

データセットを手にしたら、最初に実施するのがEDA(探索的データ分析)です。
端的に言うと、データと仲良くなるための会話です。
EDA(探索的データ分析)はほぼ半分は似たような分析を実施します。EDA(探索的データ分析)の中で似たような分析は自動化しようということで幾つかのライブラリーがあります。
Pythonに関しては「データセット手にしたら、Pythonでサクッと半自動EDA(探索的データ分析)をしよう」で紹介しました。
Rではどうでしょうか?
今回は、「Rでシンプル半自動EDA(探索的データ分析)」というお話しをします。
今回紹介するライブラリー
色々な半自動EDAライブラリーがあります。
今回紹介するのは、以下の3つです。
- DataExplorer
- summarytools
- inspectdf
DataExplorerは、PythonのPandas-Profilingと最も類似しており、EDA(探索的データ分析)結果のダッシュボードが1コードで出力されます。自動分析だけでなく、色々な分析やデータ処理がなされます。
![]()
https://boxuancui.github.io/DataExplorer/
summarytoolsは、データ分析の経験に浅い方がサクッと実施するのに向いています。多機能ではありませんが、最低限のことを実施することが出来ます。
![]()
https://github.com/dcomtois/summarytools
inspectdfも、summarytoolsと同様にデータ分析の経験に浅い方がサクッと実施するのに向いています。大きな違いは、2つのデータセット間の比較を出来ることです。
![]()
https://github.com/alastairrushworth/inspectdf
