
データセット手にしたら、数理モデルを作ったりする前に、通常はEDA(探索的データ分析)を実施します。
端的に言うと、データと仲良くなるための会話です。
ざっくり次のような流れになります。
- データコンディションチェック(欠測値や基本統計量など)
- 単変量の分析(各変数の分布など)
- 多変量の分析(変数間の関係性など)
正直、EDA(探索的データ分析)はほぼ半分は似たような分析を実施します。
そこで、EDA(探索的データ分析)の中で似たような分析は自動化しようということで幾つかのライブラリーがあります。
今回は、「データセット手にしたら、Pythonでサクッと半自動EDA(探索的データ分析)をしよう」というお話しをします。
Rに関しては「Rでシンプル半自動EDA(探索的データ分析)」で紹介しています。
半自動EDAライブラリー
色々な半自動EDAライブラリーがあります。
今回紹介するのは、以下の3つです。
- Pandas-Profiling
- D-Tale
- Sweetviz
Pandas-Profilingは、3つの中で最もシンプルです。

D-Taleは、逆に最も細部に渡ったEDAを実施することができ、自動というかD-Taleを使いEDAを実施する感じになります。

Sweetvizも、Pandas-Profilingと同じぐらいシンプルですが、2つのデータセット間の比較をすることができます。

