
多くの人にとって馴染みがあるのは、時系列データ系の数理モデル(アルゴリズム)よりも、テーブルデータ系の数理モデル(アルゴリズム)の方です。
例えば、以下の数理モデル(アルゴリズム)はテーブルデータ系のものです。
- 線形回帰モデル(単回帰、重回帰、など)
- 正則化回帰モデル(Ridge回帰、Lasso回帰、など)
- 一般化線形モデル(GLMM)
- 一般化加法モデル(GAM)
- 階層線形モデル、マルチレベルモデル、一般化混合モデル
- 決定木(ディシジョンツリー)
- ランダムフォレスト
- ブースティングモデル(AdaBoost、XGBoost、LightGBMなど)
- ニューラルネットワークモデル
……などなど。
前回は、時系列特徴量付きデータセットを使い、テーブルデータ系の数理モデル(アルゴリズム)の中で最も一般的な線形回帰モデルで、時系列予測モデルを構築しました。
今回は、前回と同じ時系列特徴量付きデータセットを使い、正則化項付き線形回帰モデル(Ridge回帰、Lasso回帰、Elastic net回帰など)で時系列予測モデルを構築します。
正則化項付き線形回帰モデルとは
奇妙な数式など登場してきますので、興味のない方は読み飛ばして下さい。
通常の線形回帰モデルは、最小二乗法という方法で回帰式の回帰係数(定数含む)を求めます。
例えば、線形回帰式を以下のように表現したとします。
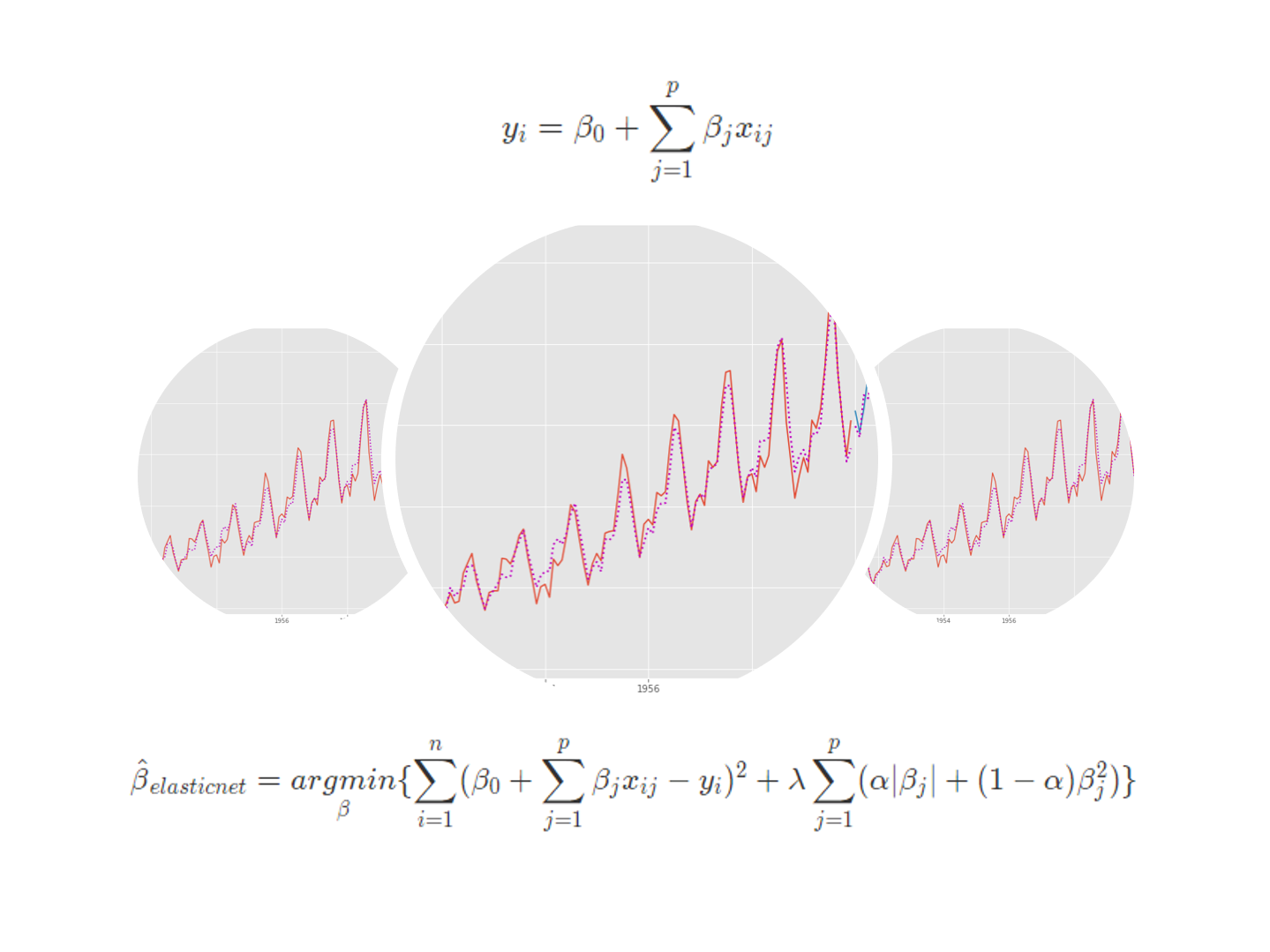
y_i = \beta_0 + \sum_{j=1}^p \beta_j x_{ij}yが目的変数で、xが説明変数です。pが説明変数の数です。nがデータ数(データセットの行数)です。
何かしら回帰係数(定数含む)を設定すると、何かしらの線形回帰式が出来上がります。何かしらの線形回帰式が出来上がれば、yの予測値を求めることができます。
yの予測値は、yの実測値に近いほどいいでしょう。言い換えると、予測値と実測値の差は小さいほどいいでしょう。もう少し言うと、予測値と実測値の差を二乗した値は小さいほどいいでしょう。
予測値と実測値の差を二乗した値を最小化するような回帰係数(定数含む)を知ることができれば、でたらめに回帰係数(定数含む)を設定し線形回帰式を作るより、非常に嬉しいでしょう。
予測値と実測値の差を二乗した値を最小化するような回帰係数(定数含む)を求める方法が、最小二乗法です。
\hat{\beta} = \underset{\beta}{argmin} \{\sum_{i=1}^n (\beta_0 + \sum_{j=1}^p \beta_j x_{ij}-y_i)^2 \}
この最小二乗法にある制約(正則化項)を付け加えた、制約(正則化項)付き最小二乗法という方法で回帰式の回帰係数(定数含む)を求めるのが、正則化項付き線形回帰モデルです。
通常の線形回帰モデルと比べ、求めた回帰係数(定数含む)が0の方向に縮小(絶対値が小さくなる)します。
この制約(正則化項)により、マルチコ(説明変数同士の相関が高いために起こる不具合)や過学習などの影響を緩和してくれます。
どのような制約(正則化項)を加えるかで、名称が変わります。有名なのは、以下の3つです。
