
データサイエンスの世界では、「データがどんな形で散らばっているか」 を理解することがとても重要です。
テストの点数は平均点付近に多くの人が集まり、極端に高い点数や低い点数の人は少なくなります。
人の身長も平均値の前後に多く集まり、極端に高い人や低い人はまれです。
こうした 「データの散らばり方のパターン」 を数学的に表したものが 確率分布(かくりつぶんぷ) です。
今回は、確率分布の中でも最も重要な 正規分布 について、SciPyでの扱い方を簡単に解説します。
Contents
確率分布とは?
ひとことで言うと
確率分布 とは、ある値がどれくらいの確率で出現するかを表した「データの散らばり方のルール」 のことです。
たとえば、サイコロを振ったとき、1〜6のどの目も同じ確率(約16.7%)で出ます。
これは 一様分布 という確率分布です。
一方、テストの点数は平均点付近に集中し、左右対称に広がる傾向があります。
これは 正規分布 という確率分布に従います。
確率分布を知っていると、以下のようなことができるようになります。
- データの特徴を理解する → 「このデータは正規分布に近いから、平均値で代表できそうだ」
- 確率を計算する → 「テストで90点以上を取る確率は何%か?」
- シミュレーションを行う → 「来月の売上をランダムにシミュレーションしてみよう」
確率分布を扱うための3つの基本概念
SciPyで確率分布を操作するとき、3つの重要な概念があります。
① PDF(確率密度関数)
PDF(Probability Density Function) は、連続データにおいて、各値がどれくらい出やすいかを表す曲線です。
PDFの曲線が高いところほど、そのあたりの値が出やすいことを意味します。
正規分布のPDFは、おなじみの「釣り鐘型」の曲線です。
② PMF(確率質量関数)
PMF(Probability Mass Function) は、離散データ(整数値など)において、各値が出る確率そのものを表します。
ポアソン分布のように「0回、1回、2回…」と整数でカウントするデータに使います。
③ CDF(累積分布関数)
CDF(Cumulative Distribution Function) は、ある値以下になる確率の合計を表す関数です。
たとえば「テストで80点以下になる確率は何%か?」を求めるときに使います。
PDF/PMF/CDFを視覚的に確認
以下のコードで、PDF・PMF・CDFのイメージをグラフで確認してみましょう。
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
from scipy import stats
# 3つのサブプロット
fig, axes = plt.subplots(3, 1, figsize=(8, 10))
# -----------------------------
# ① PDF(正規分布の例)
# -----------------------------
# 連続値のx範囲を用意
x_cont = np.linspace(-4, 4, 300)
# 正規分布のPDFを線で描画
axes[0].plot(
x_cont, # x軸の値
stats.norm.pdf(x_cont), # y軸(PDFの値)
color='blue', # 線色
linewidth=2 # 太さ
)
# 曲線の下を薄く塗って見やすくする
axes[0].fill_between(
x_cont, # x軸の値
stats.norm.pdf(x_cont), # y軸(PDFの値)
alpha=0.2, # 透明度
color='blue' # 塗りつぶし色
)
axes[0].set_title('PDF(確率密度関数)\n連続データの出やすさ')
axes[0].set_xlabel('値')
axes[0].set_ylabel('密度')
axes[0].grid(True, alpha=0.3)
# -----------------------------
# ② PMF(ポアソン分布の例)
# -----------------------------
# 離散値のとりうる範囲(0〜14)
k = np.arange(0, 15)
# ポアソン分布(平均5)のPMFを棒グラフで描画
axes[1].bar(
k, # x軸の値
