

ハイパーパラメータのチューニングは、機械学習のモデルを最適化する過程で避けては通れない重要なステップです。
前回の記事では、ハイパーパラメータチューニングの基本概念と、なぜハイパーパラメータチューニングが重要であるのか、そして手動チューニングと自動チューニングの違いについて学びました。
これらの基本的な概念を持って、今回は具体的なツール、Optunaの紹介へと進んでいきます。
Optunaはその効率性と柔軟性で注目されており、その背後にある考え方や主な特徴、そして基本的な使い方を紹介します。
Optunaの背景と特徴
機械学習の分野が急速に進化する中、ハイパーパラメータの最適化はモデルの性能向上のための重要なステップとなっています。この需要に答える形で、Optunaは2017年にPreferred Networksによって開発されました。
Optunaの最大の特徴は、ユーザーフレンドリーなAPIと強力な最適化アルゴリズムを組み合わせて、高速かつ効果的なハイパーパラメータチューニングを可能にすることです。また、複雑なハイパーパラメータの構造や条件付きのパラメータを扱うことができ、さまざまな最適化戦略をサポートしています。
Optunaのもう一つの大きな魅力は、アクティブなコミュニティと豊富なドキュメントです。これにより、新しいユーザーでも迅速に導入し、問題に応じた最適化を行うことができます。さらに、多くの実例やチュートリアルが提供されているため、具体的な使用方法や応用例を学ぶのも容易です。
Optunaのインストール
Optunaはpipを使用して簡単にインストールすることができます。
以下、コードです。
pip install optuna
スタディ(study)を定義し最適化する
スタディ(study)とは?
Optunaの使用を開始するには、まず「スタディ(study)」を作成します。
スタディ(study)を一言でいうと最適化セッション全体で、最適化の目的や方向(最小化または最大化)を定義したものです。
もう少し丁寧に説明すると特定の目的関数に対してハイパーパラメータを最適化するための一連のプロセスです。
Optuneによるハイパーパラメータチューニングは、どのようにスタディ(study)を作るのか(定義するのか)で決まります。
スタディ(study)の要素を述べる前に、コードのイメージを示します。(x - 2) ** 2の最小値を求める問題です。
import optuna
def objective(trial):
x = trial.suggest_float('x', -10, 10)
return (x - 2) ** 2
study = optuna.create_study(direction='minimize')
study.optimize(objective, n_trials=100)
パッと見た感じ、objective、trial、suggestなどが登場していることが分かります。
スタディ(study)を作成後に、最適化(optimize)していることも分かります。
スタディ(study)の要素
このスタディ(study)は、以下の要素から成り立っています。
目的関数 (Objective Function):
ハイパーパラメータの特定の組み合わせを評価するための関数です。この関数の出力(通常はスカラー値)は、ハイパーパラメータの組み合わせの「良さ」もしくは「悪さ」を示すものとして使用されます。たとえば、機械学習モデルの構築検討時には、この関数はモデルの検証エラー(MSEなど)を返すことが多いです。検証エラー(MSEなど)は値が小さい方が良いです。
トライアル (Trial):
ハイパーパラメータの特定の組み合わせと、その組み合わせに対する目的関数の結果を表したものです。ハイパーパラメータチューニングとは、最適なトライアルを見つけることです。
サジェスト(Suggest):
探索すべきハイパーパラメータの範囲や条件、およびその他の制約を定義したもの。trial.suggest_メソッドを使用して定義します。
trial.suggest_float(name, low, high, step=None, log=False):
- 指定された範囲の浮動小数点数をサジェストします。
step: この値が指定されると、サジェストされる浮動小数点数はstepの倍数になります。log: これがTrueの場合、値は対数スケールでサジェストされます。
trial.suggest_int(name, low, high, step=None, log=False):
- 指定された範囲の整数をサジェストします。
log: これがTrueの場合、値は対数スケールでサジェストされます。
trial.suggest_categorical(name, choices):
- 与えられた選択肢からカテゴリカルな値をサジェストします。選択肢は文字列や数値のリストであることが多いです。
サンプラー (Sampler):