- Ridge回帰
- Lasso回帰
- Elastic Net回帰
Ridge回帰は、線形回帰モデルの回帰係数の二乗和を正則化項として加えた推定法です。ハイパーパラメータとして、正則化項の重み(正則化パラメータ)を設定する必要があります。
\hat{\beta}_{ridge} = \underset{\beta}{argmin} \{\sum_{i=1}^n (\beta_0 + \sum_{j=1}^p \beta_j x_{ij}-y_i )^2 + \lambda \sum_{j=1}^p \beta_j^2 \}
Lasso回帰は、線形回帰モデルの回帰係数の絶対値の和を正則化項として加えた推定法です。ハイパーパラメータとして、正則化項の重み(正則化パラメータ)を設定する必要があります。
\hat{\beta}_{lasso} = \underset{\beta}{argmin} \{\sum_{i=1}^n (\beta_0 + \sum_{j=1}^p \beta_j x_{ij}-y_i )^2 + \lambda \sum_{j=1}^p |\beta_j| \}Lasso回帰はRidge回帰と異なり、回帰係数を0にするため変数選択を自動で実施してくれます。
Elastic Net回帰は、Ridge回帰とLasso回帰のハイブリッドモデルです。ハイパーパラメータとして、その割合を設定する必要があります。もちろん、ハイパーパラメータとして、正則化項の重み(正則化パラメータ)を設定する必要があります。
\hat{\beta}_{elasticnet} = \underset{\beta}{argmin} \{\sum_{i=1}^n (\beta_0 + \sum_{j=1}^p \beta_j x_{ij}-y_i )^2 + \lambda \sum_{j=1}^p (\alpha |\beta_j| + (1-\alpha)\beta_j^2 ) \}
必要なライブラリーの読み込み
先ず、必要なライブラリーなどを読み込みます。
以下、コードです。
import numpy as np
import pandas as pd
import optuna
from sklearn.linear_model import RidgeCV
from sklearn.linear_model import LassoCV
from sklearn.linear_model import ElasticNetCV
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_percentage_error
import matplotlib.pyplot as plt
plt.style.use('ggplot') #グラフのスタイル
plt.rcParams['figure.figsize'] = [12, 9] # グラフサイズ設定
利用するデータ
今回利用するデータは、前回準備した時系列特徴量付きデータセットです。
以下からダウンロードできます。
dataset.csv
https://www.salesanalytics.co.jp/6ro8