stats.poisson.pmf(k, mu=5), # y軸(PMFの値)
width=0.8, # 棒の幅
color='green', # 棒の色
alpha=0.7, # 透明度
edgecolor='black' # 棒の縁取り
)
axes[1].set_title('PMF(確率質量関数)\n離散データの出る確率')
axes[1].set_xlabel('値(回数など)')
axes[1].set_ylabel('確率')
axes[1].grid(True, alpha=0.3)
# -----------------------------
# ③ CDF(正規分布の例)
# -----------------------------
# 正規分布のCDFを線で描画
axes[2].plot(
x_cont, # x軸の値
stats.norm.cdf(x_cont), # y軸(CDFの値)
color='red', # 線色
linewidth=2 # 太さ
)
axes[2].set_title('CDF(累積分布関数)\nある値以下の確率の合計')
axes[2].set_xlabel('値')
axes[2].set_ylabel('累積確率')
axes[2].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
以下、実行結果です。
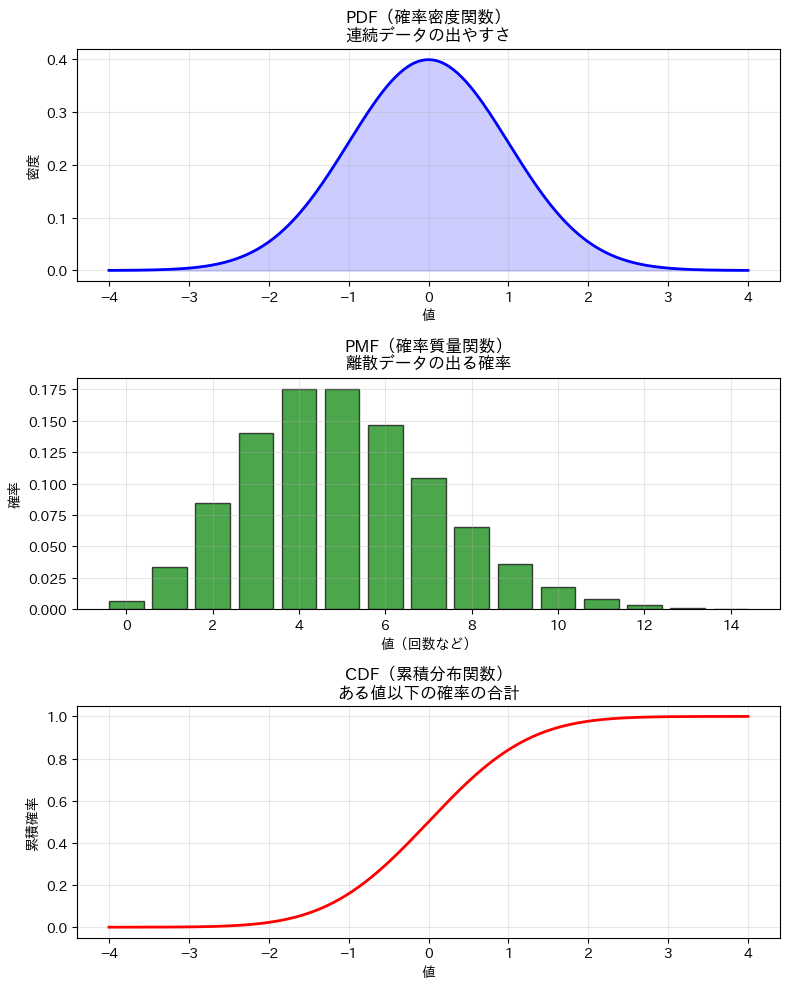
正規分布(Normal Distribution)
正規分布とは?
正規分布 は、統計学で最も重要な確率分布です。
平均値を中心に左右対称の釣り鐘型に広がる分布で、「ガウス分布」とも呼ばれます。
自然界や社会のデータの多くが正規分布に近い形をしています。
- 人の身長や体重
- テストの点数
- 製品の寸法(工場の品質管理)
- 測定誤差
正規分布を決める2つのパラメータ
正規分布の形は、平均(μ) と 標準偏差(σ) の2つだけで完全に決まります。
| パラメータ | 記号 | 意味 |
|---|---|---|
| 平均(mean) | μ | 分布の中心位置。山の頂点がどこにあるか |
| 標準偏差(std) | σ |
以下のコードで、平均と標準偏差を変えたときの正規分布の形の変化を確認してみましょう。
# x軸の範囲を作成(-10 から 15 までを300分割)
x = np.linspace(-10, 15, 300)
# 2行1列のサブプロットを用意(図サイズも指定)
fig, axes = plt.subplots(2, 1, figsize=(8, 8))
# 上段:平均(μ)を変えて正規分布のPDFを比較(σは固定)
for mu in [0, 3, 6]:
axes[0].plot(
x, # x軸の値
# 正規分布のPDFを計算
stats.norm.pdf(
x, # x軸の値
loc=mu, # 平均
scale=2 # 標準偏差
),
linewidth=2, # 線の太さ
label=f'μ={mu}, σ=2' # 凡例のラベル
)
axes[0].set_title('平均(μ)を変えると:山の位置が移動する')
axes[0].set_xlabel('値')
axes[0].set_ylabel('確率密度')
axes[0].legend()
axes[0].grid(True, alpha=0.3)
# 下段:標準偏差(σ)を変えて正規分布のPDFを比較(μは固定)
for sigma in [1, 2, 4]:
axes[1].plot(
x, # x軸の値
# 正規分布のPDFを計算
stats.norm.pdf(
x, # x軸の値
loc=3, # 平均を3で固定
scale=sigma # 標準偏差を変更
),
linewidth=2, # 線の太さ
label=f'μ=3, σ={sigma}' # 凡例のラベル
)
axes[1].set_title('標準偏差(σ)を変えると:山の幅が変わる')
axes[1].set_xlabel('値')
axes[1].set_ylabel('確率密度')
axes[1].legend()
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
以下、実行結果です。
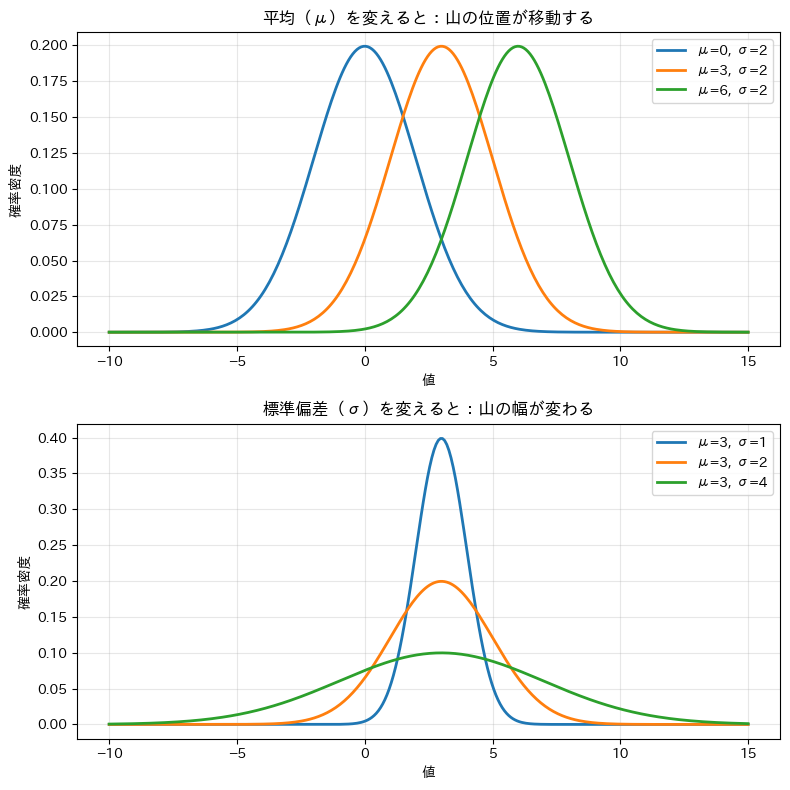
