
手元のデータを、直感的にさくっと集計したり、グラフ化したりし、ちらっと確認したいことあると思います。
Pythonで、直感的にさくっと集計したり、グラフ化したりするには、壁あります。コーディングという壁があります。コーディングしながらだと、さくさくとは行かないことでしょう。
Pythonでダッシュボードを素早く作成し、他の人と共有したいと思ったっことあると思います。
Jupyter Lab 上で、atotiというパッケージを利用することで可能になります。
今回は、「PythonでBIプラットフォームを構築するパッケージatoti」の簡単な使い方を説明します。
atotiのインストール
コマンドプロンプト上で、インストールしJupyter Labを立ち上げます。
以下、pipでインストールするときのコードです。
pip install atoti[jupyterlab]
上手くインストールできたなら、Jupyter Labを立ち上げます。
以下、コードです。
jupyter lab
以下、実行結果です。
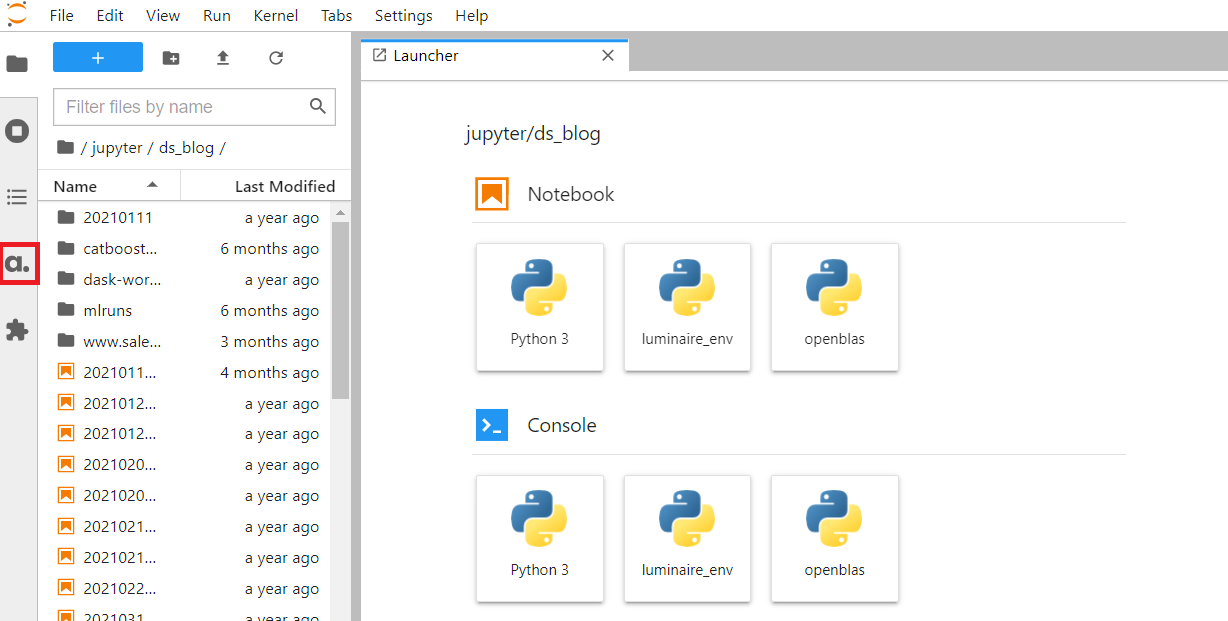