この3つのライブラリーをインストールされていない方は、以下です。
install.packages('DataExplorer', dependencies = TRUE)
install.packages('summarytools', dependencies = TRUE)
install.packages('inspectdf', dependencies = TRUE)
今回利用するデータセット
今回は、みんな大好きアヤメのデータとタイタニックのデータを使います。
「データセット手にしたら、Pythonでサクッと半自動EDA(探索的データ分析)をしよう」と全く同じサンプルデータを使います。Scikit-learn(sklearn)のものです。
Pythonとやり取りするためのライブラリーである「reticulate」を使いますので、まだインストールされていない方はインストールして頂ければと思います。

https://rstudio.github.io/reticulate/
さらに今回は、ライブラリー「dplyr」の関数「glimpse」を使って、データセットの概要を確認しますので、まだインストールされていない方はインストールして頂ければと思います。
![]()
https://github.com/tidyverse/dplyr
ライブラリー「dplyr」の関数「glimpse」を使った各変数の状況確認は、よく実施されるものです。このよく実施されるものと、専用のライブラリーを使うことの違いも確認して頂ければと思います。
半自動EDAの流れ
最初に簡単に、今回の流れを説明します。
- glimpse で各変数の状況確認
- summarytools で各変数の状況確認
- Data Explorer のダッシュボード生成
- inspectdf による比較分析