上のグラフから、平均μを変えると山全体が左右に移動することがわかります。
下のグラフから、標準偏差σが大きいほど山が低く広がり、σが小さいほど山が鋭く中心に集まることがわかります。
SciPyでの正規分布の使い方
SciPyでは、stats.norm で正規分布を扱います。
norm では、正規分布の平均を loc、標準偏差を scale で指定します。
まずは、平均70点、標準偏差10点のテスト結果を例に、正規分布を作ってみましょう。
mu = 70 # 平均(loc パラメータ) sigma = 10 # 標準偏差(scale パラメータ)
正規分布では、ある値の「起こりやすさの高さ」を表すには PDF(確率密度関数)を使います。
ここでは、平均にあたる70点と、平均よりかなり高い90点での確率密度を比べてみます。
# PDF:ある値の確率密度を求める
pdf_at_70 = stats.norm.pdf(
70, # x=70 の点で評価
loc=mu, # 平均(μ)
scale=sigma # 標準偏差(σ)
)
pdf_at_90 = stats.norm.pdf(
90, # x=90 の点で評価
loc=mu, # 平均(μ)
scale=sigma # 標準偏差(σ)
)
# 結果を表示(小数点以下4桁に丸めて表示)
print(f"x=70 の確率密度:{pdf_at_70:.4f}")
print(f"x=90 の確率密度:{pdf_at_90:.4f}")
以下、実行結果です。
x=70 の確率密度:0.0399 x=90 の確率密度:0.0054
平均に近い70点のほうが、90点よりも確率密度が高くなっています。
これは、平均付近の値が最も出やすく、平均から離れるほど出にくくなるという、正規分布の基本的な形を表しています。
次に、ある点数以下になる確率を求めてみましょう。
このようなときには CDF(累積分布関数)を使います。
ここでは「80点以下の人は全体の何%くらいか」を計算します。
# CDF:ある値以下になる確率を求める
cdf_80 = stats.norm.cdf(
80, # 評価する点(80点)
loc=mu, # 平均(mu)
scale=sigma # 標準偏差(sigma)
)
# 結果を見やすく表示(小数4桁とパーセント表記)
print(f"80点以下の確率:{cdf_80:.4f}({cdf_80*100:.1f}%)")
以下、実行結果です。
80点以下の確率:0.8413(84.1%)
結果は約84.1%でした。
これは、平均70点・標準偏差10点の正規分布を仮定すると、80点以下の人が全体の約84%を占めることを意味します。
反対に、「ある値以上」の確率もよく使います。
たとえば「90点以上を取る人はどれくらいいるか」を知りたいときです。
この場合は、「1 - その値以下の確率」で求められます。
# 「ある値以上」の確率は 1 から CDF(その値以下の確率)を引いて求める
prob_above_90 = 1 - stats.norm.cdf(
90, # しきい値(90点)
loc=mu, # 平均(μ)
scale=sigma# 標準偏差(σ)
)
# 結果を表示(小数4桁とパーセント表記)
print(f"90点以上の確率:{prob_above_90:.4f}({prob_above_90*100:.1f}%)")
以下、実行結果です。
90点以上の確率:0.0228(2.3%)
結果を見ると、90点以上を取る人は約2.3%しかいません。
平均よりかなり高い点数なので、該当する人は少ないことが分かります。
今度は逆に、「上位10%に入るには何点必要か」を求めてみます。
このように、確率から対応する値を逆算したいときには PPF を使います。
# 上位10%に入るための境界点を計算
top_10_score = stats.norm.ppf(
0.90, # 累積確率(90パーセンタイル)
loc=mu, # 平均(μ)
scale=sigma # 標準偏差(σ)
)
# 結果を表示(小数1桁)
print(f"上位10%に入るために必要な点数:{top_10_score:.1f}点")
以下、実行結果です。
上位10%に入るために必要な点数:82.8点
計算結果は82.8点でした。
つまり、この分布では約82.8点を超えると、全体の上位10%に入ることになります。
確率の計算をグラフで可視化
