

データサイエンスやデータ分析の分野で、データの統合と結合は非常に重要なスキルです。
PandasはPythonの強力なデータ操作ライブラリであり、データの統合と結合を簡単かつ効率的に行うための多くの機能を提供しています。
今回は、Pandasを使ってデータを結合・統合する方法について、具体例を交えながら解説していきます。
複数のDataFrameの結合(merge, join)
データの分析や処理を行う際、複数のデータセットを統合する必要がよくあります。
Pandasでは、mergeメソッドとjoinメソッドを使って、簡単にデータフレームを結合することができます。
これらのメソッドの基本的な使い方を紹介し、内部結合、外部結合、左結合、右結合について説明します。
mergeメソッドの基本的な使い方
mergeメソッドは、データフレームを結合するための強力なツールです。
主にキー(結合するための共通の列)を使って、データフレーム同士を結合します。
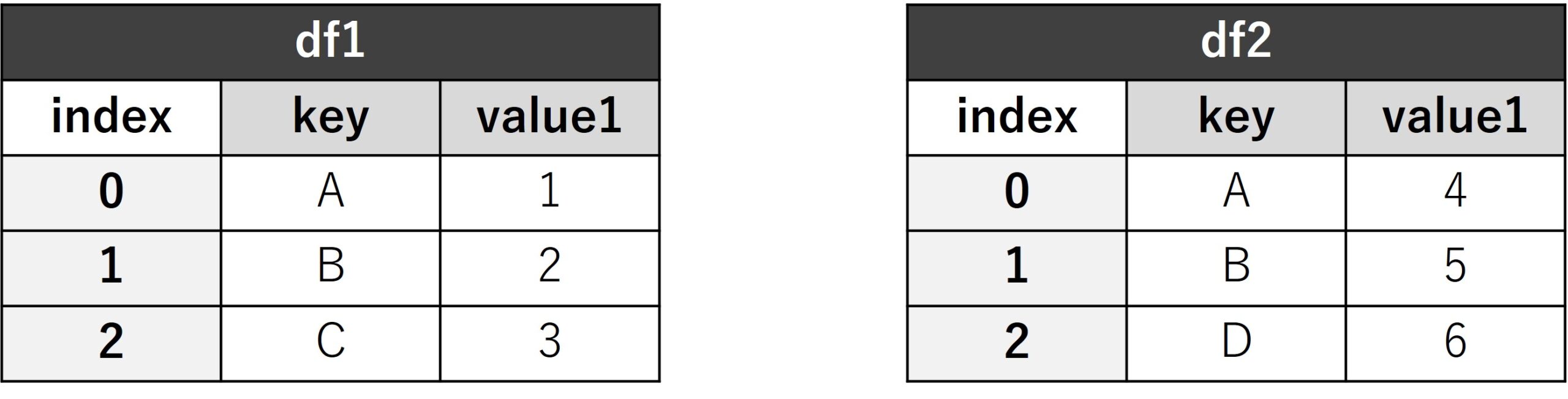
以下に、代表的な結合方法を説明します。
内部結合の説明と例
内部結合は、結合する両方のデータフレームに共通するキーの値に基づいて行われます。
共通するキーの値が存在しない行は除外されます。
以下、コードです。
import pandas as pd
# サンプルデータの作成
df1 = pd.DataFrame({'key': ['A', 'B', 'C'], 'value1': [1, 2, 3]})
df2 = pd.DataFrame({'key': ['A', 'B', 'D'], 'value2': [4, 5, 6]})
# 内部結合
result = pd.merge(df1, df2, on='key', how='inner')
print(result)
以下、実行結果です。
key value1 value2 0 A 1 4 1 B 2 5
キーがAとBの行だけが共通するため、これらの行のみが結合されました。
外部結合の説明と例
外部結合は、両方のデータフレームに存在するすべてのキーの値を保持します。
片方のデータフレームにのみ存在するキーの値に対しては、対応するデータが存在しない場合、NaNが挿入されます。
以下、コードです。
# 外部結合 result = pd.merge(df1, df2, on='key', how='outer') print(result)
以下、実行結果です。
key value1 value2 0 A 1.0 4.0 1 B 2.0 5.0 2 C 3.0 NaN 3 D NaN 6.0
すべてのキーA、B、C、Dが保持され、対応するデータがない場合はNaNが表示されます。
左結合の説明と例
左結合は、左側のデータフレームに存在するすべてのキーの値を保持します。
右側のデータフレームに存在しないキーの値に対しては、NaNが挿入されます。
以下、コードです。
# 左結合 result = pd.merge(df1, df2, on='key', how='left') print(result)
以下、実行結果です。
key value1 value2 0 A 1 4.0 1 B 2 5.0 2 C 3 NaN
左側のデータフレームdf1のキーA、B、Cが保持され、右側のデータフレームdf2に存在しないキーCに対してはNaNが表示されます。
右結合の説明と例
右結合は、右側のデータフレームに存在するすべてのキーの値を保持します。
左側のデータフレームに存在しないキーの値に対しては、NaNが挿入されます。
以下、コードです。
# 右結合 result = pd.merge(df1, df2, on='key', how='right') print(result)
以下、実行結果です。
