
ChatGPTモデルは、 OpenAIによってトレーニングされたLLM(大規模な言語モデル)です。
プロンプトで話しかけると、人のように答えてくれます。テキストでですが……
そして何よりこのChatGPTは、優れたデータサイエンティストにもなります。
例えば、プロンプトで以下のセンテンスを冒頭に付け加えることで、優れたデータサイエンティストとして、Pythonのコーディングをしてくれます。
ただ、大きな問題が1つあります。
ChatGPTが理解できるように質問する必要があります。
多少あいまいな表現は理解してくれますが、最低限必要な情報を与えないと、適切な回答が返ってきません。それは、人でも同じことです。
そこで、今回はChatGPTが理解してくれる構文(データ分析の依頼文のフォーマット)を紹介します。
この構文の【******】を、あなたが依頼した内容に変更するだけで、恐らくChatGPTは理解してくれることでしょう。
前回は、予測モデルについてお話ししました。
今回は、「データ理解のために実施するデータ可視化(Data Visualization)と探索的データ分析(EDA=Exploratory Data Analysis)」です。
ちなみに、まだOpenAIのアカウントを作成していない方は、作成して下さい。
以下の記事で簡単に説明しています。それほど難しいものではありません。
ChatGPTの機能は、OpenAIのサイト(https://chat.openai.com/)でも、上述の記事で紹介したようなJupyter Notebook上のChatGPTでも、どちらでも構いません。ChatGPTが使えればどれでも構いません。
ChatGPT
https://chat.openai.com/
構文(データ理解のためのEDAの依頼文のフォーマット)
以下、予測モデルを構築するときの構文です。