左にatotiのアイコンが表示されていれば成功です。ちなみに、atotiのアイコンとは、以下のようなアイコンです。

サンプルデータ
今回利用するサンプルデータは、Kaggleで公開されているビデオゲームの売上データです。ファイル名は、vgsales.csvです。
以下のURLからもダウンロードできます。
vgsales.csv
https://www.salesanalytics.co.jp/al1j
以下、データ項目(変数)です。
- Rank – 全体の売上高ランキング
- Name – ゲームの名前
- Platform – ゲームが発売されたプラットフォーム(例:PC、PS4、など)
- Year – 発売された年
- Genre – ゲームのジャンル
- Publisher – ゲームのパブリッシャー
- NA_Sales – 北米での売上高 (単位: 百万円)
- EU_Sales – 欧州での売上高(単位:百万ドル)
- JP_Sales – 日本での売上(単位:百万ドル)
- Other_Sales – その他の地域での売上高(単位:百万ドル)
データセットを格納するCubeを作成してみよう!
Cubeとは、集計したりフィルタリングしたりしEDA(探索的データ分析)を可能にしたり、それらをダッシュボード化を可能にするための、データセットを格納する箱のようなものです。
早速、Cubeを作ってみましょう。
以下、コードです。
import atoti as tt
session = tt.create_session(
config={
"user_content_storage": "./content",
"port": 9000,
}
)
今回は、configを設定しています。設定しなくてもCubeは作れますが、ダッシュボードを保存したり、他の人と共有したりする場合に設定しておく必要があります。
- user_content_storage :ダッシュボードが保存される場所
- port:ダッシュボードアプリのポート番号
CSVファイルからデータを読み込んでDataFrameを作成します。
以下、コードです。フォルダ「C:\dataset」にデータセット「vgsales.csv」を格納していた場合の例です。
df = session.read_csv("C:/dataset/vgsales.csv")
df.head()
以下、実行結果です。
