

「テスト環境では精度95%だったのに、実際に運用を始めたら60%しか当たらない」
こんな経験はありませんか?
需要予測や売上予測のプロジェクトで、開発時には素晴らしい成果を見せたモデルが、本番環境では期待を大きく裏切る。
機械学習の世界では、データを学習用と検証用に分けてモデルの性能を評価することが一般的です。
しかし、時系列データを扱う予測において、通常のランダム分割を使うことは、まるで「明日の答えを知っている状態で今日を予測する」ようなものです。
これでは、どんなに高い精度が出ても意味がありません。
時系列データには「時間の流れ」という絶対的な制約があります。
過去のデータで学習し、未来を予測する。
この当たり前の原則を、検証段階でも厳密に守る必要があるのです。
ところが、多くのプロジェクトでは、この基本原則が見落とされています。
データをランダムに70対30に分けて「はい、検証完了」としてしまうと、実は未来の情報が過去の予測に混ざり込んでしまいます(データリーク問題)。
さらに、時系列データ特有の「自己相関」という性質により、隣接する時点のデータは似通っているため、学習データと検証データが実質的に「同じようなもの」になってしまうこともあります。
Contents
検証の3原則:時系列予測を成功に導く鉄則

時系列データの検証を正しく行うには、以下の3つの原則を守ることが不可欠です。
第1原則:時間順を崩さない
最も基本的で、最も重要な原則です。
学習データは必ず検証データより過去でなければなりません。
2024年のデータで学習したモデルを2023年のデータで評価することは、タイムマシンを使ったカンニングと同じです。
現実の運用では、過去のデータしか使えません。
検証もまた、この制約を忠実に再現する必要があります。
第2原則:時系列専用の分割手法を使う
通常のランダム分割やK-fold交差検証は使えません。
代わりに、Growing Window、Sliding Window、Blocked分割など、時系列の特性を考慮した専用の手法を選択します。
それぞれの手法には特徴があり、予測対象やビジネス要件に応じて使い分ける必要があります。
第3原則:近接相関を断つ
株価や売上のような時系列データでは、今日の値と明日の値は強く相関しています。
学習データの最終日と検証データの初日が隣接していると、モデルは「ほぼ同じデータ」を見ることになり、実力以上の精度が出てしまいます。
そのような場合、学習期間と検証期間の間に「隙間(ギャップ)」を設ける検討も必要になります。
代表的な検証フォーマットと使いどころ
時系列クロスバリデーションには、様々な手法があります。
それぞれの特徴と適用場面を理解することで、自社の予測タスクに最適な方法を選択できるようになります。
Expanding Window(拡張窓)方式

あなたが小売チェーンの需要予測担当者だとします。
2020年から事業を始めて、今は2024年末。来年の売上を予測したいとき、どのようにモデルを評価すべきでしょうか。
Expanding Window方式の核心は「歴史から学ぶ量を増やし続ける」という思想にあります。
たとえば、最初の検証(折り目1)では2020年から2022年の3年分で学習し、2023年を予測しています。次の検証(折り目2)では、2023年のデータも学習に加えて4年分とし、2024年を予測します。
なぜこの方式が有効なのでしょうか。
考えてみれば、私たちの実際の業務でも同じことをしています。
来年の計画を立てる時、去年のデータだけでなく、過去数年分のトレンドを参考にしますよね。
特に季節商品を扱う場合、「去年の夏は猛暑で売上が伸びたが、一昨年は冷夏だった」といった複数年のパターンを学習することで、より頑健な予測が可能になります。
ただし、注意点もあります。
市場環境が大きく変わった場合(例えばコロナ禍のような)、古いデータがかえってノイズになる可能性があります。
この方式は「過去は未来の良い指標である」という前提に立っているのです。
Sliding Window(スライディング窓)方式