【 1 】 のデータセットを使います。
データ理解のために、データの可視化と探索的データ分析をして下さい。
【 2 】。
- 【 1 】 :データセット
- データセットの概要を記載
- このとき、目的変数は明記
- 【 2 】 :追加事項(無ければ記載してくてもOK)
- 具体的な変数名などを記載
ちなみに、PythonではなくR言語でコーディングして欲しいときは、Pythonの個所を次のようにRに変えてください。
【 1 】 のデータセットを使います。
データ理解のために、データの可視化と探索的データ分析をして下さい。
【 2 】。
例1:データセットの概要のみ指定
例えば、次にように記載します。解約に関するデータセットです。
顧客の特徴と解約(churn)のデータセットを使います。
データ理解のために、データの可視化と探索的データ分析をして下さい。
- 【 1 】 :データセット ⇒ 顧客の特徴と解約(churn)
- 【 2 】 :追加事項 ⇒ なし
実際に、ChatGPTに聞いてみます。
以下、実行結果です。
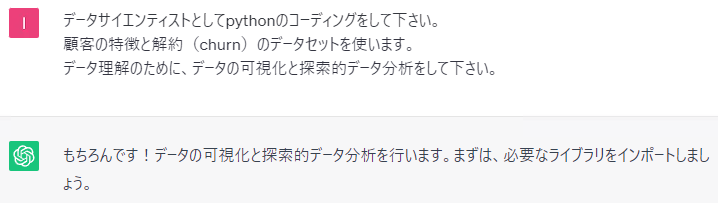
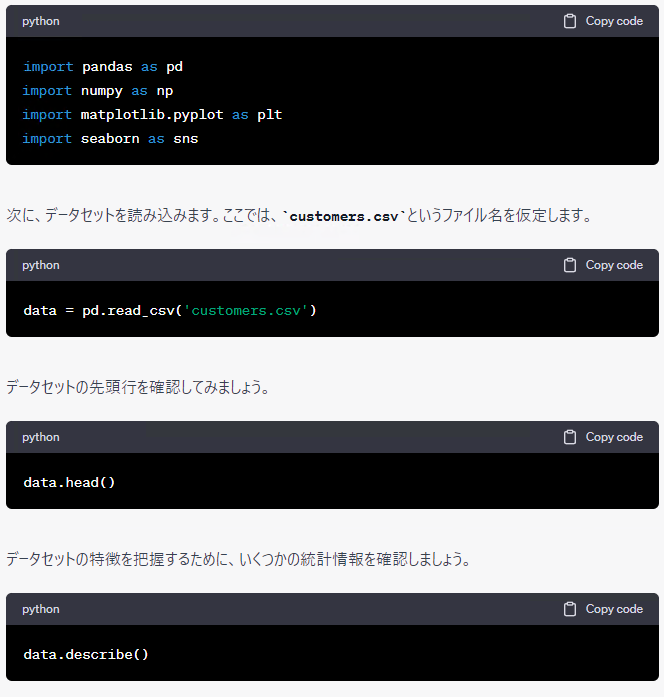
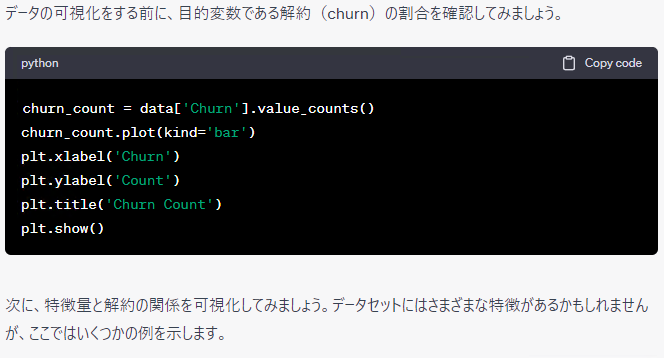
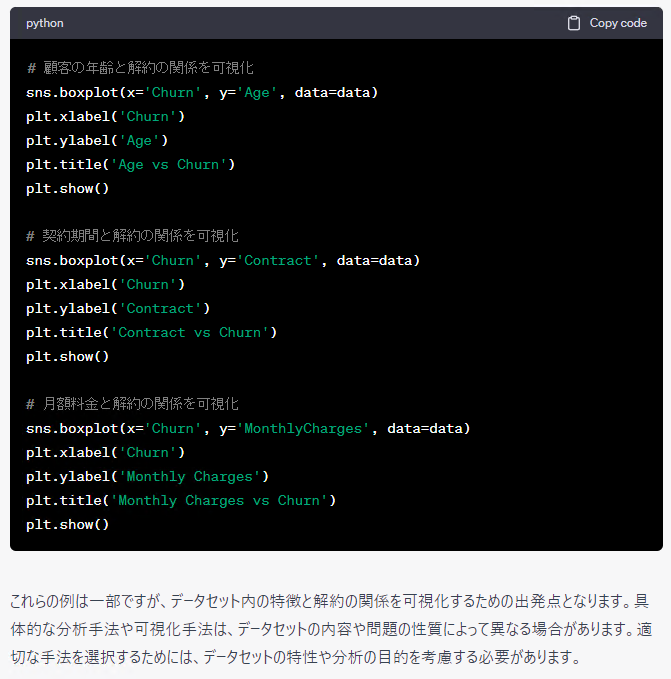
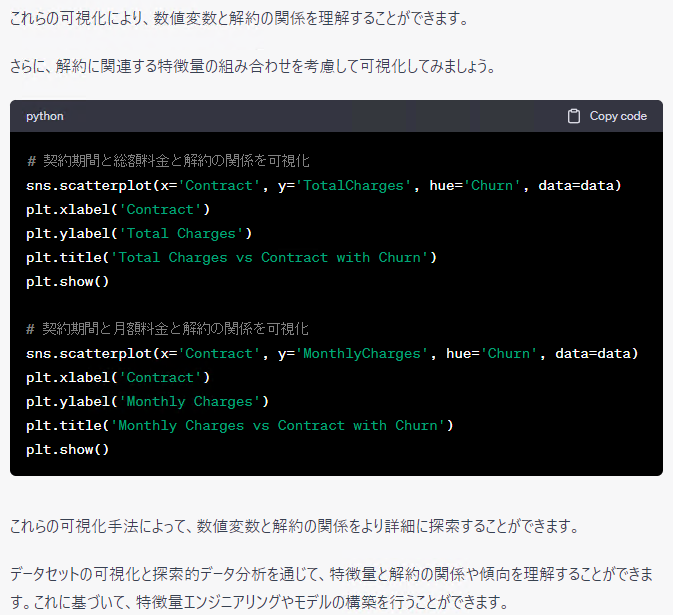
データを読み込み、データの一部を確認し、各変数の記述統計量(平均など)を出力し、各特徴量と解約の関係性の確認と、定石どおりです。
ただ、データ理解のためのデータ可視化や探索的データ分析としては、まだ不十分な気もします。
もう少し分析を続けて欲しいときは、どうすればいいでしょうか?