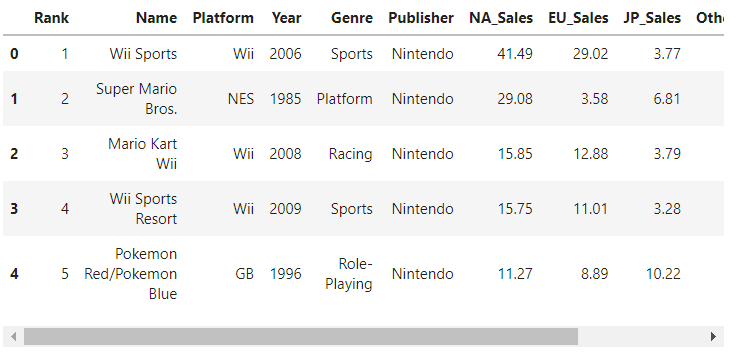
データフレーム化したデータセットから、Cubeを作成します。
以下、コードです。
cube = session.create_cube(df)
Cubeは、ディメンジョン(dimension)とメジャー(measure)の2つのコンポーネントで構成されています。
- ディメンジョン(dimension):データセットのカテゴリカル変数(質的変数)
- メジャー(measure):データセットのニューメリカル変数(量的変数)
どの変数(列)がカテゴリカル変数(質的変数)で、どの変数(列)がニューメリカル変数(量的変数)かは自動で判別されます。
どのように判別されたかを確認するには、以下のコードです。
Cube
以下、実行結果です。
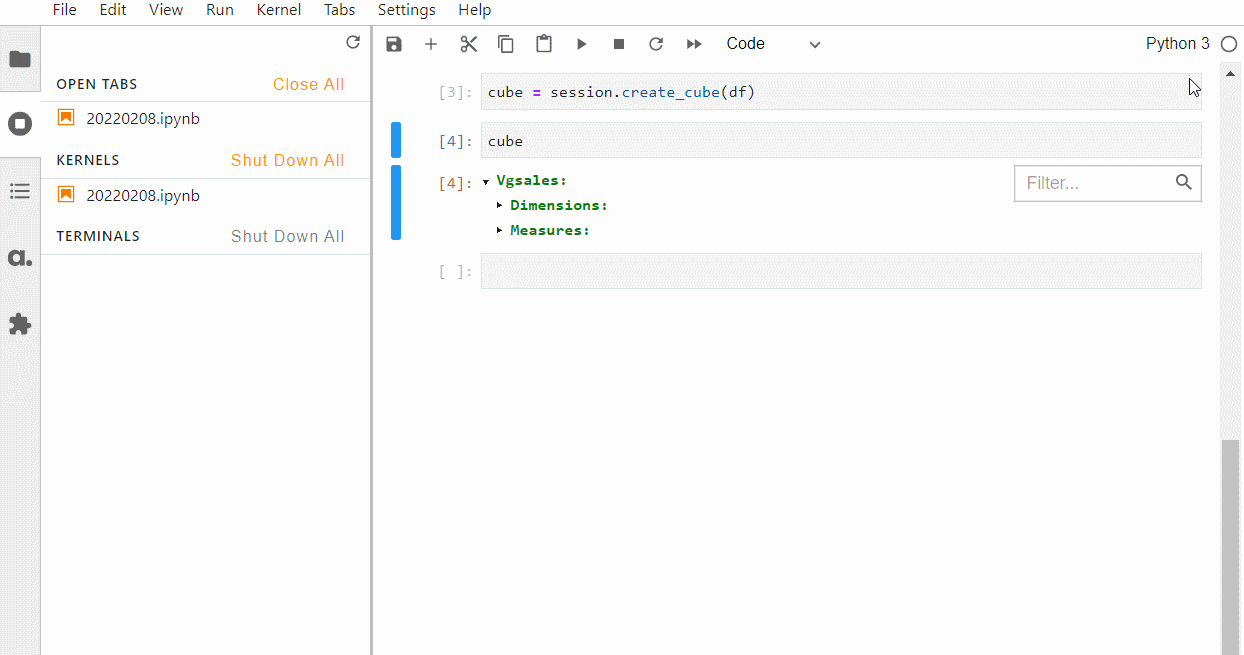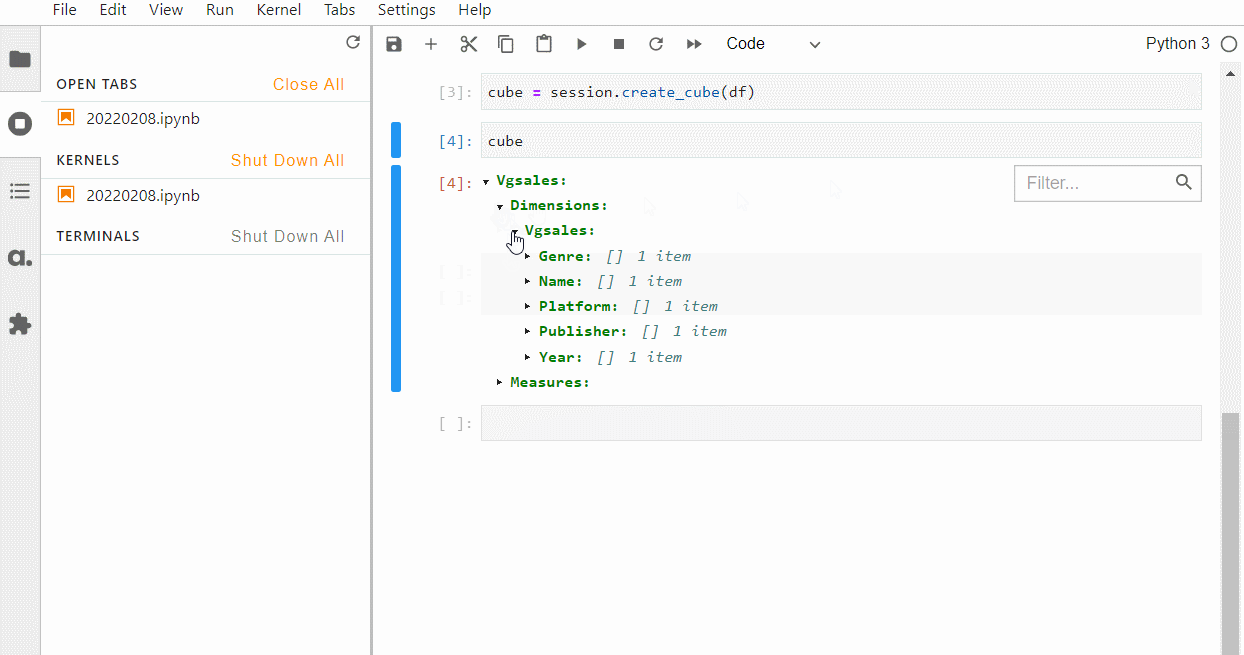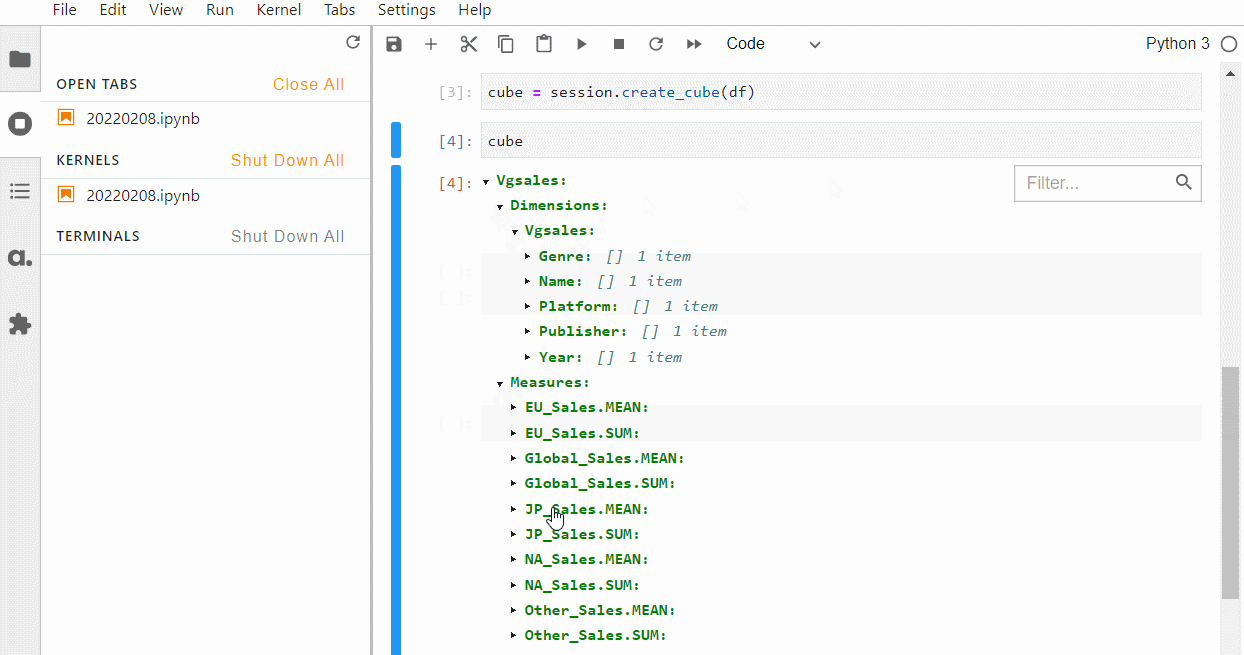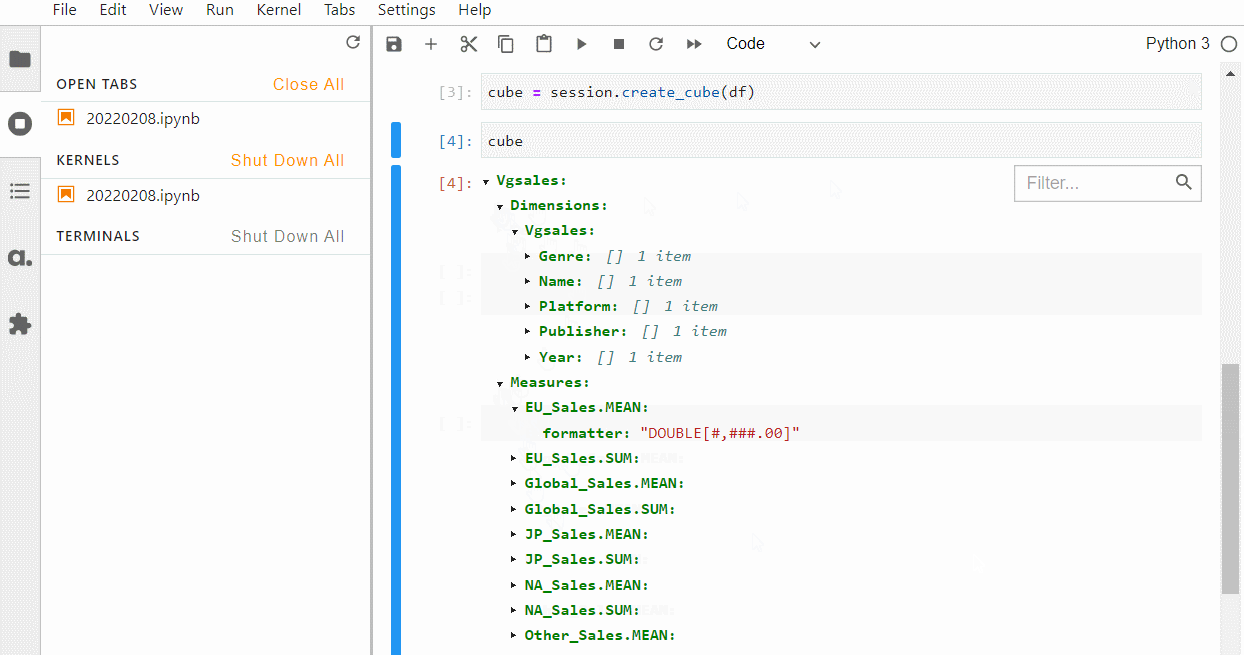
