

最近色々な自動機械学習 AutoML(Automated Machine Learning)が登場しています。TPOT、MLBox、Auto-Sklearnなどの様々なAutoML(自動機械学習)Pythonライブラリーがあり、分類や回帰の機械学習モデルを自動化することができます。
NLP問題を自動化するPyhtonライブラリーは、AutoViMLです。
時系列データに対するAutoML(自動機械学習)もあります。Pythonの時系列AutoML(自動機械学習)ライブラリーであるAutoTSです。
前回は、「AutoTSのインストール方法や簡単な使い方」を紹介しました。
今回は、「AutoTSを使った時系列予測モデルの自動構築方法」について説明します。超簡単です。
利用するデータセット
時系列解析系のサンプルデータとしよく活用されている、以下のデータセット2つを使います。
- Australian wine sales(オーストラリアのワイン販売量) ※月単位の時系列データ
- Airline Passengers(飛行機乗客数) ※月単位の時系列データ
以下の記事で利用しているデータセットです。
Python ThymeBoost でさくっと勾配ブーステッド時系列モデル(A Gradient Boosted Time-Series Model)を作ろう!
上記の記事では、Python の ThymeBoost というパッケージを使って勾配ブーステッド時系列モデル(A Gradient Boosted Time-Series Model)や、伝統的な時系列解析モデルである ARIMAモデル などで予測モデルを構築し精度比較しています。
具体的には、以下の4つです。
- ARIMAモデル
- Prophetモデル
- ThymeBoostモデル
- ThymeBoost(ARIMA)モデル
これらの時系列予測モデルと比較して見たいと思います。
ちなみに、上記4つの時系列予測モデルも、一種のAutoML(自動機械学習)です。ほぼ自動で構築しているからです。例えば、ARIMAモデルもAutoARIMAというARIMAモデルを自動構築するアルゴリズムで構築しています。
AutoTSは何が違うのかと言うと、大きな違いは多変量時系列データに対応していることと、一様ARIMAやProphetを含んでいるところです。AutoTSが必ずよい結果をもたらすわけではなく、AutoTSの中に実装されているAutoML(自動機械学習)の探索アルゴリズムによっては、精度は悪化することがあります。
予測精度評価で利用する指標
学習データで予測モデルを構築し、テストデータで精度検証していきます。
予測精度評価で利用する指標は、平均絶対誤差(MAE、Mean Absolute Error)と平均絶対パーセント誤差(MAPE、Mean absolute percentage error)です。
以下の記号を使い精度指標の説明をします。
- y_i^{actual} ・・・i番目の実測値
- y_i^{pred} ・・・i番目の予測値
- \overline{y^{actual}} ・・・実測値の平均
- n ・・・実測値・予測値の数
■ 二乗平均平方根誤差(RMSE、Root Mean Squared Error)
\sqrt{\frac{1}{n}\sum_{i=1}^n(y_i^{actual}-{y_i^{pred}})^2}■ 平均絶対誤差(MAE、Mean Absolute Error)