どのハイパーパラメータの組み合わせを次に試すかを決定するためのアルゴリズムや手法のことです。例えば、ランダムサンプリングやベイズ最適化などが該当します。Optunaの場合、デフォルトはベイズ最適化です。
- RandomSampler: ハイパーパラメータの値をランダムにサンプリングします。
- TPESampler (Tree-structured Parzen Estimator): デフォルトのサンプラーです。ベイズ最適化の一種で、過去のトライアルの結果を考慮して、次のハイパーパラメータの値を提案します。
- GridSampler: 与えられたハイパーパラメータのグリッド上のすべての組み合わせを試します。
プルーナー (Pruner):
プルーナーは、進行中のトライアルを早期に終了するかどうかを決定するコンポーネントです。これにより、非効果的なトライアルを早期に打ち切り、リソースを節約することができます。
- MedianPruner: トライアルの中間結果が他のトライアルの中央値よりも悪い場合、そのトライアルを早期終了します。
- SuccessiveHalvingPruner: 予定されたリソースの一部だけを使用して初期の評価を行い、良好な結果を示すトライアルだけにリソースを増やしていきます。
スタディ(study)の作成と最適化
Optunaの「スタディ(study)」は、上記の要素を組み合わせて定義されます。
スタディ(study)を定義したら、次にこのスタディ(study)を作成(optuna.create_study)します。このとき、最適化の方向(最小化または最大化)を指定します。
これは、目的関数 (Objective Function)の出力(通常はスカラー値)が最小となるハイパーパラメータを探するか、最大となるハイパーパラメータを探するか、ということです。
そして、スタディ(study)のoptimizeメソッドを呼び出すことで、最適化のセッションが開始され、最小となるハイパーパラメータの探索(もしくは、最大となるハイパーパラメータの探索)が始まります。
ハイパーパラメータの探索範囲の設定次第(要は、サジェストの設定次第)で、非常に時間が掛かることがあるので注意しましょう。
はじめてのOptunaチューニングの実践
Optunaを実際に使用してハイパーパラメータの最適化を行う際の基本的なステップを紹介します。
以下の3つの例で説明します。
- 先程の例(
(x - 2) ** 2を最小値を求める問題) - 回帰問題(カリフォルニアの住宅価格データセット)
- 分類問題(アヤメの種類を分類するデータセット)
先程の例((x - 2) ** 2を最小値を求める問題)
先ずは、先程の例((x - 2) ** 2を最小値を求める問題)を使って説明します。
Optunaライブラリをインポートしています。
import optuna
目的関数の定義:
まず、ハイパーパラメータの組み合わせを評価するための目的関数を定義します。この関数は、OptunaのTrialオブジェクトを引数に取ります。
def objective(trial):
x = trial.suggest_float('x', -10, 10)
return (x - 2) ** 2
objectiveという名前の関数を定義しています。この関数はOptunaによって繰り返し呼び出され、ハイパーパラメータの組み合わせに対する目的関数の値を返します。trial.suggest_floatメソッドを使用して、名前がxの浮動小数点数のハイパーパラメータをサジェストしています。このハイパーパラメータxの探索範囲は-10から10までとなっています。- 目的関数として、
(x - 2) ** 2を定義しています。この関数は、x=2で最小値0を取ります。
スタディの作成:
ハイパーパラメータの最適化の方向(最小化または最大化)を指定して、スタディを作成します。
study = optuna.create_study(direction='minimize')
新しいOptunaの「study」を作成しています。direction='minimize'という引数は、目的関数の値を最小化することを目指すことを示しています。
最適化の実行:
study.optimizeメソッドを使用して、目的関数の最適化を行います。この際、試行回数や並列実行の数などを指定できます。
study.optimize(objective, n_trials=100)
結果の確認:
最適化が完了した後、スタディから最良の結果やハイパーパラメータの組み合わせを取得できます。
print(study.best_value) print(study.best_params)
作成したstudyを使用して、objective関数を最適化します。具体的には、100回のトライアルを実行して、最適なxの値を探します。
結果の可視化:
Optunaには結果を可視化するための便利なツールが組み込まれています。例えば、最適化の過程やハイパーパラメータの分布を表示できます。