今度は、あなたがファッションECサイトの在庫管理者だとしましょう。
ファッションのトレンドは移り変わりが激しく、2年前の売れ筋は今では全く参考になりません。
Sliding Window方式は、まさにこういった状況のために設計されています。
たとえば、常に「直近12ヶ月」という固定の窓で学習する、といった感じです。
窓が時間とともに右にスライドしていく様子を想像してください。2023年1-3月を予測する時は2022年のデータで学習し、2023年4-6月を予測する時は2022年4月から2023年3月のデータで学習します。
この方式の賢い点は、古い情報を「忘れる」ことです。
人間の記憶のように、最近の出来事は鮮明に覚えているけれど、古い出来事は忘れていく。
市場の変化が速い環境では、この「忘却」が予測精度の向上につながるのです。
実務での活用例を挙げると、スマートフォンアクセサリーの需要予測などが典型的です。
新機種が出るたびに市場が一変するため、1年以上前のデータはむしろ邪魔になることがあります。
Blocked分割方式
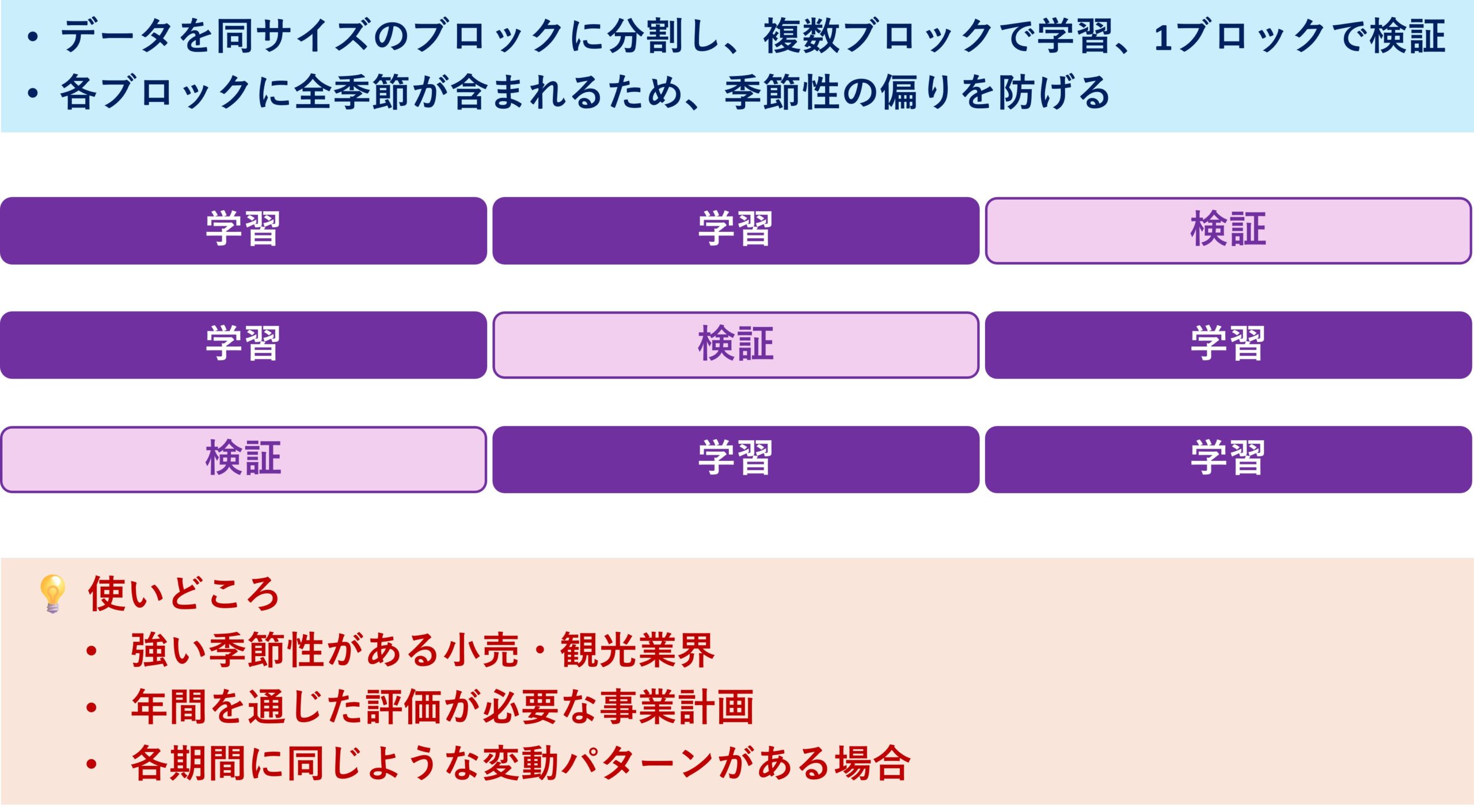
レストランチェーンの売上予測を考えてみましょう。
夏はビールが売れ、冬は鍋料理が人気。このように強い季節性がある場合、学習データと検証データの分け方を間違えると大きな問題になります。
たとえば、単純に時系列を前半と後半に分けてしまうとどうなるでしょう。学習データに夏が多く、検証データに冬が多いといった偏りが生じ、夏のパターンだけで冬を予測することになってしまいます。もちろん、精度は大きく低下します。
Blocked分割方式は、この問題を避けるための方法です。
データを「年単位」など同じ長さのブロックに分け、交差検証では複数のブロックを学習に使い、残りのブロックを検証に使います。各ブロックには春夏秋冬すべてが含まれるため、季節性の偏りを避け、公平にモデルを評価できます。
注意点として、Blocked分割は「未来のデータで過去を検証する」形になることもあります。したがって、将来予測の実運用を想定した評価には不向きですが、年間を通じた分布をバランス良く反映させたい場合の汎化性能評価には非常に有効です。
この方式は、電力需要予測、観光業の来客数予測、アイスクリームや暖房器具など強い季節性を持つ商品の需要予測で特に威力を発揮します。
Gap方式

