

第3回では、行を削除する リストワイズ削除(CCA)についてお話ししました。
今回はもう2つの削除戦略である、列(特徴量)を削除する 方法と、分析ごとに使えるデータを最大化する ペアワイズ削除を取り上げます。
- 行を削除するか、列を削除するか?
- 全体で削除するか、ペアごとに削除するか?
この組み合わせを理解すると、削除戦略の引き出しが一気に広がります。
前回同様 Titanic データセットを使って、それぞれの実装と、どのような場面で利用するのか判断基準を見ていきましょう。
Contents
サンプルデータの準備
これまで通り、seaborn の Titanic データセットを使います。
以下、コードです。
import pandas as pd
import numpy as np
import seaborn as sns
# Titanicデータセットの読み込み
df = sns.load_dataset('titanic')
# 列ごとの欠損率を計算
missing_pct = (
df.isnull().mean() * 100
).round(2)
# 欠損率が0より大きい列のみを抽出し、欠損率の降順でソート
missing_pct = (
missing_pct[missing_pct > 0]
.sort_values(ascending=False)
)
print("欠損のある列と欠損率:")
print(missing_pct)
以下、実行結果です。
欠損のある列と欠損率: deck 77.22 age 19.87 embarked 0.22 embark_town 0.22 dtype: float64
deck が約77%、age が約20%、embarked と embark_town が約0.22% という欠損率が確認できます。
特徴量削除(列削除)
特徴量削除(列削除)とは?
特徴量削除(feature deletion) とは、欠損値が多すぎる 列をまるごと捨てる という戦略です。
第3回のリストワイズ削除が「行」を捨てるアプローチだったのに対し、特徴量削除は「列」を捨てます。
視点が90度違う、と言えばイメージしやすいかもしれません。
列削除を検討すべき場面
列削除は、特に次のような状況で有効です。
- 欠損率が極端に高い(一般的な目安は 70〜80%超)
- その列を補完しても情報がほとんど復元できない
- その列が予測対象(目的変数)と弱くしか関係しない
逆に、欠損率が高くても次のような場合は 列削除を慎重に判断 すべきです。
- 欠損自体が情報を持っている(「未回答」がパターンを示す)
- ドメイン知識上、その列が重要だとわかっている
- 他の手法(たとえば「欠損インジケータ」)で代替できる
単一列の削除:drop() の基本
pandas で列を削除する基本は drop() メソッド です。
以下、コードです。
# deck 列を削除
df_no_deck = df.drop(columns=['deck'])
print(f"削除前の列数: {df.shape[1]}")
print(f"削除後の列数: {df_no_deck.shape[1]}")
print(f"削除された列: deck")
df.drop(columns=['deck']):deck列を削除した新しいデータフレームを返します- 元のデータフレームは変更されません(
inplace=Falseがデフォルト)
以下、実行結果です。
削除前の列数: 15 削除後の列数: 14 削除された列: deck
列数が15から14に減り、deck 列だけが除去されます。
Titanic の deck 列は欠損率が約77% と非常に高いため、列削除の候補となりえます。
複数列の削除
columns にはリストを渡せるので、複数の列を一度に削除できます。
以下、コードです。
# deck と age を同時に削除
df_drop_two = df.drop(columns=['deck', 'age'])
print(f"削除前の列数: {df.shape[1]}")
print(f"削除後の列数: {df_drop_two.shape[1]}")
print(f"残った列: {df_drop_two.columns.tolist()}")
以下、実行結果です。
削除前の列数: 15 削除後の列数: 13 残った列: ['survived', 'pclass', 'sex', 'sibsp', 'parch', 'fare', 'embarked', 'class', 'who', 'adult_male', 'embark_town', 'alive', 'alone']
deck と age の両方が削除され、列数が13になります。
欠損率に基づく自動削除