強制的にカテゴリカル変数(質的変数)を指定する場合には、例えばCSVファイルを読み込みデータフレーム化するときにdfhierarchized_columns=[…]を付けて読み込みます。
これで準備が整いました。
ダッシュボードを作ってみよう!!
以下、コードです。
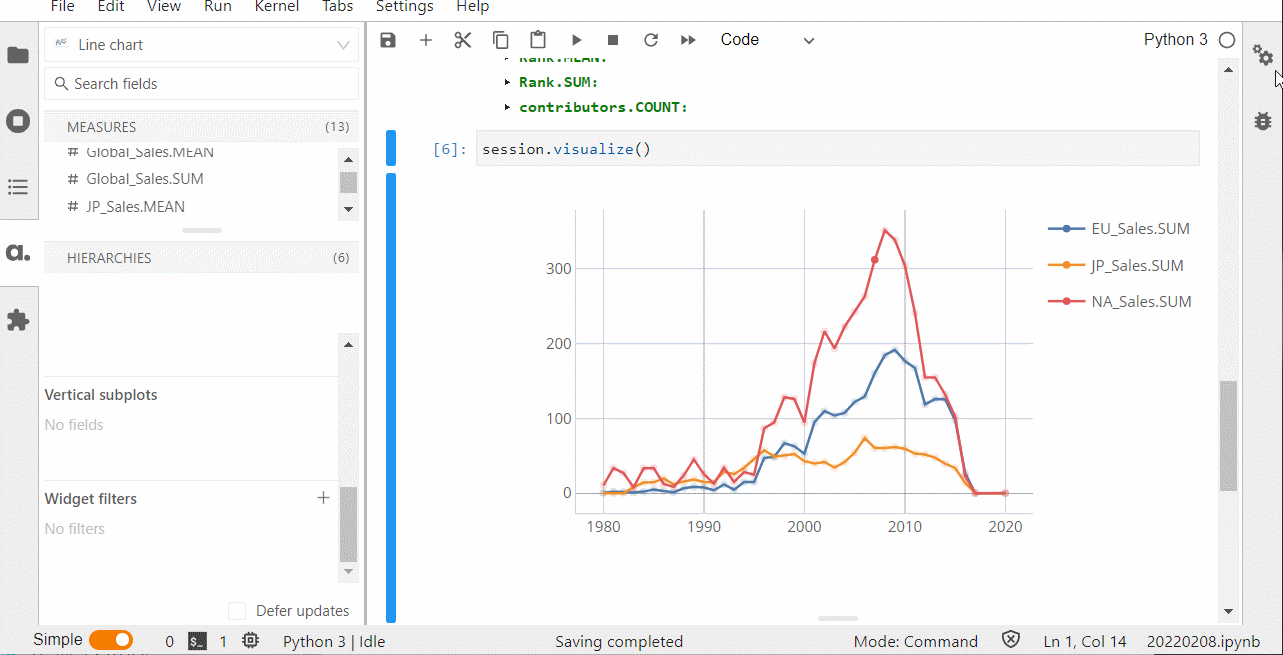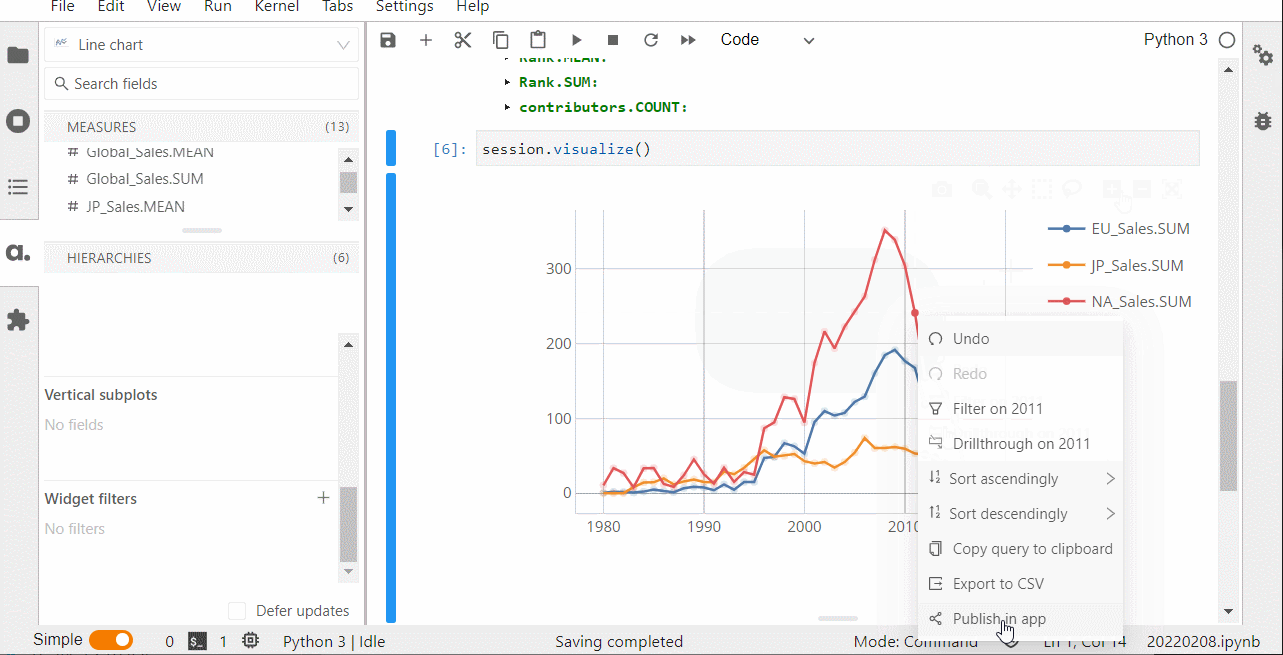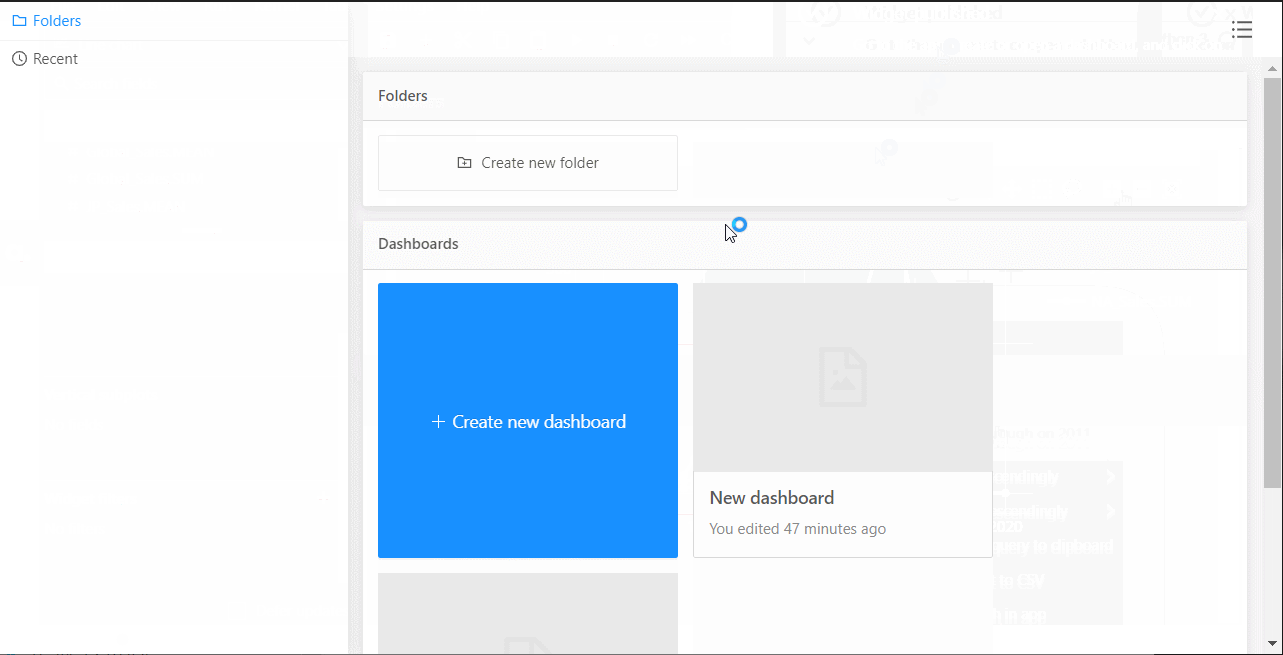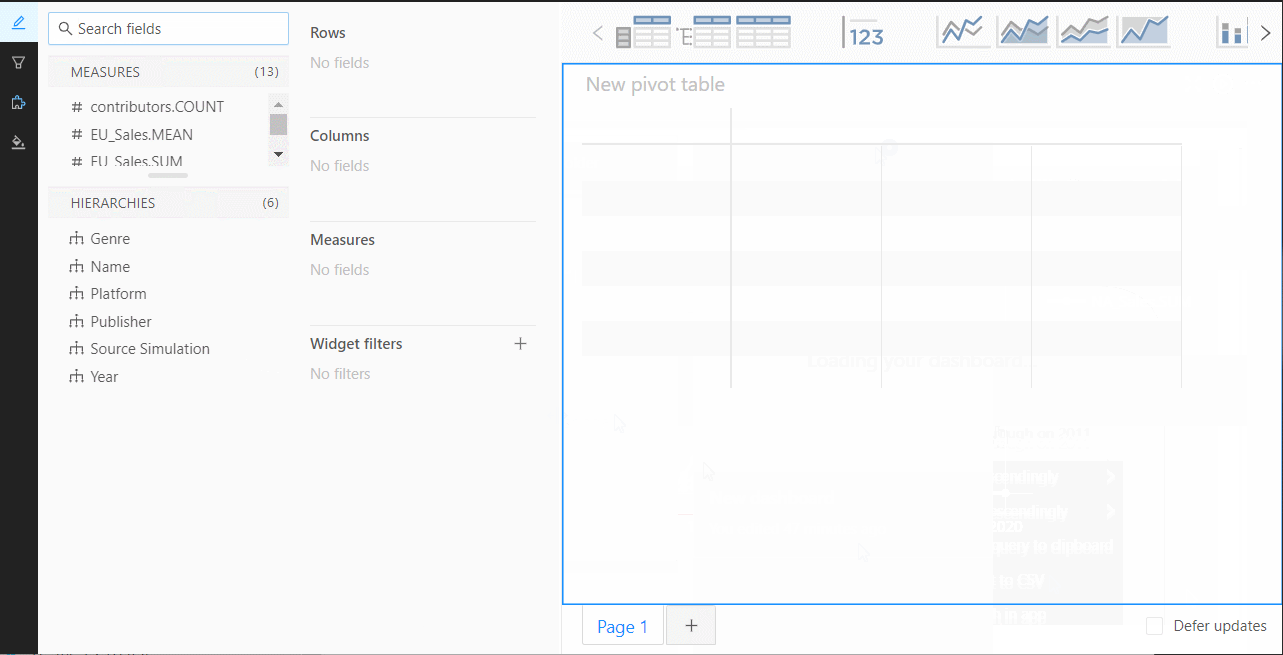
session.visualize()
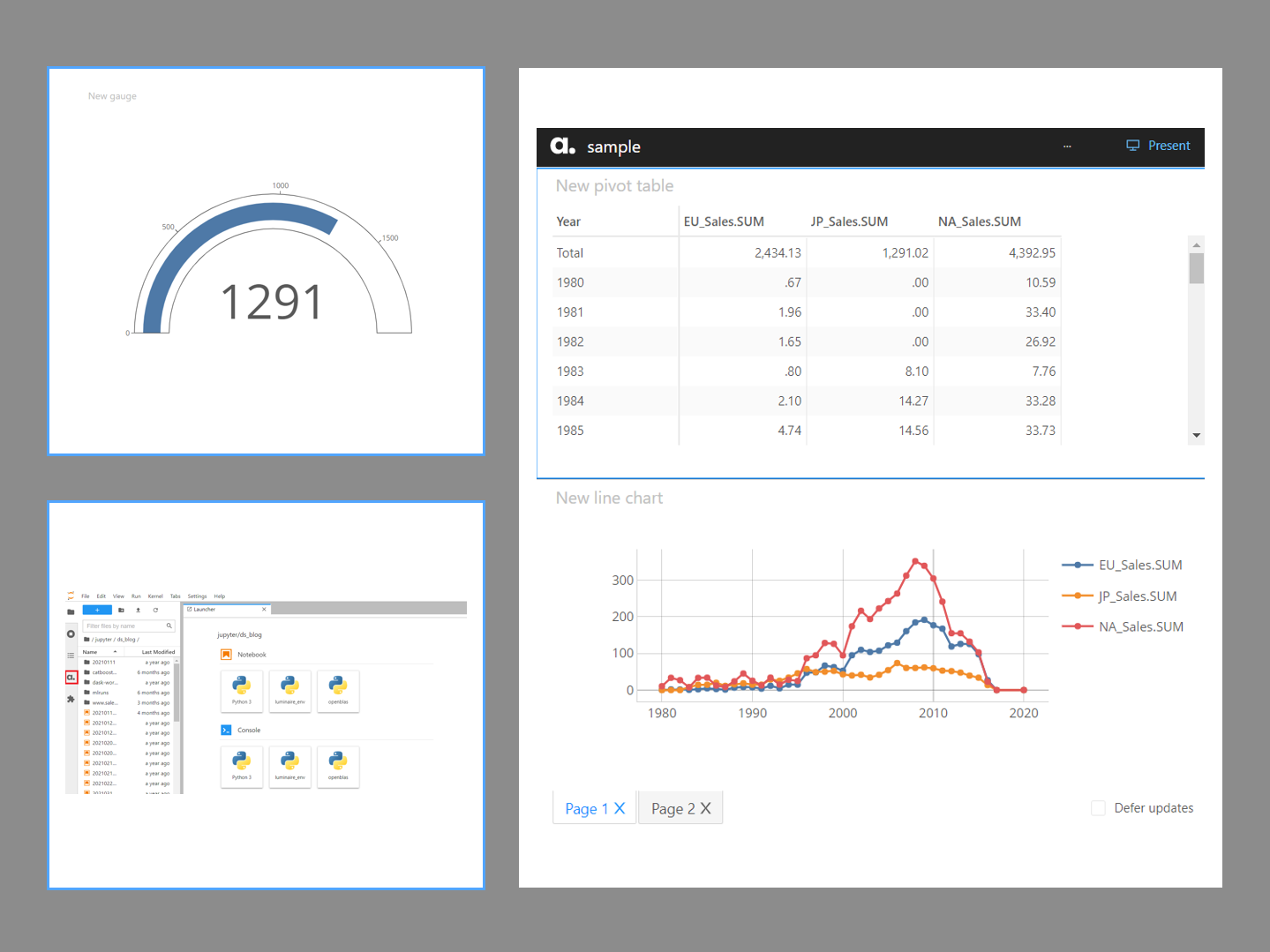
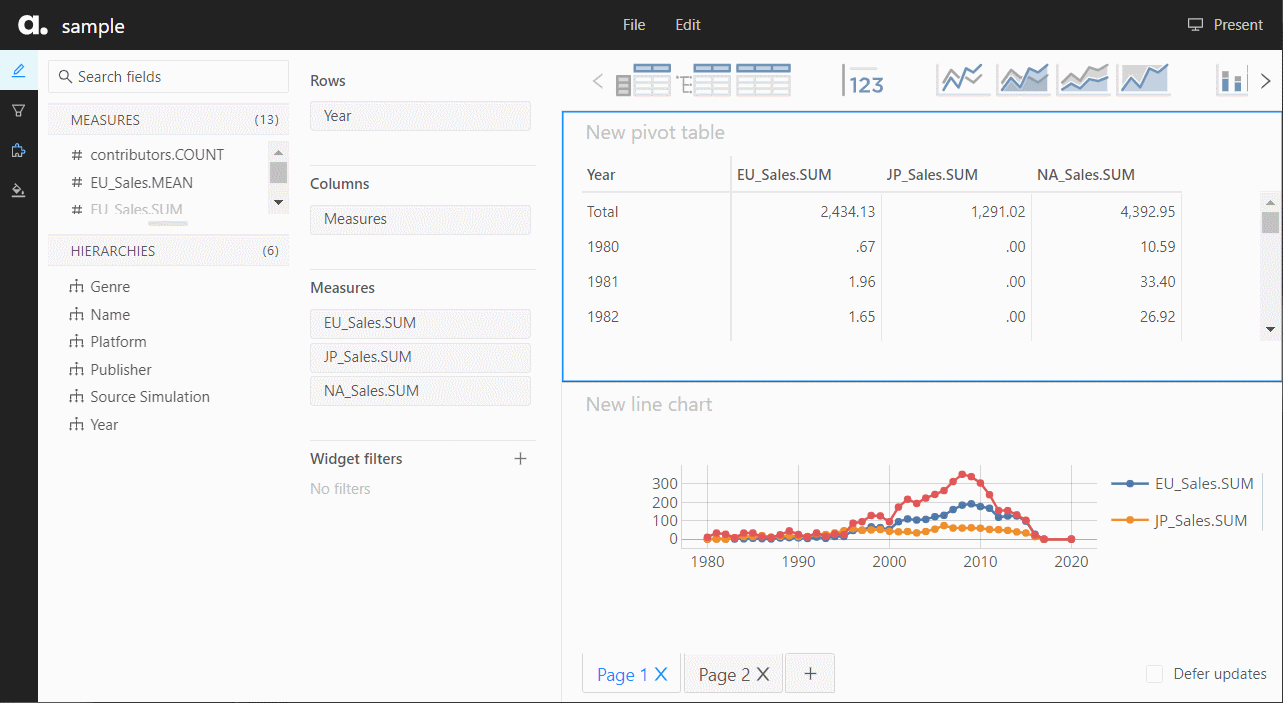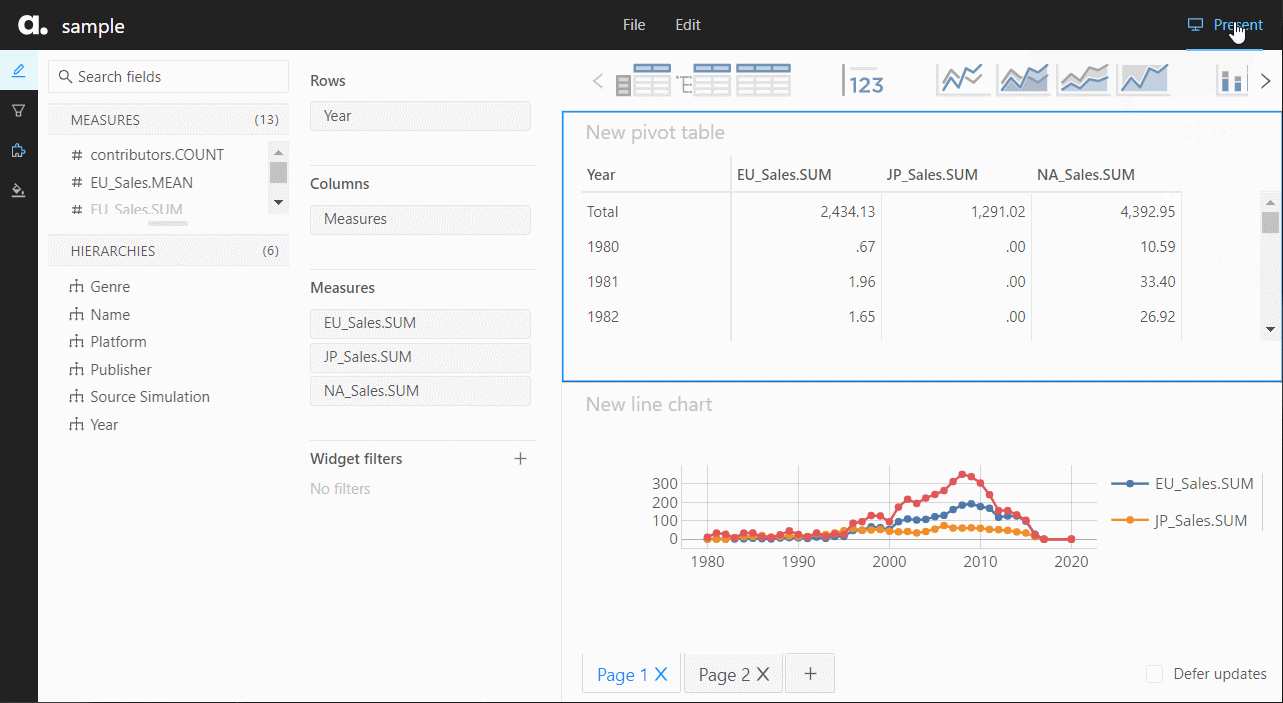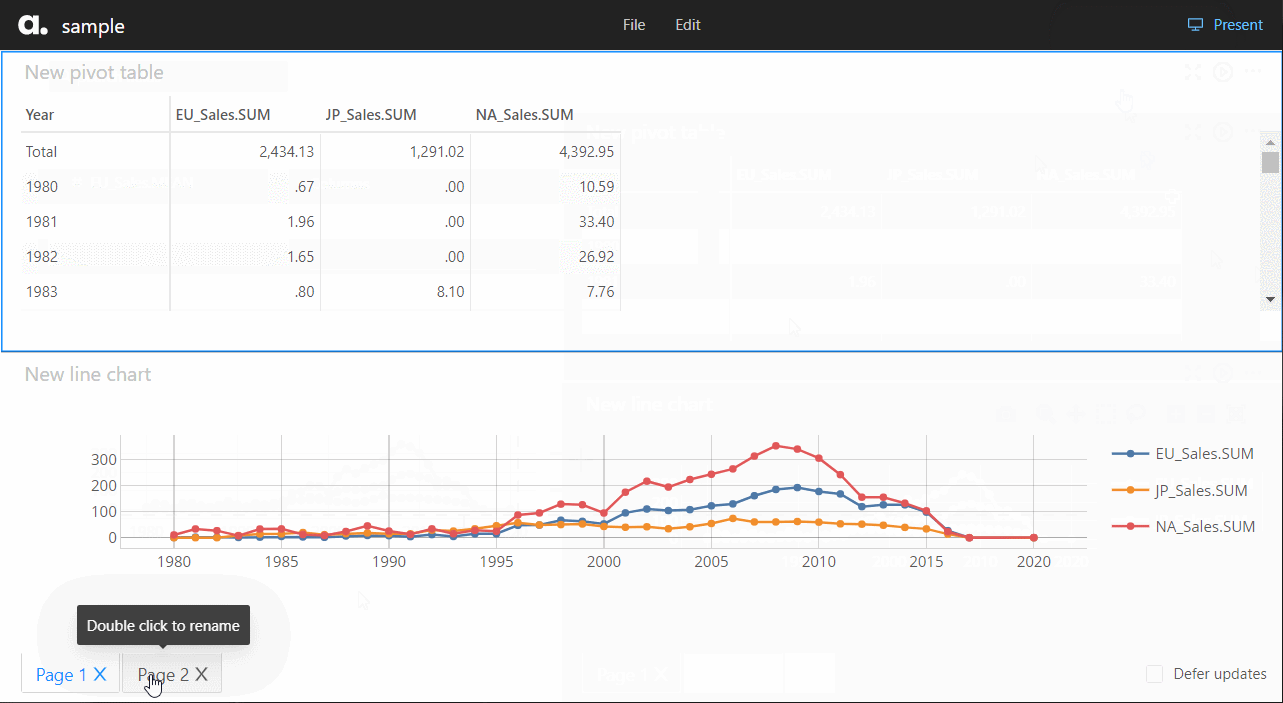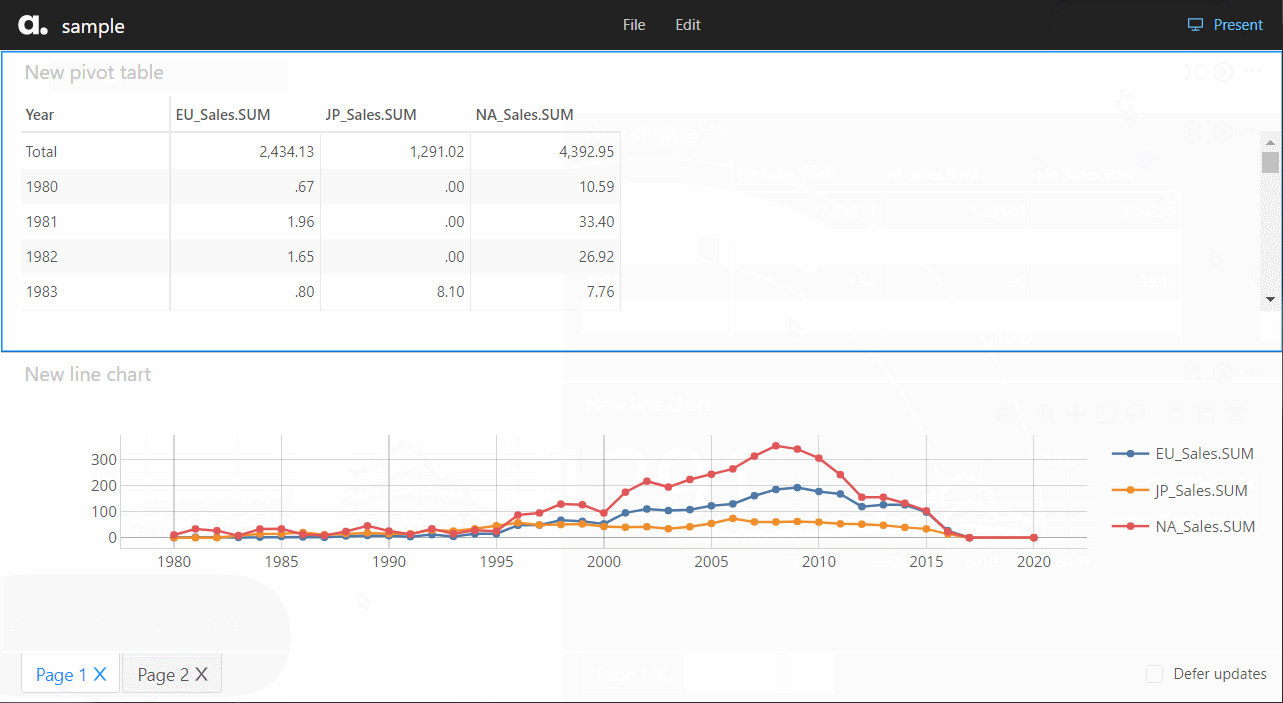
以下、実行結果です。ピボットテーブルです。