アヤメ(iris)に関しては、inspectdf による比較分析を実施いたしません。タイタニック(titanic)に関しては、生存者(survived)と死亡者(died)でinspectdf による比較分析を実施いたします。
EDA(探索的データ分析)の経験の浅い方は、Data Explorer などが実施していることを参考にして頂くと、何をすべきかが何となく見えてくるかと思います。
また、EDA(探索的データ分析)は、今回の専用のライブラリーでサクッと実施し終了するものではありません。多くの場合、その後の何かしらのEDA(探索的データ分析)を実施することになると思います。
ライブラリーの読み込み
ライブラリーを読み込みます。
以下、コードです。
# ライブラリー読み込み library(DataExplorer) library(summarytools) library(inspectdf) library(reticulate) #Pythonを動かすライブラリー library(dplyr) #今回はglimpse利用のため
データセットの準備
Pythonとやり取りするためのライブラリーである「reticulate」を使い、Scikit-learn(sklearn)のアヤメのデータセットとタイタニックのデータセットを、Rのデータフレームとします。
先ず、PythonのSklearnのデータセットを読み込みます。
以下、コードです。
# PythonのSklearnのデータセットの読み込み
## Pyhtonへ
repl_python()
## Pythonコード(サンプルデータの読み込み)
from sklearn.datasets import fetch_openml, load_iris
irisXy = load_iris(as_frame=True,
return_X_y=False).frame