このURLから直接データセットを読み込めます。
以下、コードです。
# データセットの読み込み
url='https://www.salesanalytics.co.jp/6ro8'
df=pd.read_csv(url, #読み込むデータのURL
index_col='Month', #変数「Month」をインデックスに設定
parse_dates=True) #インデックスを日付型に設定
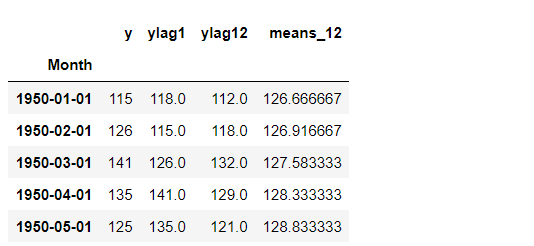
df.head() #確認
以下、実行結果です。
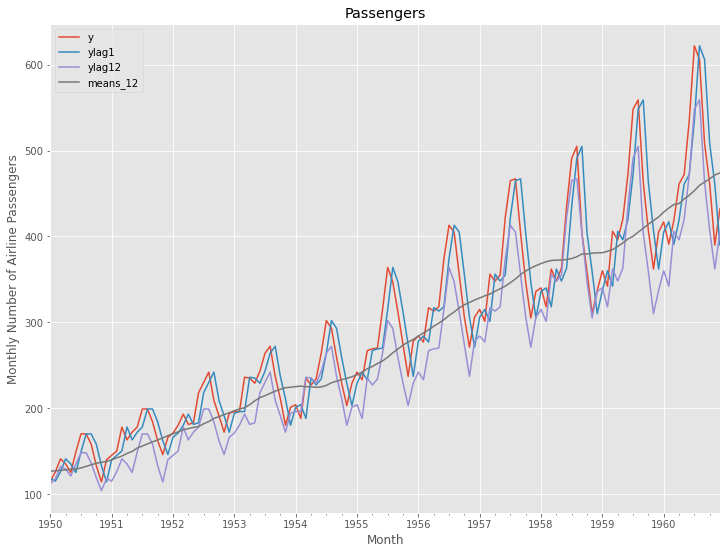
グラフ化し確認します。
以下、コードです。
# プロット
df.plot()
plt.title('Passengers') #グラフタイトル
plt.ylabel('Monthly Number of Airline Passengers') #タテ軸のラベル
plt.xlabel('Month') #ヨコ軸のラベル
plt.show()
以下、実行結果です。
次に、読み込んだデータセットを、学習データとテストデータに分割します。
以下、コードです。
# 学習データ
train = df.iloc[:-12]
y_train = train['y'] #目的変数y
X_train = train.drop('y', axis=1) #説明変数X
# テストデータ
test = df.iloc[-12:] #テストデータ
y_test = test['y'] #目的変数y
X_test = test.drop('y', axis=1) #説明変数X
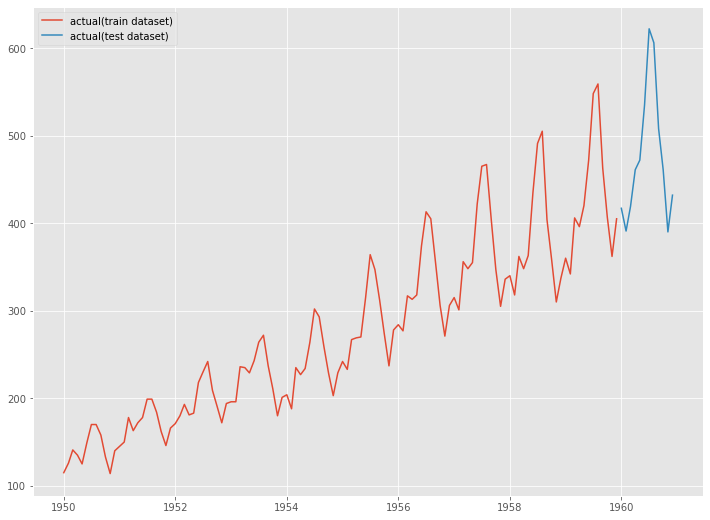
グラフ化します。
以下、コードです。
# グラフ化 fig, ax = plt.subplots() ax.plot(y_train.index, y_train.values, label="actual(train dataset)") ax.plot(y_test.index, y_test.values, label="actual(test dataset)") plt.legend()
以下、実行結果です。
学習データで正則化項付き線形回帰モデル(Ridge回帰、Lasso回帰、Elastic net回帰など)を構築し、構築したモデルをテストデータで精度検証します。
予測精度の評価指標
今回の予測精度の評価指標は、RMSE(二乗平均平方根誤差、Root Mean Squared Error)とMAE(平均絶対誤差、Mean Absolute Error)、MAPE(平均絶対パーセント誤差、Mean absolute percentage error)を使います。
以下の記号を使い精度指標の説明をします。
- y_i^{actual} ・・・i番目の実測値
- y_i^{pred} ・・・i番目の予測値
- n ・・・実測値・予測値の数
■ 二乗平均平方根誤差(RMSE、Root Mean Squared Error)
