

機械学習モデルを本番環境で運用していると、ある日突然「予測精度が急落した」「思ったように結果が出ない」といった問題に直面することがあります。
これらの症状はしばしばデータドリフトと呼ばれる、訓練時と本番時におけるデータ分布のズレが原因です。
MLOps(機械学習オペレーション)の重要性が高まる現在、モデルの監視と品質保証は企業のAI活用において最重要課題の一つとなっています。
特に本番環境で継続的に稼働するモデルにとって、データドリフトの検知は安定したサービス提供の鍵となります。
今回は、データドリフトを定量的に検知するための定番指標であるPopulation Stability Index(PSI)を用いて、モデル運用中に起こる予測精度低下の原因を突き止める方法を簡単にお話しします。
Contents
- データドリフトがもたらす影響
- PSI(Population Stability Index)とは?
- PSI が必要になる理由をもう一度おさらい
- PSI 計算は「ビンづくり」から始まる
- 計算ステップの概要
- PSI の計算式
- PSI の判定基準
- 計算例(年齢を 4 ビンに分割)
- Python 実装例
- PSIの出力デモ
- 関数の定義
- サンプルデータ生成
- PSIの計算
- PSIの計算過程を出力するデモ
- 関数の定義
- loan_amount(申込額)
- credit_score(信用スコア)
- interest_rate(金利)
- PSI の限界と、併用したい補完指標について
- 特徴量同士の相関を捉えきれない
- サンプル数が少ないと信頼性が下がる
- ビン設定しだいで数値が変動する
- 今回のまとめ
データドリフトがもたらす影響
機械学習モデルの予測精度が劣化する原因は主に以下の2つに大別されます。
| ドリフトの種類 | 説明 | 例 |
|---|---|---|
| コンセプトドリフト | 予測対象そのものが変化し、モデルの仮定が崩れる。 | 顧客の購買行動が社内キャンペーンの影響で変わる。 |
| データドリフト | モデルの特徴量(説明変数)の分布が変化し、訓練時のパターンを踏襲できなくなる。 | センサーが新型に置き換わり出力分布が変わる。 |
簡単な例で説明します。
あるECサイトで「商品購入予測モデル」を運用していたとします。
このモデルは「過去30日間のサイト訪問回数」を重要な特徴量としていました。ところが、サイトのリニューアルによりユーザ行動が変化し、一回の訪問で複数ページを見るようになりました。
訪問回数の分布が変わったことでモデルの精度が急落したのです。これはデータドリフトの典型例です。
ここでは後者のデータドリフトにフォーカスし、説明変数の分布変化を定量的に把握する手法としてのPSIを紹介します。
PSI(Population Stability Index)とは?
機械学習モデルは、学習時に観測したデータ分布を前提に作られています。ところが、ビジネス環境やユーザー行動が変わると、データの性質も少しずつ(あるいは急激に)変化します。
こうした変化をいち早く検知しないと、モデルの精度は知らないうちに低下してしまいます。
Population Stability Index(PSI)は、「訓練データ」と「本番データ」それぞれの分布を比較し、どれだけズレたかを 1 つの数値で表す指標です。
もともとクレジットスコアリング領域で広く使われてきましたが、現在ではデータドリフト監視の汎用的なツールとして活躍しています。
PSI が必要になる理由をもう一度おさらい
モデルは学習時のデータ分布を前提に動きます。
しかし、サービスの利用者層が変わったり、業務フローが刷新されたりすると、入力データも予測対象も少しずつ姿を変えます。
その変化を放置すると、モデルは「過去の常識」で未来を判断し続けます。
PSI はそうした“静かな劣化”を数値で可視化する指標です。
PSI 計算は「ビンづくり」から始まる
まず、連続値を細かい“箱”に分ける ビニング が要となります。
ビンは「連続変数を離散区間に区切る箱」のことです。
年齢を 4 つに分けるなら、たとえば次のようになります。
| ビン名 | 区間 (歳) | ラベル例 |
|---|---|---|
| ビン1 | 0–20 | 学生層 |
| ビン2 | 21–40 | 若手社会人 |
| ビン3 | 41–60 | 中堅・シニア |
| ビン4 | 61+ | シニア・リタイア後 |
- 連続値以外(カテゴリ変数)でも、カテゴリーそのものをビンとして扱えます。