titanicXy = fetch_openml("titanic",
version=1,
as_frame=True,
return_X_y=False).frame
次に、R上にデータセットを持ってきます。
以下、コードです。
# Pythonのデータセットの受取 sklearn_iris <- data.frame(py$irisXy) sklearn_titanic <- data.frame(py$titanicXy)
アヤメのデータに対し半自動EDA

アヤメのデータをglimpse で各変数の状況確認
以下、コードです。
# glimpse で各変数の状況確認 glimpse(sklearn_iris)
以下、実行結果です。

アヤメのデータをsummarytools で各変数の状況確認
以下、コードです。RStudioでの実施を想定しています。
# summarytools で各変数の状況確認 dfSummary(sklearn_iris) %>% view()
以下、RStudio上の実行結果です。
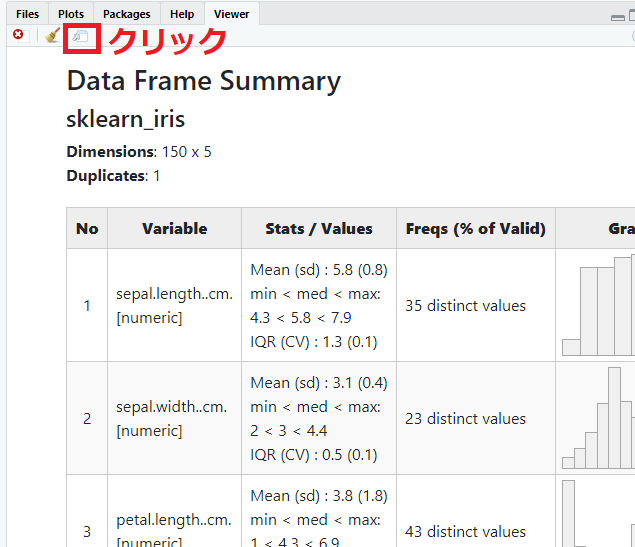
「Show in new window 」(赤く囲ったところ)をクリックすると、ブラウザ上に表示されます。
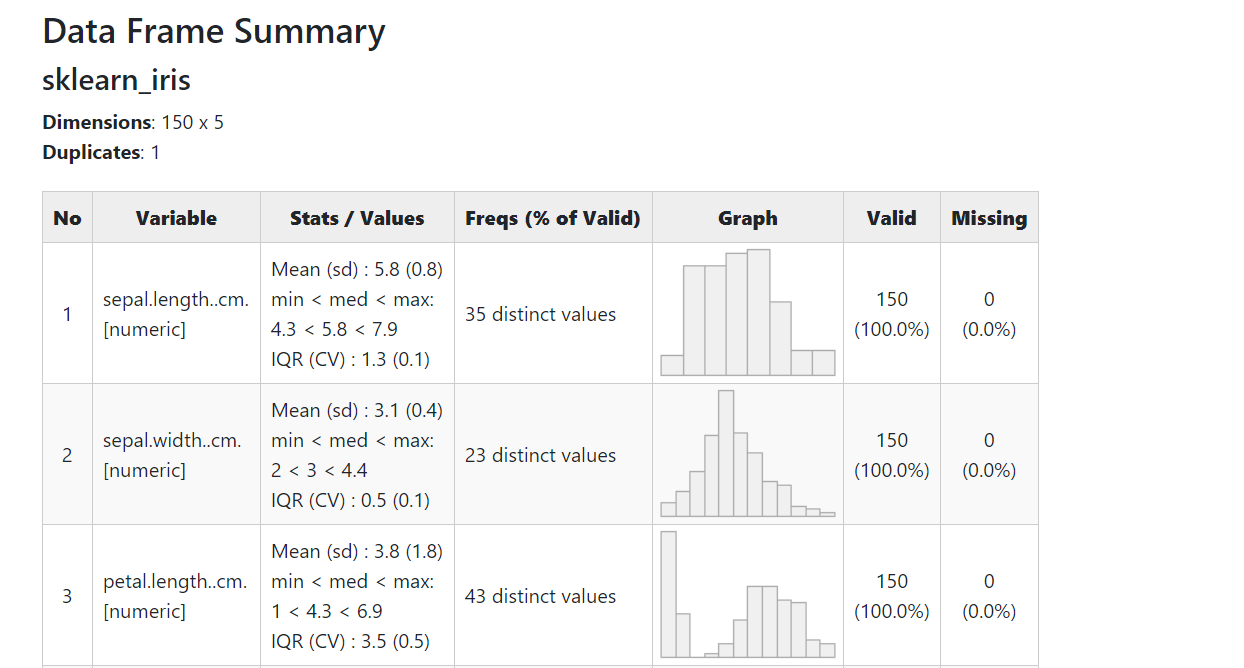
アヤメのデータをData Explorer のダッシュボード生成
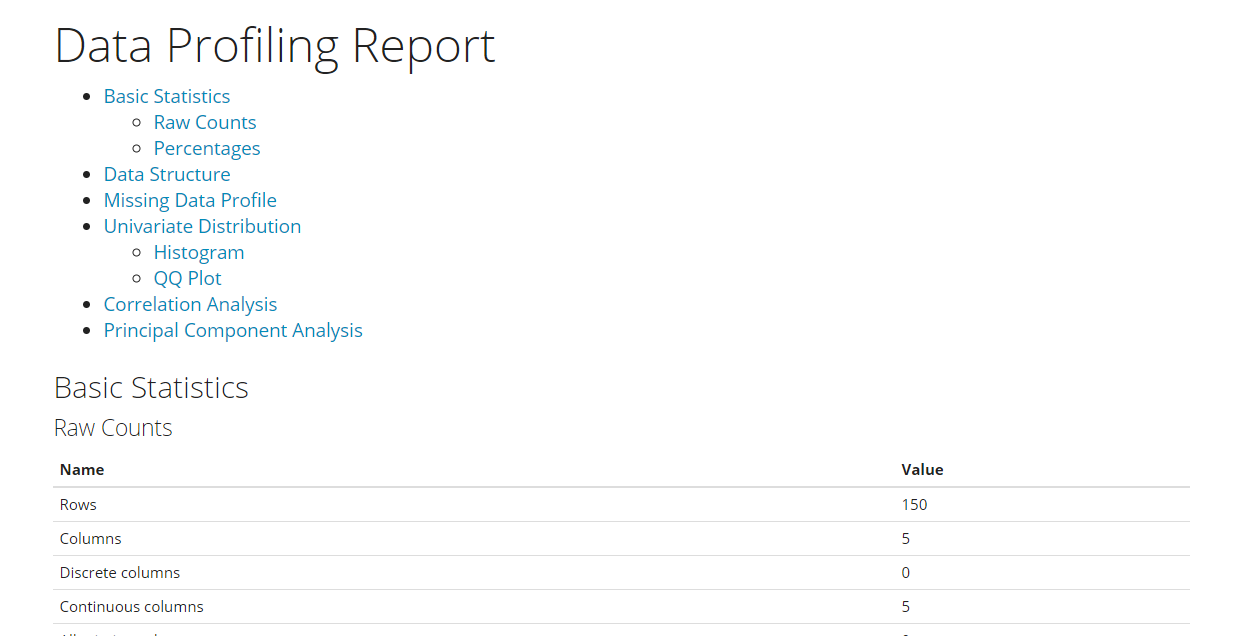
Data Explorerは、1コードで以下のEDA(探索的データ分析)を自動で実施します。
- Basic Statistics:基本統計量
- Data Structure:データ構造(変数など)
- Missing Data Profiling:欠測状況