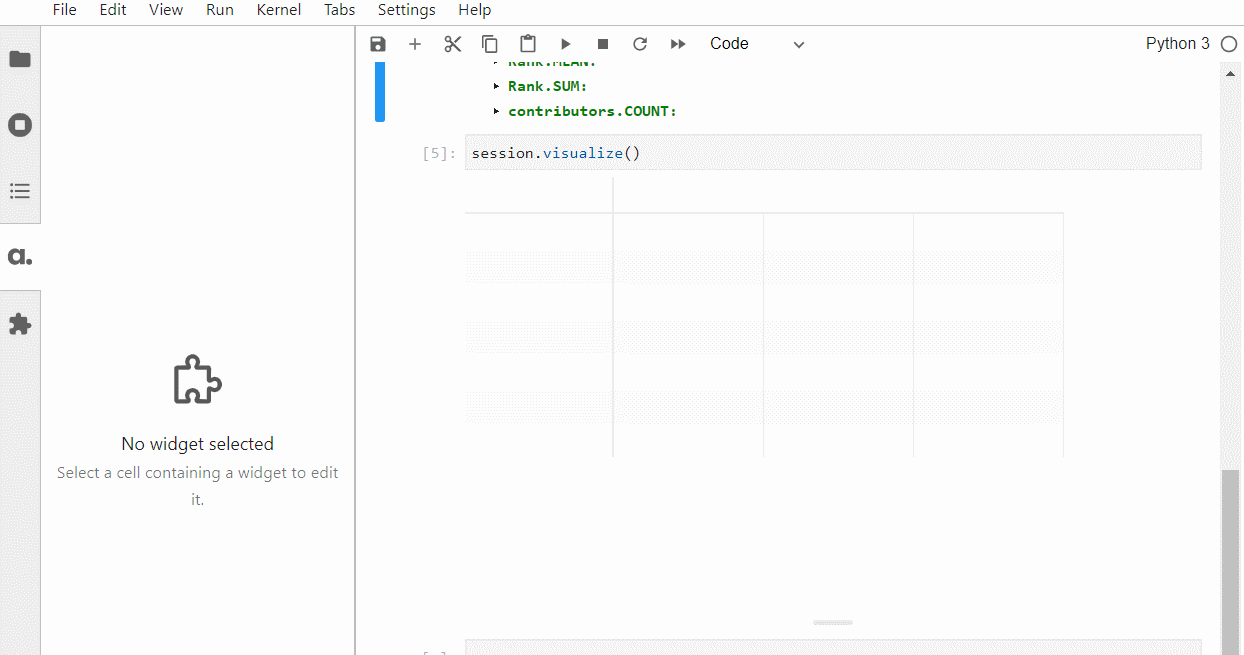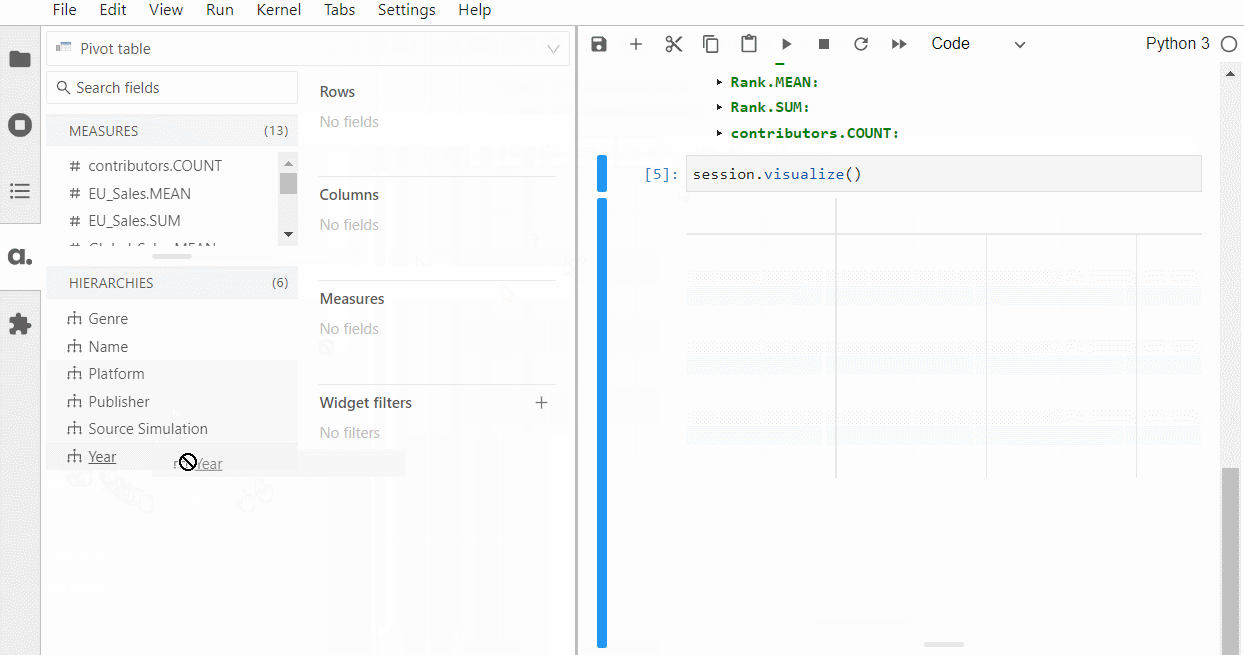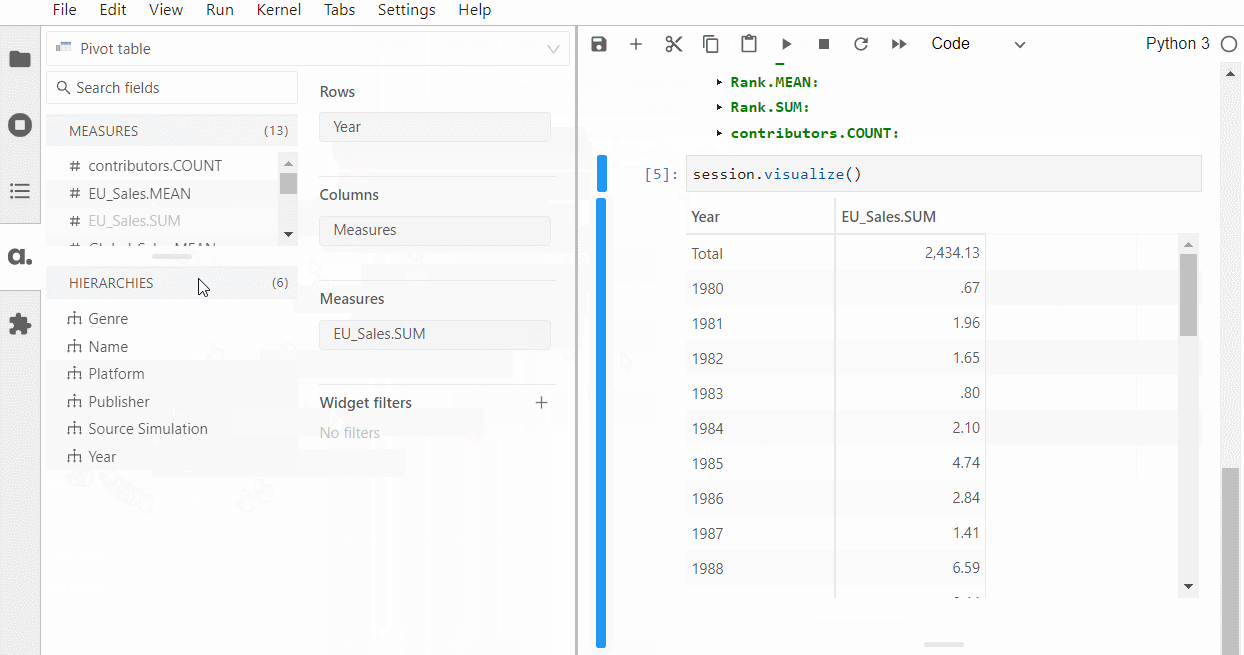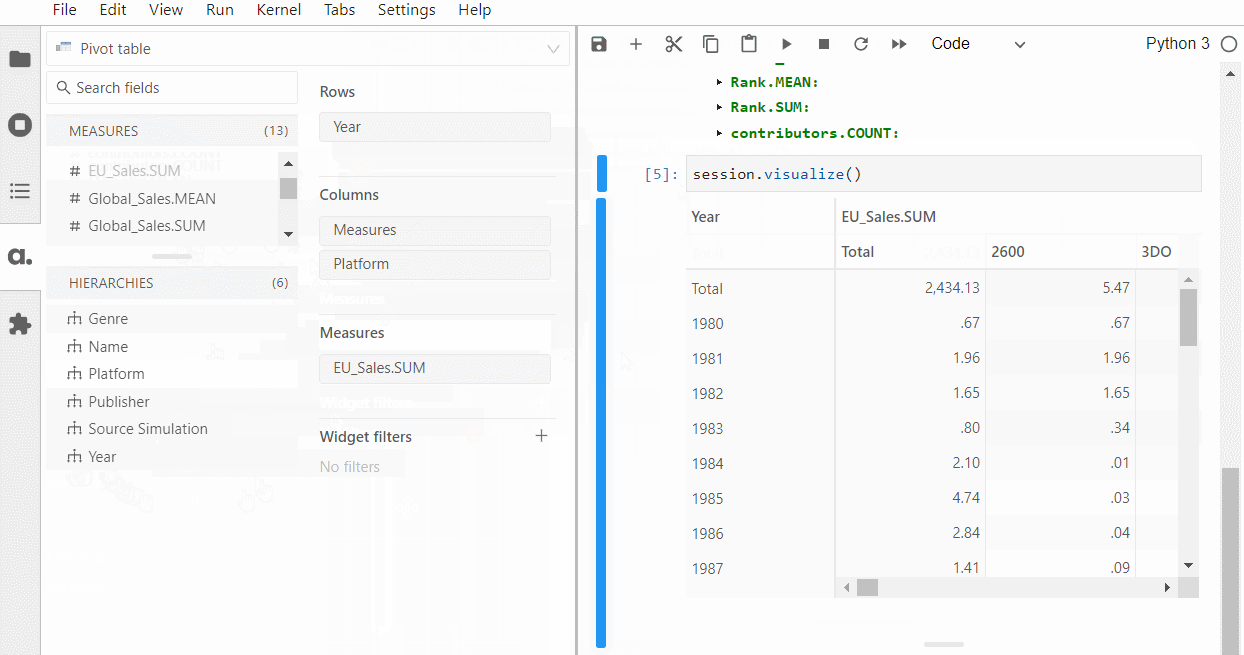
グラフ作成なども手軽にできます。
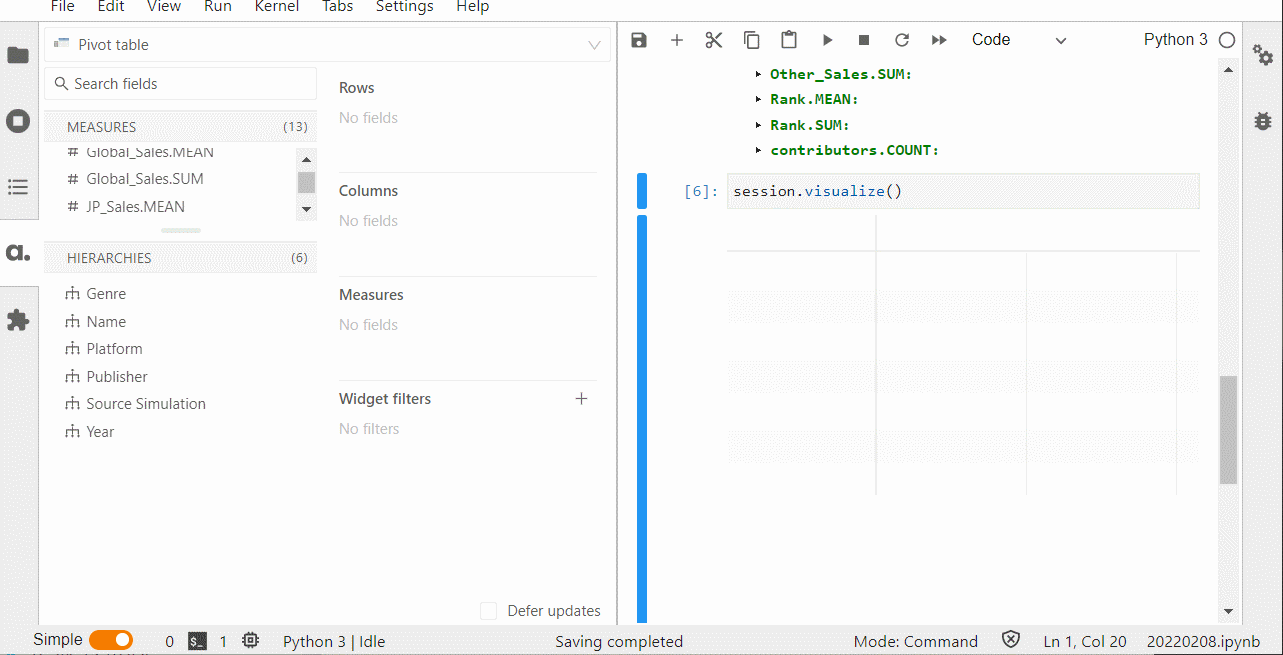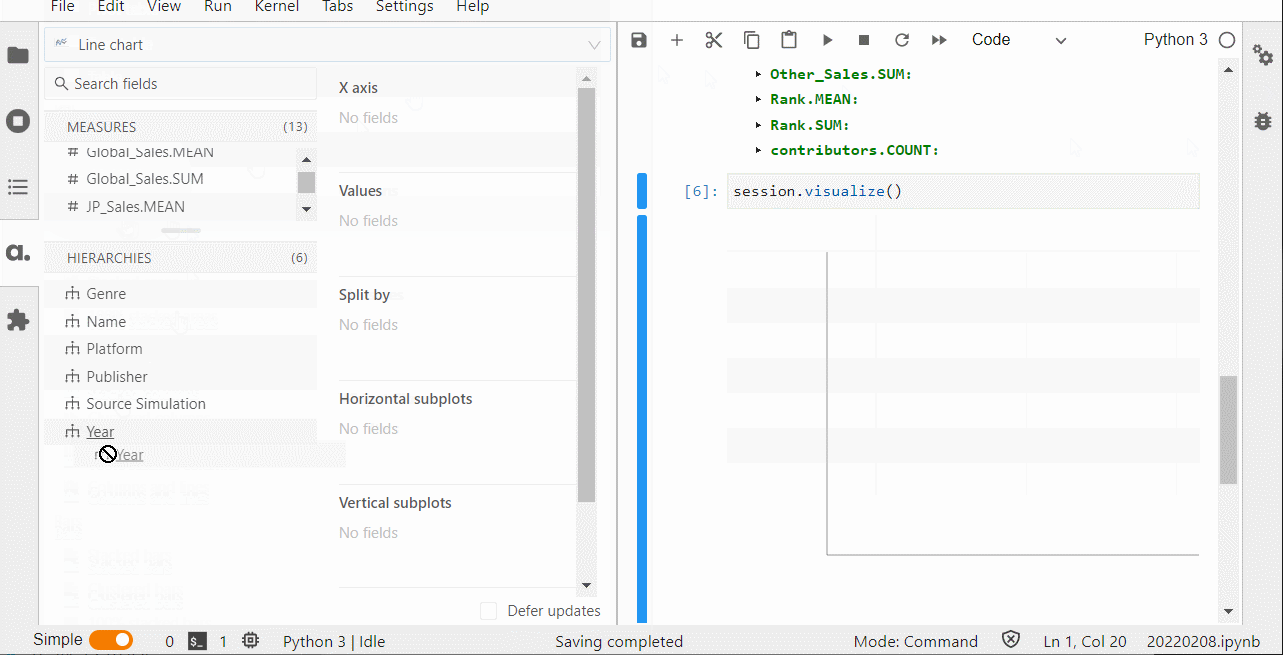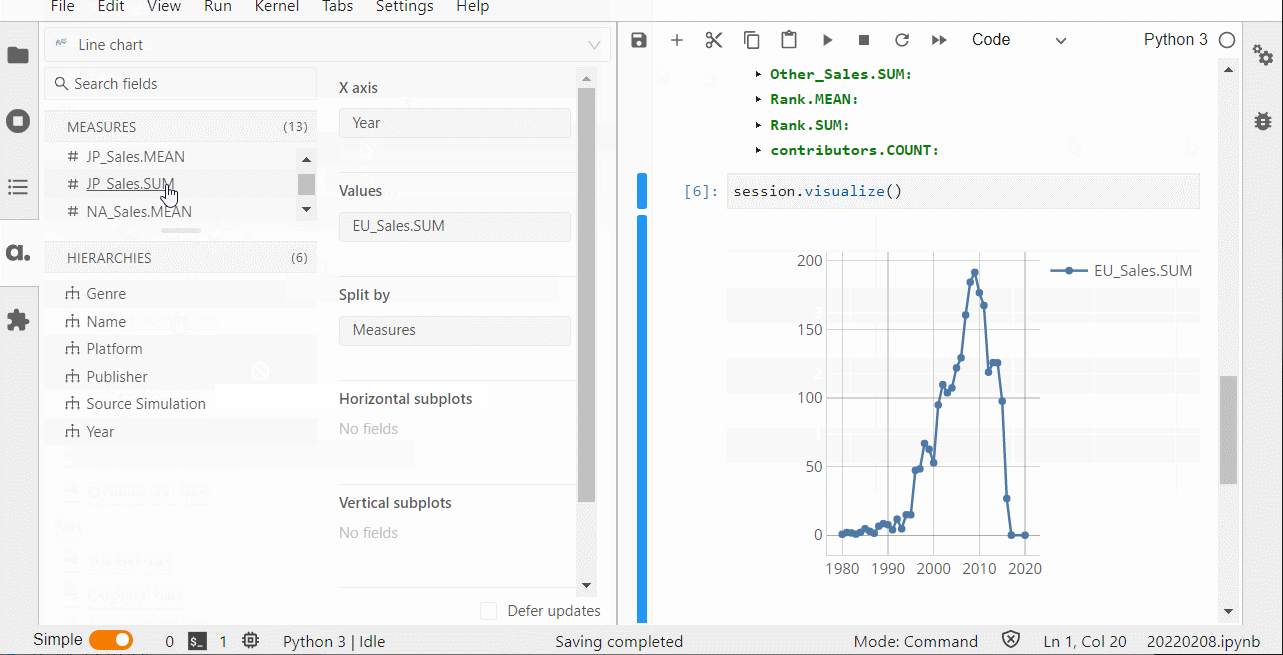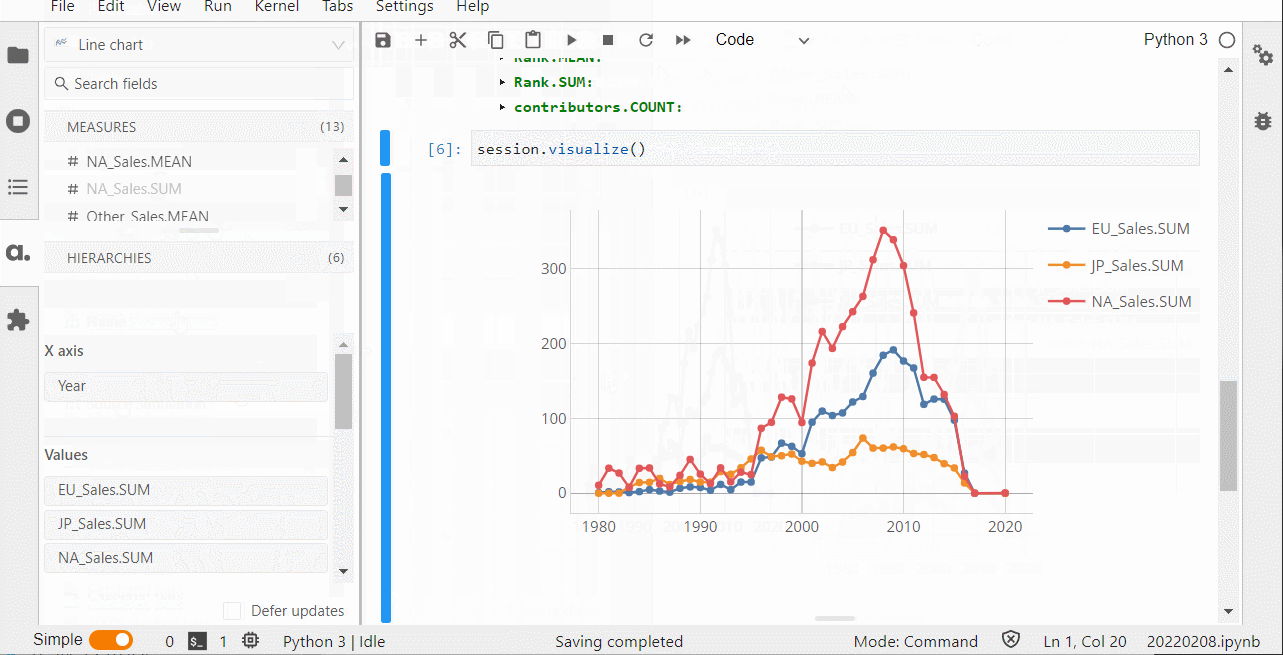
プロット上で右クリックし、「Publish in-app」を選択することで、ダッシュボードをさくさく作ることができます。
もしくは、以下のコードを入力しURLを出力します。
session.link()
このURLをクリックすることで、同じ画面に遷移します。
ダッシュボード作成で使える、データテーブルやグラフなどの部品が上の方にあるので、それを使ってダッシュボードを作っていきます。