\sqrt{\frac{1}{n}\sum_{i=1}^n(y_i^{actual}-{y_i^{pred}})^2}■ 平均絶対誤差(MAE、Mean Absolute Error)
\frac{1}{n}\sum_{i=1}^n|y_i^{actual}-{y_i^{pred}}|■ 平均絶対パーセント誤差(MAPE、Mean absolute percentage error)
\frac{1}{n}\sum_{i=1}^n|\frac{y_i^{actual}-{y_i^{pred}}}{y_i^{actual}}|
Ridge回帰モデル
学習データを使って、Ridge回帰モデルを学習します。適切なハイパーパラメータを探索する、CV(クロスバリデーション)付きの関数で学習します。
以下、コードです。
regressor = RidgeCV(alphas=np.linspace(1, 10000000, 1000)/100, cv = 10) regressor.fit(X_train, y_train)
学習結果である回帰係数(定数含む)とハイパーパラメータを出力します。
以下、コードです。
# 切片と回帰係数
print('切片:',regressor.intercept_)
print('回帰係数:',regressor.coef_)
print('正則化パラメータ:',regressor.alpha_)
以下、実行結果です。
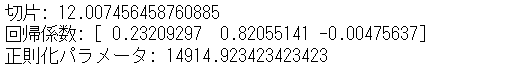
テストデータで精度検証します。
以下、コードです。
# 予測
train_pred = regressor.predict(X_train)
test_pred = regressor.predict(X_test)
# 精度指標(テストデータ)
print('RMSE:')
print(np.sqrt(mean_squared_error(y_test, test_pred)))
print('MAE:')
print(mean_absolute_error(y_test, test_pred))
print('MAPE:')
print(mean_absolute_percentage_error(y_test, test_pred))
以下、実行結果です。

グラフ化します。
以下、コードです。
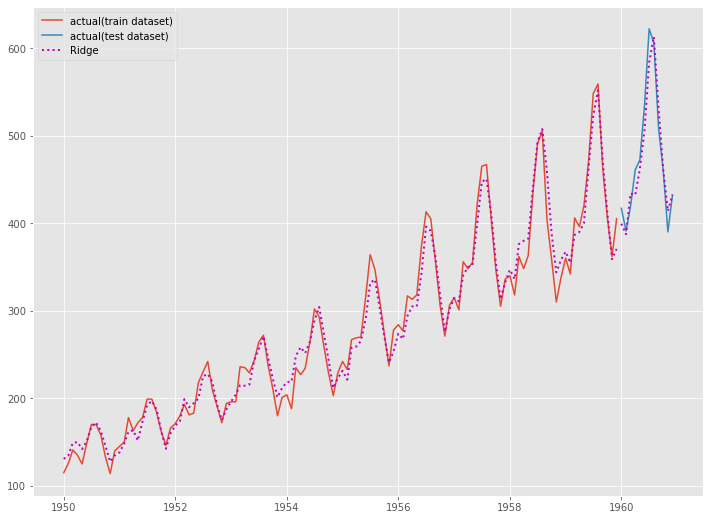
# グラフ化 fig, ax = plt.subplots() ax.plot(y_train.index, y_train.values, label="actual(train dataset)") ax.plot(y_test.index, y_test.values, label="actual(test dataset)") ax.plot(y_train.index, train_pred, linestyle="dotted", lw=2,color="m") ax.plot(y_test.index, test_pred, label="Ridge", linestyle="dotted", lw=2, color="m") plt.legend()
以下、実行結果です。