「80点以下の確率」と「90点以上の確率」をグラフの塗りつぶしで表現してみましょう。
まずは、平均70点、標準偏差10点の正規分布を用意します。
横軸に点数、縦軸に確率密度をとり、あとでこの曲線の一部を塗りつぶして確率の範囲を見えるようにします。
# パラメータ設定(平均と標準偏差)
mu, sigma = 70, 10
# x軸の範囲を作成(30〜110を300分割)
x = np.linspace(30, 110, 300)
# 正規分布のPDF(確率密度)を計算
y = stats.norm.pdf(
x, # x軸の範囲
loc=mu, # 平均
scale=sigma # 標準偏差
)
最初に、「80点以下の確率」を描いてみます。
正規分布の曲線を描いたうえで、80点より左側の部分を塗りつぶせば、「80点以下に入る範囲」が視覚的に分かります。
# -----------------------------
# 80点以下の確率
# -----------------------------
# プロットの設定
fig1, ax1 = plt.subplots(figsize=(8, 4))
# PDFの曲線
ax1.plot(
x, # x
y, # y
color='blue', # 青色
linewidth=2 # 太さ
)
# 80以下のx範囲
x_fill = x[x <= 80] # 80以下
ax1.fill_between(
x_fill, # x範囲
# PDFの計算
stats.norm.pdf(
x_fill, # x範囲
loc=mu, # 平均
scale=sigma # 標準偏差
),
alpha=0.3, # 透明度
color='blue', # 色
label=f'80点以下: {stats.norm.cdf(80, mu, sigma)*100:.1f}%'
)
# 80点の目安線
ax1.axvline(
x=80, # x位置
color='red', # 赤
linestyle='--', # 破線
alpha=0.7, # 透明度
label='80点' # ラベル
)
ax1.set_title('80点以下の確率')
ax1.set_xlabel('点数')
ax1.set_ylabel('確率密度')
ax1.legend()
ax1.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
以下、実行結果です。
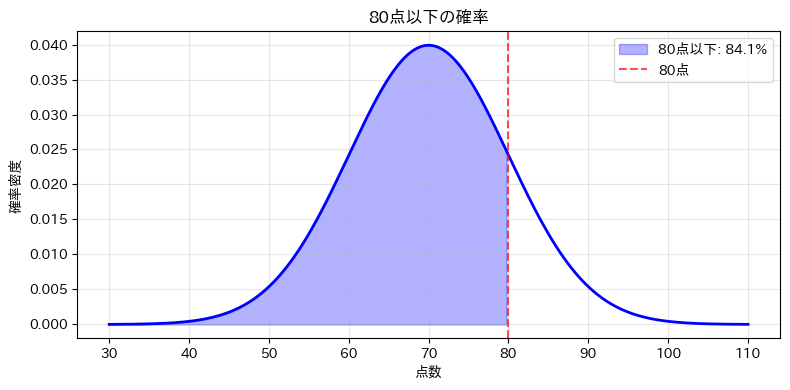
この図では、赤い破線が80点を表し、その左側の青い塗りつぶし部分が「80点以下の確率」に対応しています。
数式だけで見るよりも、分布全体の中でどのくらいの範囲を占めるかが直感的に理解しやすくなります。
次に、「90点以上の確率」も同じように見てみましょう。
今度は90点より右側を塗りつぶすことで、上位側の確率を表現します。
# -----------------------------
# 90点以上の確率
# -----------------------------
# プロットの設定
fig2, ax2 = plt.subplots(figsize=(8, 4))
# PDFの曲線
ax2.plot(
x, # x
y, # y
color='blue', # 青色
linewidth=2 # 太さ
)
# 90以上のx範囲
x_fill2 = x[x >= 90] # 90以上
ax2.fill_between(
x_fill2, # x範囲
# PDFの計算
stats.norm.pdf(
x_fill2, # x範囲
loc=mu, # 平均
scale=sigma # 標準偏差
),
alpha=0.3, # 透明度
color='red', # 色
label=f'90点以上: {(1 - stats.norm.cdf(90, mu, sigma))*100:.1f}%'
)
# 90点の目安線
ax2.axvline(
x=90, # x位置
color='red', # 線色
linestyle='--', # 破線
alpha=0.7, # 透明度
label='90点' # ラベル
)
ax2.set_title('90点以上の確率')
ax2.set_xlabel('点数')
ax2.set_ylabel('確率密度')