ですので、先ずはPandas-Profilingを利用し、物足りないときにD-Taleを利用し、データセット間の比較が必要なときにSweetvizを利用するのがいいでしょう。
この3つのライブラリーをインストールされていない方は、以下です。
pip install pandas-profiling pip install dtale pip install sweetviz
今回利用するデータセット
今回は、みんな大好きアヤメのデータとタイタニックのデータを使います。
この2つのデータセットの概要説明は、以下の記事を参考にしていただければと思います。
■データセットの概要説明
「予測モデルは機械学習パイプライン化しよう(Python)
https://www.salesanalytics.co.jp/datascience/datascience007/
このサンプルデータはScikit-learn(sklearn)のものを利用するので、Scikit-learn(sklearn)をインストールされていない方は、インストールして頂ければと思います。
ライブラリーの読み込み
ライブラリーを読み込みます。
では、コードです。
# 例で利用するデータセット from sklearn.datasets import fetch_openml, load_iris # データセット分割(学習データ・テストデータ) from sklearn.model_selection import train_test_split # EDAツール from pandas_profiling import ProfileReport import dtale import sweetviz as sv
アヤメのデータに対し半自動EDA

アヤメのサンプルデータを読み込みます。
以下、コードです。
irisXy = load_iris(as_frame=True, return_X_y=False).frame
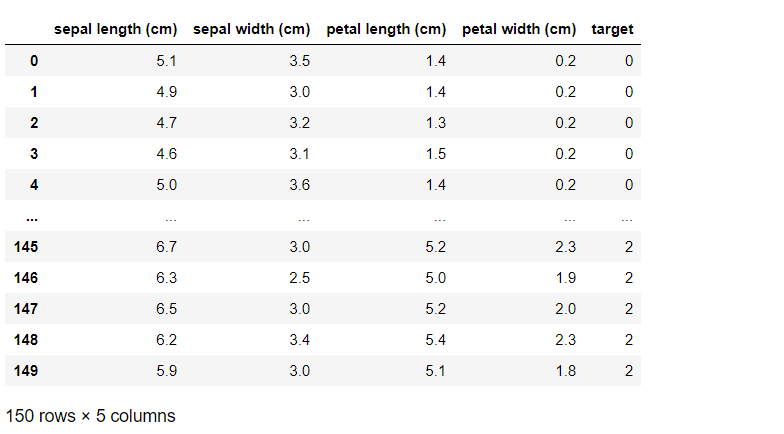
どのようなデータセットを読み込んだのか、確認してみます。
以下、コードです。
irisXy
以下、実行結果です。
次に、読み込んだデータセットを、学習データとテストデータに分解します。
irisXy_train, irisXy_test = train_test_split(irisXy, test_size=0.5)
- irisXy_train:学習データ
- irisXy_test:テストデータ
どのようなデータセットを読み込んだのか、確認してみます。
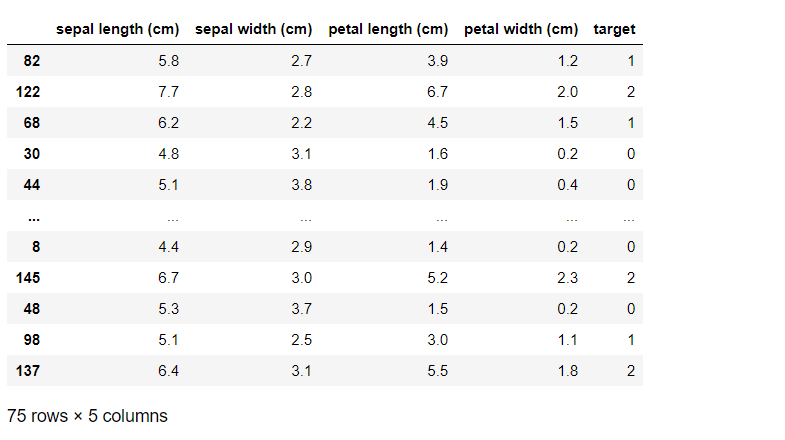
以下、学習データを確認するコードです。
irisXy_train
以下、実行結果です。
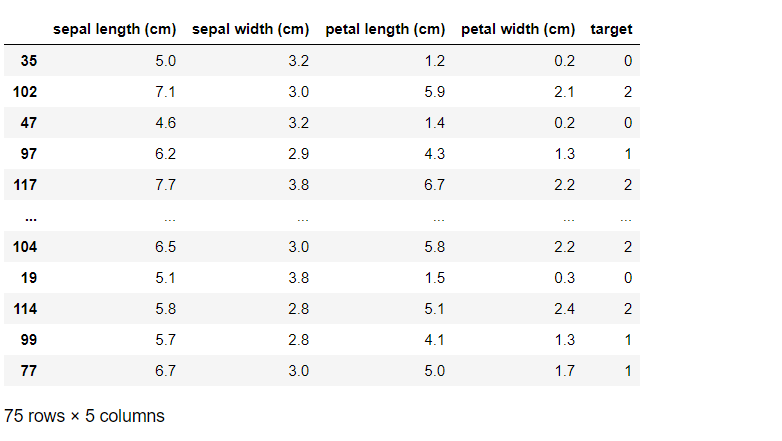
以下、テストデータを確認するコードです。
irisXy_test
以下、実行結果です。
データセット「irisXy」がどのようなデータなのか、以下の3つの手段を通じて見ていきます。