Lasso回帰モデル
学習データを使って、Lasso回帰モデルを学習します。適切なハイパーパラメータを探索する、CV(クロスバリデーション)付きの関数で学習します。
以下、コードです。
regressor = LassoCV(alphas=np.linspace(1, 10000000, 1000)/100, cv = 10) regressor.fit(X_train, y_train)
学習結果である回帰係数(定数含む)とハイパーパラメータを出力します。
以下、コードです。
# 切片と回帰係数
print('切片:',regressor.intercept_)
print('回帰係数:',regressor.coef_)
print('正則化パラメータ:',regressor.alpha_)
以下、実行結果です。
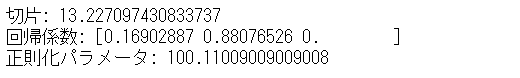
左から3番目の回帰係数が0になっています。Lassoによる変数選択では、左から1番目と2番目の説明変数(ylag1とylag2)だけで十分だ、ということです。
テストデータで精度検証します。
以下、コードです。
# 予測
train_pred = regressor.predict(X_train)
test_pred = regressor.predict(X_test)
# 精度指標(テストデータ)
print('RMSE:')
print(np.sqrt(mean_squared_error(y_test, test_pred)))
print('MAE:')
print(mean_absolute_error(y_test, test_pred))
print('MAPE:')
print(mean_absolute_percentage_error(y_test, test_pred))
以下、実行結果です。

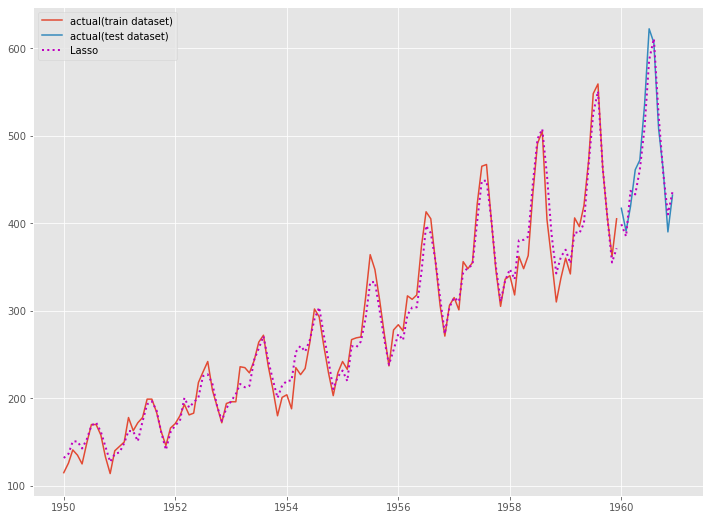
Ridge回帰よりもLasso回帰の方が、予測精度がいいようです。
グラフ化します。
以下、コードです。
# グラフ化 fig, ax = plt.subplots() ax.plot(y_train.index, y_train.values, label="actual(train dataset)") ax.plot(y_test.index, y_test.values, label="actual(test dataset)") ax.plot(y_train.index, train_pred, linestyle="dotted", lw=2,color="m") ax.plot(y_test.index, test_pred, label="Lasso", linestyle="dotted", lw=2, color="m") plt.legend()
以下、実行結果です。
Elastic Net回帰モデル
学習データを使って、Elastic Net回帰モデルを学習します。適切なハイパーパラメータを探索する、CV(クロスバリデーション)付きの関数で学習します。
以下、コードです。