ax2.legend()
ax2.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
以下、実行結果です。
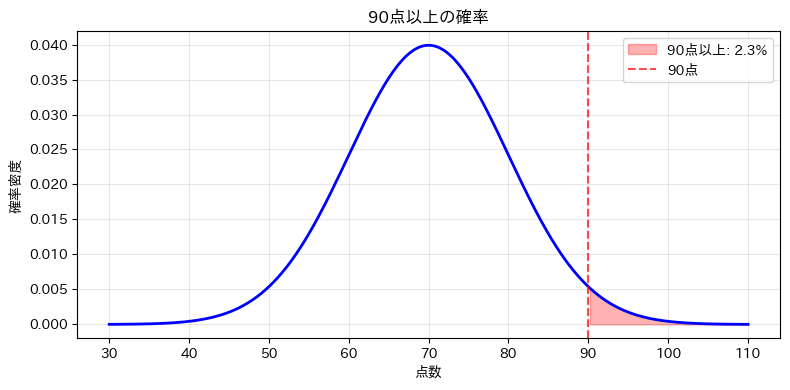
この図では、90点より右側の赤い塗りつぶし部分が「90点以上の確率」です。
平均からかなり離れた高得点なので、塗りつぶされる面積が小さくなり、該当する人が少ないことも視覚的に確認できます。
正規分布の68-95-99.7ルール
正規分布には 「68-95-99.7ルール」 という有名な性質があります。
これは、データが平均からどれくらいの範囲に収まるかを示す法則です。
| 範囲 | 含まれるデータの割合 |
|---|---|
| μ ± 1σ | 約 68.3% |
| μ ± 2σ | 約 95.4% |
| μ ± 3σ |
つまり、正規分布に従うデータの約95%は「平均 ± 2×標準偏差」の範囲に入り、約99.7%は「平均 ± 3×標準偏差」の範囲に入ります。
では、stats.normで正規分布を作り、以下のコードで確認してみましょう。
# 平均(mu)と標準偏差(sigma)を設定
mu, sigma = 0, 1
# x軸の範囲を作成(-4から4まで)
x = np.linspace(-4, 4, 300)
# 正規分布の確率密度関数(PDF)を計算
y = stats.norm.pdf(x, loc=mu, scale=sigma)
# 数値で確認:±1σ, ±2σ, ±3σ に含まれる確率を計算
for n_sigma in [1, 2, 3]:
# CDFを使って [-nσ, nσ] 区間の確率を求める
prob = (
# nσ までの確率から
stats.norm.cdf(
n_sigma, # nσ
loc=mu, # 平均
scale=sigma # 標準偏差
)
# -nσ までの確率を引く
- stats.norm.cdf(
-n_sigma, # -nσ
loc=mu, # 平均
scale=sigma # 標準偏差
)
)
# 結果をパーセンテージで表示
print(f"μ±{n_sigma}σ の範囲に含まれる確率:{prob*100:.1f}%")
以下、実行結果です。
μ±1σ の範囲に含まれる確率:68.3% μ±2σ の範囲に含まれる確率:95.4% μ±3σ の範囲に含まれる確率:99.7%
グラフで視覚的に確認してみましょう。
以下、コードです。
# グラフのサイズ
plt.figure(figsize=(8, 6))
# PDFの曲線(標準正規分布)
plt.plot(x, y, color='black', linewidth=2)
# 1σ の範囲(68.3%)を塗りつぶし
x1 = x[(x >= -1) & (x <= 1)] # -1σ〜+1σ のx範囲 plt.fill_between( x1, stats.norm.pdf(x1, mu, sigma), alpha=0.4, color='blue', label='μ±1σ(68.3%)' ) # 2σ の範囲(1σの外側を追加で塗る) x2_left = x[(x >= -2) & (x < -1)] # 左側の -2σ〜-1σ x2_right = x[(x > 1) & (x <= 2)] # 右側の +1σ〜+2σ plt.fill_between( x2_left, stats.norm.pdf(x2_left, mu, sigma), alpha=0.3, color='green', label='μ±2σ(95.4%)' ) plt.fill_between( x2_right, stats.norm.pdf(x2_right, mu, sigma), alpha=0.3, color='green' ) # 3σ の範囲(2σの外側を追加で塗る) x3_left = x[(x >= -3) & (x < -2)] # 左側の -3σ〜-2σ x3_right = x[(x > 2) & (x <= 3)] # 右側の +2σ〜+3σ
plt.fill_between(
x3_left,
stats.norm.pdf(x3_left, mu, sigma),
alpha=0.2,
color='orange',
label='μ±3σ(99.7%)'
)
plt.fill_between(