- 通常は等頻度ビニング(各ビンのサンプルを均等にする)か等幅ビニング(区間幅を同じにする)を採用します。
- 等頻度ビニングは外れ値の影響を抑えやすく、PSI で安定した検知がしやすい傾向があります。
ビンの区切り方で検知感度が大きく変わるため、以下のポイントを押さえておきましょう。
| チェックポイント | 注意点 |
|---|---|
| サンプル数のバランス | 各ビンに十分なサンプルが入らないと、比率がブレやすい。 |
| 分布形状へのフィット感 | 外れ値が多い場合は等頻度ビニングにすると極端な偏りを緩和できる。 |
| 業務解釈のしやすさ | たとえば年齢なら「~20 歳」「21–40 歳」のように業界で通じやすい区分を採用すると分析結果が会議で伝わりやすい。 |
上の 3 点を踏まえつつ、「10〜20 個」のビンで切ることが多いです。
ただ、多すぎても少なすぎても検知が甘くなるので、最初は 10 個前後で試しながら最適な粒度を探るのがいいでしょう。
計算ステップの概要
下表は「アルゴリズムそのもの」ではなく、「実務でどう手を動かすか」をイメージした手順です。
| ステップ | 何をするか | なぜ必要か |
|---|---|---|
| ① ビニング定義 | 訓練データでビン境界を決める | ビンは訓練時固定。運用後に境界を変えると過去比較ができなくなる |
| ② 比率計算(E) | 訓練データのビン比率 |
基準分布を保存しておくと再学習時も使い回せる |
| ③ 比率計算(A) | 本番データのビン比率 |
実測分布。バッチ処理なら日次、ストリームなら数分単位も可 |
| ④ 差分×対数 | 差が大→小でも、対数がマイナス補正で方向性を保持 | |
| ⑤ 合計 | 全ビンで加算し PSI を得る | 0 に近いほど分布差が小さく、閾値超えでアラートを発砲 |
PSI の計算式
以下、PSIの計算式です。
$$\mathrm{PSI} \;=\; \sum_{i=1}^{k} (A_i – E_i)\;\ln\!\Bigl(\displaystyle \tfrac{A_i}{E_i}\Bigr)$$
| 記号 | 説明 |
|---|---|
| 訓練データにおけるビン |
|
| 本番データにおけるビン |
|
| ビン数 | |
| 自然対数 |
式の中身を分解すると……
- 差の大きさ
:プラスなら本番で比率が増えた、マイナスなら減った。 - 対数比
:「増えた/減った方向」と「相対的な変化量」を同時に表現。 - 掛け合わせて合計:ビンごとの指標を足し合わせ、全体の分布差にまとめる。
この形は統計学でKL ダイバージェンス(相対エントロピー)とほぼ同じロジックです。
つまり「確率分布 P(訓練)」と「分布 Q(本番)」がどれだけ離れているかを測る一種の距離尺度と見ることができます。
PSI の判定基準
次は判定基準の表ですが、単に数字を覚えるのではなく「行動指針」までセットで理解することが大切です。
| PSI 値範囲 | 状態 | 具体的アクション例 |
|---|---|---|
| < 0.10 | データ分布は安定 | 通常運用を継続。定期チェックのみで OK。 |
| 0.10–0.25 | わずかなズレが発生(要注意) | モデル精度モニタリングを強化。必要に応じて追加特徴量の調査。 |
| ≥ 0.25 | データ分布が大きく変化(要対応) | モデルの再学習/特徴量設計の見直し。ビジネス要因のヒアリングも。 |
しきい値は業界やモデル特性で微調整が必要です。たとえば取引量が急増しやすい EC サイトでは、0.15 でも大きな影響が出る場合があります。
PSI だけで判断せず、モデルの精度指標(AUC や RMSE など)*や*ビジネス KPIも同時に確認すると、誤検知を抑えられます。
分布変化の原因を探るときは、どのビンが一番寄与したか(寄与度)を可視化すると調査がスムーズです。
計算例(年齢を 4 ビンに分割)
例えば、とある年齢データを4つのビンに分けたとします。
| ビン | 訓練データ比率(E) | 本番データ比率(A) | A-E | ln(A/E) | (A-E)×ln(A/E) |
|---|---|---|---|---|---|
| 0-20歳 | 0.3 | 0.2 | -0.1 | -0.405 | 0.0405 |
| 21-40歳 | 0.4 | 0.3 | -0.1 | -0.288 | 0.0288 |
| 41-60歳 | 0.2 | 0.4 | 0.2 | 0.693 | 0.1386 |