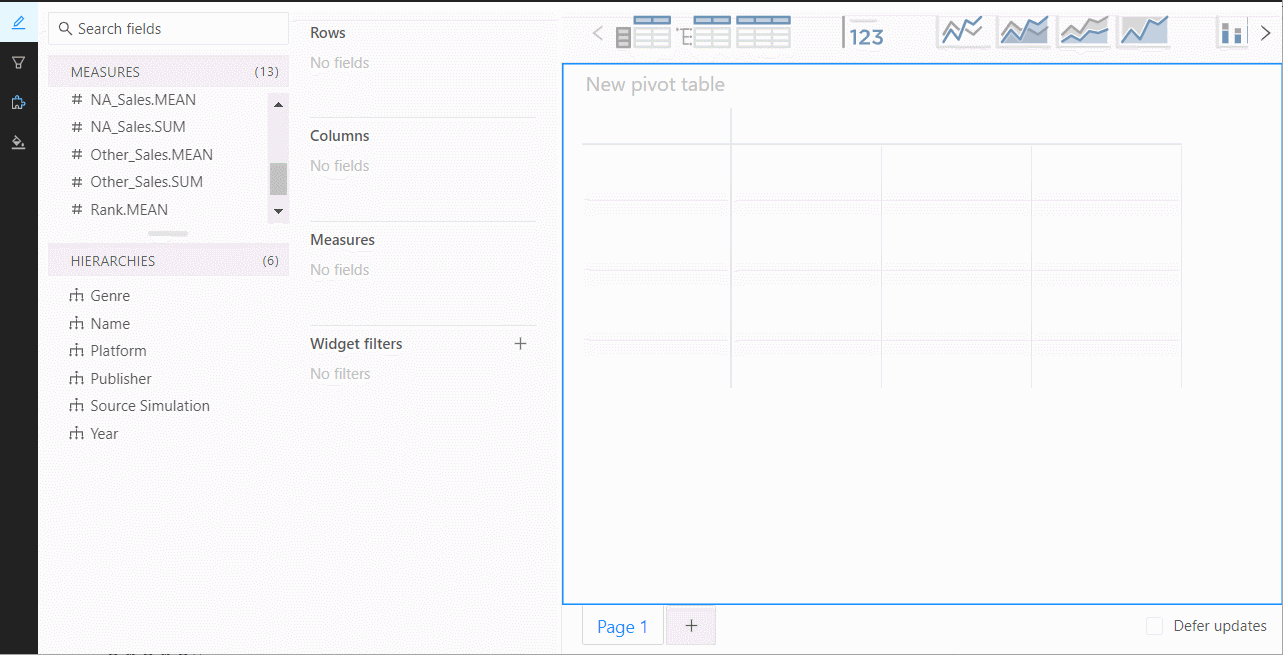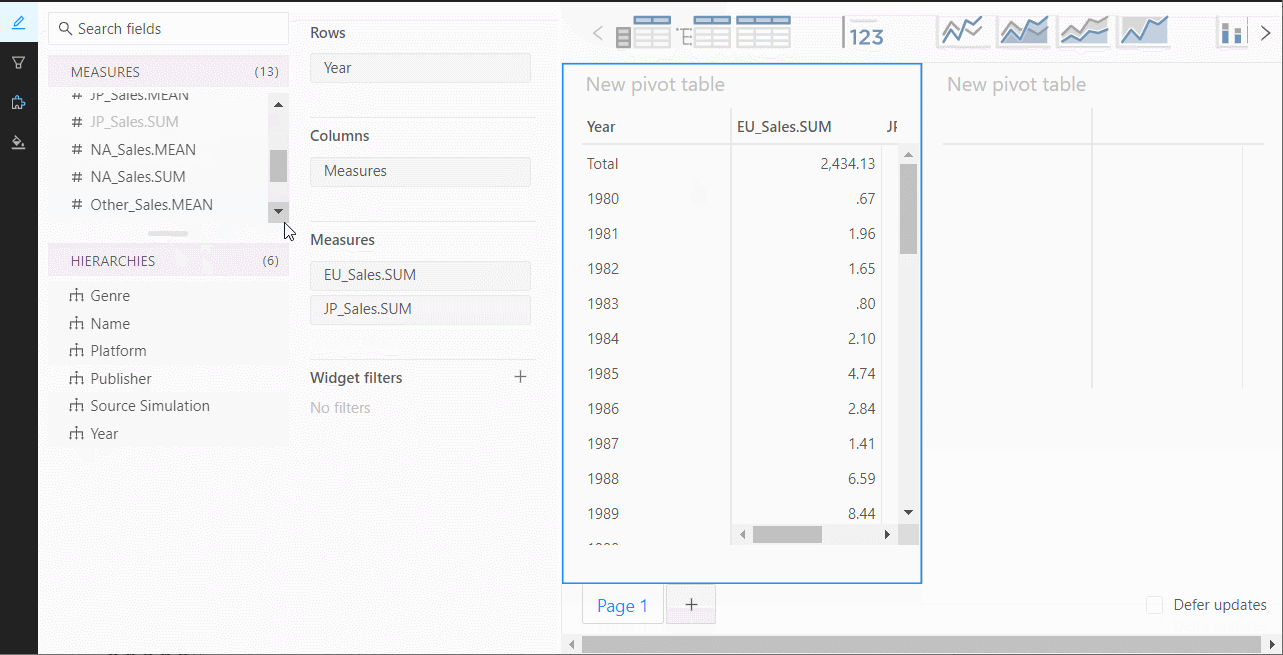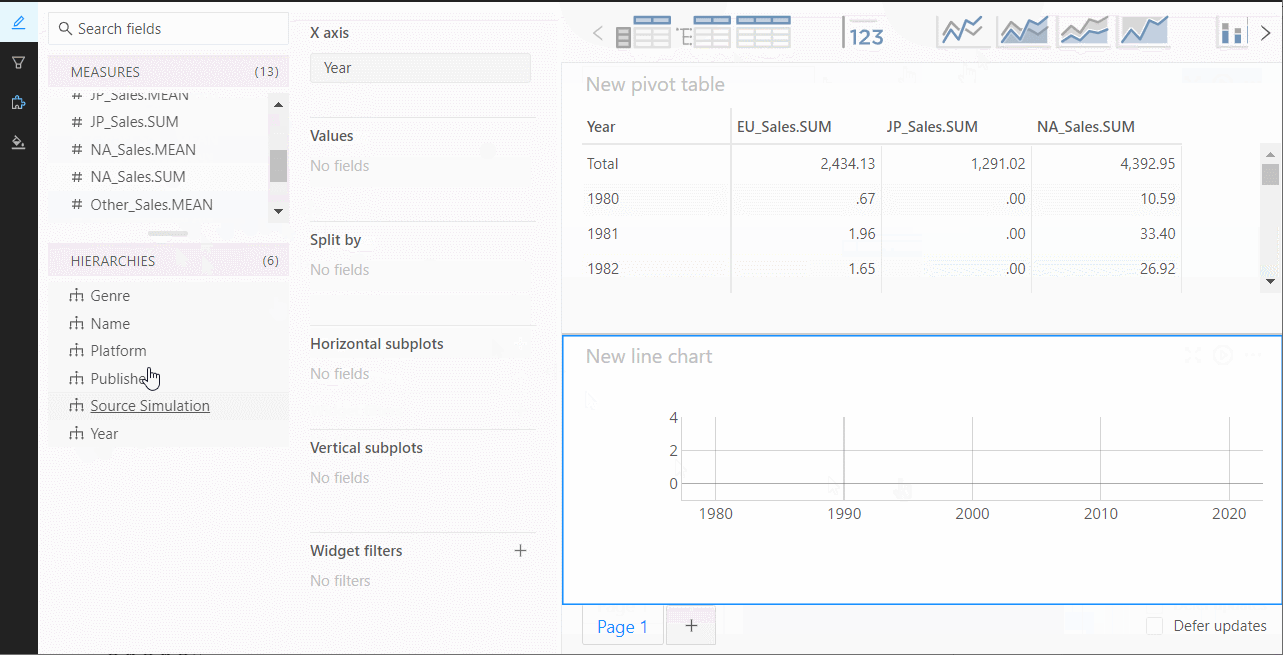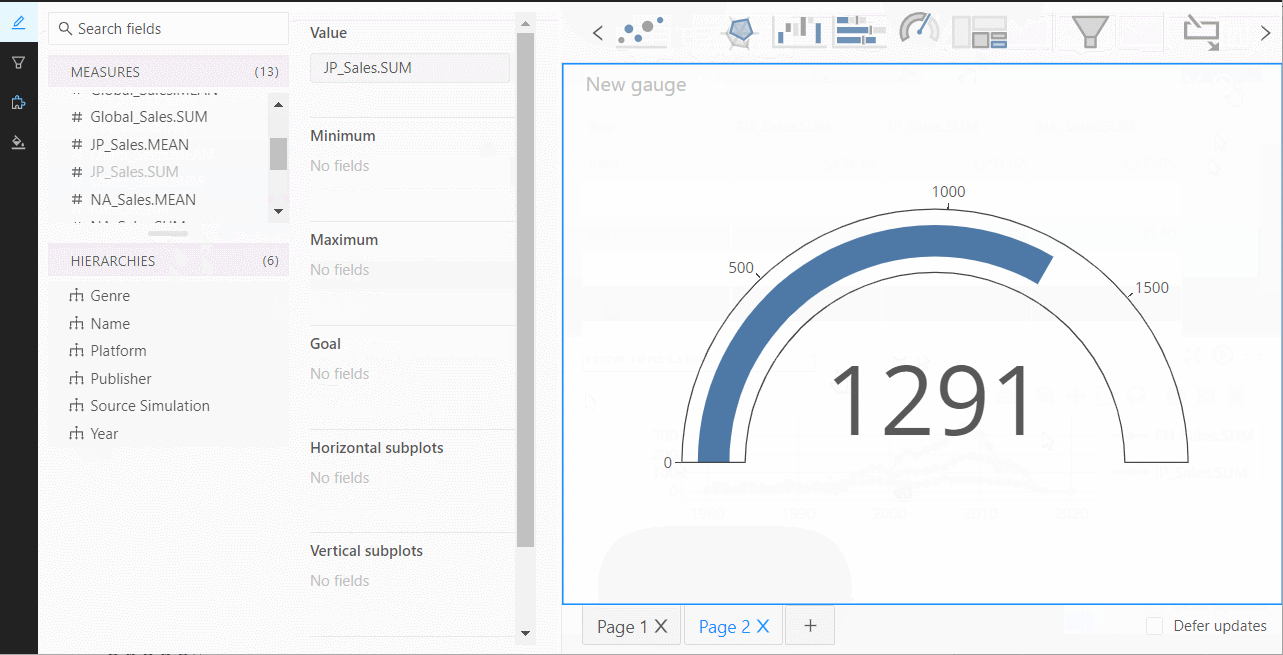
ページを増やすときは、下のページ追加ボタンをクリックし追加していきます。
ダッシュボードの保存
作ったダッシュボードの保存です。
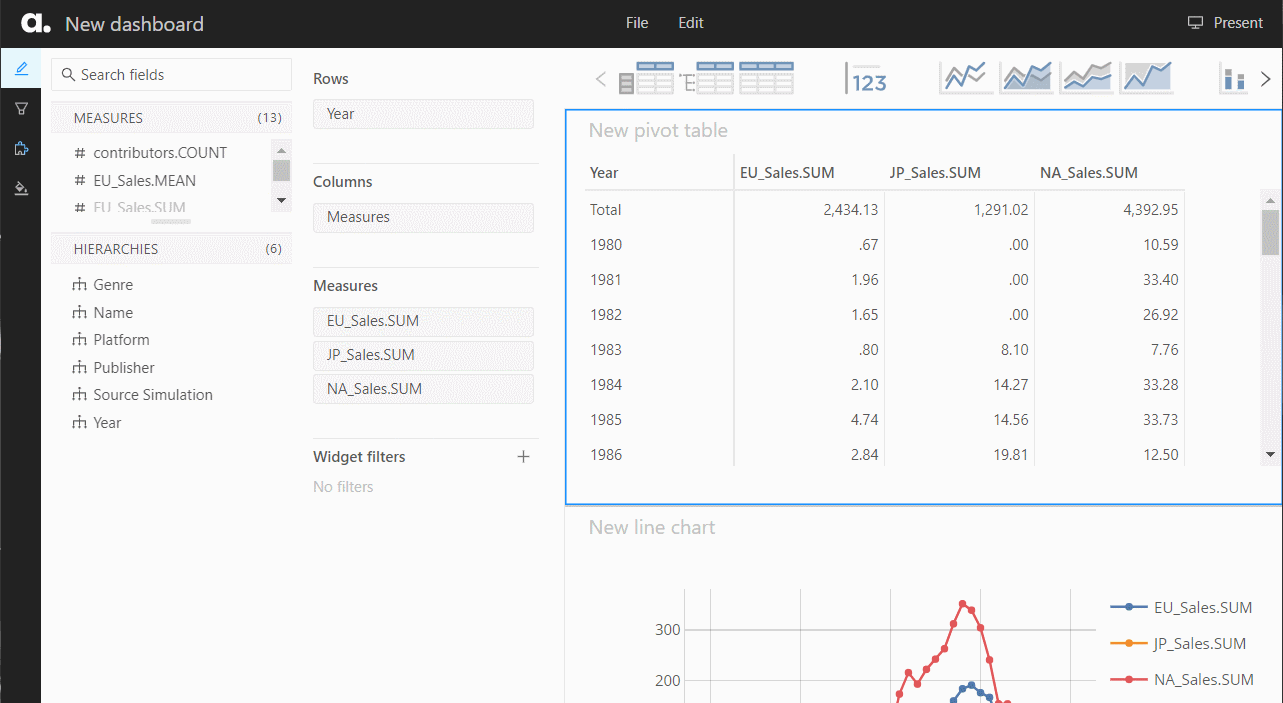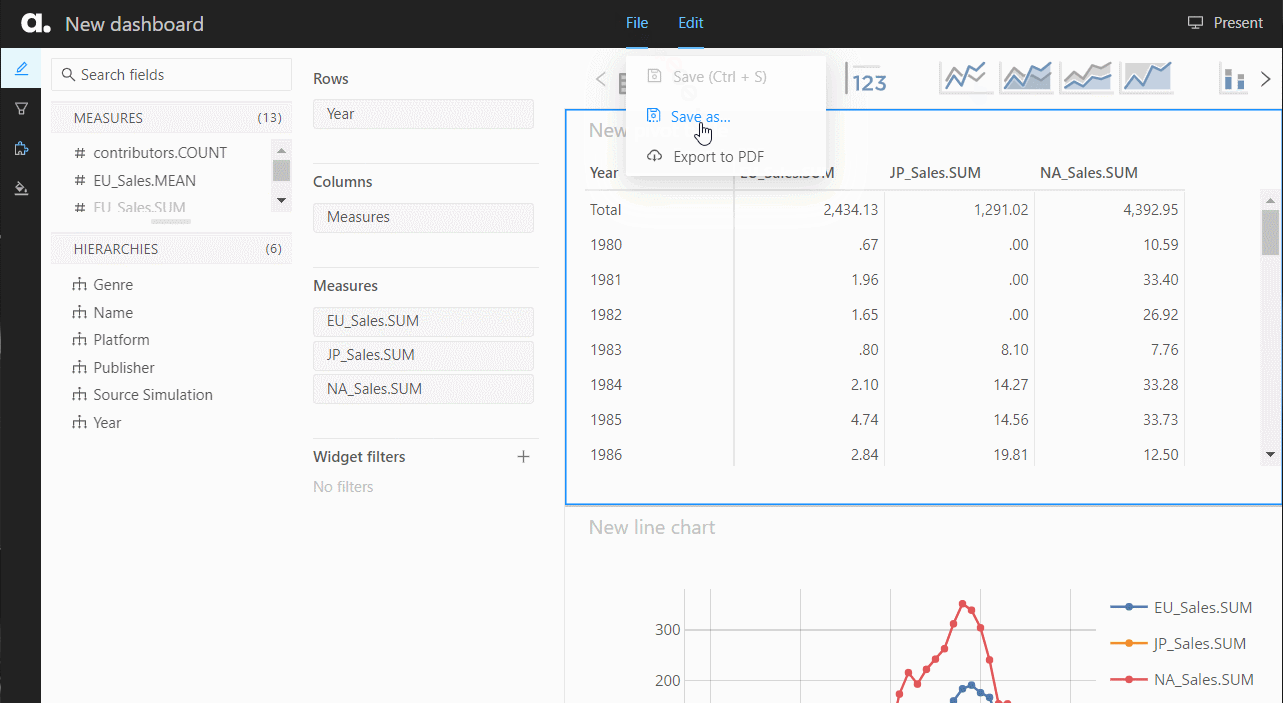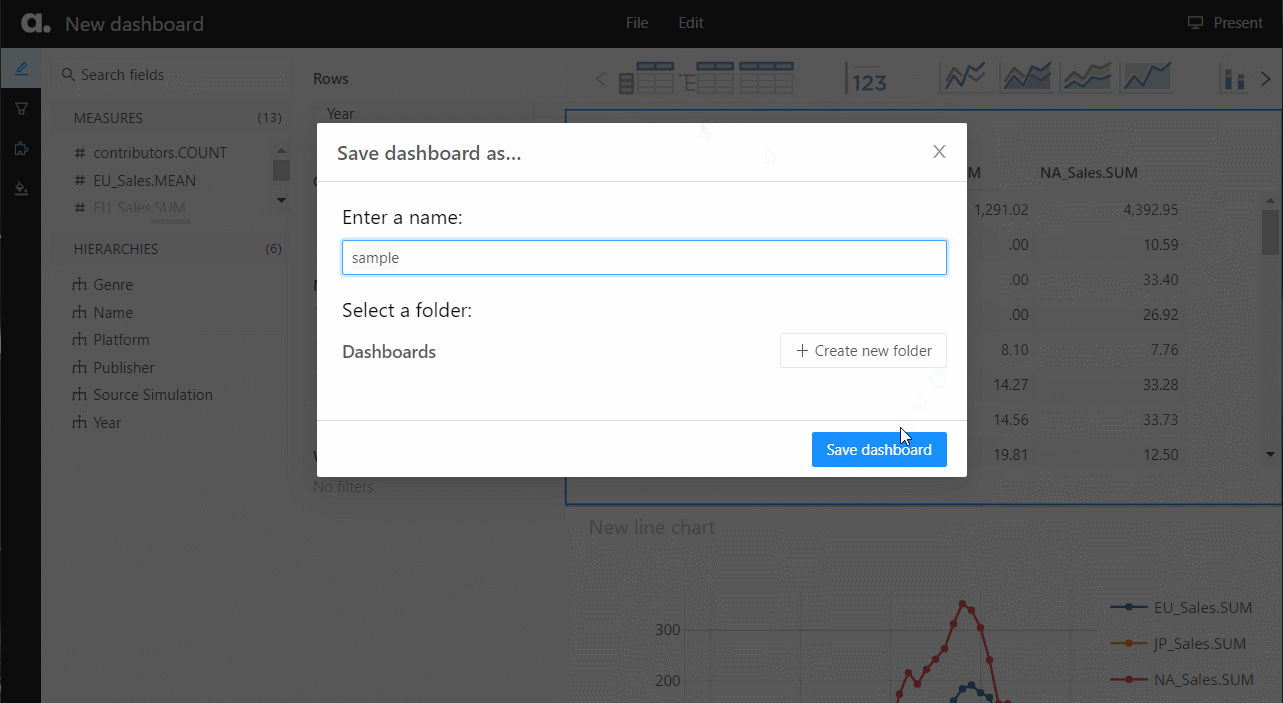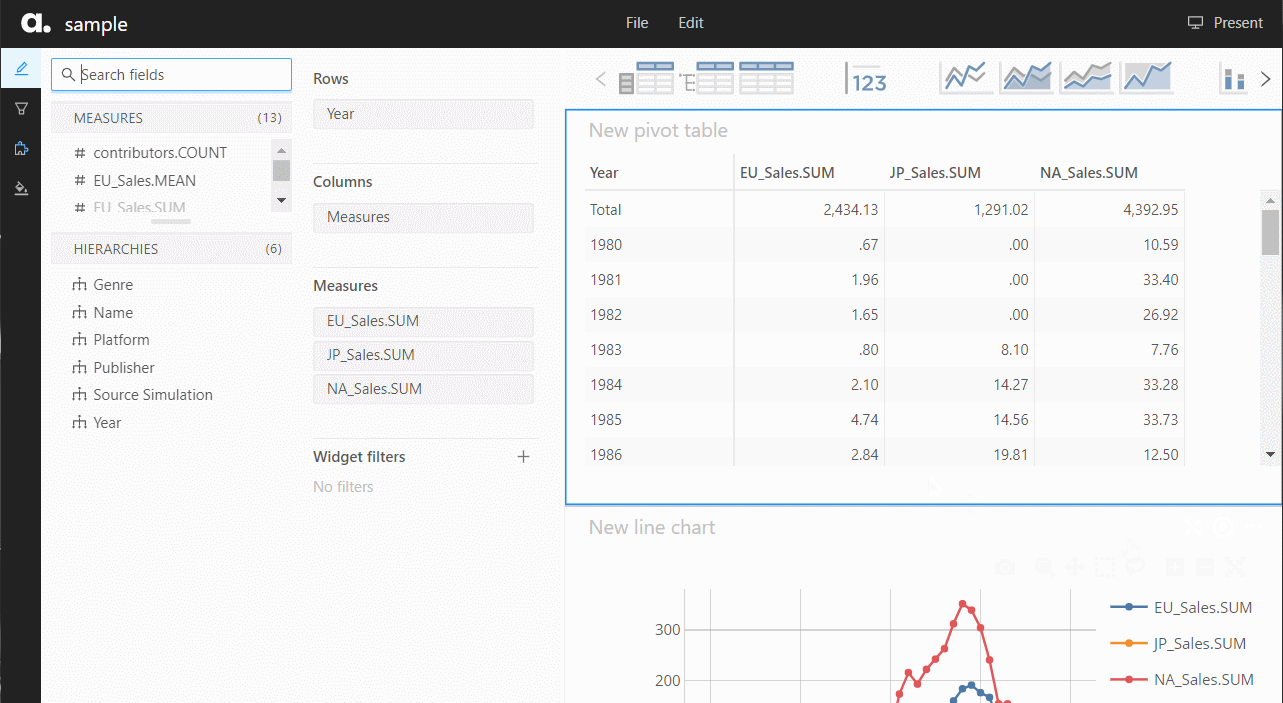
保存したダッシュボードを表示したり、編集したりするときは、以下のURLをクリックします。
クリックし、先程保存したダッシュボードを選択します。