regressor = ElasticNetCV(alphas=np.linspace(1, 10000000, 1000)/100,
l1_ratio=np.linspace(0, 10000, 1000)/10000,
cv = 10)
regressor.fit(X_train, y_train)
学習結果である回帰係数(定数含む)とハイパーパラメータを出力します。
以下、コードです。
# 切片と回帰係数
print('切片:',regressor.intercept_)
print('回帰係数:',regressor.coef_)
print('正則化パラメータ:',regressor.alpha_)
print('L1の割合:',regressor.l1_ratio_)
以下、実行結果です。

左から3番目の回帰係数が0になっています。Elastic Netによる変数選択では、左から1番目と2番目の説明変数(ylag1とylag2)だけで十分だ、ということです。
テストデータで精度検証します。
以下、コードです。
# 予測
train_pred = regressor.predict(X_train)
test_pred = regressor.predict(X_test)
# 精度指標(テストデータ)
print('RMSE:')
print(np.sqrt(mean_squared_error(y_test, test_pred)))
print('MAE:')
print(mean_absolute_error(y_test, test_pred))
print('MAPE:')
print(mean_absolute_percentage_error(y_test, test_pred))
以下、実行結果です。

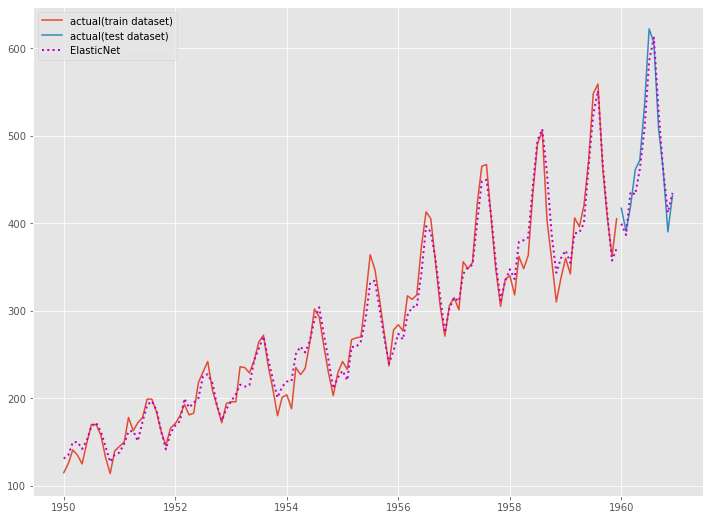
Elastic Net回帰よりもLasso回帰の方が、予測精度がいいようです。
グラフ化します。
以下、コードです。
# グラフ化 fig, ax = plt.subplots() ax.plot(y_train.index, y_train.values, label="actual(train dataset)") ax.plot(y_test.index, y_test.values, label="actual(test dataset)") ax.plot(y_train.index, train_pred, linestyle="dotted", lw=2,color="m") ax.plot(y_test.index, test_pred, label="ElasticNet", linestyle="dotted", lw=2, color="m") plt.legend()
以下、実行結果です。
次回
今回は、前回と同じ時系列特徴量付きデータセットを使い、正則化項付き線形回帰モデル(Ridge回帰、Lasso回帰、Elastic net回帰など)で時系列予測モデルを構築しました。
次回は、今回と同じ時系列特徴量付きデータセットを使い、ディシジョンツリーモデル(決定木)で時系列予測モデルを構築します。