| 61歳以上 | 0.1 | 0.1 | 0.0 | 0.000 | 0.0000 |
$$PSI = 0.0405 + 0.0288 + 0.1386 + 0.0000 = 0.2079$$
この値は0.1≤PSI<0.25の範囲に入るため、「軽微なズレがある」と判断できます。
Python 実装例
PSIの出力デモ
関数の定義
以下のコードは、numpy と pandas のみでPSIをシンプルに計算する関数です。
import numpy as np
import pandas as pd
def calculate_psi(
expected: np.ndarray,
actual: np.ndarray,
bins: int = 10
) -> float:
"""
訓練データ(expected)と本番データ(actual)のPSIを計算する関数
:param expected: 訓練データの値配列
:param actual: 本番データの値配列
:param bins: ビン数(デフォルト10)
:return: PSI値 (float)
"""
# 訓練データのパーセンタイルでビン境界を算出
# ここでは等頻度ビンを使用(訓練データのサンプルが各ビンに均等に入るように)
breakpoints = np.linspace(0, 100, bins + 1)
thresholds = np.percentile(expected, breakpoints)
# 最後のビンの上限は最大値より大きくする(すべてのデータを含めるため)
thresholds[-1] = float('inf')
psi_value = 0.0
for i in range(bins):
# 各ビンごとのサンプル割合を計算
# 下限以上、上限未満の条件でデータをフィルタリングし、その比率を計算
e_pct = ((expected >= thresholds[i]) &
(expected < thresholds[i+1])).mean()
a_pct = ((actual >= thresholds[i]) &
(actual < thresholds[i+1])).mean()
# 0除算を避けるため、最小値を設定
e_pct = max(e_pct, 1e-6)
a_pct = max(a_pct, 1e-6)
# 差分 × 対数比 を加算
psi_value += (a_pct - e_pct) * np.log(a_pct / e_pct)
return psi_value
では、適当にサンプルデータを乱数を使い生成し、この関数を使ってみます。
サンプルデータ生成
まずは、サンプルデータの生成です。
- train_df:訓練データ(2019年の申込データ)
- prod_df:本番データ(2024年の申込データ)
変数は以下です。
- loan_amount: ローン申込額(万円)
- interest_rate: 金利(%)
- credit_score: 信用スコア(点)
以下、コードです。
# サンプルデータを生成(実行用)
np.random.seed(42) # 再現性のため乱数シードを固定
n_samples = 1000
# ===== 訓練データ(2019年の申込データと仮定)=====
# 1. loan_amount: ローン申込額(万円)
train_loan_amount = np.random.normal(300, 100, n_samples)
# 2. interest_rate: 金利(%)
train_interest_rate = np.random.normal(2.5, 0.5, n_samples)
# 3. credit_score: 信用スコア(点)
train_credit_score = np.random.normal(650, 50, n_samples)
# ===== 本番データ(2024年の申込データと仮定)- ドリフトを発生させる =====
# 1. loan_amount: 経済状況の変化で申込額が増加
prod_loan_amount = np.random.normal(400, 150, n_samples)
# 2. interest_rate: 金利はほぼ変化なし
prod_interest_rate = np.random.normal(2.6, 0.5, n_samples)
# 3. credit_score: やや変化
prod_credit_score = np.random.normal(620, 60, n_samples)