- Continuous and Categorical Distribution Profiling:各変数の分布状況
- Relationships :変数間の関係性
以下、コードです。
# Data Explorer のダッシュボード生成 create_report(sklearn_iris)
以下、実行結果です。
タイタニックのデータに対し半自動EDA

タイタニックのデータをglimpse で各変数の状況確認
以下、コードです。
# glimpse で各変数の状況確認 glimpse(sklearn_titanic)
以下、実行結果です。

List型になっている変数(10列目、12列目、14列目)があるのでChar型(文字列型)へ変換します。
以下、コードです。
# List型になっている変数をChar型へ変換
for(i in c(10,12,14)){
sklearn_titanic[,i] <- as.character(sklearn_titanic[,i])
}
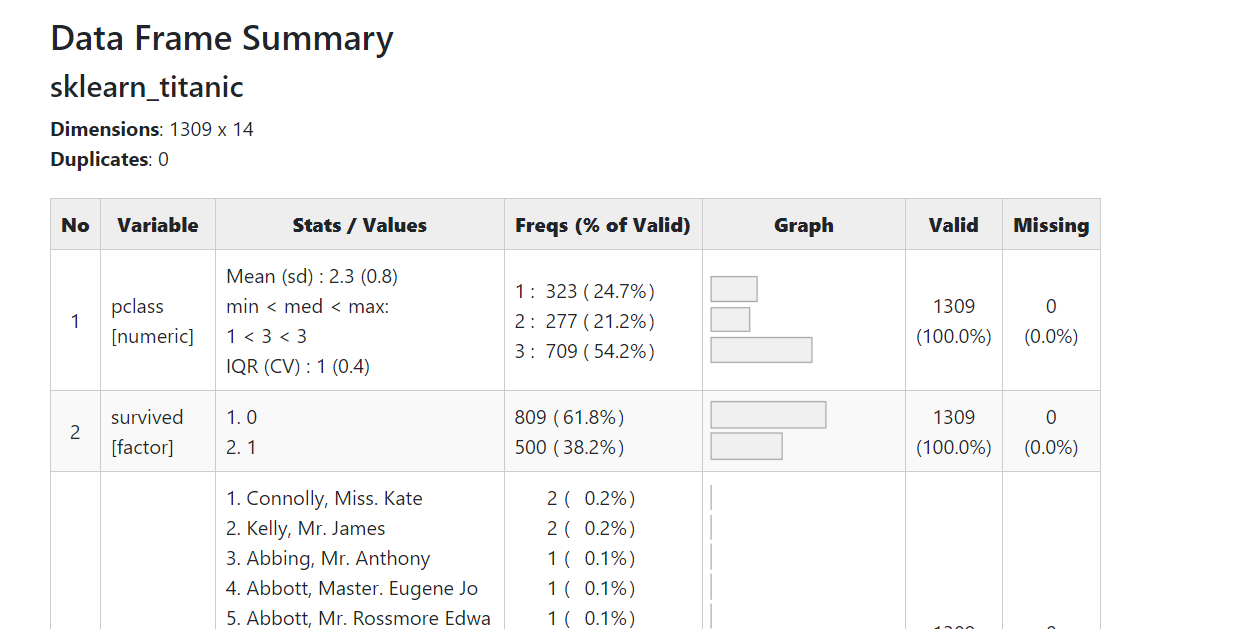
タイタニックのデータをsummarytools で各変数の状況確認
以下、コードです。RStudioでの実施を想定しています。
# summarytools で各変数の状況確認 dfSummary(sklearn_titanic) %>% view()
以下、RStudio上の実行結果です。
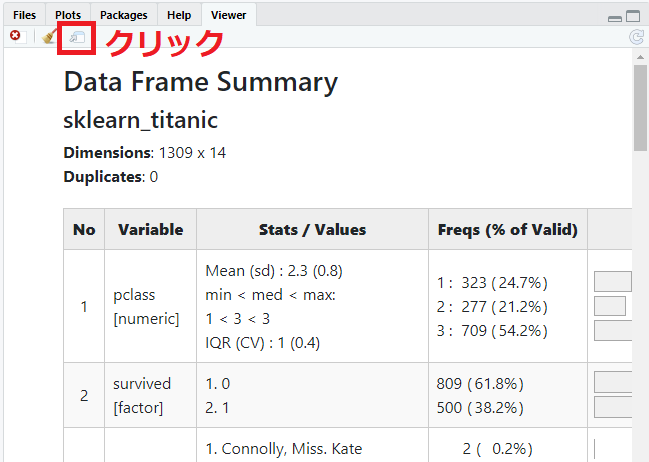
「Show in new window 」(赤く囲ったところ)をクリックすると、ブラウザ上に表示されます。
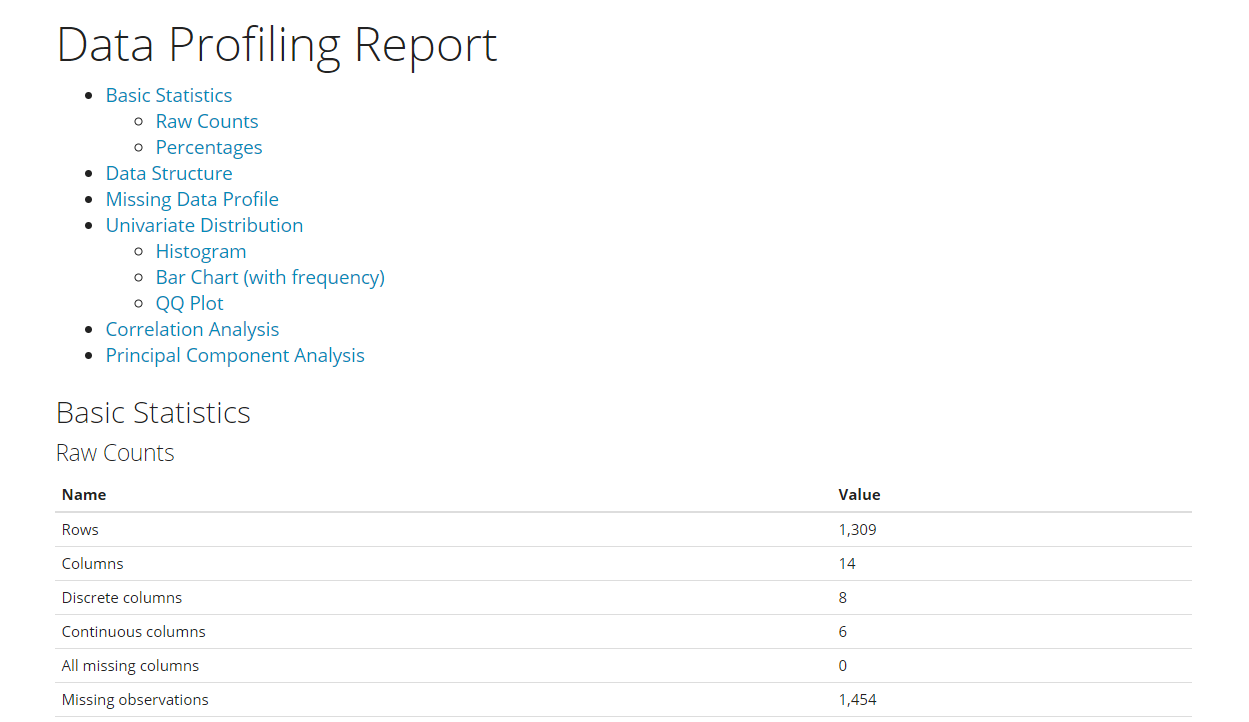