key value1 value2 0 A 1.0 4 1 B 2.0 5 2 D NaN 6
右側のデータフレームdf2のキーA、B、Dが保持され、左側のデータフレームdf1に存在しないキーDに対してはNaNが表示されます。
joinメソッドの使い方とmergeとの違い
joinメソッドは、データフレームのインデックスを基に結合する場合に使われます。
mergeメソッドと異なり、joinはデフォルトでインデックスを使用して結合を行います。
まず、今まで利用していたサンプルデータのインデックスを変え、以下のようなデータセットにします。

以下、コードです。
# サンプルデータの作成
df1.set_index('key', inplace=True)
df2.set_index('key', inplace=True)
インデックスを利用し結合します。
以下、コードです。
# joinメソッドによる結合 result = df1.join(df2, how='inner') print(result)
以下、実行結果です。
value1 value2 key A 1 4 B 2 5
実践例: 複数のデータセットの統合
実際の業務では、複数のデータセットを統合することがよくあります。
例えば、顧客情報データ(customers)と購入履歴データ(orders)を統合するケースを考えてみましょう。
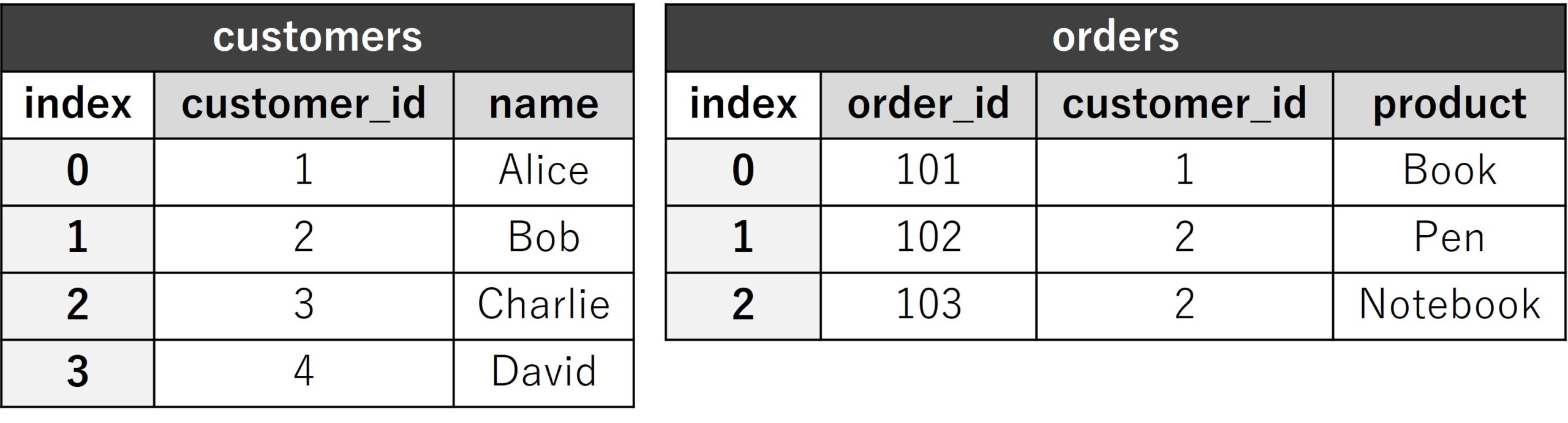
以下、コードです。
# サンプルデータの作成
customers = pd.DataFrame({
'customer_id': [1, 2, 3, 4],
'name': ['Alice', 'Bob', 'Charlie', 'David']
})
orders = pd.DataFrame({
'order_id': [101, 102, 103],
'customer_id': [1, 2, 2],
'product': ['Book', 'Pen', 'Notebook']
})
# 顧客情報と購入履歴の結合
result = pd.merge(customers, orders, on='customer_id', how='left')
print(result)
以下、実行結果です。
customer_id name order_id product 0 1 Alice 101.0 Book 1 2 Bob 102.0 Pen 2 2 Bob 103.0 Notebook 3 3 Charlie NaN NaN 4 4 David NaN NaN
顧客情報データと購入履歴データが統合され、各顧客の購入履歴が表示されます。
データの縦結合(concat)
データの縦結合は、複数のデータフレームを一つにまとめる際に非常に便利です。
Pandasでは、concatメソッドを使って簡単にデータを縦に結合することができます。
concatメソッドの基本的な使い方
concatメソッドは、複数のデータフレームを縦または横に結合するために使用されます。
特にデータの縦結合においては、データフレームをリストとして渡すことで、複数のデータフレームを一度に結合することができます。
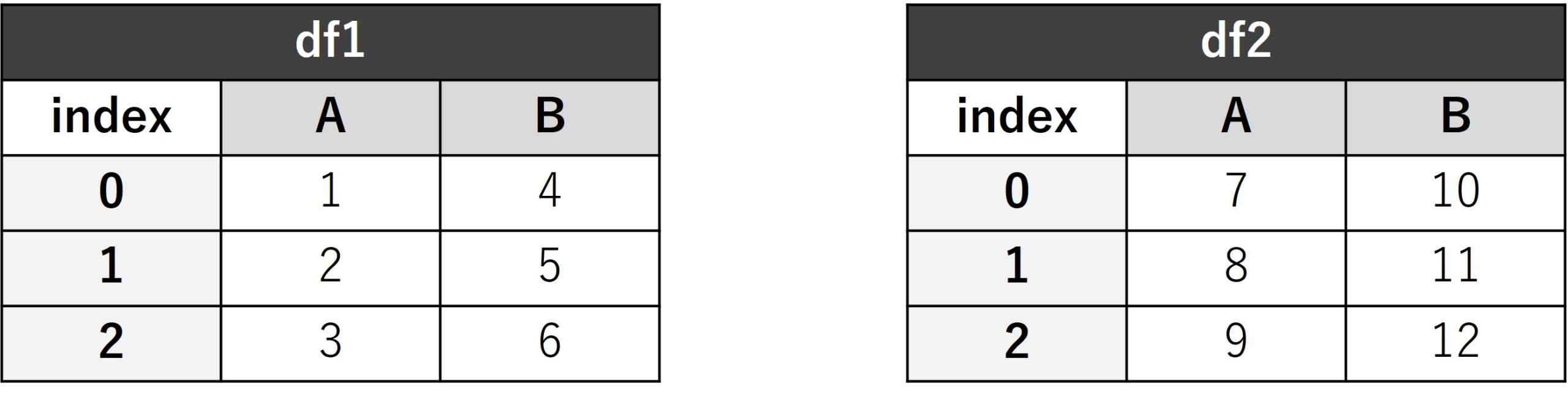
データフレームの縦結合
縦結合は、複数のデータフレームを縦方向に結合します。
以下、コードです。
import pandas as pd
# サンプルデータの作成
df1 = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
df2 = pd.DataFrame({'A': [7, 8, 9], 'B': [10, 11, 12]})