# データフレームに格納
train_df = pd.DataFrame({
'loan_amount': train_loan_amount,
'interest_rate': train_interest_rate,
'credit_score': train_credit_score
})
prod_df = pd.DataFrame({
'loan_amount': prod_loan_amount,
'interest_rate': prod_interest_rate,
'credit_score': prod_credit_score
})
どのようなデータなのか、視覚的に見ていきます。
以下、コードです。
import matplotlib.pyplot as plt
# グラフのサイズを設定
plt.figure(figsize=(10, 10))
# 各変数についてヒストグラムを描画
features = ['loan_amount', 'interest_rate', 'credit_score']
for i, feature in enumerate(features, 1):
plt.subplot(3, 1, i)
# 訓練データと本番データのヒストグラムを重ねて描画
plt.hist(
train_df[feature],
bins=30,
alpha=0.5,
label='Train (2019)',
density=True
)
plt.hist(
prod_df[feature],
bins=30,
alpha=0.5,
label='Production (2024)',
density=True
)
# グラフの設定
plt.title(f'Distribution of {feature}')
plt.xlabel(feature)
plt.ylabel('Density')
plt.legend()
# グラフ全体の調整
plt.tight_layout()
plt.show()
# 基本統計量を横に並べて表示
print("\n===== 基本統計量の比較 =====")
pd.set_option('display.float_format', lambda x: '%.3f' % x)
for feature in features:
print(f"\n{feature}の統計量:")
# 訓練データと本番データの統計量を横に並べて表示
stats_comparison = pd.DataFrame({
'訓練データ (2019)': train_df[feature].describe(),
'本番データ (2024)': prod_df[feature].describe()
})
print(stats_comparison)
以下、実行結果です。
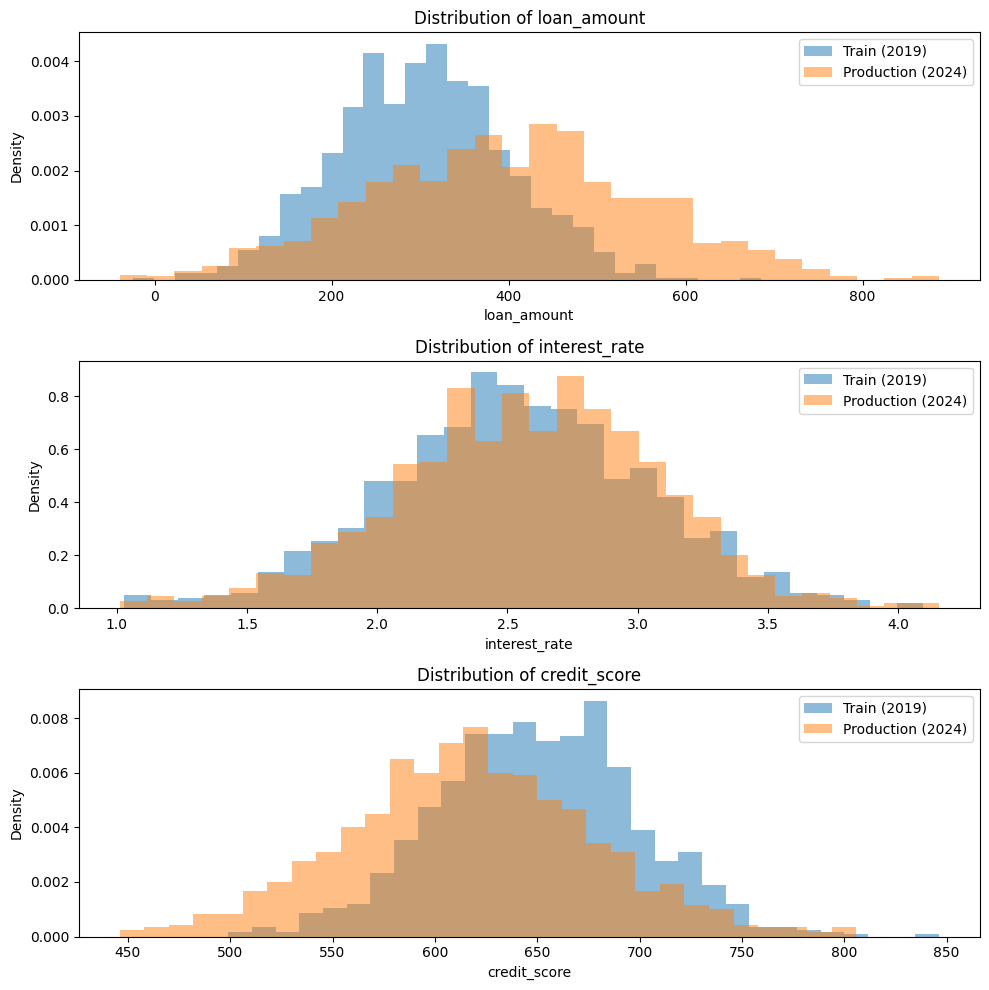
===== 基本統計量の比較 =====
loan_amountの統計量:
訓練データ (2019) 本番データ (2024)
count 1000.000 1000.000
mean 301.933 397.192
std 97.922 154.070
min -24.127 -39.417
25% 235.241 289.387
50% 302.530 400.028
75% 364.794 500.042
max 685.273 886.464
interest_rateの統計量:
訓練データ (2019) 本番データ (2024)
count 1000.000 1000.000
mean 2.535 2.575
std 0.499 0.496
min 1.030 1.012
25% 2.197 2.259
50% 2.532 2.591
75% 2.864 2.920
max 4.097 4.156
credit_scoreの統計量:
訓練データ (2019) 本番データ (2024)
count 1000.000 1000.000
mean 650.292 617.196
std 49.173 60.443
min 499.024 446.029
25% 617.600 578.378
50% 649.987 617.430
75% 683.046 656.747
max 846.312 805.898
PSIの計算
次に、先ほど定義した関数を使い、PSIを計算します。
以下、コードです。