「続けてください。」とお願いし分析を続けよう!
もう少し分析を続けて欲しいときは……
……と依頼すると、分析を半ば強引に続けてくれます。
ただ、何度も「続けてください。」とお願いすると、途中から似たような分析を繰り返すようになったり、「追加情報をお願いします」という回答が返ってきますので、ほどほどにしましょう。
では実際に、ChatGPTに「続けてください。」とお願いしてみます。
以下、実行結果です。

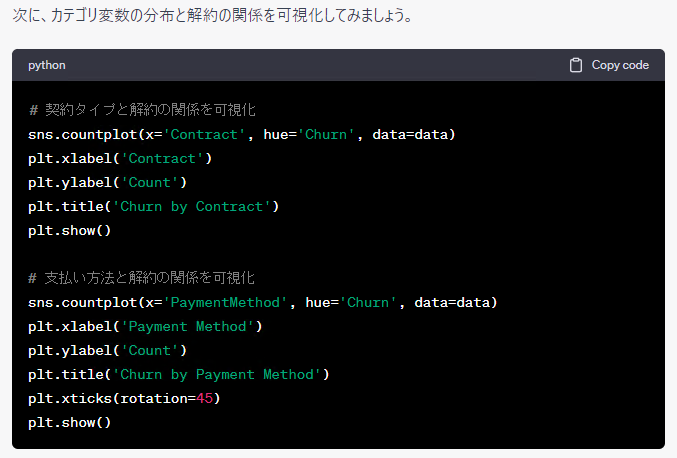
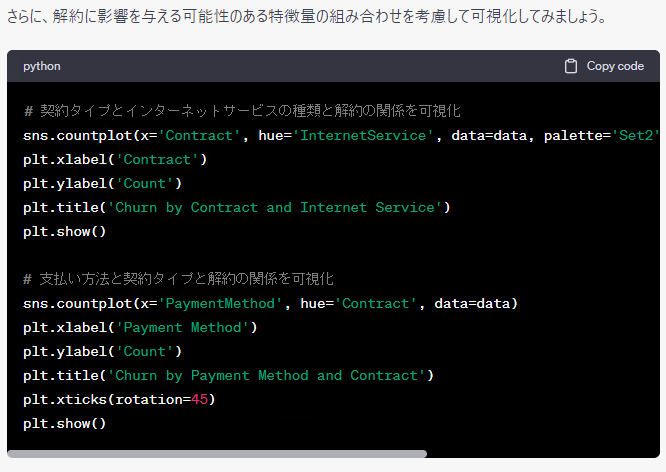

さらに、ChatGPTに「続けてください。」とお願いしてみます。
以下、実行結果です。

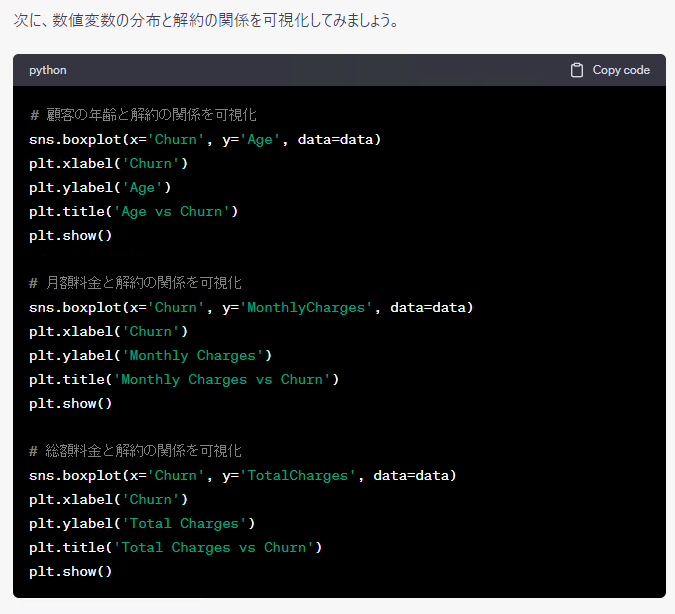
今回は、これぐらいで終了します。
例1のR版
Pythonではなく、Rでのコーディングをお願いしてみます。
