
機械学習などの数理モデルには、通常幾つかのハイパーパラメータがあり、そのハイパーパラメータの設定次第で大きく精度が変わります。
このハイパーパラメータを調整し最適な設定を探すタスクを、ハイパーパラメータチューニングと言います。
ハイパーパラメータチューニングは、モデル構築をするデータサイエンティストや機械学習エンジニアなどの腕次第です。
ただ、ある程度自動化しようという動きもあり、ハイパーパラメータチューニング用の探索アルゴリズムが幾つか提案されています。
主なものは以下の3つです。
- グリッドサーチ(Grid Search)
- ランダムサーチ(Random Search)
- ベイズ最適化(Bayesian Optimization)
グリッドサーチは設定した範囲内でハイパーパラメータ設定を全組み合わせ試行し、ランダムサーチはランダムにハイパーパラメータ設定の組み合わせを作り試行します。
ベイズ最適化は前回のハイパーパラメータ設定の組み合わせによる試行を参考に効率よく設定の組み合わせを作り試行していきます。
Optunaは、ハイパーパラメータチューニングをベイズ最適化で行う代表的なPythonのライブラリーの1つで、目的関数(objective function)を設定し最適化を目指すことでより良いハイパーパラメータの組み合わせを探索します。非常に便利なものです。

例えば、Scikit-Learn(sklearn)などで予測モデルを構築するとき、ハイパーパラメータの設定をデフォルトのままにして使用している方は、Optunaなどを使いハイパーパラメータチューニングにチャレンジしてみてください。
今回は、「Python の ハイパーパラメータ自動最適化ライブラリー Optuna のちょっとした使い方」について簡単に説明します。
ライブラリー「Optuna」のインストール
コマンドプロンプト上で、condaでインストールするときのコードは以下です。
conda install -c conda-forge optuna
コマンドプロンプト上で、pipでインストールするときのコードは以下です。
pip install optuna
Optuna の手順
冒頭で説明しましたが、Optunaは、目的関数(objective function)を設定し最適化を目指すことでより良いハイパーパラメータの組み合わせを探索します。
以下、ざっくり手順です。
- ステップ1:目的関数を設定する
- 各モデルのハイパーパラメータの集合を定義する
- 良し悪しを判断するメトリクスを定義する
- ステップ2:目的関数の最適化を実行する
- ステップ3:最適解を利用する
ステップ4で試行回数(n_trials)を設定し実行します。試行回数が多いほど時間が掛かりますが、より良い解になる可能性が高くなります。