# 縦結合
result = pd.concat([df1, df2])
print(result)
以下、実行結果です。
A B 0 1 4 1 2 5 2 3 6 0 7 10 1 8 11 2 9 12
複数のデータフレームが縦に結合され、一つのデータフレームになっています。
データフレームの横結合
横結合は、複数のデータフレームを横方向に結合します。
以下、コードです。
# 横結合 result = pd.concat([df1, df2], axis=1) print(result)
以下、実行結果です。
A B A B 0 1 4 7 10 1 2 5 8 11 2 3 6 9 12
複数のデータフレームが横方向に結合され、新しい列が追加されます。
keysパラメータの利用例
concatメソッドのkeysパラメータを使用することで、結合されたデータフレームに階層的なインデックスを追加できます。
以下、コードです。
# keysパラメータの利用 result = pd.concat([df1, df2], keys=['df1', 'df2']) print(result)
以下、実行結果です。
A B
df1 0 1 4
1 2 5
2 3 6
df2 0 7 10
1 8 11
2 9 12
階層的なインデックスが追加され、どのデータフレームからのデータかが一目でわかります。
実践例: 複数年のデータの結合
実際のデータ分析では、複数年のデータを一つのデータフレームに結合するケースがよくあります。

以下、コードです。
# サンプルデータの作成
sales_2020 = pd.DataFrame({
'Month': ['Jan', 'Feb', 'Mar'],
'Sales': [200, 210, 215]
})
sales_2021 = pd.DataFrame({
'Month': ['Jan', 'Feb', 'Mar'],
'Sales': [220, 230, 250]
})
# 複数年のデータの結合
all_sales = pd.concat([sales_2020, sales_2021], keys=['2020', '2021'])
print(all_sales)
以下、実行結果です。
Month Sales
2020 0 Jan 200
1 Feb 210
2 Mar 215
2021 0 Jan 220
1 Feb 230
2 Mar 250
階層的なインデックスを利用することで、各年のデータを簡単に識別できます。
インデックスでデータを抽出するには、locまたはilocを使用します。
locはラベルベースのインデックスを使用し、ilocは位置ベースのインデックスを使用します。
例えば、all_salesデータフレームから2020年のデータを抽出するには、次のようにします。
以下、コードです。
sales_2020 = all_sales.loc['2020'] print(sales_2020)
以下、実行結果です。
Month Sales 0 Jan 200 1 Feb 210 2 Mar 215
2020年のデータの一部(2行目まで)を抽出するには、次のようにします。
以下、コードです。
sales_2020_subset = all_sales.loc['2020'].iloc[0:2] print(sales_2020_subset)
以下、実行結果です。
Month Sales 0 Jan 200 1 Feb 210
パフォーマンス最適化
データの結合や統合が効率的に行われることは、特に大規模データセットを扱う際に重要です。
大規模データセットの結合における課題、インデックスの活用によるパフォーマンス向上、メモリ使用量の最適化について解説します。
大規模データセットの結合における課題