実務では、列の数が多いデータセットに対して「欠損率が○%を超える列を一括で削除する」というロジックを書くことがよくあります。
以下、コードです。
# 欠損率の閾値(ここでは50%)
threshold = 50.0
# 閾値を超える列を抽出
cols_to_drop = df.columns[
df.isnull().mean() * 100 > threshold
].tolist()
print(f"削除対象の列: {cols_to_drop}")
# 一括削除
df_cleaned = df.drop(columns=cols_to_drop)
print(f"\n削除前の列数: {df.shape[1]}")
print(f"削除後の列数: {df_cleaned.shape[1]}")
df.isnull().mean() * 100:列ごとの欠損率(%)を計算しますdf.columns[条件]:条件を満たす列名を抽出します.tolist():Series をリストに変換します
以下、実行結果です。
削除対象の列: ['deck'] 削除前の列数: 15 削除後の列数: 14
欠損率が50% を超える列(Titanic では deck のみ)が自動で検出され、削除されます。
閾値を変えれば「30% 以上を削除」「80% 以上を削除」と柔軟に調整できます。
列削除の影響をモデル精度で確かめる
「列を削除すると、どれくらい予測精度に影響するのか?」を実際に確かめてみましょう。
Titanic データを使い、deck 列を残したまま CCA したケース と deck 列を削除してから CCA したケース で、生存予測の精度を比較します。
以下、コードです。
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
#
# データセット準備
#
# 数値列だけを使った簡易実験用データを準備
df_exp = df[[
'survived', 'pclass', 'age', 'fare', 'sibsp', 'parch'
]].copy()
# パターンA:年齢(age)を残し、欠損値を含む行をすべて削除
df_a = df_exp.dropna()
X_a = df_a.drop(columns=['survived']) # 説明変数
y_a = df_a['survived'] # 目的変数
# パターンB:年齢(age)列をあらかじめ削除し、その後に欠損値行を削除
df_b = df_exp.drop(columns=['age']).dropna()
X_b = df_b.drop(columns=['survived']) # 説明変数
y_b = df_b['survived'] # 目的変数
#
# モデル学習と精度計算
#
# モデル学習と精度計算(ホールドアウト法で学習/評価を実施)
def evaluate(X, y, label):
# データを学習用とテスト用に分割
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# ロジスティック回帰モデルを学習
model = LogisticRegression(max_iter=1000)
model.fit(X_train, y_train)
# テストデータで予測し、精度(accuracy)を算出
pred = model.predict(X_test)
acc = accuracy_score(y_test, pred)
print(
f"【{label}】\n "
f" - サンプル数={len(X)} \n "
f" - accuracy={acc:.4f}"
)
# 2つのパターンで評価結果を比較
evaluate(X_a, y_a, "A: age 列を残してCCA")
evaluate(X_b, y_b, "B: age 列を削除してCCA")
train_test_split:データを学習用とテスト用に分割しますLogisticRegression:シンプルな線形分類モデル(生存予測のような2値分類でよく使われる)accuracy_score:正解率を計算します
以下、実行結果です。
【A: age 列を残してCCA】 - サンプル数=714 - accuracy=0.6993 【B: age 列を削除してCCA】 - サンプル数=891 - accuracy=0.7151
パターンAでは age の欠損で約180件が削除されてサンプル数が減りますが、age の情報を保持できます。
パターンBではサンプル数は減りませんが、age という重要な特徴量を失います。
どちらが優れているかはデータと目的次第 で、こうした比較実験で確かめるのが実務的なアプローチです。
ペアワイズ削除
ペアワイズ削除とは?