- Pandas-Profiling
- D-Tale
- Sweetviz
さらに、データセット「irisXy_train」(学習データ)とデータセット「irisXy_test」(テストデータ)がどのようなデータなのか、以下の手段を通じて比較しながら見ていきます。
- Sweetviz
アヤメのデータをPandas-Profiling
データセット「irisXy」をPandas-Profilingを使い、どのようなデータなのか確認します。
以下、コードです。
profile_iris = ProfileReport(irisXy, explorative=True)
profile_iris.to_file("profile_iris.html")
profile_iris
以下、実行結果です。
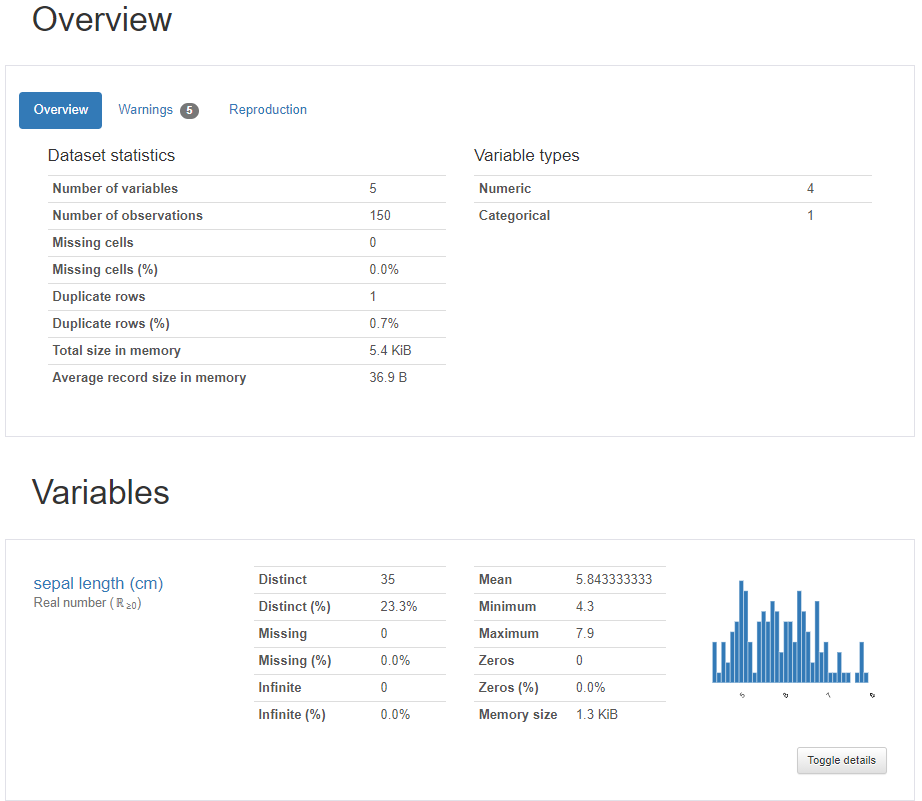
基本、Jupyter Notebook などに実行結果が埋め込まれますが、生成されたHTMLから実行結果を見ることもできます。
アヤメのデータをD-Tale
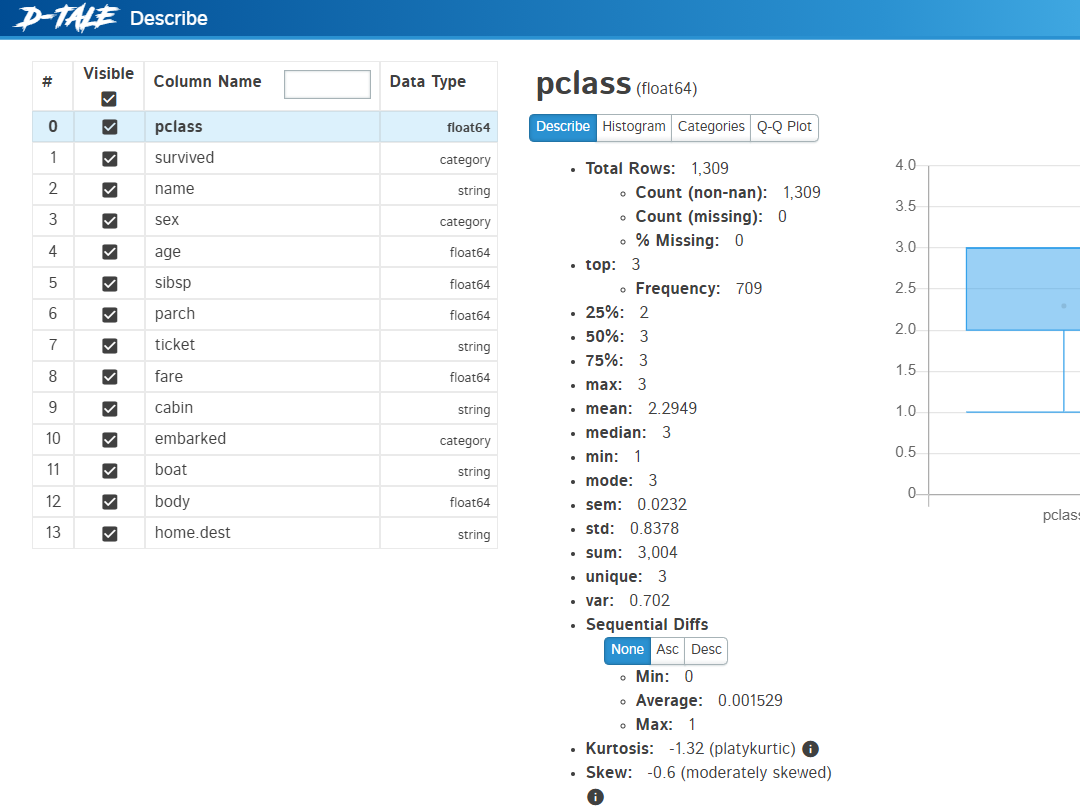
データセット「irisXy」をD-Taleを使い、どのようなデータなのか確認します。
以下、コードです。
dtale.show(irisXy)
以下、実行結果です。
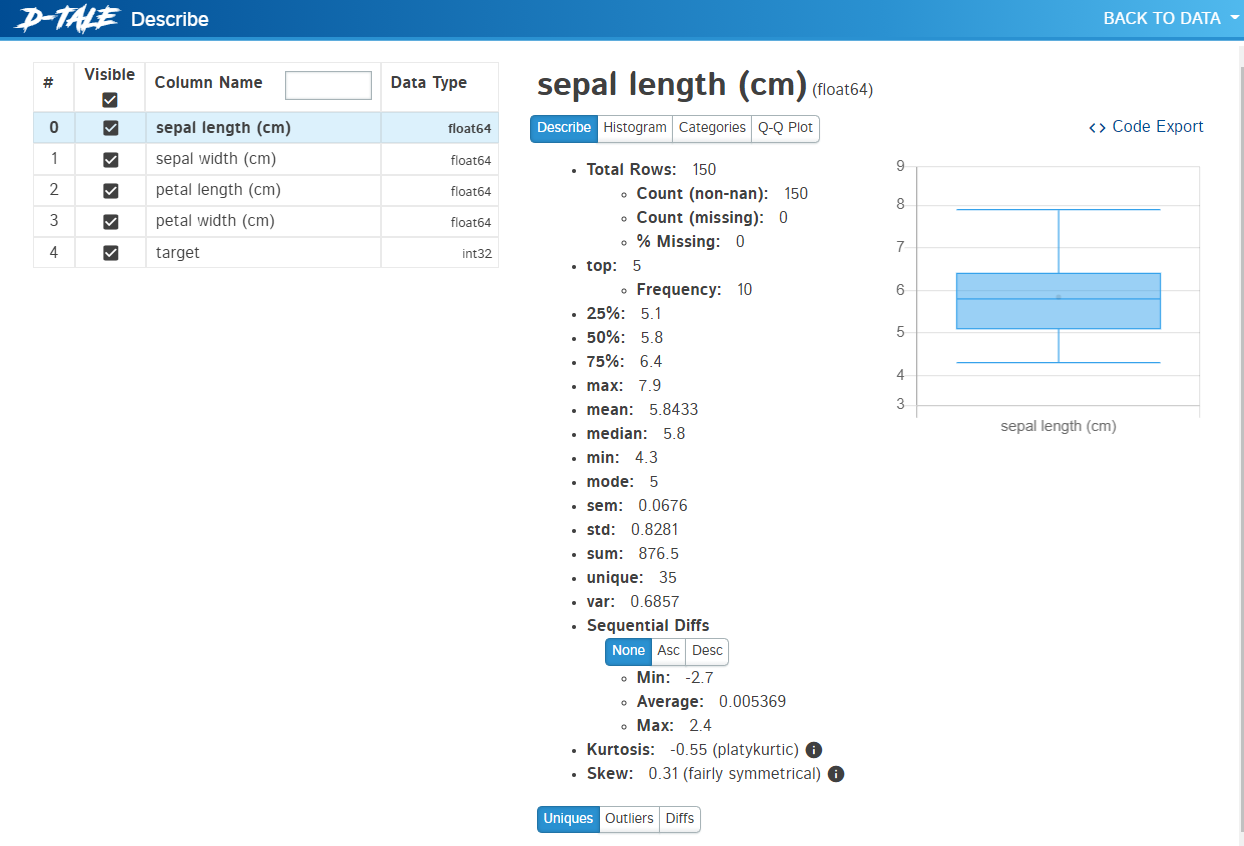
D-Taleは、自動というかD-Taleを使いEDAを実施する感じになります。