簡単な例
Optunaの挙動を理解するために、ある2次関数の最小値を求める目的関数を作り実行してみます。
ライブラリーを読み込みます。以下、コードです。
# ライブラリーの読み込み import optuna
目的関数を設定します。以下、コードです。数理モデルが無いので、ステップ2を飛ばしています。
# 2次関数
def f(x):
return ((x - 3) ** 2)
# 目的関数の設定(ステップ1)
def objective(trial):
x = trial.suggest_float('x', -7, 13) #ハイパーパラメータの集合を定義する
return f(x) #良し悪しを判断するメトリクスを返す
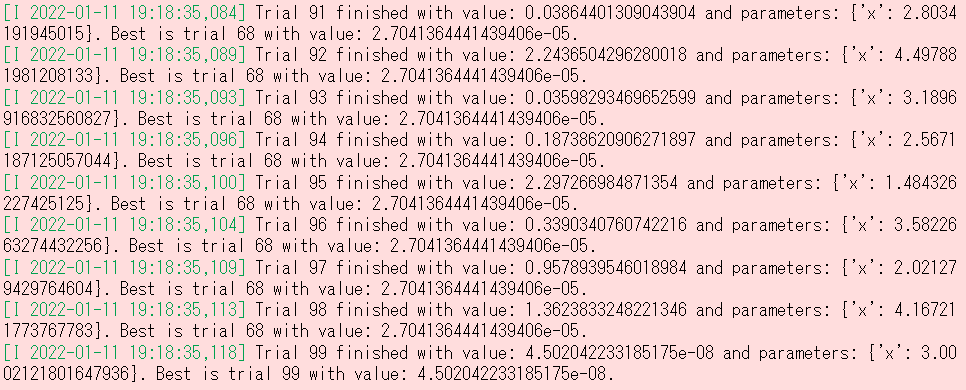
目的関数を最適化します。以下、コードです。
# 目的関数の最適化を実行する(ステップ2) study = optuna.create_study(direction="minimize") study.optimize(objective, n_trials=100)
以下、実行結果です。
最適解を表示します。以下、コードです。
# 最適解の出力
print(f"The best value is : \n {study.best_value}")
print(f"The best parameters are : \n {study.best_params}")
以下、実行結果です。

分類問題(乳がんデータ)
乳がんデータを使い、実施してみます。データセットに関しては、以下で簡単に説明しています。
AutoML【TPOT】で分類問題を解く
https://www.salesanalytics.co.jp/software/automl/automl003/#i
簡単に説明すると……
- 目的変数Y:良性(=1)と悪性(=0)の2クラス値
- 説明変数X:細胞核に関する30個の特徴量
乳がんかどうかを分類する問題を、以下の3種類のモデルの中から探索します。
- ロジスティック回帰(LogReg)
- サポートベクターマシン(SVC)
- ランダムフォレスト(RandomForest)
モデルごとに、ハイパーパラメータの範囲を定め、その中から最良のモデルを探索していきます。
最良と判断するためにはメトリクスが必要です。今回は、最適化するメトリクスとして正答率(accuracy)を用います。正答率の最大化です。
ライブラリーを読み込みます。以下、コードです。
# ライブラリーの読み込み import optuna import pandas as pd import sklearn.svm from sklearn import linear_model from sklearn import ensemble from sklearn import datasets from sklearn import model_selection
サンプルデータ(乳がんデータ)を読み込みます。以下、コードです。