x3_right,
stats.norm.pdf(x3_right, mu, sigma),
alpha=0.2,
color='orange'
)
plt.title('68-95-99.7ルール(正規分布)')
plt.xlabel('値(σ単位)')
plt.ylabel('確率密度')
plt.xticks(range(-4, 5), [f'{i}σ' for i in range(-4, 5)])
plt.legend(loc='upper right')
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
以下、実行結果です。
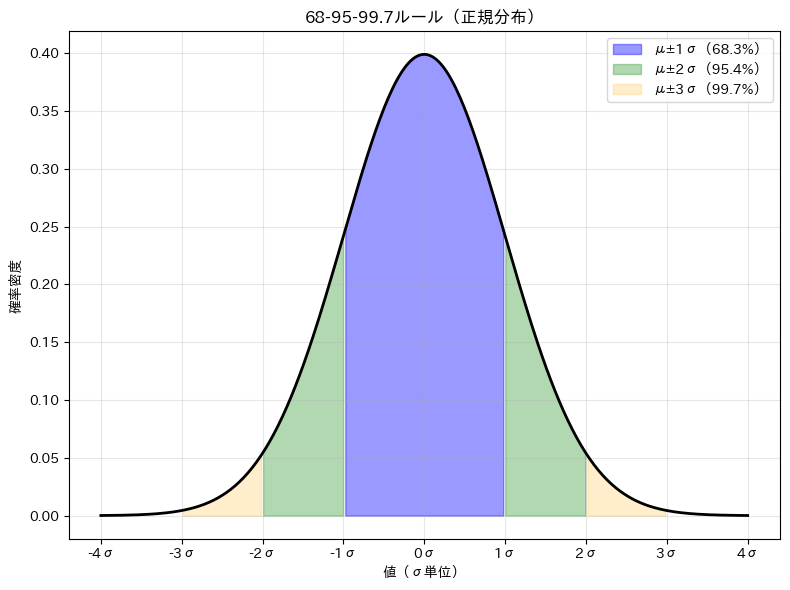
この性質は、異常検知(3σを超えるデータを異常とみなす)や品質管理(製品が規格内に収まる確率を計算する)などで広く活用されています。
正規分布の乱数生成とシミュレーション
確率分布からランダムなデータ(乱数)を生成する機能は、シミュレーションに非常に役立ちます。
たとえば、「ある集団がだいたい正規分布に従う」と仮定できるとき、その分布から擬似的なデータを作り、どのようなばらつきが生じるかを確かめることができます。
ここでは、平均170cm、標準偏差6cmの身長データを1000人分生成してみます。
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
np.random.seed(42) # 再現性のため乱数シードを固定
# 平均170cm、標準偏差6cm の身長データを1000人分シミュレーション
heights = stats.norm.rvs(loc=170, scale=6, size=1000)
# 結果の統計量
print("【シミュレーション結果(1000人の身長)】")
print(f" 平均 :{heights.mean():.1f} cm")
print(f" 標準偏差:{heights.std():.1f} cm")
print(f" 最小値 :{heights.min():.1f} cm")
print(f" 最大値 :{heights.max():.1f} cm")
以下、実行結果です。
【シミュレーション結果(1000人の身長)】 平均 :170.1 cm 標準偏差:5.9 cm 最小値 :150.6 cm 最大値 :193.1 cm
生成されたデータの平均や標準偏差を見ると、設定した平均170cm、標準偏差6cmにかなり近い値になっていることが分かります。
乱数なので一人ひとりの値はばらつきますが、全体としては想定した正規分布の性質が反映されています。
さらに、ヒストグラムを描いて理論上の正規分布の曲線と重ねると、シミュレーションで得られたデータがどの程度正規分布らしい形になっているかを視覚的に確認できます。
# ヒストグラムと理論曲線を重ねて描画
x_theory = np.linspace(145, 195, 200)
plt.figure(figsize=(9, 6))
plt.hist(heights, bins=30, color='blue', alpha=0.7, edgecolor='black',
density=True, label='シミュレーション(1000人)')
plt.plot(x_theory, stats.norm.pdf(x_theory, loc=170, scale=6),
color='red', linewidth=2, label='理論曲線(μ=170, σ=6)')
plt.axvline(x=heights.mean(), color='orange', linestyle='--',
label=f'サンプル平均 ({heights.mean():.1f}cm)')
plt.xlabel('身長(cm)')
plt.ylabel('確率密度')
plt.title('正規分布からの乱数生成:1000人の身長シミュレーション')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('normal_random.png', dpi=150)
plt.show()
以下、実行結果です。
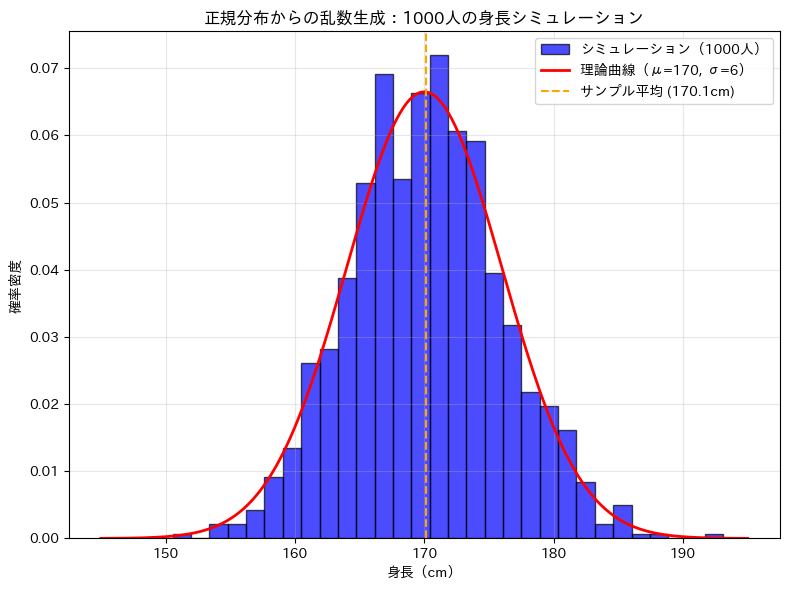