大規模データセットを結合する際には、計算速度とメモリ使用量が問題となります。
結合操作が遅いと処理時間が長くなり、メモリ使用量が多すぎるとプログラムがクラッシュする可能性があります。
これらの問題を回避するために、いくつかの最適化技術を利用する必要があります。
インデックスの活用によるパフォーマンス向上
インデックスを利用することで、データフレームの結合操作を高速化できます。
インデックスを設定することで、Pandasはデータの検索を効率的に行うことができ、結合処理が速くなります。
以下は、インデックスありなしのコード例です。
import pandas as pd
import numpy as np
# 大規模データセットの作成
n = 10**6
df1 = pd.DataFrame({
'key': np.arange(n),
'value1': np.random.randn(n)
})
df2 = pd.DataFrame({
'key': np.arange(n),
'value2': np.random.randn(n)
})
# インデックスなしでの結合
merge_time = %timeit -o pd.merge(df1, df2, on='key')
# インデックスを設定して結合
df1.set_index('key', inplace=True)
df2.set_index('key', inplace=True)
join_time = %timeit -o df1.join(df2, how='inner')
merge_time, join_time
実行時間を計測したいコードの前に%timeit -oを付けることで、測定結果も出力します。
以下、実行結果です。
113 ms ± 1.32 ms per loop (mean ± std. dev. of 7 runs, 10 loops each) 3.73 ms ± 141 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
このように、インデックスを設定することで、Pandasはデータの検索を効率的に行うことができ、結合処理が速くなります。
この例では、インデックスを設定した結合操作の方が圧倒的に高速であることがわかります。
- インデックスなしでの結合: 約113ミリ秒
- インデックスを設定しての結合: 約3.73ミリ秒
メモリ使用量の最適化
メモリ使用量を最適化するためには、必要なデータのみをロードし、不要なデータを削除することが重要です。
また、データ型を適切に設定することで、メモリ使用量を削減できます。
以下、コード例です。
# 必要な列のみを読み込む
df = pd.read_csv('large_dataset.csv', usecols=['column1', 'column2'])
# データ型を適切に設定する
df['column1'] = df['column1'].astype('category')
df['column2'] = pd.to_numeric(df['column2'], downcast='float')
まとめ
今回は、Pandasを使ったデータの統合と結合の基本的な操作を説明しました。
具体的には、mergeとjoinメソッドを使ったデータフレームの結合、concatメソッドを使ったデータの縦結合、そしてデータのマージ時のパフォーマンス最適化について解説しました。
これらの技術を習得することで、データ分析やデータサイエンスのプロジェクトでのデータ処理がより効率的かつ効果的に行えるようになるでしょう。
次のステップとして、より高度なデータ操作やPandasの他の機能について学ぶことをお勧めします。
また、実際のプロジェクトでこれらの技術を適用することで、理解を深めることができます。