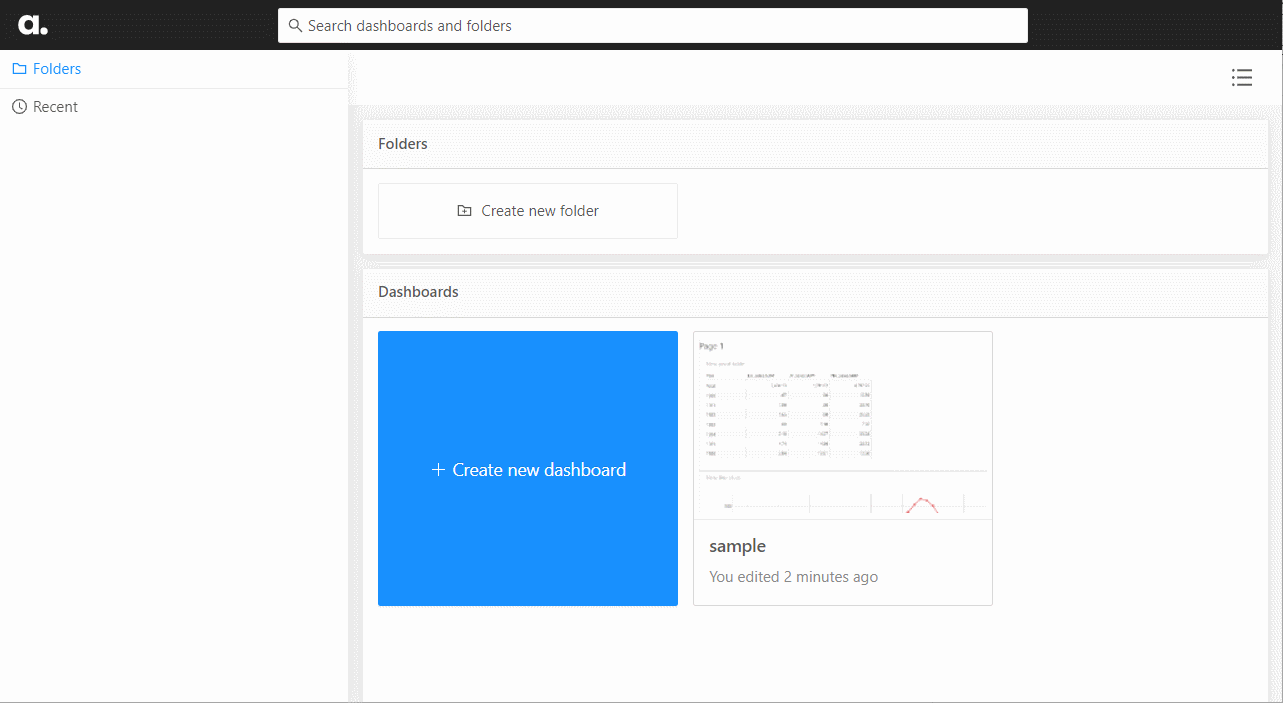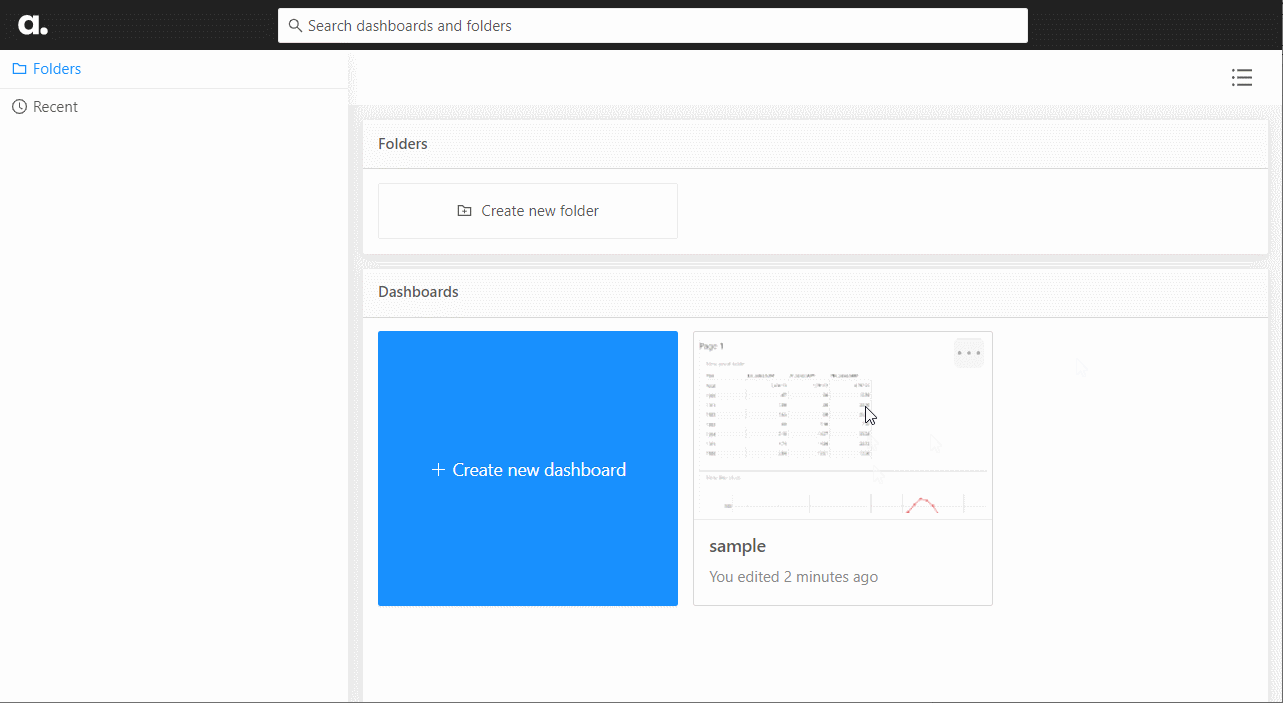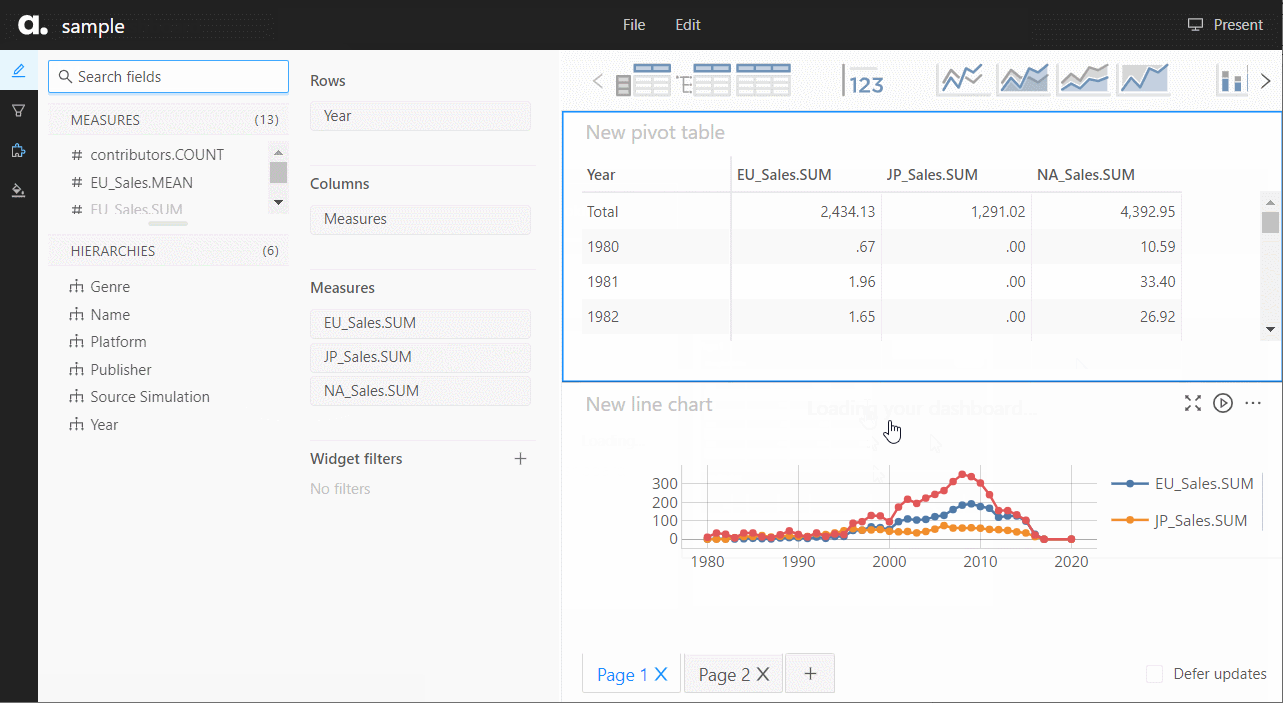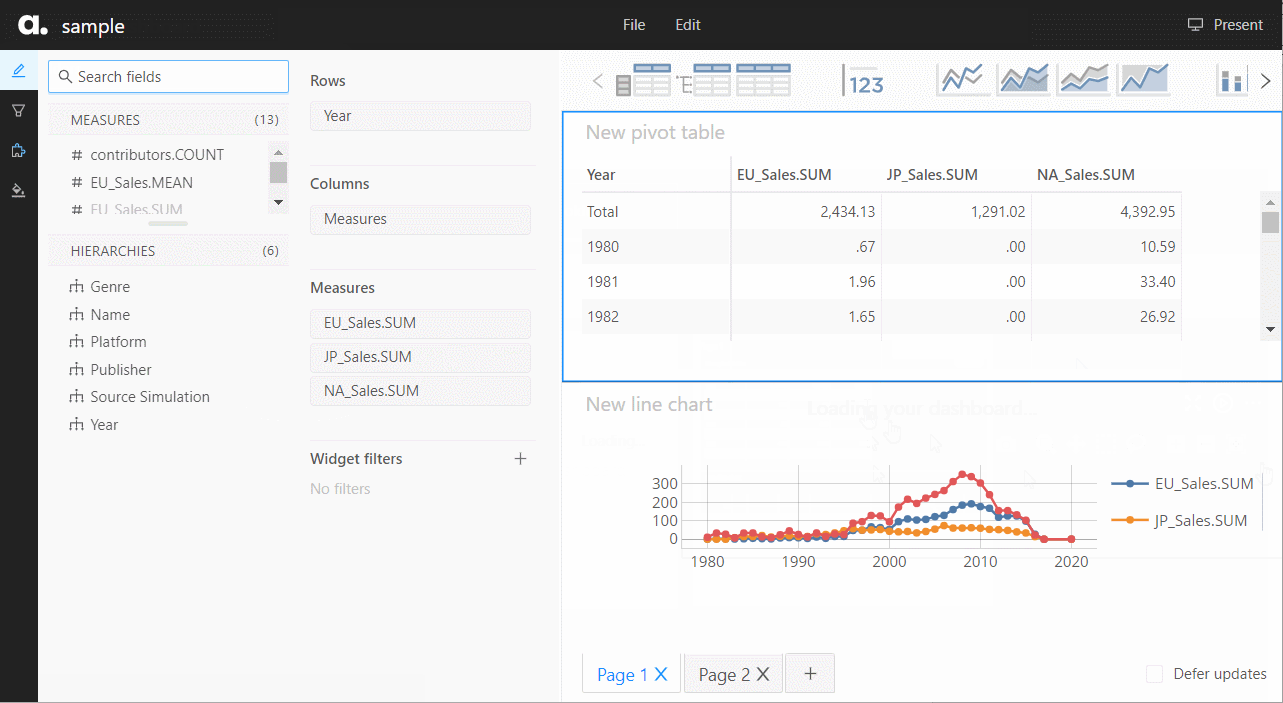
先程作成したダッシュボードが表示されます。
ダッシュボードの共有
作成したダッシュボードを第3者に使ってもらうには、Jupyter LabのNotebook(ipynbファイル)を共有し実行してもらうのが、もっとも簡単でしょう。
ただ、スマートさに欠けます。
Webアプリ化して共有する方法もありますが、その方法は次回に譲ります。
まとめ
今回は、「PythonでBIプラットフォームを構築するパッケージatoti」の簡単な使い方を説明しました。
atotiは、ローカルPCのWebサーバ上で動いています。
作成したダッシュボードを第3者に使ってもらうには、例えばngrok(エングロック)などのローカルPCなどで開発したWebアプリを簡単にグローバルに公開できる、便利ツールを使う方法もあります。
次回は、ngrok(エングロック)のインストールから構築したダッシュボードの公開までのお話しをします。