タイタニックのデータをData Explorer のダッシュボード生成
Data Explorerは、1コードで以下のEDA(探索的データ分析)を自動で実施します。
- Basic Statistics:基本統計量
- Data Structure:データ構造(変数など)
- Missing Data Profiling:欠測状況
- Continuous and Categorical Distribution Profiling:各変数の分布状況
- Relationships :変数間の関係性
以下、コードです。
# Data Explorer のダッシュボード生成 create_report(sklearn_titanic)
以下、実行結果です。
タイタニックのデータをinspectdf で比較分析
sklearn_titanicのデータセットを、死亡者(died)と生存者(survived)に分割します。
# sklearn_titanicのデータセットの分割(diedとsurvived) ## 死亡者(died) sklearn_titanic_died <- sklearn_titanic %>% filter(survived == 0) ## 生存者(survived) sklearn_titanic_survived <- sklearn_titanic %>% filter(survived == 1)
以下に関し、最初に全体を表示し、次に比較分析を実施していきます。
- 型
- naの割合
- カテゴリカル変数(最頻値の割合)
- カテゴリカル変数(分布)
- 数値変数
- 数値変数間の相関
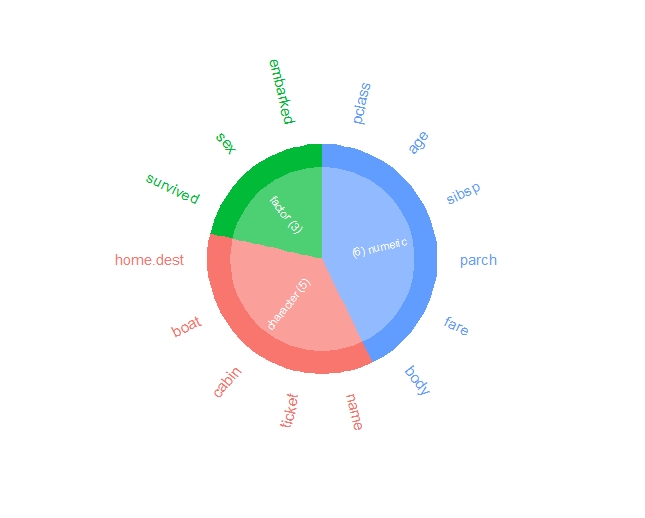
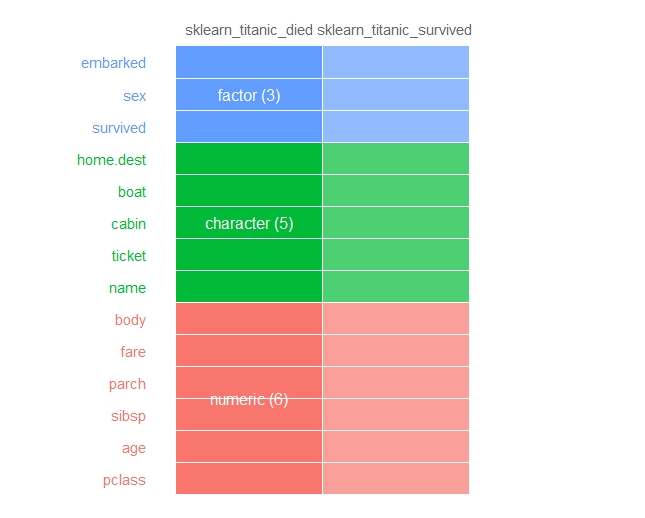
型
以下、コードです。