アヤメのデータをSweetviz
データセット「irisXy」をSweetvizを使い、どのようなデータなのか確認します。
以下、コードです。
sweet_iris = sv.analyze(irisXy)
sweet_iris.show_html("sweet_iris.html")
以下、実行結果です。
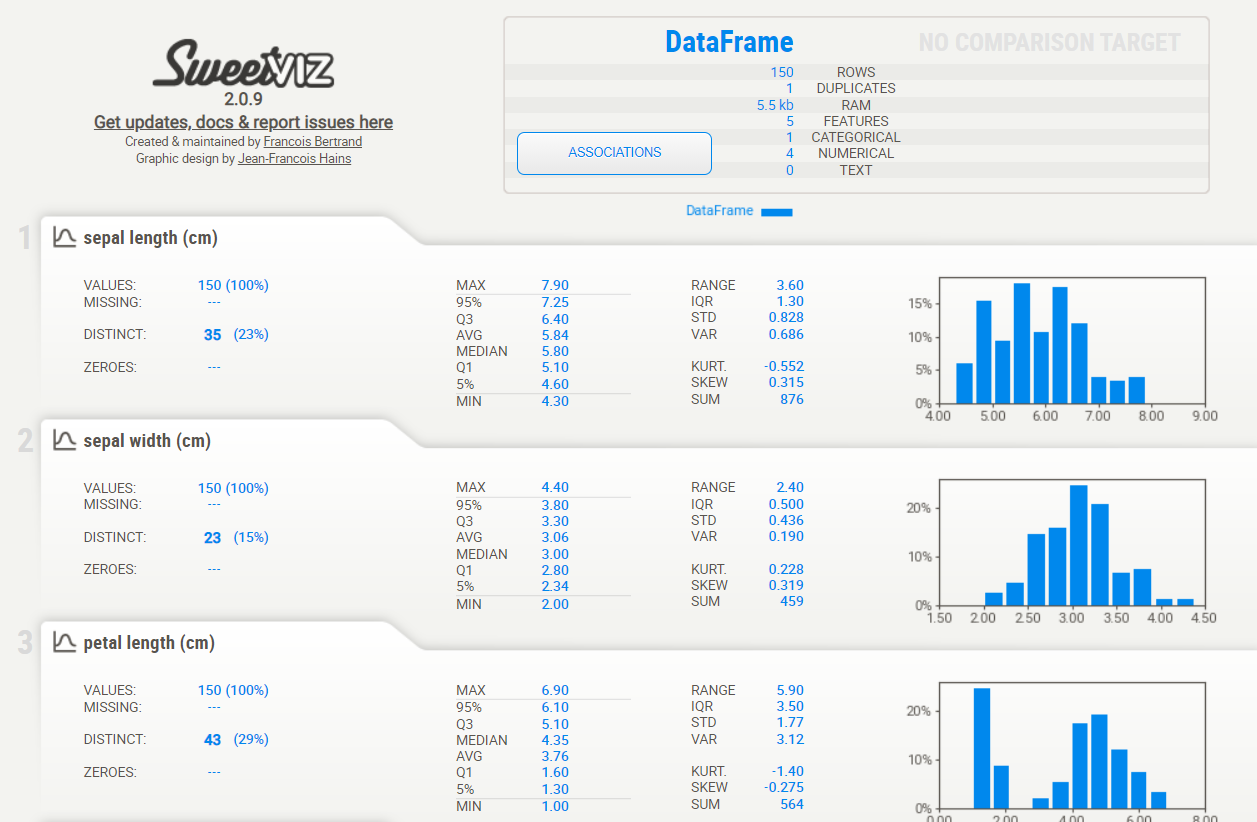
アヤメの学習データとテストデータをSweetvizで比較
Sweetvizを使い、データセット「irisXy_train」(学習データ)とデータセット「irisXy_test」(テストデータ)がどのようなデータなのか確認します。
以下、コードです。
sweet_iris_compare = sv.compare([irisXy_train, "Train"], [irisXy_test, "Test"])
sweet_iris_compare.show_html("sweet_iris_compare.html")
以下、実行結果です。
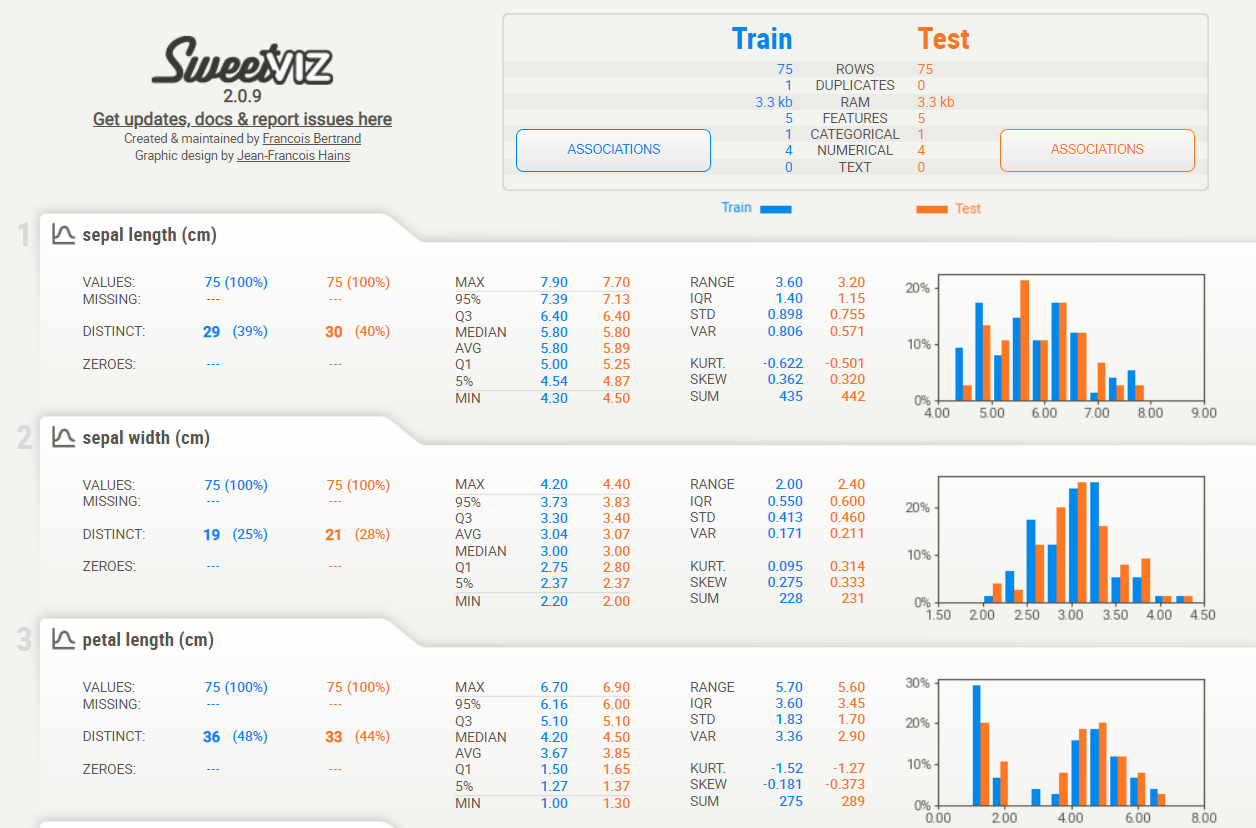
タイタニックのデータに対し半自動EDA

タイタニックのサンプルデータを読み込みます。
以下、コードです。
titanicXy = fetch_openml("titanic", version=1, as_frame=True, return_X_y=False).frame