例えば、次にように記載します。解約に関するデータセットです。
顧客の特徴と解約(churn)のデータセットを使います。
データ理解のために、データの可視化と探索的データ分析をして下さい。
- 【 1 】 :データセット ⇒ 顧客の特徴と解約(churn)
- 【 2 】 :追加事項 ⇒ なし
実際に、ChatGPTに聞いてみます。何度か「続けてください。」のお願いもします。
以下、実行結果です。
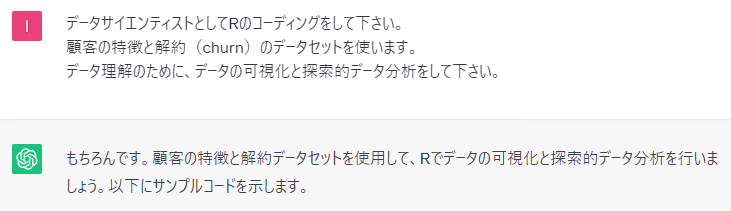
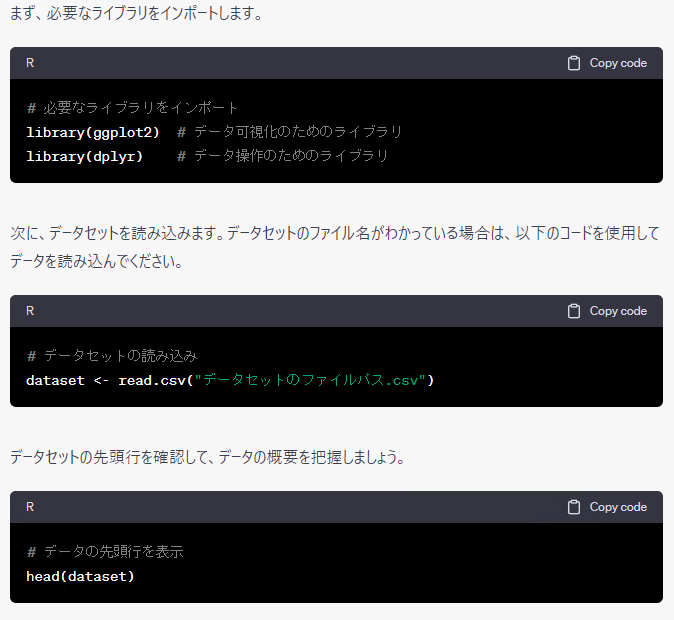
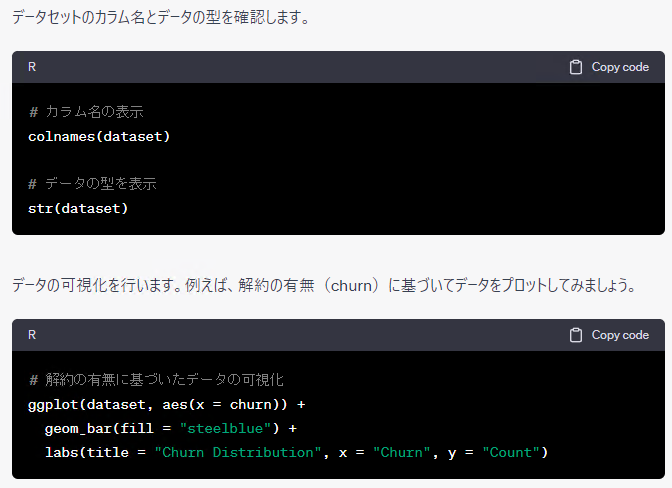
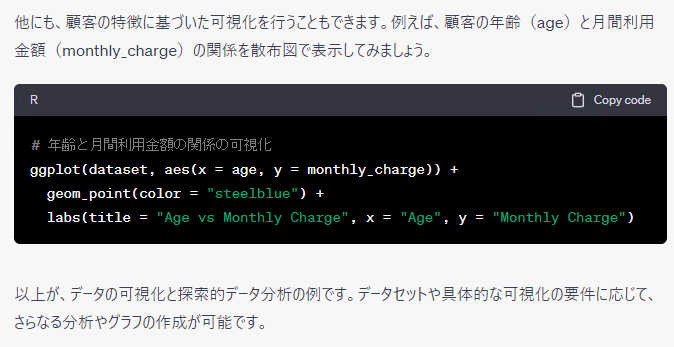

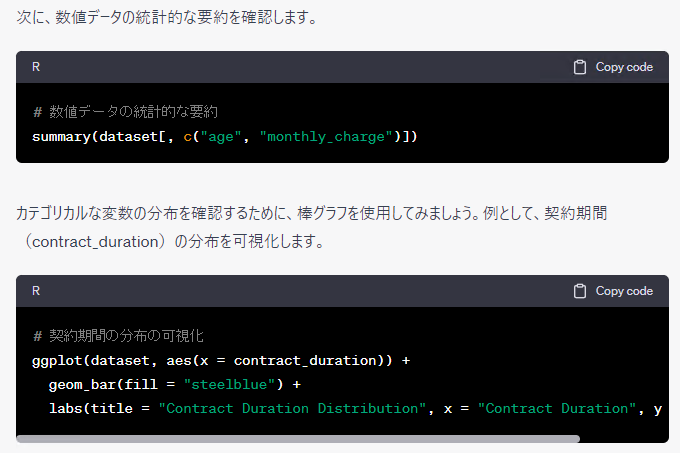


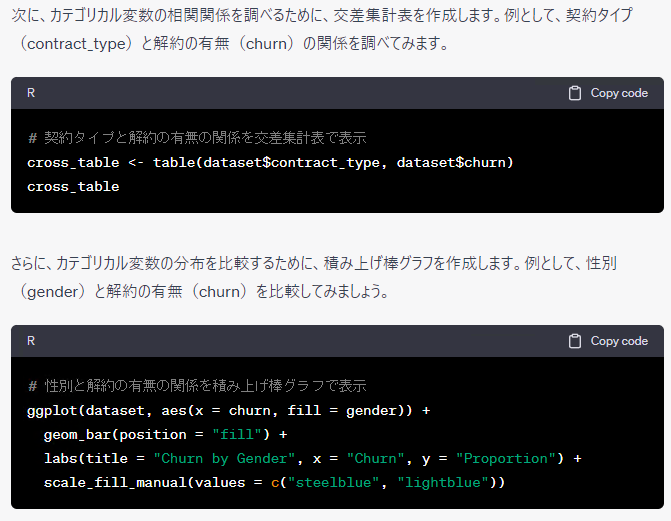