# 各特徴量のPSIを計算
features = ['loan_amount', 'interest_rate', 'credit_score']
results = {}
print("=== PSI計算結果 ===")
for feat in features:
psi_val = calculate_psi(
train_df[feat].values,
prod_df[feat].values,
bins=10
)
results[feat] = psi_val
print(f"{feat} の PSI: {psi_val:.4f}")
以下、実行結果です。
=== PSI計算結果 === loan_amount の PSI: 0.6909 interest_rate の PSI: 0.0206 credit_score の PSI: 0.3500
この結果を解釈すると、次のようになります。
| 特徴量 | PSI値 | 分布変化レベル | 主な要因例 | 推奨対応 |
|---|---|---|---|---|
| loan_amount(ローン申込額) | 0.6909 | 重大(PSI > 0.25) | インフレーション、不動産価格高騰 | 即時のモデル再学習・パラメータ見直し |
| interest_rate(金利) | 0.0206 | 安定(PSI < 0.1) | ほぼ変化なし | 現状維持 |
| credit_score(信用スコア) | 0.3500 | 重大(PSI > 0.25) | 新規顧客層の参入、信用ポリシー変更 | モデルの再調整または再学習を検討 |
PSI で判明した「ズレの大きさ」に応じて、まず どの特徴量にどの順で手を打つか を整理し、その後 横串となる運用ルール を具体策としてまとめました。
| 対応カテゴリ | 対象特徴量 | PSI値 | 優先度 & 主な対応 |
|---|---|---|---|
| 最優先対応 | loan_amount(申込額) | 0.6909 | – PSI > 0.25 を大きく超過し 重大なドリフト – 即時再学習 と特徴量エンジニアリングの再設計 |
| 要フォローアップ | credit_score(信用スコア) | 0.3500 | – PSI > 0.25 で 大きな変化 – 再学習計画とパラメータ調整を早急に検討 |
| 現状維持 | interest_rate(金利) | 0.0206 | – PSI < 0.1 で ほぼ変化なし – 当面はモデル・システム変更不要 |
上表から読み取れるように、ローン申込額は例えばインフレや不動産価格高騰の影響で旧モデルが追いつけないレベルのズレが発生しています。
信用スコアも顧客層の変化が疑われ、早期の再学習が望まれます。一方、金利は安定しているため定例モニタリングのみで十分です。
PSIの計算過程を出力するデモ
ここで、状況をより正確に掴むために、各ビンの途中計算とPSI貢献度を出力します。
関数の定義
以下、コードです。
def calculate_psi_with_details(
expected: np.ndarray,
actual: np.ndarray,
bins: int = 10
) -> pd.DataFrame:
"""
PSIの計算過程を詳細に出力する関数
"""
# 訓練データのパーセンタイルでビン境界を算出
breakpoints = np.linspace(0, 100, bins + 1)
thresholds = np.percentile(expected, breakpoints)
thresholds[-1] = float('inf')
# 結果を格納するリスト
results = []
for i in range(bins):
# 各ビンの範囲
bin_range = f"{thresholds[i]:.1f}-{thresholds[i+1]:.1f}"
# 各ビンごとのサンプル割合を計算
e_pct = ((expected >= thresholds[i]) &
(expected < thresholds[i+1])).mean()
a_pct = ((actual >= thresholds[i]) &
(actual < thresholds[i+1])).mean()
# 0除算を避けるため、最小値を設定
e_pct = max(e_pct, 1e-6)
a_pct = max(a_pct, 1e-6)
# 差分と対数比を計算
diff = a_pct - e_pct