optuna.visualization.plot_optimization_history(study)
このように、Optunaを使用すると、ハイパーパラメータの最適化をシンプルなコードで簡単に実行することができます。
さまざまなハイパーパラメータ空間や最適化戦略を試すことで、モデルの性能をさらに向上させることが期待されます。
今のコードをまとめると、以下のようになります。
import optuna
# 目的関数の定義
def objective(trial):
x = trial.suggest_float('x', -10, 10)
return (x - 2) ** 2
# スタディの作成
study = optuna.create_study(direction='minimize')
# 最適化の実行
study.optimize(objective, n_trials=100)
# 結果の確認
print(study.best_value)
print(study.best_params)
# 結果の可視化
optuna.visualization.plot_optimization_history(study)
以下、実行結果です。
9.453176754478803e-05
{'x': 1.9902772551434902}
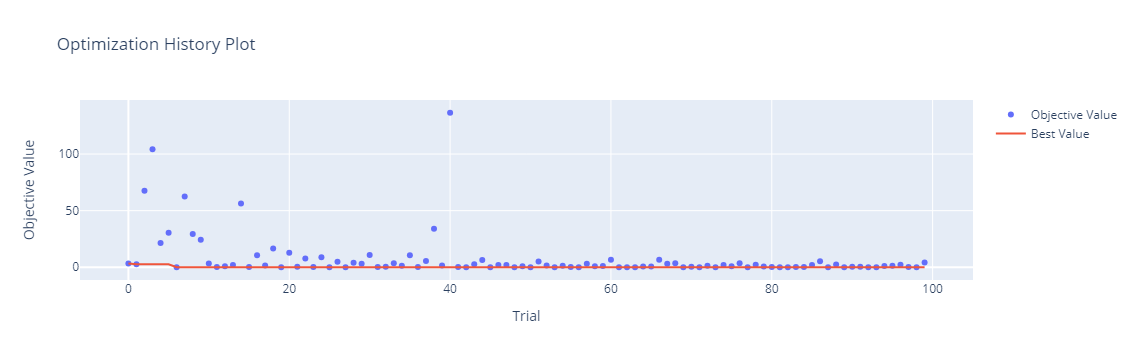
回帰問題例(カリフォルニアの住宅価格データセット)
カリフォルニアの住宅価格を予測するモデルを、scikit-learnのRidge回帰モデルで構築します。
今回チューニングするRidge回帰モデルのハイパーパラメータは、alphaです。
以下、コードです。
import optuna
from sklearn.datasets import fetch_california_housing
from sklearn.linear_model import Ridge
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# データのロードと分割
data = fetch_california_housing()
X_train, X_valid, y_train, y_valid = train_test_split(
data.data,
data.target,
test_size=0.25,
random_state=42
)
# 目的関数の定義
def objective(trial):
# ハイパーパラメータのサジェスト
alpha = trial.suggest_float('alpha', 0.001, 10.0)
model = Ridge(alpha=alpha)
model.fit(X_train, y_train)
y_pred = model.predict(X_valid)
return mean_squared_error(y_valid, y_pred)
# スタディの作成
study = optuna.create_study(direction='minimize')
# 最適化の実行
study.optimize(objective, n_trials=100)
# 結果の確認
print(study.best_value)
print(study.best_params)
# 結果の可視化 (オプション)
optuna.visualization.plot_optimization_history(study)
- 必要なライブラリやモジュールをインポート:
optuna: ハイパーパラメータ最適化のためのライブラリfetch_california_housing: カリフォルニアの住宅価格データセットをロードする関数Ridge: Ridge回帰のモデルtrain_test_split: データセットをトレーニング用と検証用に分割する関数mean_squared_error: 平均二乗誤差を計算する関数
- データセットをロード:
data = fetch_california_housing() - データセットをトレーニング用と検証用に分割:
X_train, X_valid, y_train, y_valid = train_test_split(...) - 目的関数
objectiveを定義:alphaというハイパーパラメータの範囲を指定:trial.suggest_float('alpha', 0.001, 10.0)- Ridge回帰モデルを使用してトレーニングデータで学習
- 検証データを使って予測を行い、平均二乗誤差を計算して返す
- Optunaのスタディを作成:
study = optuna.create_study(direction='minimize')- 目的は誤差を最小化すること
- スタディを使用して最適化を実行:
study.optimize(objective, n_trials=100) - 最適なハイパーパラメータとその時の誤差を表示:
print(study.best_value)とprint(study.best_params) - 最適化の履歴を可視化:
optuna.visualization.plot_optimization_history(study)
以下、実行結果です。
2808.1446682335486
{'alpha': 0.1569332191084981}
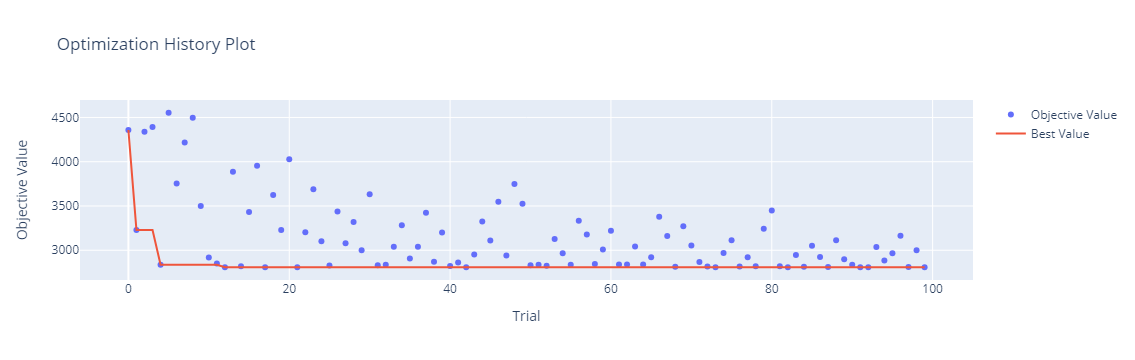
分類問題例(アヤメの種類を分類するデータセット)
アヤメの種類を分類する予測モデルを、scikit-learnのRandomForestClassifierで構築します。
今回チューニングするRandomForestClassifierのハイパーパラメータは、n_estimatorsとmax_depthです。
以下、コードです。
import optuna
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# データのロードと分割
data = load_iris()
X_train, X_valid, y_train, y_valid = train_test_split(
data.data,
data.target,
test_size=0.25,
random_state=42
)
# 目的関数の定義
def objective(trial):
# ハイパーパラメータのサジェスト
n_estimators = trial.suggest_int('n_estimators', 2, 150)
max_depth = trial.suggest_int('max_depth', 1, 32, log=True)
model = RandomForestClassifier(n_estimators=n_estimators, max_depth=max_depth)
model.fit(X_train, y_train)
y_pred = model.predict(X_valid)
return 1.0 - accuracy_score(y_valid, y_pred)
# スタディの作成
study = optuna.create_study(direction='minimize')
# 最適化の実行
study.optimize(objective, n_trials=100)
# 結果の確認
print(study.best_value)
print(study.best_params)
# 結果の可視化 (オプション)
optuna.visualization.plot_optimization_history(study)
- 必要なライブラリやモジュールをインポート:
optuna: ハイパーパラメータ最適化のためのライブラリ。load_iris: アヤメのデータセットをロードする関数。RandomForestClassifier: ランダムフォレストの分類モデル。train_test_split: データセットをトレーニング用と検証用に分割する関数。accuracy_score: 分類の正解率を計算する関数。
- データセットのロードと分割:
data = load_iris(): アヤメのデータセットをロード。- データセットをトレーニング用と検証用に分割。
- 目的関数
objectiveを定義:- ハイパーパラメータ
n_estimatorsとmax_depthの範囲を指定。 - ランダムフォレスト分類器を使用してトレーニングデータで学習。
- 検証データを使って予測を行い、正解率の逆数(1.0 – 正解率)を返す。
- ハイパーパラメータ
- Optunaのスタディを作成:
study = optuna.create_study(direction='minimize')- 目的は誤差を最小化すること
- スタディを使用して最適化を実行:
study.optimize(objective, n_trials=100) - 最適なハイパーパラメータとその時の誤差を表示:
print(study.best_value)とprint(study.best_params) - 最適化の履歴を可視化:
optuna.visualization.plot_optimization_history(study)
以下、実行結果です。
0.0
{'n_estimators': 41, 'max_depth': 8}
まとめ
Optunaは、ハイパーパラメータの最適化を効率的かつ簡単に行うための強力なツールです。今回は、Optunaの主要な機能やAPIの基本的な使い方を探索しました。
次回では、Optunaのアルゴリズムの核心、すなわちベイズ最適化に焦点を当てて深く探ることとなります。ハイパーパラメータの最適化を更に効果的に行うための理論的背景を理解し、Optunaの真髄に迫りましょう。
Optunaで学ぶベイズハイパーパラメータチューニング超入門 – 第3回: ベイズ最適化とは? Optunaのアルゴリズムの背後にあるもの –