大まかにみるとRとPythonで同じようなことをしているようですが、細かくみると若干異なるようです。そもそも、ChatGPTに聞くたびに、微妙に分析の流れや出力されるコードなどが異なります。
例2:特徴量を指定しよう
先ほどのChatGPTのお願い文には、特徴量(説明変数)などはありませんでした。
そのため、架空のデータと架空の特徴量で、頑張ってコードを返してくれました。
ここでは、特徴量(説明変数)を指定(変数名と、量的なのか質的なのかの指定)してお願いしてみます。
顧客の特徴と解約(churn)のデータセットを使います。
データ理解のために、データの可視化と探索的データ分析をして下さい。
顧客の特徴を表す変数は以下です。
・量的変数:Age,Income,Amount of transaction
・質的変数:Gender,Education,Area of residence
- 【 1 】 :データセット ⇒ 顧客の特徴と解約(churn)
- 【 2 】 :追加事項 ⇒ 特徴量の変数名と、質的なのか量的なのかの指定
実際に、ChatGPTに聞いてみます。何度か「続けてください。」のお願いもします。
以下、実行結果です。
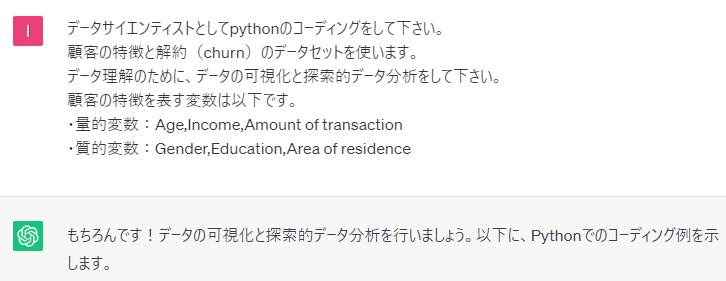

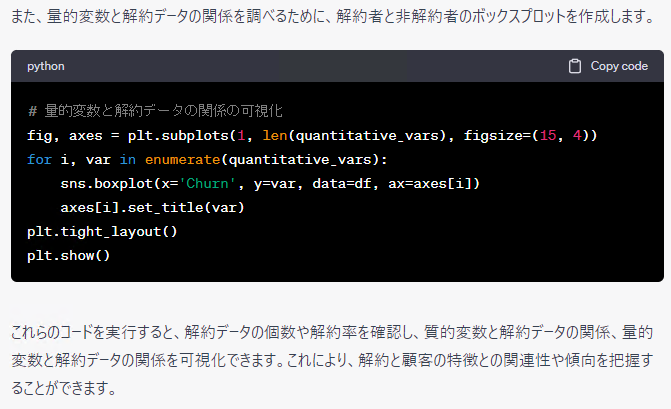

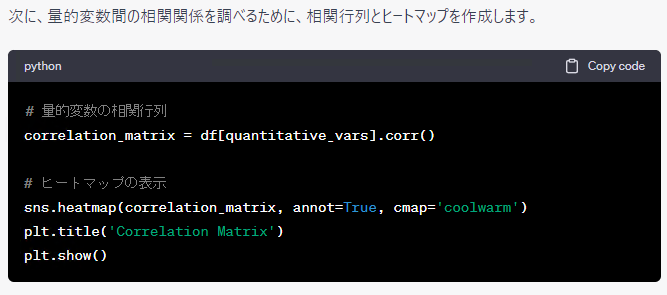
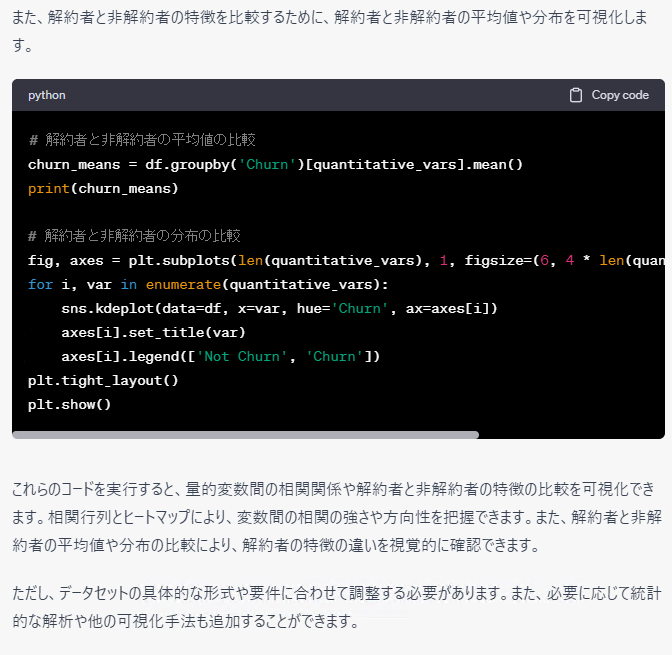

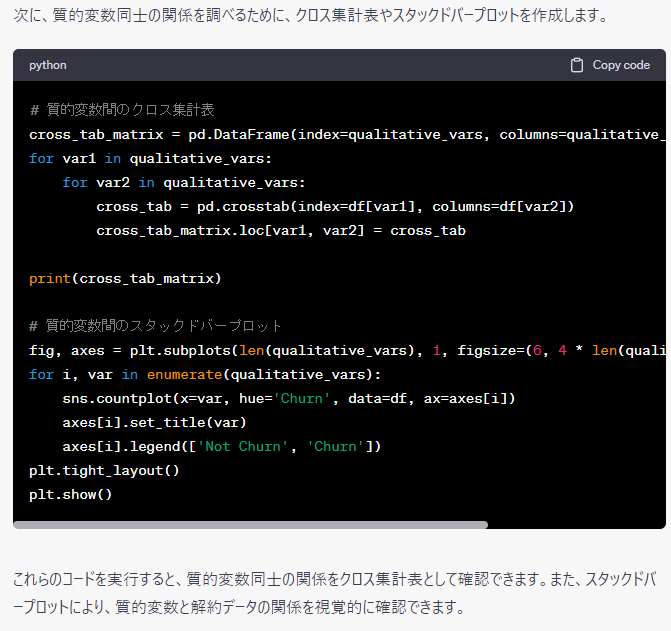
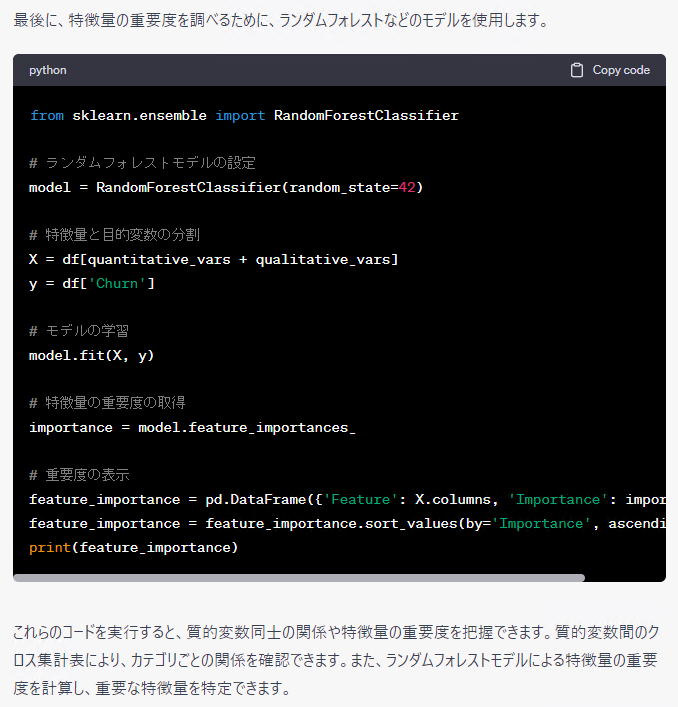
特徴量を具体的に明示した方が、イメージがつきやすいですね。しかも、そのまま使えますし……
今回の例の場合ですと、最後にランダムフォレストを利用した特徴量重要度まで出力しています。