log_ratio = np.log(a_pct / e_pct)
psi_contribution = diff * log_ratio
results.append({
'ビン': f'ビン{i+1}',
'範囲': bin_range,
'訓練データ比率': e_pct,
'本番データ比率': a_pct,
'差分(A-E)': diff,
'ln(A/E)': log_ratio,
'PSI貢献度': psi_contribution
})
# DataFrameに変換
df_results = pd.DataFrame(results)
# 小数点以下の表示形式を設定
format_dict = {
'訓練データ比率': '{:.4f}',
'本番データ比率': '{:.4f}',
'差分(A-E)': '{:.4f}',
'ln(A/E)': '{:.4f}',
'PSI貢献度': '{:.4f}'
}
return df_results.style.format(format_dict)
loan_amount(申込額)
まずは、loan_amount(申込額)について見てみます。
以下、コードです。
loan_amount_pd = calculate_psi_with_details(
train_df['loan_amount'].values,
prod_df['loan_amount'].values,
bins=10
)
loan_amount_pd
以下、実行結果です。
| ビン | 範囲 | 訓練データ比率 | 本番データ比率 | 差分(A-E) | ln(A/E) | PSI貢献度 |
|---|---|---|---|---|---|---|
| ビン1 | -24.1-175.5 | 0.1000 | 0.0740 | -0.0260 | -0.3011 | 0.0078 |
| ビン2 | 175.5-219.7 | 0.1000 | 0.0510 | -0.0490 | -0.6733 | 0.0330 |
| ビン3 | 219.7-247.7 | 0.1000 | 0.0430 | -0.0570 | -0.8440 | 0.0481 |
| ビン4 | 247.7-275.9 | 0.1000 | 0.0540 | -0.0460 | -0.6162 | 0.0283 |
| ビン5 | 275.9-302.5 | 0.1000 | 0.0520 | -0.0480 | -0.6539 | 0.0314 |
| ビン6 | 302.5-324.9 | 0.1000 | 0.0470 | -0.0530 | -0.7550 | 0.0400 |
| ビン7 | 324.9-351.4 | 0.1000 | 0.0660 | -0.0340 | -0.4155 | 0.0141 |
| ビン8 | 351.4-381.4 | 0.1000 | 0.0630 | -0.0370 | -0.4620 | 0.0171 |
| ビン9 | 381.4-430.6 | 0.1000 | 0.1240 | 0.0240 | 0.2151 | 0.0052 |
| ビン10 | 430.6-inf | 0.1000 | 0.4230 | 0.3230 | 1.4422 | 0.4658 |
今回の分析から、ローン申込額( loan_amount )の分布が 2019 年の訓練データと 2024 年の本番データのあいだで劇的に変化していることが明らかになりました。
訓練データでは、申込額を 10 等分した各ビンに顧客がほぼ均等(10 %)に分布していましたが、本番データでは高額帯への集中が際立っています。
とりわけ 430.6 万円超(ビン 10)の比率が 10 % から 42.3 % へと 32.3 ポイント跳ね上がり、一方で低〜中額帯(ビン 1〜8)は軒並みシェアを落としました。象徴的なのが 219.7–247.7 万円(ビン 3)の層で、5.7 ポイントの大幅減です。
こうした偏りは PSI(Population Stability Index)にも如実に表れており、総 PSI 0.6909 のうち約 0.466 がビン 10 だけで説明されます。
中低額帯の複数ビンも 0.028〜0.048 程度ずつ寄与しており、分布全体が高額側にスライドした構図です。
PSI が 0.2 を大きく上回る 0.6909 という値は、一般的な閾値を超える深刻なデータドリフトを示唆します。