\frac{1}{n}\sum_{i=1}^n|y_i^{actual}-{y_i^{pred}}|■ 平均絶対パーセント誤差(MAPE、Mean absolute percentage error)
\frac{1}{n}\sum_{i=1}^n|\frac{y_i^{actual}-{y_i^{pred}}}{y_i^{actual}}|
必要なライブラリーの読み込み
先ずは、必要なライブラリー一式を読み込みます。
以下、コードです。
# ライブラリーの読み込み
import numpy as np
import pandas as pd
from autots import AutoTS
from autots.tools.shaping import simple_train_test_split
from sklearn.metrics import mean_absolute_error
from statistics import mean
from matplotlib import pyplot as plt
# グラフのスタイルとサイズ
plt.style.use('ggplot')
plt.rcParams['figure.figsize'] = [12, 9]
Australian wine sales(オーストラリアのワイン販売量)
Australian wine sales|データセットの読み込み
Australian wine sales(オーストラリアのワイン販売量)は、1980年1月から1994年8月までのオーストラリアのワインメーカーによるワイン販売を記録した月単位のデータです。
先ず、データセットを読み込みます。
以下、コードです。
# データの読み込み url = 'https://www.salesanalytics.co.jp/l6p7' df = pd.read_csv(url) df.columns = ["Month","Sales"] df #読み込んだデータセットの確認
以下、実行結果です。

Australian wine sales|学習データとテストデータに分割
予測モデルを構築する学習データと、構築した予測モデルを検証するためのテストデータに分割します。
時系列データですので、ある時期を境に2つのデータに分割します。
今回は、新しい12ヶ月(1年間)のデータをテストデータとし、その前のデータを学習データとします。
では、データを分割します。以下、コードです。
# データセットの分割(学習データとテストデータ) train_df, test_df = simple_train_test_split(df,forecast_length=12)
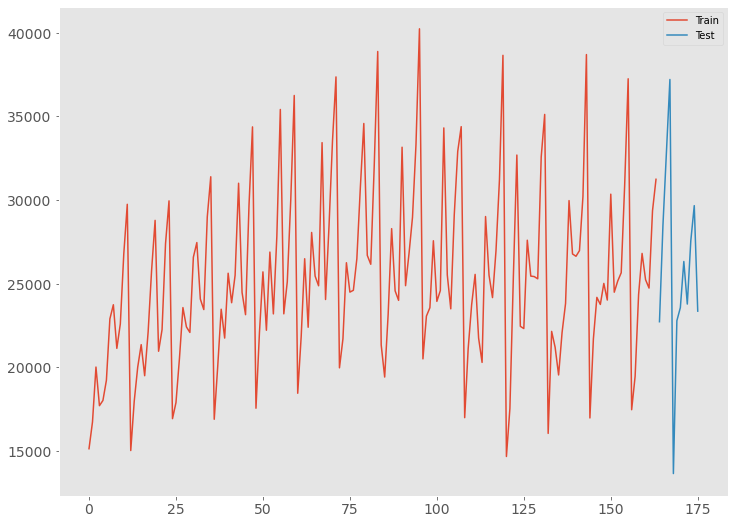
読み込んだデータセットをグラフで確認してみます。
以下、コードです。
# データをグラフで確認 train_df.Sales.plot(fontsize=14, label='Train') test_df.Sales.plot(fontsize=14, label='Test') plt.legend() plt.grid() plt.show()
以下、実行結果です。
Australian wine sales|予測モデルの自動構築
学習データ(train_df)を使い、予測モデルを自動構築します。
以下、コードです。
# AutoML設定
model = AutoTS(
forecast_length=12,
frequency='infer',
model_list='fast_parallel',