例3:データ理解のためにして欲しいことをダイレクトにお願いしよう(今回は、特徴量重要度)
データ理解のためには、色々なデータ視覚化や探索的データ分析をする必要があります。
その中で、ダイレクトに1つ2つお願いするのもいいでしょう。
ということで、今回は解約にとって重要な特徴を探してもらいましょう。
「データ理解のために、データの可視化と探索的データ分析をして下さい。」を「最も重要な特徴を見つけて下さい。」に変えるだけです。
顧客の特徴と解約(churn)のデータセットを使います。
最も重要な特徴を見つけて下さい。
顧客の特徴を表す変数は以下です。
・量的変数:Age,Income,Amount of transaction
・質的変数:Gender,Education,Area of residence
実際に、ChatGPTに聞いてみます。
以下、実行結果です。

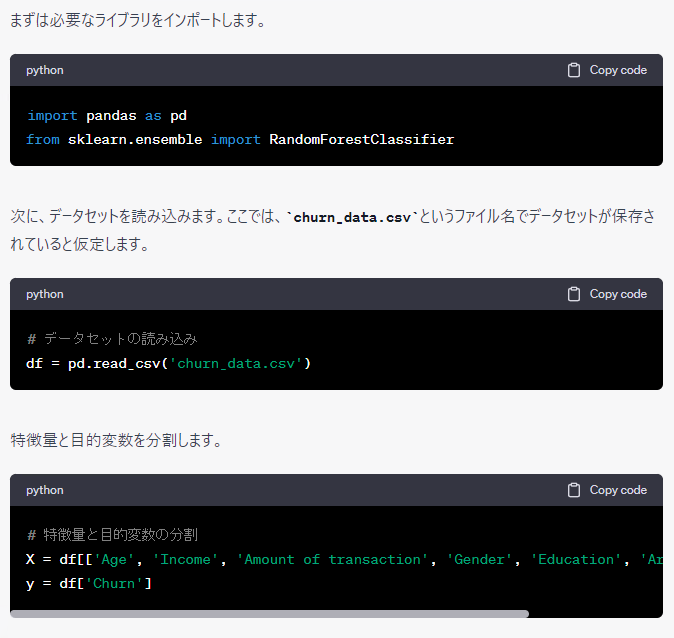