例えば、背景にはインフレーションや不動産価格上昇などマクロ経済の変動が影響していると考えられ、現行モデルの再学習や特徴量の抜本的な見直しが急務と言えるでしょう。
credit_score(信用スコア)
次に、credit_score(信用スコア)について見てみます。
以下、コードです。
credit_score_pd = calculate_psi_with_details(
train_df['credit_score'].values,
prod_df['credit_score'].values,
bins=10
)
credit_score_pd
以下、実行結果です。
| ビン | 範囲 | 訓練データ比率 | 本番データ比率 | 差分(A-E) | ln(A/E) | PSI貢献度 |
|---|---|---|---|---|---|---|
| ビン1 | 499.0-588.0 | 0.1000 | 0.2870 | 0.1870 | 1.0543 | 0.1972 |
| ビン2 | 588.0-608.4 | 0.1000 | 0.1270 | 0.0270 | 0.2390 | 0.0065 |
| ビン3 | 608.4-624.1 | 0.1000 | 0.1170 | 0.0170 | 0.1570 | 0.0027 |
| ビン4 | 624.1-637.4 | 0.1000 | 0.0850 | -0.0150 | -0.1625 | 0.0024 |
| ビン5 | 637.4-650.0 | 0.1000 | 0.0770 | -0.0230 | -0.2614 | 0.0060 |
| ビン6 | 650.0-663.4 | 0.1000 | 0.0670 | -0.0330 | -0.4005 | 0.0132 |
| ビン7 | 663.4-675.8 | 0.1000 | 0.0530 | -0.0470 | -0.6349 | 0.0298 |
| ビン8 | 675.8-690.9 | 0.1000 | 0.0510 | -0.0490 | -0.6733 | 0.0330 |
| ビン9 | 690.9-712.2 | 0.1000 | 0.0440 | -0.0560 | -0.8210 | 0.0460 |
| ビン10 | 712.2-inf | 0.1000 | 0.0670 | -0.0330 | -0.4005 | 0.0132 |
信用スコア(credit_score)の PSI 分析から、2019 年と 2024 年で顧客のスコア分布が大きく様変わりしていることがわかりました。
まず訓練データでは、スコアを 10 等分した各ビンに顧客が均等(10 %)に分布していましたが、本番データでは低スコア側へ極端に偏っています。
とりわけ 499–588 点のもっとも低い層(ビン 1)が 10 % から 28.7 % へと 18.7 ポイント増え、このビンだけで総 PSI 0.3500 の半分以上(0.1972)を押し上げました。
分布をもう少し細かく見ると、低スコア帯(ビン 1–3)は比率が 12–28 % に上昇する一方、中スコア帯(ビン 4–6)は 6–8 % に縮小し、700 点超の高スコア帯(ビン 7–10)は 4–6 % にまで落ち込んでいます。
PSI への寄与も低スコア層が突出しており、高スコアでもわずかに(ビン 8–9 で 0.033–0.046 程度)押し上げが見られるものの、全体として「信用力の低下」が支配的なトレンドです。
PSI が 0.2 を超える 0.3500 という値は、統計的に見て重要なドリフトが起きていることを示唆します。
例えば、背景には景気悪化や新たな顧客層の流入などが考えられ、現行の信用リスク評価モデルは低スコア層の急増に対応できていない可能性が高いといえます。
したがって、モデルの再調整や再学習を早急に検討し、スコア分布の最新トレンドを反映させる必要があります。
interest_rate(金利)
最後に、interest_rate(金利)について見てみます。
以下、コードです。
interest_rate_pd = calculate_psi_with_details(
train_df['interest_rate'].values,
prod_df['interest_rate'].values,
bins=10
)
interest_rate_pd
以下、実行結果です。
| ビン | 範囲 | 訓練データ比率 | 本番データ比率 | 差分(A-E) | ln(A/E) | PSI貢献度 |
|---|---|---|---|---|---|---|