株式投資のアルゴリズムを開発している場面を想像してください。
今日の株価は昨日の株価と強く相関しています。
もし月曜日までのデータで学習して火曜日を予測すると、モデルは「月曜日の終値に近い値」と予測すれば高い精度が出てしまいます。
でも、これは本当の予測能力でしょうか。
Gap方式は、この「近すぎることによる情報漏洩」を防ぎます。
学習期間と検証期間の間に意図的な空白(ギャップ)を作ります。たとえば、6月までのデータで学習し、7月をスキップして、8月のデータで検証します。
この1ヶ月のギャップにより、「直前の値をそのまま使う」という安易な予測ができなくなります。
実務では、発注リードタイムがある製造業でも有効です。
今日発注しても商品が届くのは2週間後。この2週間のギャップを検証に組み込むことで、より現実的な評価が可能になります。
モデルによって最適な分割方式は変わる
興味深いことに、同じデータセットでも、使用するモデルによって最適な分割方法は変わります。
ある研究では、深層学習モデル(GRUなど)はBlocked分割やGap方式で良好な結果を示す一方、従来型の機械学習モデル(SVRなど)はSliding Window方式で優れた性能を発揮することが報告されています。
これは、深層学習モデルが長期的なパターンを学習する能力に優れている一方、従来型モデルは直近のデータに敏感に反応する傾向があるためと考えられます。
つまり、分割方法の選択は、単なる「お作法」ではなく、モデルの性能を最大化するための重要なチューニング要素なのです。
さらに、データの特性も考慮する必要があります。
季節性が強いデータではBlocked分割が有効ですし、トレンドが急激に変化するデータではSliding Windowが適しています。
自己相関が強いデータでは、Gap方式が必須となります。
このように、モデル、データ、ビジネス要件の3つの観点から、最適な検証方法を選択することが、予測精度向上への近道となります。
参考文献
- Bergmeir, C., & Benítez, J. M. (2012). “On the use of cross-validation for time series prediction.” Knowledge-Based Systems, 26, 1-13.
- Scherf, M., Rieger, J., & Litz, R. (2019). “Machine-Learning-Based Exchange Rate Prediction Using Survey Expectations.” Journal of Forecasting, 38(7), 643-662.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
明日から使える検証設計

以下のチェック項目を使って、自社の予測プロジェクトの検証設計を見直してみましょう。
✅基本設計の確認
まず、予測の更新頻度を明確にします。
毎日更新するのか、週次か、月次か。
この頻度に合わせて、検証の粒度も決定します。
次に、評価期間の妥当性を検討します。
1日先を予測するモデルを1年先のデータで評価しても意味がありません。
実際の運用で必要とされる予測期間で評価することが重要です。
✅データ特性の把握
自己相関関数(ACF)を計算し、データの相関がどの程度の期間続くかを把握します。
相関が1週間続くなら、最低でも1週間のギャップが必要です。
また、季節性の有無と周期を確認します。
年次の季節性があるなら、最低1年分のデータを含む検証が必要です。
✅運用シミュレーション
モデルの再学習頻度を決定します。
毎月再学習するなら、月次のSliding Windowが適しているかもしれません。
早期終了の条件も重要です。
性能が一定基準を下回ったら再学習する、といったルールを検証段階から組み込みます。
✅バックテストの設計
過去のどの時点でも同じ方法で予測できたか、を確認するバックテストは必須です。
2020年のコロナ禍のような異常事態でも、選択した検証方法が機能するかを確認しましょう。
検証とは「現場運用リハーサル」

時系列クロスバリデーションは、単なる精度測定の手段ではありません。
それは、モデルが現実世界でどのように振る舞うかを事前に知るための、重要なリハーサルなのです。
正しい分割方法を選択することは、最も費用対効果の高い精度向上施策といえるでしょう。
高価な外部データを購入したり、複雑なモデルを開発したりする前に、まず検証方法を見直してみてください。
それだけで、予測精度が大幅に改善することも珍しくありません。
「テスト環境での精度」ではなく「本番環境での精度」を追求する。
この当たり前のことを実現するために、時系列クロスバリデーションの正しい理解と実践が不可欠です。
明日からでも、自社の予測プロジェクトで使っているデータ分割方法を確認してみてください。
もしランダム分割を使っているなら、それを時系列専用の方法に変えるだけで、より信頼性の高い予測モデルへと進化させることができるはずです。
予測の精度は、分け方で決まる。この真実を、ぜひ実務で活かしていただければ幸いです。
今回のまとめ
時系列予測モデルが使えるかどうかは、モデルの複雑さよりもデータの「分け方」で決まることも、少なくありません。
通常のランダム分割は、未来の情報で過去を予測してしまう「データリーク」を引き起こし、モデルの性能を不当に高く見せてしまうため、決して用いてはなりません。
予測を成功させるには、学習データを必ず検証データより過去にするという時間順の原則を厳守し、時系列専用のクロスバリデーション手法を適用することが不可欠です。
たとえば……
- 長期トレンドを学習させるなら過去のデータを蓄積する「Expanding Window」
- トレンド変化が速い市場には最新データを用いる「Sliding Window」
- 季節性には「Blocked分割」
……が適しています。
また、自己相関が強いデータでは、学習期間と検証期間の間に「Gap」を設ける工夫も有効です。
結局のところ、検証とは単なる精度測定ではなく、モデルが現場でどう振る舞うかを試す「運用のリハーサル」に他なりません。
このリハーサルを正しく行うことこそが、信頼性の高い予測モデルを構築するための最も確実な一歩となるのです。