ここからが今回のもう一つのテーマ、ペアワイズ削除(pairwise deletion) です。
リストワイズ削除(第3回)が「ある行に1つでも欠損があれば、その行をすべての分析から除外する」のに対し、ペアワイズ削除は「分析ごとに、その分析に必要な変数だけ揃っている行を使う」というアプローチです。
| 削除方法 | 行うこと | 例:A・B・Cの3列で分析するとき |
|---|---|---|
| リストワイズ | A・B・Cがすべて揃った行だけ使う | |
| ペアワイズ | 分析ごとに必要列だけ揃った行を使う | A・Bの相関にはA・B揃った行、A・Cの相関にはA・C揃った行 |
ペアワイズ削除の使いどころ:相関分析
ペアワイズ削除がもっとも自然に使われるのが、相関係数の計算 です。
pandas の corr() メソッドは、デフォルトでペアワイズ削除を実行しています。
以下、コードです。
# 数値列を抽出(相関を見たい数値列を指定)
numeric_cols = ['age', 'fare', 'sibsp', 'parch']
# 指定した列だけを取り出す
df_num = df[numeric_cols]
# 相関係数の計算(NaNはペアワイズで無視される)
corr_matrix = df_num.corr()
# 結果を表示(小数第3位まで丸めて見やすく)
print("相関行列:")
print(corr_matrix.round(3))
df.corr():数値列同士の相関係数を計算します- デフォルトで欠損を含む行は ペアごとに自動的に除外 されます
以下、実行結果です。
相関行列:
age fare sibsp parch
age 1.000 0.096 -0.308 -0.189
fare 0.096 1.000 0.160 0.216
sibsp -0.308 0.160 1.000 0.415
parch -0.189 0.216 0.415 1.000
4変数間の相関行列(4×4 の表)が表示されます。
各ペアで何件のデータが使われたか確認する
ペアワイズ削除では、ペアごとに使われるサンプル数が異なります。
これを確認するには count() メソッドが便利です。
以下、コードです。
# ペアごとの有効サンプル数を数える関数
# 各数値列の組み合わせ(i, j)について、2列とも欠損していない行数をカウントします。
def pairwise_count(df_num):
cols = df_num.columns # 対象となる列名一覧
n = len(cols) # 列数(今回は使っていないが残しておく)
# 結果を格納する空のDataFrame(行・列ともに元の列名、要素は整数)
result = pd.DataFrame(
index=cols,
columns=cols,
dtype=int
)
# 2重ループで全てのペアを走査
for i in cols:
for j in cols:
# 列iと列jの2列を取り出し、両方が非欠損の行のみを残して件数を数える
result.loc[i, j] = (
df_num[[i, j]]
.dropna()
.shape[0]
)
return result
# 関数を使ってペアごとの有効サンプル数を計算
count_matrix = pairwise_count(df_num)
# 結果を表示
print("ペアごとの有効サンプル数:")
print(count_matrix)
df_num[[i, j]].dropna().shape[0]:列iとjの両方に値がある行数を数えます- ループで全ペアの組み合わせについてカウントします
以下、実行結果です。
ペアごとの有効サンプル数:
age fare sibsp parch
age 714.0 714.0 714.0 714.0
fare 714.0 891.0 891.0 891.0
sibsp 714.0 891.0 891.0 891.0
parch 714.0 891.0 891.0 891.0
age を含むペアでは約714件、age を含まないペアでは891件の有効サンプルがあることがわかります。
ペアによって使えるデータ量が違う のがペアワイズ削除の特徴です。
相関行列を可視化する