| ビン1 | 1.0-1.9 | 0.1000 | 0.0870 | -0.0130 | -0.1393 | 0.0018 |
| ビン2 | 1.9-2.1 | 0.1000 | 0.0950 | -0.0050 | -0.0513 | 0.0003 |
| ビン3 | 2.1-2.3 | 0.1000 | 0.0840 | -0.0160 | -0.1744 | 0.0028 |
| ビン4 | 2.3-2.4 | 0.1000 | 0.1000 | 0.0000 | 0.0000 | 0.0000 |
| ビン5 | 2.4-2.5 | 0.1000 | 0.0800 | -0.0200 | -0.2231 | 0.0045 |
| ビン6 | 2.5-2.7 | 0.1000 | 0.1020 | 0.0020 | 0.0198 | 0.0000 |
| ビン7 | 2.7-2.8 | 0.1000 | 0.1000 | 0.0000 | 0.0000 | 0.0000 |
| ビン8 | 2.8-3.0 | 0.1000 | 0.1340 | 0.0340 | 0.2927 | 0.0100 |
| ビン9 | 3.0-3.2 | 0.1000 | 0.1070 | 0.0070 | 0.0677 | 0.0005 |
| ビン10 | 3.2-inf | 0.1000 | 0.1090 | 0.0090 | 0.0862 | 0.0008 |
訓練データ(2019 年)は各ビンに 10 % ずつ顧客が均等に入るよう設計されていましたが、2024 年の本番データを見ると、わずかながら中~高レンジ側へシフトしています。
具体的には、2.8–3.0(ビン 8) の比率が 10 % から 13.4 %(+3.4 pt) に増え、PSI への寄与も 0.0100 と表中で最大です。
一方、1.0–1.9(ビン 1) や 2.1–2.3(ビン 3) の低~中レンジはそれぞれ −1.3 pt、−1.6 pt 減少し、PSI に小さなプラスを与えています。
中間帯では 2.4–2.5(ビン 5) が −2.0 pt とやや減り、PSI へ 0.0045 のプラス寄与。逆に 2.5–2.7(ビン 6) は +0.2 pt でほぼ横ばいです。
最も高い 3.2 超(ビン 10) も +0.9 pt と微増ですが、PSI への影響は 0.0008 にとどまります。
これら個別ビンの寄与をすべて合計しても 総 PSI は 0.021 前後 にしかならず、一般的な警戒ライン(0.10)を大きく下回ります。
従って、今回のシフトは統計的には軽微であり、モデル再学習の必要性は現時点では低いと判断できます。
ただし、ビン 8 への偏りが続くようなら、今後のモニタリング強化が望ましいでしょう。
PSI の限界と、併用したい補完指標について
PSI はデータドリフトを素早く定量化できる優れた指標ですが、運用時には留意点があります。
特徴量同士の相関を捉えきれない
PSI は各特徴量を独立にビン分割し、その分布差を比較する仕組みです。
したがって「複数の変数が同時にわずかずつ変動し、結果として大きな影響を及ぼす」といった複合的ドリフトには鈍感です。
対策例として、マハラノビス距離や KL ダイバージェンスなど、多変量の分布差を測る指標を併用し、相関構造の変化もモニタリングする方法があります。
サンプル数が少ないと信頼性が下がる
PSI はビンごとに「比率 × 対数比」を計算しますが、母数が 100 件を大きく下回るような状況では各ビンのサンプルがほとんど入らず、数値が不安定になりがちです。
対策例として、サンプルが十分に蓄積するまで結果を参考程度にとどめるか、ウォーターフォール方式で期間を束ねてサンプル数を確保する方法があります。
ビン設定しだいで数値が変動する
ビン数や等幅・等頻度といった分割法の選択により、PSI の値は少なからず変動します。
極端な例では、ビン数を増やすと本質でない“細かな揺らぎ”にも過敏になることがあります。
対策例として、複数のビン設定でテストし、結果が大きくブレないかを確認する/重要変数だけは固定ビン境界を設定し、比較を一貫させる方法があります。
今回のまとめ
PSIは、訓練データと本番データの分布差を一数値で可視化できる手軽なドリフト監視指標です。
0.10・0.25という目安を越えたら、影響の大きい特徴量を優先的に再学習・再設計し、モデル精度指標や多変量指標と併用してモニタリング頻度も強化することで、運用モデルの劣化を最小限に抑えられます。