ensemble='all',
max_generations=9,
num_validations=10,
n_jobs='auto'
)
# 学習
model = model.fit(
train_df,
date_col='Month',
value_col='Sales'
)
AutoML(自動機械学習)の最良モデルを表示します。
以下、コードです。
# 最適モデルの表示 model
以下、実行結果です。

構築したモデルを使い予測をします。
以下、コードです。
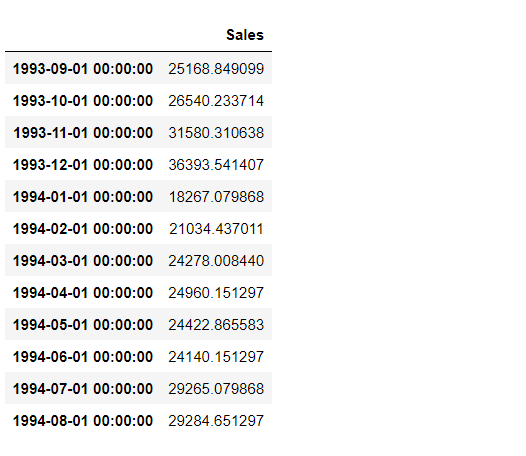
# 予測 prediction = model.predict() prediction.forecast #予測結果の確認
以下、実行結果です。
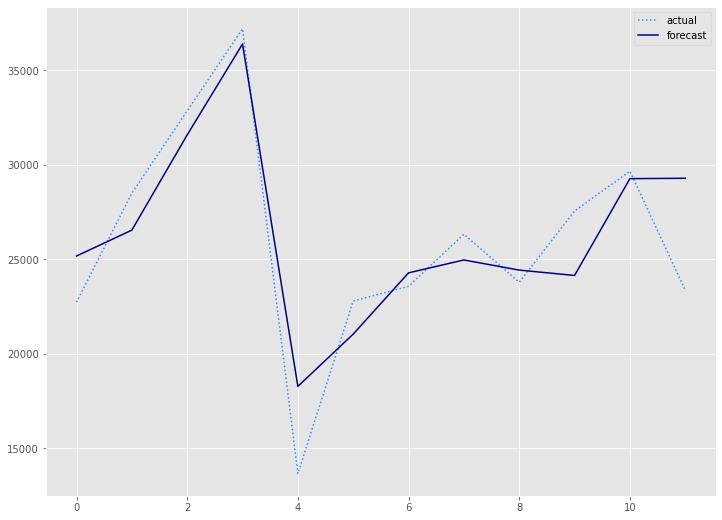
構築したモデルをテストデータ(test_df)を使い精度評価します。
以下、コードです。
# 予測値と実測値
preds = prediction.forecast.Sales.to_numpy() #予測値
test = test_df.Sales.to_numpy() #実測値
# 予測精度
rmse = mean((test - preds)**2)**.5
mae = mean_absolute_error(test, preds)
mape = mean(abs(test - preds)/test)*100
print('RMSE:')
print(rmse)
print('MAE:')
print(mae)
print('MAPE(%):')
print(mape)
# 予測値グラフ
x_axis = range(len(test))
plt.plot(x_axis,test,label="actual",color='#1e90ff', linestyle='dotted')
plt.plot(x_axis,preds, label='forecast',color='#000080')
plt.legend()
plt.show()
以下、実行結果です。

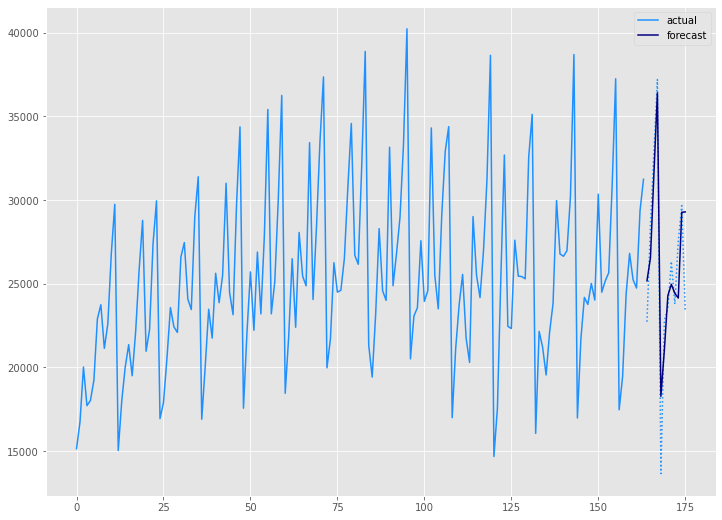
学習データ(train)の期間も含めグラフ化してみます。
以下、コードです。
# グラフ(学習データとテストデータ、予測結果) x_axis = np.arange(len(df)) plt.plot(x_axis[:len(train_df)],train_df.Sales,color='#1e90ff',label="actual") plt.plot(x_axis[len(train_df):],test,color='#1e90ff', linestyle='dotted') plt.plot(x_axis[len(train_df):],preds, label='forecast',color='#000080') plt.legend() plt.show()
以下、実行結果です。
Australian wine sales|予測精度比較
「Python ThymeBoost でさくっと勾配ブーステッド時系列モデル(A Gradient Boosted Time-Series Model)を作ろう!」で、作った以下の4つの予測モデルと比較します。
- ARIMAモデル
- Prophetモデル
- ThymeBoostモデル
- ThymeBoost(ARIMA)モデル
以下、今回のAutoTSを含めた5つのモデルの予測精度です。