どのようなデータセットを読み込んだのか、確認してみます。
以下、コードです。
titanicXy
以下、実行結果です。
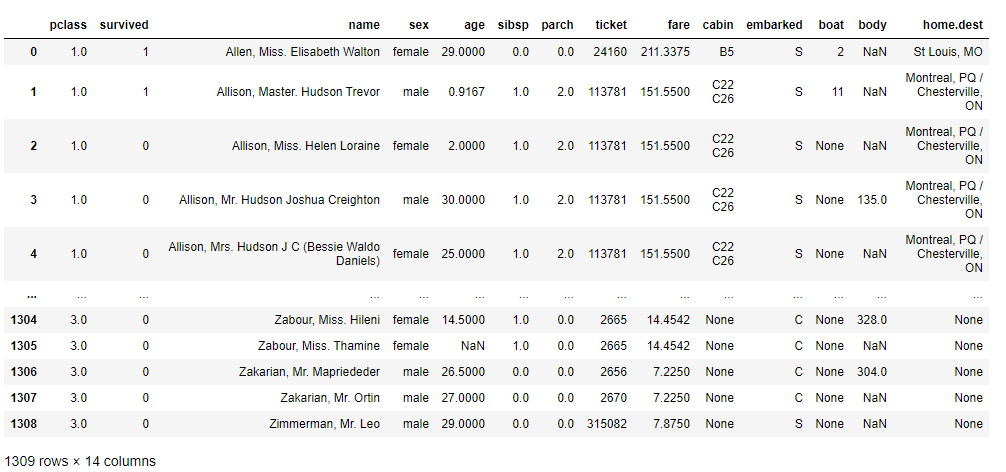
次に、読み込んだデータセットを、学習データとテストデータに分解します。
titanicXy_train, titanicXy_test = train_test_split(titanicXy, test_size=0.5)
- titanicXy_train:学習データ
- titanicXy_test:テストデータ
どのようなデータセットを読み込んだのか、確認してみます。
以下、学習データを確認するコードです。
titanicXy_train
以下、実行結果です。
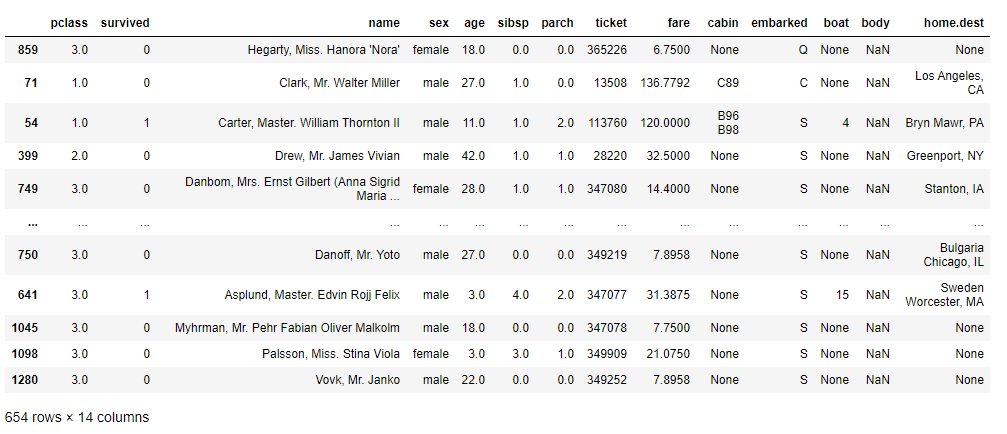
以下、テストデータを確認するコードです。
titanicXy_test
以下、実行結果です。
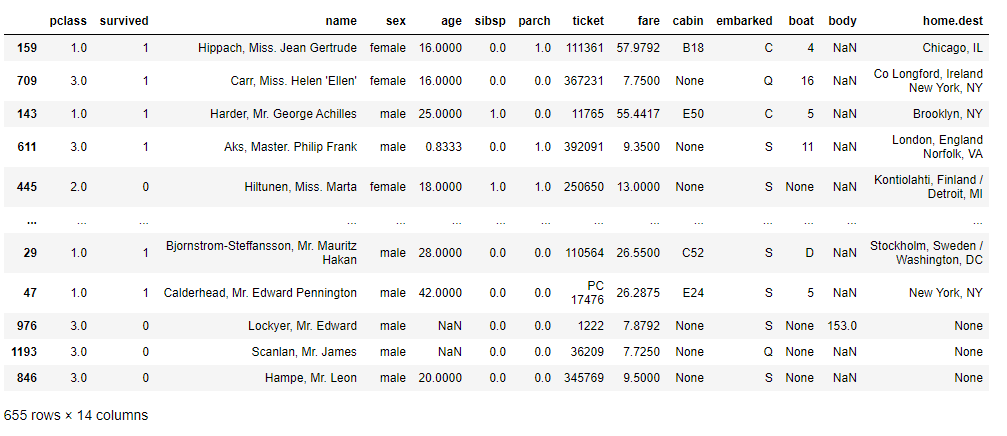
データセット「titanicXy」がどのようなデータなのか、以下の3つの手段を通じて見ていきます。
- Pandas-Profiling
- D-Tale
- Sweetviz
さらに、データセット「titanicXy_train」(学習データ)とデータセット「titanicXy_test」(テストデータ)がどのようなデータなのか、以下の手段を通じて比較しながら見ていきます。