# inspectdf による比較分析
## 型
inspect_types(sklearn_titanic) %>% show_plot()
inspect_types(sklearn_titanic_died,
sklearn_titanic_survived) %>% show_plot()
以下、実行結果です。
naの割合
以下、コードです。
## naの割合
inspect_na(sklearn_titanic) %>% show_plot()
inspect_na(sklearn_titanic_died,
sklearn_titanic_survived) %>% show_plot()
以下、実行結果です。
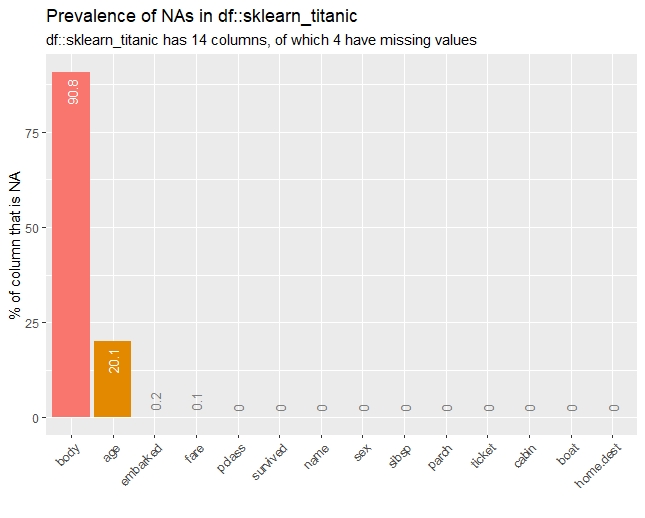
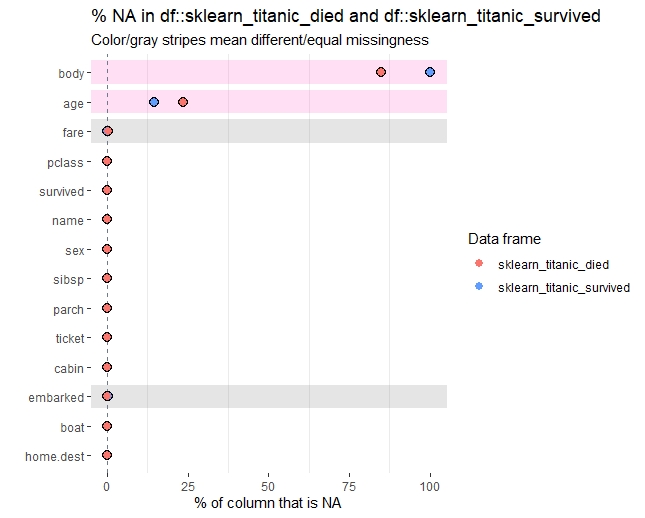
カテゴリカル変数(最頻値の割合)
以下、コードです。
## カテゴリカル変数(最頻値の割合)
inspect_imb(sklearn_titanic) %>% show_plot()
inspect_imb(sklearn_titanic_died,
sklearn_titanic_survived) %>% show_plot()
以下、実行結果です。
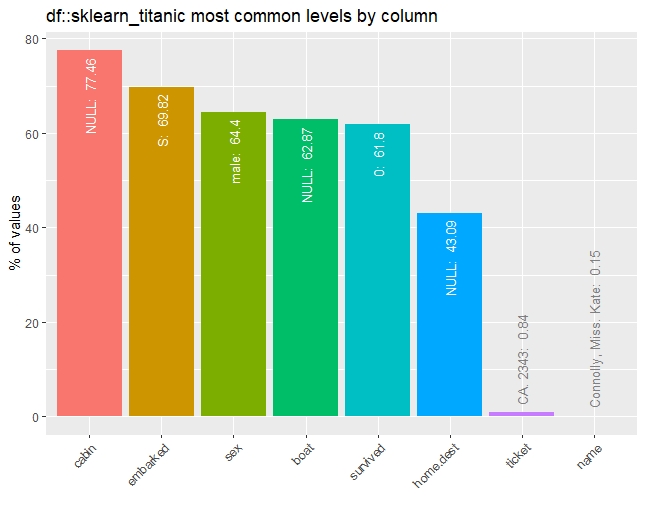
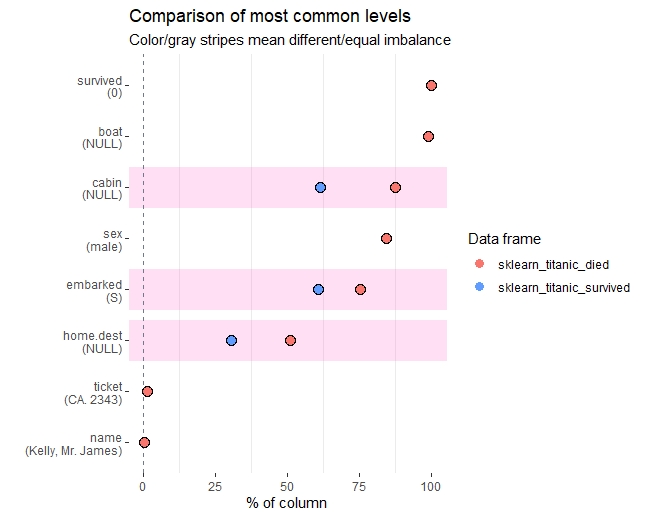
カテゴリカル変数(分布)
以下、コードです。
## カテゴリカル変数(分布)
inspect_cat(sklearn_titanic) %>% show_plot()
inspect_cat(sklearn_titanic_died,
sklearn_titanic_survived) %>% show_plot()
