムを推定するヒント
ここまでで欠損の「現状」は把握できました。
前回で学んだ MCAR / MAR / MNAR の推定につなげる視点を紹介します。
MAR の兆候を探る:他の変数との関係を見る
MAR は「他の変数で欠損が説明できる」状態でした。
これを確かめるには、欠損のある列と他の列の関係を見るのが有効です。
たとえば、age の欠損率が 客室クラス(pclass) によって違うかを調べてみましょう。
以下、コードです。
# pclass別のage欠損率
age_missing_by_class = df.groupby('pclass')['age'].apply(
lambda x: x.isnull().mean() * 100
).round(2)
print("客室クラス別の age 欠損率(%):")
print(age_missing_by_class)
df.groupby('pclass'):pclass列でグループ化します['age'].apply(lambda x: x.isnull().mean() * 100):各グループのageについて欠損率を計算しますlambdaは無名関数で、簡単な処理を1行で書きたいときに使います
以下、実行結果です。
客室クラス別の age 欠損率(%): pclass 1 13.89 2 5.98 3 27.70 Name: age, dtype: float64
客室クラスによって age の欠損率に差がある ことがわかります。
これは「age の欠損が pclass という観測変数で説明できる」可能性を示唆しており、MAR の兆候 といえます。
グループ別欠損率を可視化する
以下、コードです。
import matplotlib.pyplot as plt
# グラフのサイズを設定
fig, ax = plt.subplots(figsize=(6, 4))
# pclassごとのage欠損率を棒グラフで描画
age_missing_by_class.plot(
kind='bar', # 棒グラフ
ax=ax, # 描画領域
color='steelblue', # 棒の色
edgecolor='black' # 棒の枠線の色
)
# タイトルと軸ラベルを設定
ax.set_title('Age Missing Rate by Passenger Class')
ax.set_xlabel('Passenger Class')
ax.set_ylabel('Missing Rate (%)')
# x軸の目盛りラベルを見やすく設定
ax.set_xticklabels(['1st', '2nd', '3rd'], rotation=0)
# レイアウト調整と表示
plt.tight_layout()
plt.show()
age_missing_by_class.plot(kind='bar', ...):pandas の Series から直接棒グラフを描けますset_xticklabels(..., rotation=0):x軸ラベルを水平に表示します
以下、実行結果です。
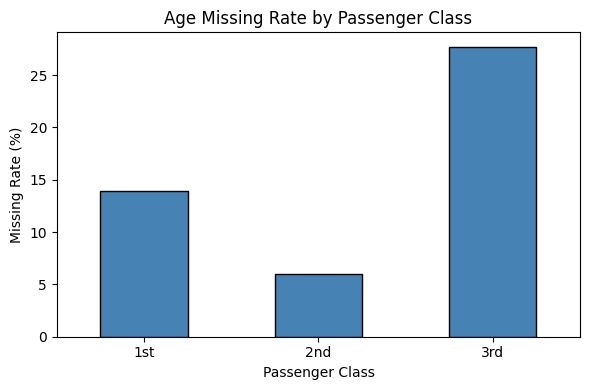
客室クラスが下がる(=2等→3等)にしたがって age の欠損率が上がっていく傾向が棒グラフで確認できます。
これは「下位クラスの乗客ほど年齢情報の記録が雑だった」という歴史的背景を反映している可能性があります。
いずれにせよ、age の欠損が pclass と関連しているため、pclass を使って age を補完する という発想が立てられます。
MNAR の兆候を見つけるのは難しい
一方で、MNAR の兆候を見つけるのは原理的に難しいです。
なぜなら、MNAR は 「欠損している値そのもの」 に依存するため、欠損していない部分のデータからでは判断できないからです。
実務では、ドメイン知識(その分野の専門知識)を使って「この欠損は値そのものに依存している可能性がある」と推測することが多いです。
たとえば、収入アンケートで「高所得者が答えたがらない」というのは、調査の経験則から推測される MNAR のパターンです。
まとめ
今回のポイントを振り返りましょう。
- 欠損値処理の出発点は 「現状の正確な把握」。やみくもに補完したり削除したりしてはいけない
- pandas の **
info()、isnull().sum()などで件数と割合を確認する - 欠損件数と欠損率をまとめた サマリーテーブル を作ると判断しやすい
missingnoライブラリ を使うと、欠損パターンを視覚的に把握できるmatrix:欠損の位置をマトリクス表示bar:列ごとの非欠損数を棒グラフで表示heatmap:欠損の相関を表示dendrogram:欠損パターンの階層クラスタリング
- グループ別の欠損率を見ることで、MAR の兆候 を探ることができる
- MNAR の兆候はドメイン知識で推測する しかないことが多い