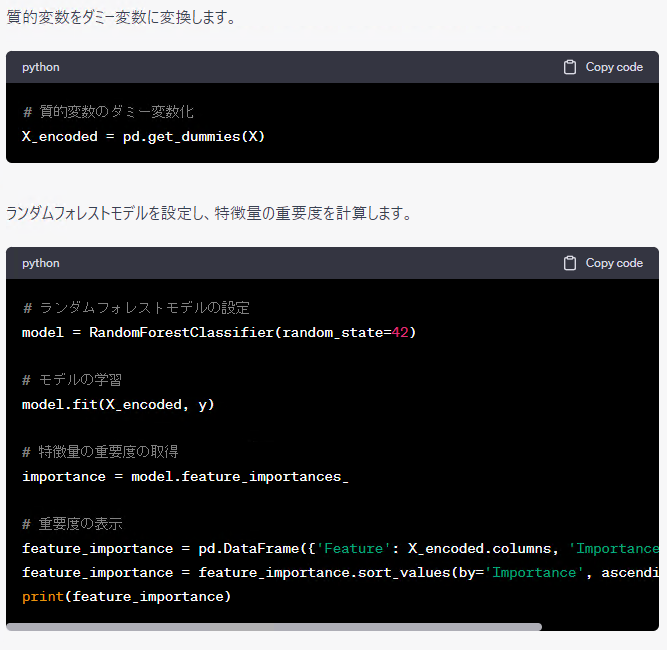
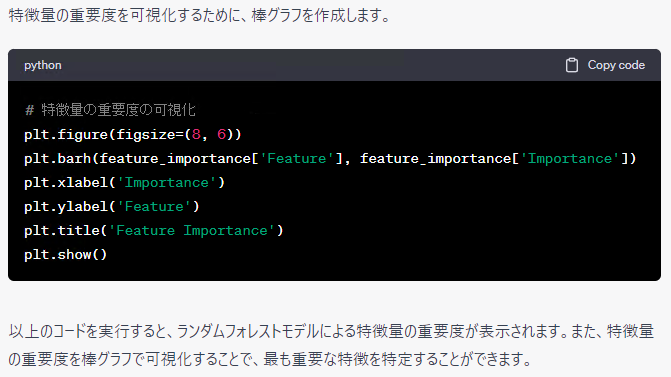
特徴量重要度はランダムフォレスト以外による方法もあるため、場合によっては別のアルゴリズムで実施される場合があります。このあたりは気まぐれです。
まとめ
今回は、今回はChatGPTが理解してくれる構文(データ分析の依頼文のフォーマット)を紹介しました。
最初に……
「データサイエンティストとしてpythonのコーディングをして下さい。」
……を入れると、ほぼ確実にコーディングしてくれます。
このセンテンスを入れなくても、コーディングしてくれることもあるのですが、そうでないときもあります。
- 前回:予測モデル
- 今回:データ理解のためのEDA
次回は、特徴量エンジニアリング系の構文を紹介します(機会があれば……)。
何はともあれ、興味のある方は試してみてください。