- Sweetviz
タイタニックのデータをPandas-Profiling
データセット「titanicXy」をPandas-Profilingを使い、どのようなデータなのか確認します。
以下、コードです。
profile_titanic = ProfileReport(titanicXy, explorative=True)
profile_titanic.to_file("profile_titanic.html")
profile_titanic
以下、実行結果です。
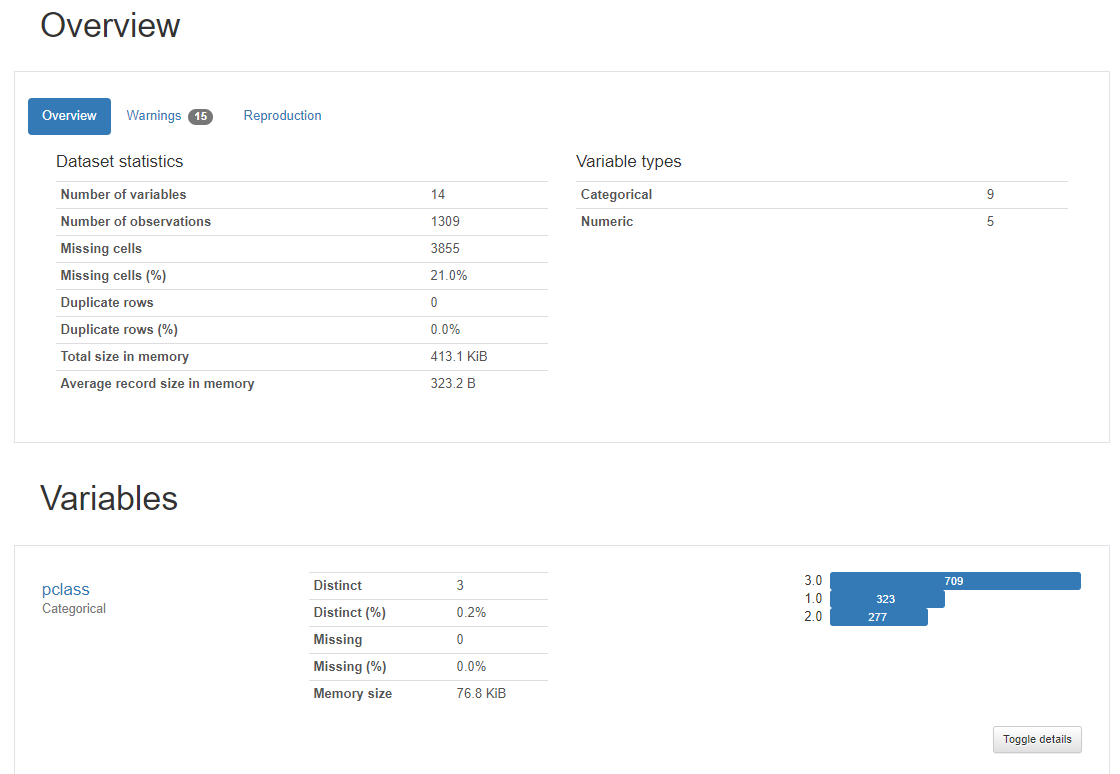
基本、Jupyter Notebook などに実行結果が埋め込まれますが、生成されたHTMLから実行結果を見ることもできます。
タイタニックのデータをD-Tale
データセット「titanicXy」をD-Taleを使い、どのようなデータなのか確認します。
以下、コードです。
dtale.show(titanicXy)
以下、実行結果です。
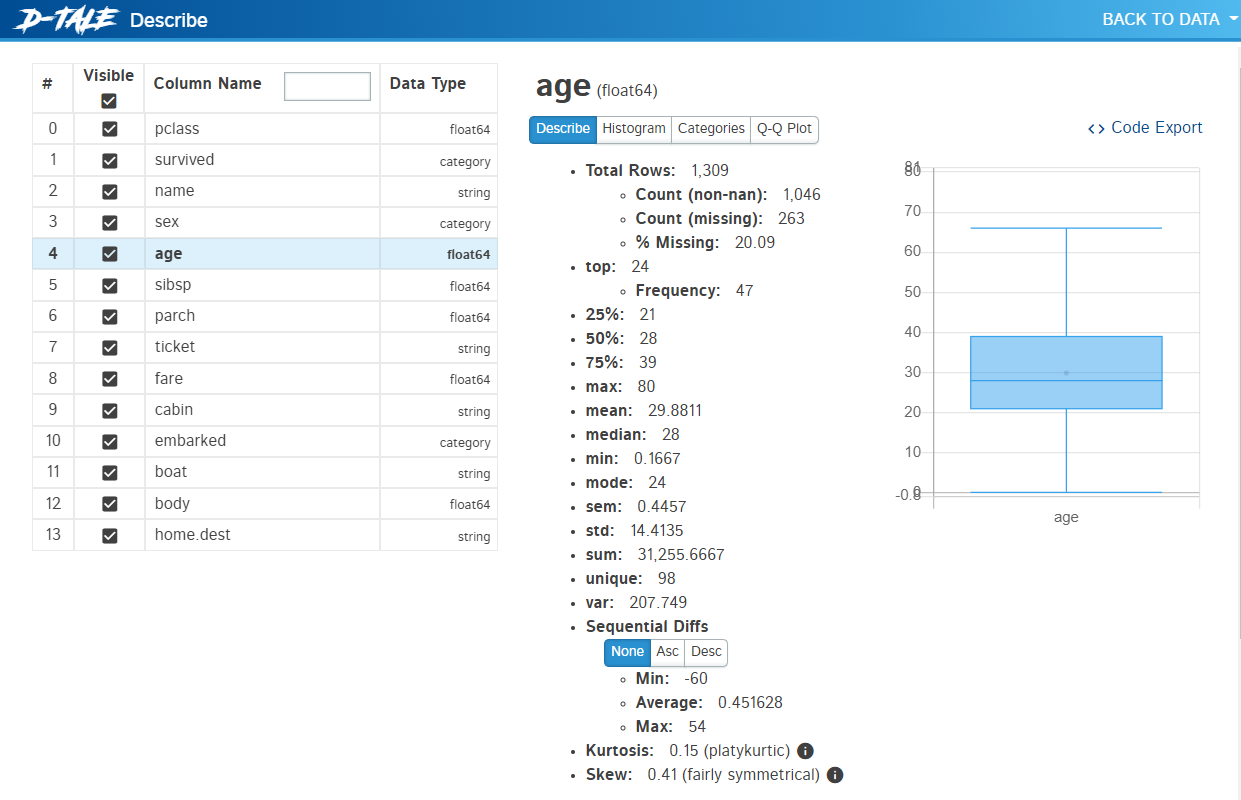
D-Taleは、自動というかD-Taleを使いEDAを実施する感じになります。
タイタニックのデータをSweetviz
データセット「titanicXy」をSweetvizを使い、どのようなデータなのか確認します。
以下、コードです。
sweet_titanic = sv.analyze(titanicXy)