グラフを見ると、ヒストグラムは滑らかな釣り鐘型に近い形になっており、赤い理論曲線ともおおむね一致しています。
サンプル数が十分に多いと、乱数で生成したデータでも、もとの分布の形がよく再現されることが分かります。
正規分布に従うか確認するための検定
グラフなどを見て「なんとなく釣り鐘型に見える」というだけでは、正規分布に従うかどうかを厳密には判断できません。
そこで使われるのが正規性の検定です。
ここでは代表的な方法として、シャピロ・ウィルク検定を使ってみます。
この検定では、まず次の2つの仮説を立てます。
- 帰無仮説:データは正規分布に従う
- 対立仮説:データは正規分布に従わない
そして、この帰無仮説のもとで今のデータがどの程度起こりやすいかを p値 で評価します。
一般には、p値が 0.05 より大きければ帰無仮説を棄却できないため、「正規分布に従うとしても不自然ではない」と考えます。
逆に、p値が 0.05 以下なら帰無仮説を棄却し、「正規分布に従わない可能性が高い」と判断します。
ここで、比較のために2種類のデータを用意します。
ひとつは正規分布から生成したデータ、もうひとつは正規分布ではない指数分布から生成したデータです。
最初に、どのような値が得られているかを少しだけ確認してみましょう。
# 乱数の再現性を保つためにシードを固定
np.random.seed(42)
# ===== 正規分布に従うデータ =====
# 平均50、標準偏差10の正規分布から100個の乱数を生成
normal_data = stats.norm.rvs(loc=50, scale=10, size=100)
# ===== 正規分布に従わないデータ(指数分布) =====
# 平均(スケール)10の指数分布から100個の乱数を生成
non_normal_data = stats.expon.rvs(scale=10, size=100)
# 生成データの簡単な確認(先頭5件)
print('normal_data (head):', normal_data[:5])
print('non_normal_data (head):', non_normal_data[:5])
以下、実行結果です。
normal_data (head): [54.96714153 48.61735699 56.47688538 65.23029856 47.65846625] non_normal_data (head): [ 5.40273321 2.51167338 1.27680392 4.1190858 28.63121123]
まず、正規分布から生成したデータに対してシャピロ・ウィルク検定を行います。
ここでは、「このデータは正規分布に従う」という帰無仮説を棄却できるかどうかを調べます。
# シャピロ・ウィルク検定(正規分布データに対して適用)
stat_n, p_n = stats.shapiro(normal_data)
# 結果を表示
print("【正規分布から生成したデータ】")
print(f" シャピロ・ウィルク検定: 統計量={stat_n:.4f}, p値={p_n:.4f}")
# 有意水準5%で判定
if p_n > 0.05:
print(f" → p値({p_n:.4f}) > 0.05:正規分布に従うと考えて良い")
else:
print(f" → p値({p_n:.4f}) ≤ 0.05:正規分布に従わない可能性が高い")
以下、実行結果です。
【正規分布から生成したデータ】 シャピロ・ウィルク検定: 統計量=0.9899, p値=0.6551 → p値(0.6551) > 0.05:正規分布に従うと考えて良い
p値は 0.6551 となり、0.05 を大きく上回っています。したがって、帰無仮説は棄却されません。
この結果から、このデータは正規分布に従うとしても不自然ではないと判断できます。
次に、指数分布から生成したデータに対して同じ検定を行います。
指数分布は左右対称ではなく右に長い裾を持つため、正規分布とは性質がかなり異なります。
# シャピロ・ウィルク検定(指数分布データに対して適用)
stat_e, p_e = stats.shapiro(non_normal_data)
# 結果を表示
print("【指数分布から生成したデータ】")
print(f" シャピロ・ウィルク検定: 統計量={stat_e:.4f}, p値={p_e:.4f}")