相関行列はヒートマップで表示すると直感的に把握できます。
以下、コードです。
import matplotlib.pyplot as plt
# 図と軸を作成
fig, ax = plt.subplots(figsize=(6, 5))
# 相関行列をヒートマップとして描画
im = ax.imshow(
corr_matrix,
cmap='coolwarm',
vmin=-1, vmax=1
)
# 軸ラベルの設定(列名を使う)
ax.set_xticks(range(len(numeric_cols)))
ax.set_yticks(range(len(numeric_cols)))
ax.set_xticklabels(numeric_cols)
ax.set_yticklabels(numeric_cols)
# 各セルに相関係数の数値を表示
for i in range(len(numeric_cols)):
for j in range(len(numeric_cols)):
ax.text(
j, i,
f'{corr_matrix.iloc[i, j]:.2f}',
ha='center', va='center',
color='black'
)
# タイトルとカラーバーを設定
ax.set_title('Correlation Matrix (Pairwise Deletion)')
plt.colorbar(im, ax=ax)
plt.tight_layout()
plt.show()
imshow:行列を画像のように表示しますcmap='coolwarm':青(負の相関)〜赤(正の相関)のカラーマップtextで各セルに相関係数の値を書き込みます
以下、実行結果です。
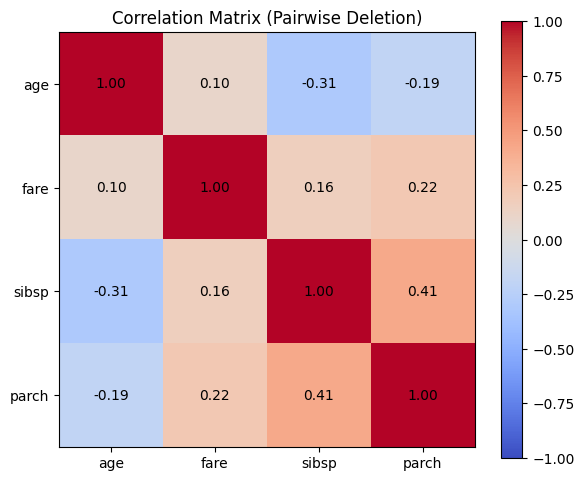
変数間の相関の強さが色で表示されたヒートマップが描画されます。
ペアワイズ削除のメリットとデメリット
ペアワイズ削除には次のような利点があります。
- データを最大限に活用できる:欠損が散在していても、ペアごとに使える行を最大化できる
- 行を一律に削除しない:1つの欠損で大量の行を失うリスクが小さい
一方で、注意すべき点もあります。
- ペアごとに分析対象が違う:ある相関は700件、別の相関は900件と 異なるサンプル から計算されるため、結果の比較が難しい
- 分析手法が限定される:相関分析や記述統計には使えるが、機械学習モデルの学習にはそのまま使えない
- 共分散行列の整合性が崩れる:複数の相関を組み合わせる手法(因子分析、構造方程式モデル)では、ペアごとに異なる行で計算された共分散行列が 正定値でない という数学的問題が起きることがある
削除戦略の整理
第3回・第4回で扱った3つの削除戦略を整理しておきましょう。
| 戦略 | 削除対象 | 主な用途 | |
|---|---|---|---|
| リストワイズ削除(CCA) | 行 | モデル学習用データの作成 | 欠損率が低い & MCAR が想定される |
| 特徴量削除(列削除) | 列 | 高欠損率の不要列を捨てる | 列の欠損率が極端に高い |
| ペアワイズ削除 | 分析単位で部分的 | 相関分析・記述統計 | 機械学習用ではなく EDA 用 |
これら3つはどれかを選ぶというより、組み合わせて使う ものです。
たとえば「欠損率77% の deck 列はまず削除(特徴量削除)→ 欠損率0.22% の embarked 列は対象列を絞って行削除(CCA)→ 欠損率20% の age 列は補完(次回以降)」というように、列ごとに最適な戦略を選ぶのが現実的なアプローチです。
まとめ
今回のポイントを振り返りましょう。
- 特徴量削除(列削除) は、欠損率が極端に高い列を捨てる戦略
- pandas の
drop(columns=[...])で実装でき、欠損率に基づいた自動削除も簡単に書ける - 列削除と行削除は 情報損失のかたちが違う だけで、どちらが優れているかはケース次第
- ペアワイズ削除 は、分析ごとに使えるデータを最大化する考え方
- pandas の
corr()はデフォルトでペアワイズ削除を実行している - ペアワイズ削除は EDA や記述統計に向くが、機械学習の前処理にはそのまま使えない
- 削除戦略は 組み合わせて使う のが現実的