sweet_titanic.show_html("sweet_titanic.html")
以下、実行結果です。
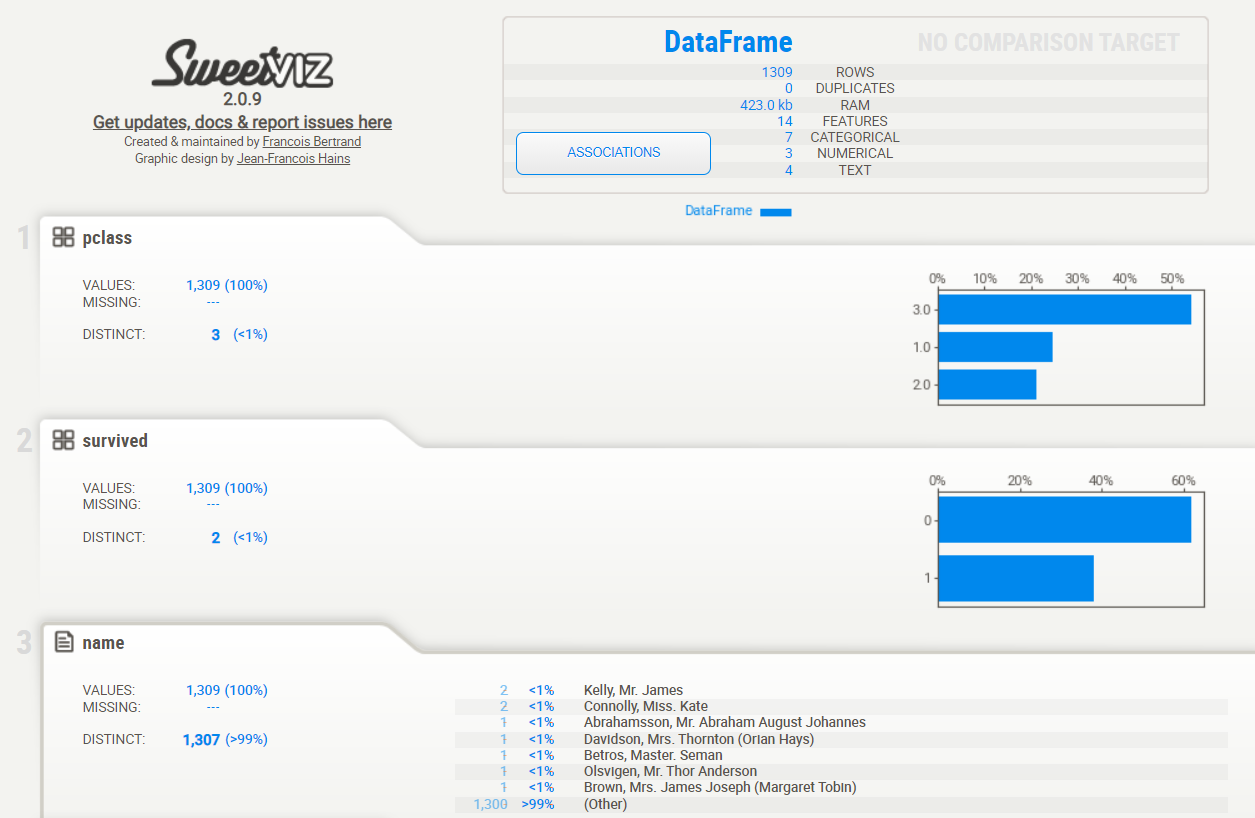
タイタニックの学習データとテストデータをSweetvizで比較
Sweetvizを使い、データセット「titanicXy_train」(学習データ)とデータセット「titanicXy_test」(テストデータ)がどのようなデータなのか確認します。
以下、コードです。
sweet_titanic_compare = sv.compare([titanicXy_train, "Train"], [titanicXy_test, "Test"])
sweet_titanic_compare.show_html("sweet_titanic_compare.html")
以下、実行結果です。
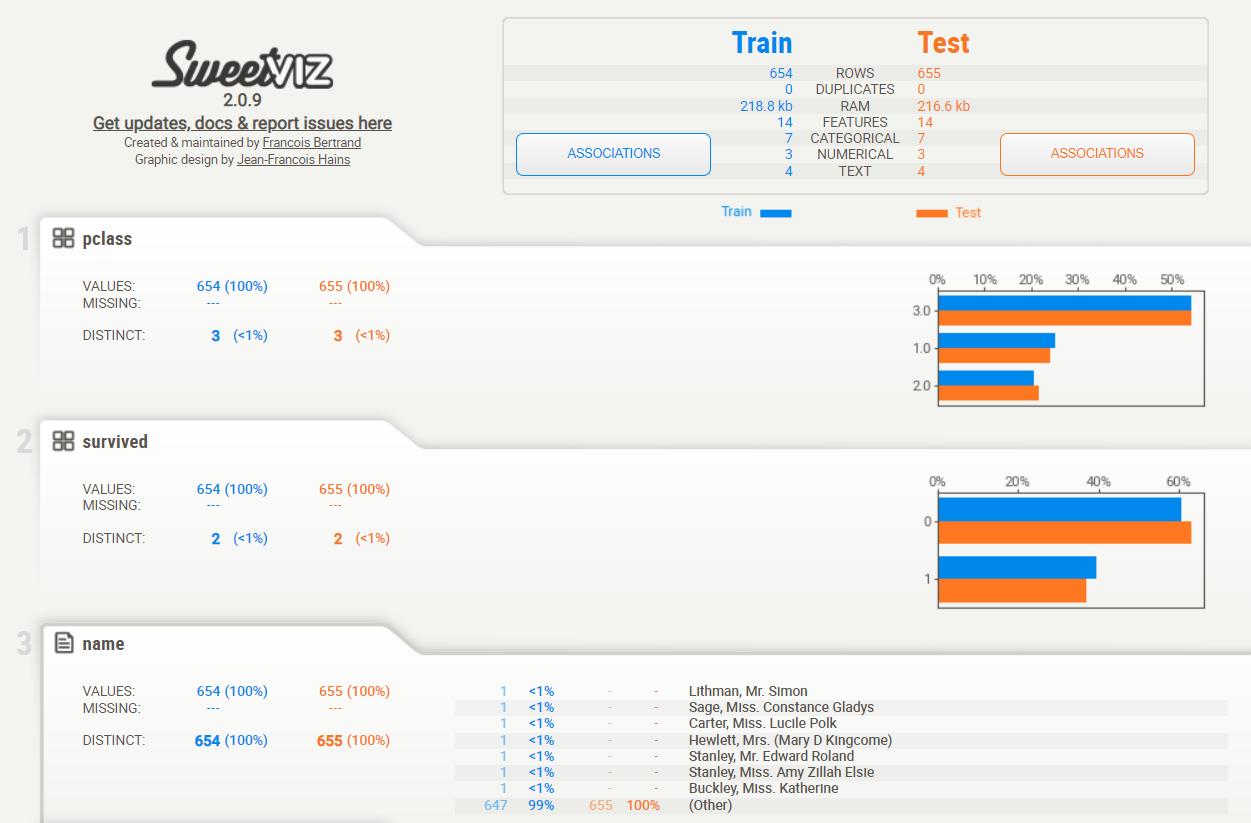
まとめ
今回は、「データセット手にしたら、Pythonでサクッと自動EDA(探索的データ分析)をしよう」というお話しをしました。
以下の3つのライブラリーを利用すると、サクッとEDA(探索的データ分析)を実施することができます。
- Pandas-Profiling
- D-Tale
- Sweetviz
興味のある方は、試してみてください。
Rに関しては「Rでシンプル半自動EDA(探索的データ分析)」です。今回とほぼ同じ内容です。