| RMSE | MAE | MAPE(%) | |
| AutoTS | 2,679 | 2,108 | 9.60% |
| ARIMA | 4,139 | 3,177 | 15.19% |
| Prophet | 2,734 | 2,429 | 10.49% |
| ThymeBoost | 5,896 | 4,590 | 21.11% |
| ThymeBoost(ARIMA) | 2,631 | 2,133 | 9.49% |
Airline Passengers(飛行機乗客数)
Airline Passengers|データセットの読み込み
Airline Passengers(飛行機乗客数)は、1949年から1960年までの国際航空旅客の月単位のデータです。
先ず、データセットを読み込みます。
以下、コードです。
# データの読み込み url = 'https://raw.githubusercontent.com/tblume1992/ThymeBoost/main/ThymeBoost/Datasets/AirPassengers.csv' df = pd.read_csv(url) df.columns = ["Month","Passengers"] df #読み込んだデータセットの確認
以下、実行結果です。
Airline Passengers|学習データとテストデータに分割
予測モデルを構築する学習データと、構築した予測モデルを検証するためのテストデータに分割します。
時系列データですので、ある時期を境に2つのデータに分割します。
今回は、新しい12ヶ月(1年間)のデータをテストデータとし、その前のデータを学習データとします。
では、データを分割します。以下、コードです。
# データセットの分割(学習データとテストデータ) train_df, test_df = simple_train_test_split(df,forecast_length=12)
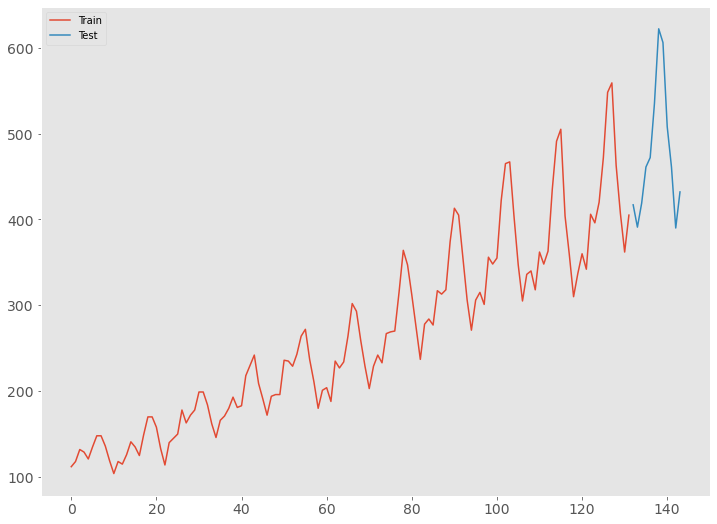
読み込んだデータセットをグラフで確認してみます。
以下、コードです。
# データをグラフで確認 train_df.Passengers.plot(fontsize=14, label='Train') test_df.Passengers.plot(fontsize=14, label='Test') plt.legend() plt.grid() plt.show()
以下、実行結果です。
Airline Passengers|予測モデルの自動構築
学習データ(train_df)を使い、予測モデルを自動構築します。
以下、コードです。
# AutoML設定
model = AutoTS(
forecast_length=12,
frequency='infer',
model_list='fast_parallel',
ensemble='all',
max_generations=9,
num_validations=10,
n_jobs='auto'
)
# 学習
model = model.fit(
train_df,
date_col='Month',
value_col='Passengers'
)
AutoML(自動機械学習)の最良モデルを表示します。
以下、コードです。
# 最適モデルの表示 model
以下、実行結果です。

構築したモデルを使い予測をします。
以下、コードです。