以下、実行結果です。
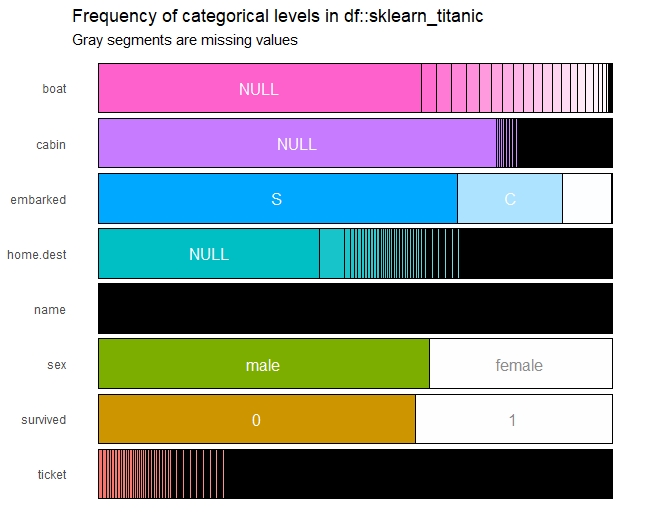
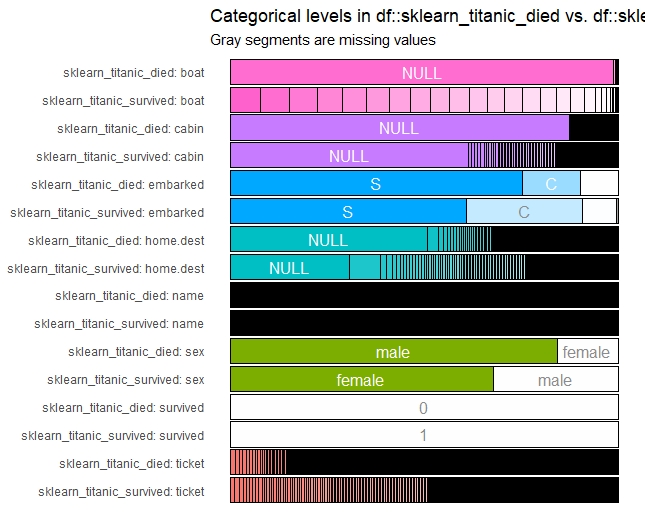
数値変数
以下、コードです。
## 数値変数
inspect_num(sklearn_titanic) %>% show_plot()
inspect_num(sklearn_titanic_died,
sklearn_titanic_survived) %>% show_plot()
以下、実行結果です。
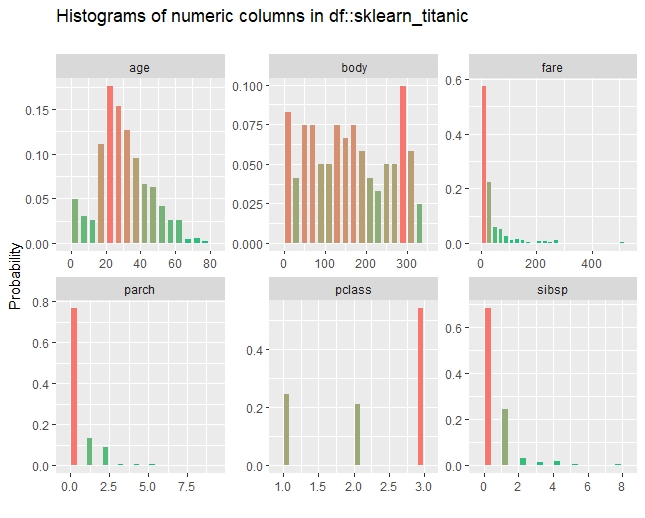
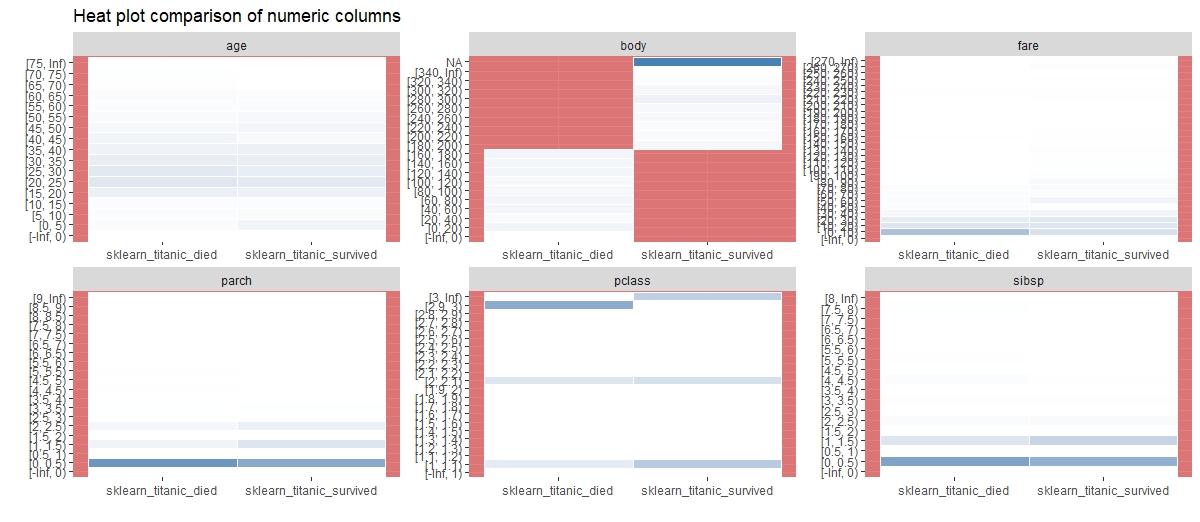
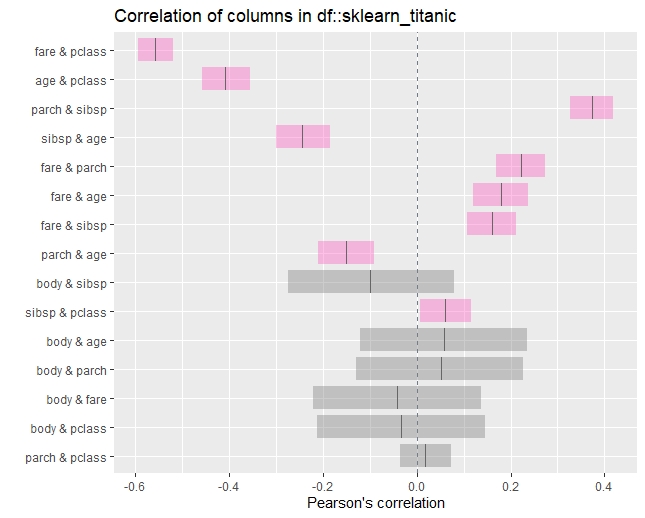
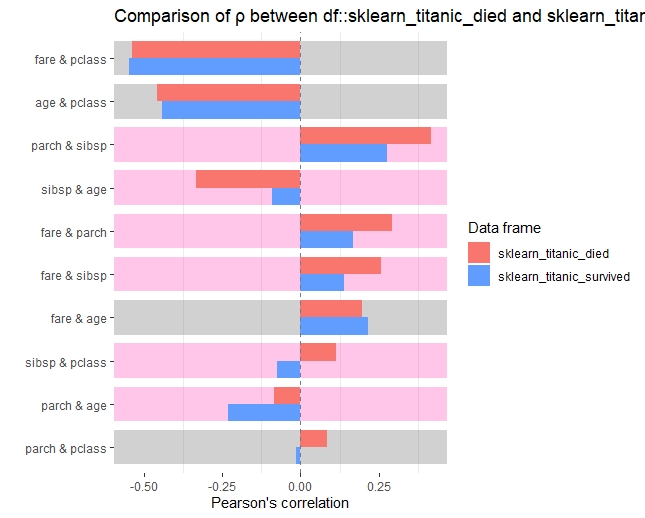
数値変数間の相関
以下、コードです。
## 数値変数間の相関
inspect_cor(sklearn_titanic) %>% show_plot()
inspect_cor(sklearn_titanic_died,
sklearn_titanic_survived) %>% show_plot()
以下、実行結果です。
まとめ
今回は、「Rでシンプル半自動EDA(探索的データ分析)」というお話しをしました。
色々な半自動EDAライブラリーがあります。今回紹介したのは、以下の3つです。
- DataExplorer
- summarytools
- inspectdf
興味のある方は、試してみてください。
Pythonに関しては「データセット手にしたら、Pythonでサクッと半自動EDA(探索的データ分析)をしよう」です。今回とほぼ同じ内容です。