# サンプルデータの読み込み(乳がんデータ) X,y = datasets.load_breast_cancer(return_X_y=True, as_frame=True)
目的関数を設定します。以下、コードです。
# 目的関数の設定(ステップ1)
def objective(trial):
#ハイパーパラメータの集合を定義する
##推定器の集合
classifier_name = trial.suggest_categorical("classifier",
["LogReg",
"SVC",
"RandomForest"
]
)
##推定器ごとのハイパーパラメータの集合
###ロジ回(LogReg)
if classifier_name == 'LogReg':
logreg_c = trial.suggest_float("logreg_c",
1e-10, 1e10,
log=True
)
classifier_obj = linear_model.LogisticRegression(C=logreg_c)
###サポートベクターマシン(SVC)
elif classifier_name == "SVC":
svc_c = trial.suggest_float("svc_c",
1e-10, 1e10,
log=True
)
classifier_obj = sklearn.svm.SVC(C=svc_c,
gamma="auto"
)
###ランダムフォレスト(RandomForest)
else:
rf_n_estimators = trial.suggest_int("rf_n_estimators",
10, 1000
)
rf_max_depth = trial.suggest_int("rf_max_depth",
2, 50,
log=True
)
classifier_obj = ensemble.RandomForestClassifier(
max_depth=rf_max_depth,
n_estimators=rf_n_estimators
)
#良し悪しを判断するメトリクスを定義する
##CVの実施
score = model_selection.cross_val_score(classifier_obj,
X,
y,
n_jobs=-1,
cv=10
)
##CVの結果の平均値
accuracy = score.mean()
return accuracy
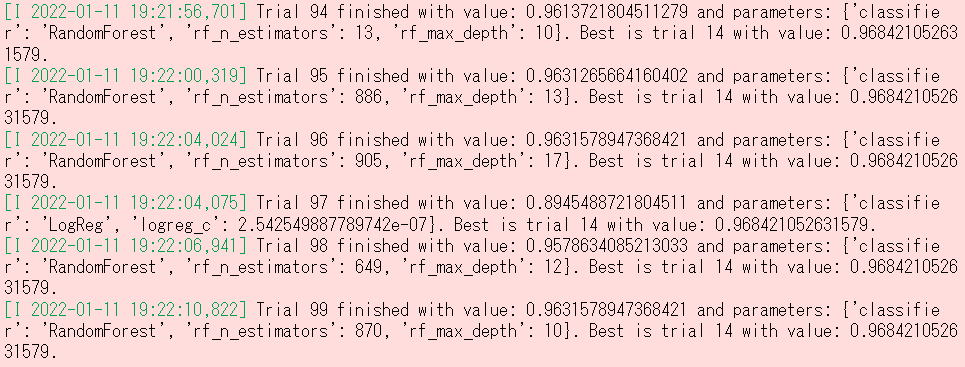