# 予測 prediction = model.predict() prediction.forecast #予測結果の確認
以下、実行結果です。
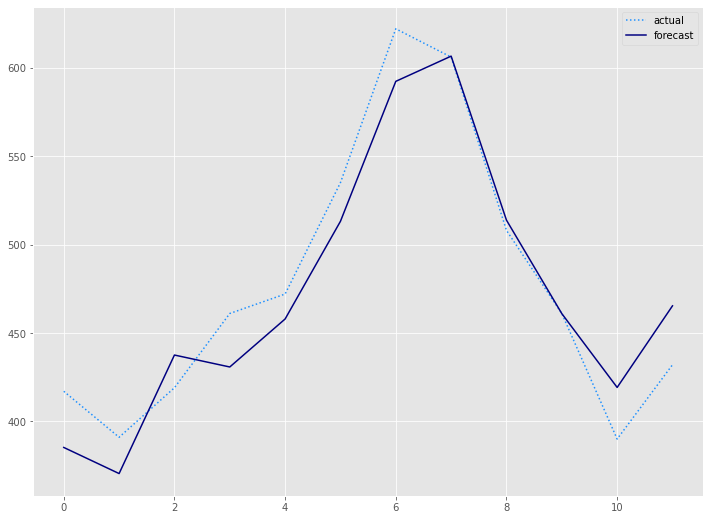
構築したモデルをテストデータ(test_df)を使い精度評価します。
以下、コードです。
# 予測値と実測値
preds = prediction.forecast.Passengers.to_numpy() #予測値
test = test_df.Passengers.to_numpy() #実測値
# 予測精度
rmse = mean((test - preds)**2)**.5
mae = mean_absolute_error(test, preds)
mape = mean(abs(test - preds)/test)*100
print('RMSE:')
print(rmse)
print('MAE:')
print(mae)
print('MAPE(%):')
print(mape)
# 予測値グラフ
x_axis = range(len(test))
plt.plot(x_axis,test,label="actual",color='#1e90ff', linestyle='dotted')
plt.plot(x_axis,preds, label='forecast',color='#000080')
plt.legend()
plt.show()
以下、実行結果です。

学習データ(train)の期間も含めグラフ化してみます。
以下、コードです。
# グラフ(学習データとテストデータ、予測結果) x_axis = np.arange(len(df)) plt.plot(x_axis[:len(train_df)],train_df.Passengers,color='#1e90ff',label="actual") plt.plot(x_axis[len(train_df):],test,color='#1e90ff', linestyle='dotted') plt.plot(x_axis[len(train_df):],preds, label='forecast',color='#000080') plt.legend() plt.show()
以下、実行結果です。
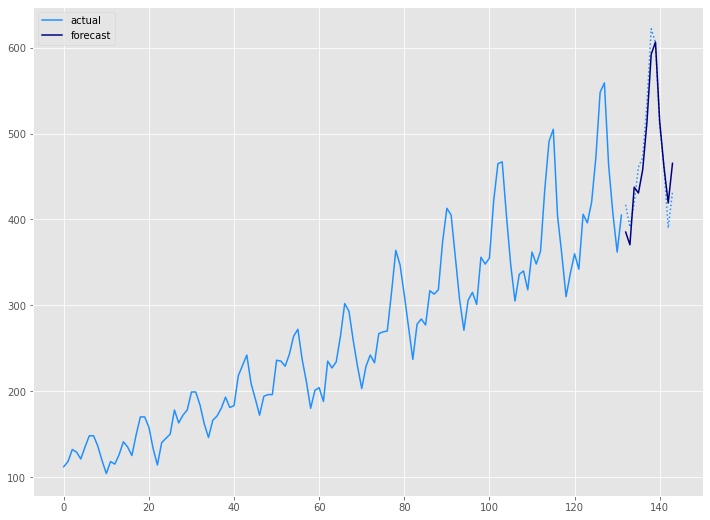
Airline Passengers|予測精度比較
「Python ThymeBoost でさくっと勾配ブーステッド時系列モデル(A Gradient Boosted Time-Series Model)を作ろう!」で、作った以下の4つの予測モデルと比較します。
- ARIMAモデル
- Prophetモデル
- ThymeBoostモデル
- ThymeBoost(ARIMA)モデル
以下、今回のAutoTSを含めた5つのモデルの予測精度です。
| RMSE | MAE | MAPE(%) | |
| AutoTS | 22 | 19 | 4.34% |
| ARIMA | 19 | 15 | 3.09% |
| Prophet | 24 | 22 | 4.59% |
| ThymeBoost | 22 | 16 | 3.41% |
| ThymeBoost(ARIMA) | 31 | 21 | 4.08% |
まとめ
今回は、「AutoTSを使った予測モデルの自動構築方法」を紹介しました。
非常に時間が掛かります。
次回は、特定の数理モデルのアルゴリズムを指定し自動構築する方法について説明します。