目的関数を最適化します。以下、コードです。
# 目的関数の最適化を実行する(ステップ2) study = optuna.create_study(direction="maximize") study.optimize(objective, n_trials=100)
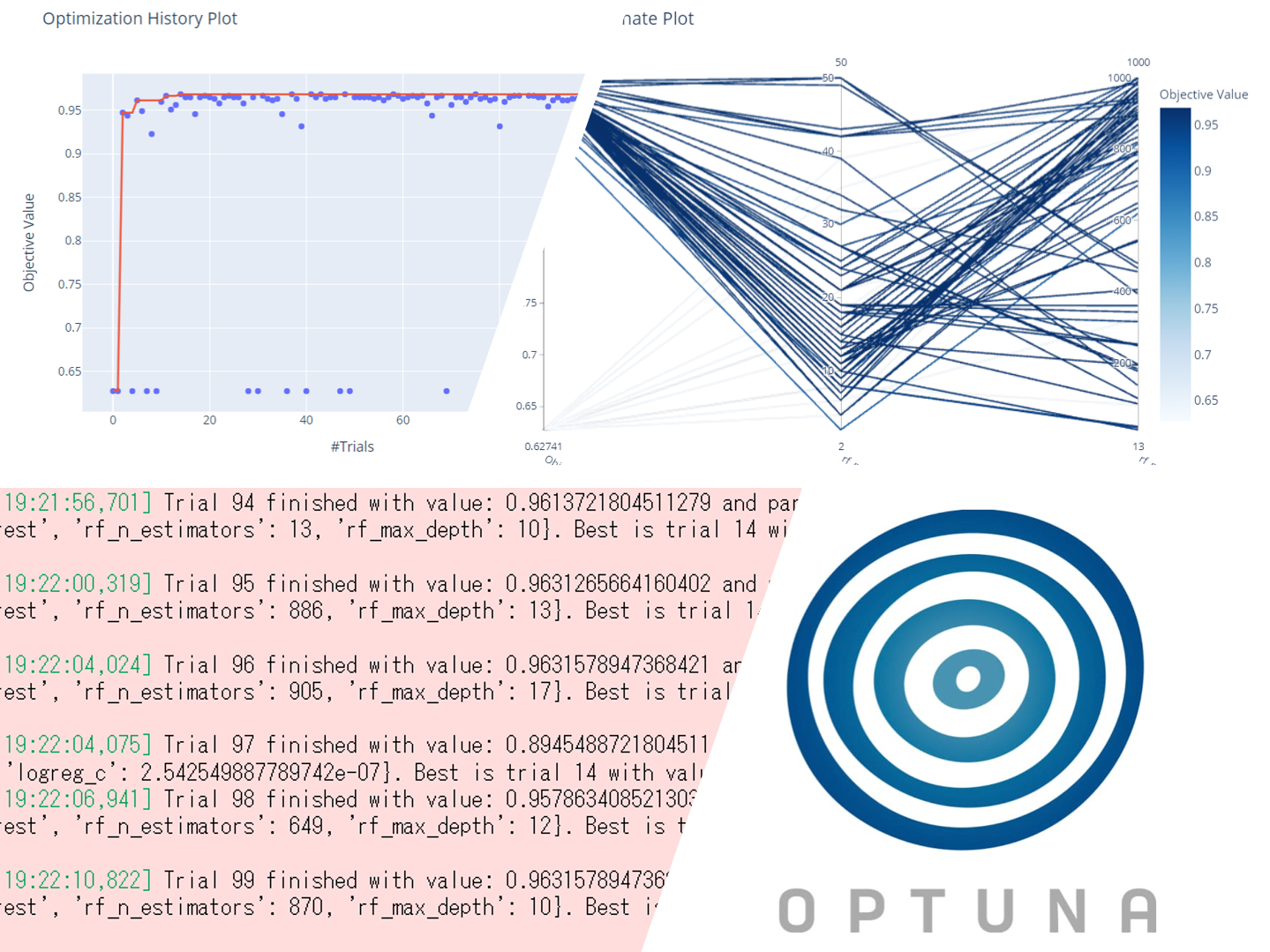
以下、実行結果です。
最適解を表示します。以下、コードです。
# 最適解の出力
print(f"The best value is : \n {study.best_value}")
print(f"The best parameters are : \n {study.best_params}")
以下、実行結果です。

最良のモデルは、ランダムフォイレストであることが分かります。
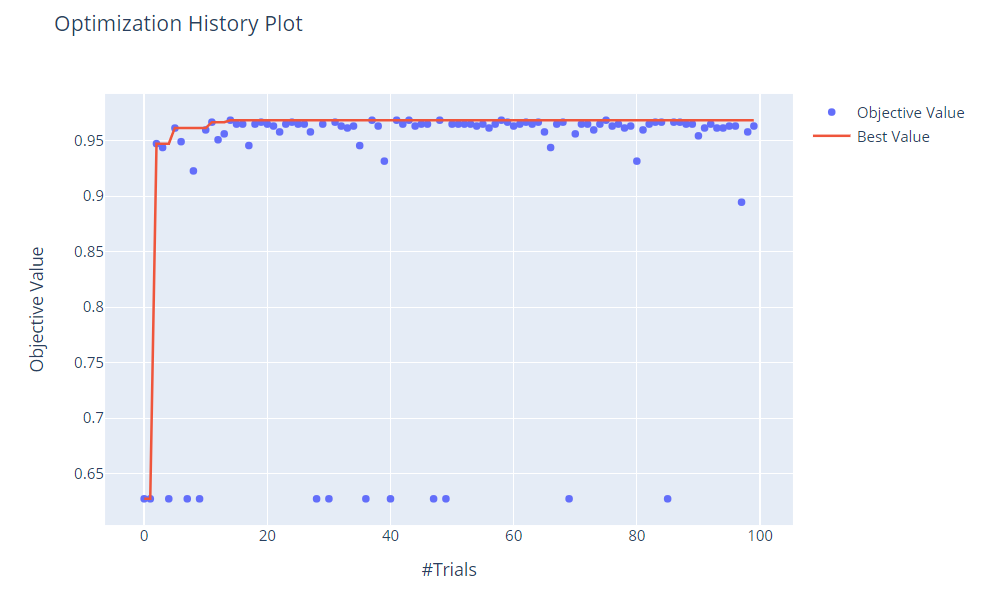
探索の軌跡を見てみます。以下、コードです。
# 最適解に至るまでの軌跡 optuna.visualization.plot_optimization_history(study).show()
以下、実行結果です。
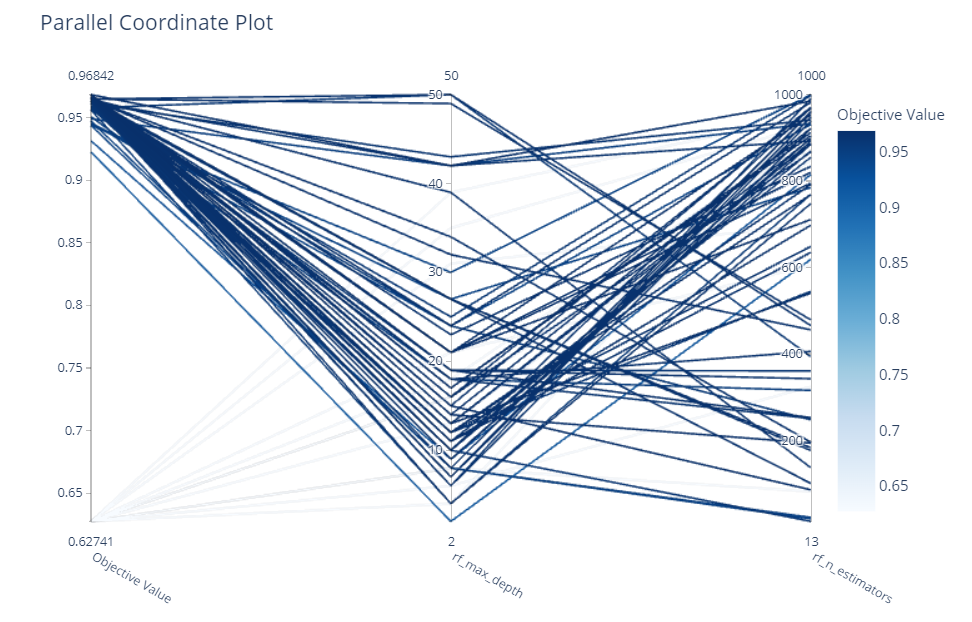
最良のモデルとされたランダムフォレストを深堀してみます。ハイパーパラメータ設定によって、どのように正答率が変化するのかを見てみます。
以下、コードです。
# ランダムフォレストのパラメータ設定の組み合わせと正答率
optuna.visualization.plot_parallel_coordinate(study,
params=['rf_n_estimators',
'rf_max_depth'
]
)
以下、実行結果です。
まとめ
今回は、「Python の ハイパーパラメータ自動最適化ライブラリー Optuna のちょっとした使い方」について簡単に説明しました。
Optunaを使ったハイパーパラメータチューニングは、非常に簡単にできます。
しかし、Optunaを使う前に、個々の数理モデルを構築するアルゴリズムのハイパーパラメータを理解しておく必要があります。
Optunaを使ったハイパーパラメータチューニングの結果は、限られた試行回数の中の最良のハイパーパラメータの組み合わせを提示してくれるだけです。
最後は、人が微修正などしてハイパーパラメータを設定することになります。
ハイパーパラメータの設定をデフォルトのままにして使用している方は、Optunaなどを使いハイパーパラメータチューニングにチャレンジしてみてください。
Python のハイパーパラメータ自動最適化ライブラリー Optuna その2 – Optunaを使うとき最低限覚えておきたい探索範囲の指定方法 –