# 有意水準5%で判定
if p_e > 0.05:
print(f" → p値({p_e:.4f}) > 0.05:正規分布に従うと考えて良い")
else:
print(f" → p値({p_e:.4f}) ≤ 0.05:正規分布に従わない可能性が高い")
以下、実行結果です。
【指数分布から生成したデータ】 シャピロ・ウィルク検定: 統計量=0.8406, p値=0.0000 → p値(0.0000) ≤ 0.05:正規分布に従わない可能性が高い
こちらは p値がほぼ 0 となり、0.05 を大きく下回っています。そのため、帰無仮説は棄却されます。
つまり、このデータは正規分布に従わない可能性が高いと判断できます。
このように、シャピロ・ウィルク検定を使うと、データが正規分布とみなせるかどうかを客観的に確認できます。
ただし、p値が大きかったからといって「正規分布であることが証明された」わけではありません。
あくまで、「正規分布ではない」とまではいえなかった、という意味で解釈することが大切です。
SciPyで使える正規分布メソッドのまとめ
stats.norm を使うと、正規分布に関するいろいろな計算ができます。
よく使うメソッドを整理すると、次のようになります。
| メソッド | 意味 | |
|---|---|---|
pdf(x) |
ある値のあたりの出やすさの高さ(確率密度) | 「70点あたりはどれくらい出やすいか」 |
cdf(x) |
ある値以下になる確率 | 「80点以下の確率は?」 |
ppf(q) |
下から q の割合にあたる値 | 「上位5%に入るには何点必要か」 |
rvs(size=n) |
乱数を発生させる | 「1000人分のデータを作る」 |
mean() |
理論上の平均 | 「平均はいくつか」 |
std() |
理論上の標準偏差 | 「ばらつきの大きさはどれくらいか」 |
interval(alpha) |
ほとんどのデータが収まる範囲 | 「95%のデータが収まりそうな範囲は?」 |
たとえば、平均70点、標準偏差10点の正規分布を考えてみましょう。
stats.norm(loc=70, scale=10) のように書くと、その正規分布を表す「分布オブジェクト」を作れます。
from scipy import stats
# 分布オブジェクトを作成(平均70、標準偏差10)
dist = stats.norm(loc=70, scale=10)
print("【正規分布メソッド一覧(μ=70, σ=10)】")
print(f" 平均 : {dist.mean():.1f}")
print(f" 標準偏差 : {dist.std():.1f}")
print(f" PDF(x=70) : {dist.pdf(70):.4f}")
print(f" CDF(x=80) : {dist.cdf(80):.4f}(80点以下の確率)")
print(f" PPF(q=0.95) : {dist.ppf(0.95):.1f}(上位5%のライン)")
print(f" 95%信頼区間 : {dist.interval(0.95)}")
以下、実行結果です。
【正規分布メソッド一覧(μ=70, σ=10)】 平均 : 70.0 標準偏差 : 10.0 PDF(x=70) : 0.0399 CDF(x=80) : 0.8413(80点以下の確率) PPF(q=0.95) : 86.4(上位5%のライン) 95%信頼区間 : (50.40036015478788, 89.59963984521212)
ちなみに、ここで dist.interval(0.95) が表しているのは、この正規分布に従うデータをたくさん集めたとき、そのうち約95%が入りそうな範囲です。
今回なら、点数の多くは 50.4点から89.6点くらいの間に入る、と考えればよいでしょう。
逆にいうと、残りの約5%はこの範囲の外に出るということです。
つまり、この範囲は「すべてのデータが入る範囲」ではなく、大部分のデータが入る範囲を表しています。
まとめ
今回のポイントを振り返りましょう。
- 確率分布 は、データの散らばり方のパターンを数学的に表したもの
- 正規分布 は、平均(μ)と標準偏差(σ)で形が決まる釣り鐘型の分布
- PDF は各値の出やすさ、CDF は累積確率、PPF はCDFの逆関数
- 68-95-99.7ルール:データの68%は μ±1σ、95%は μ±2σ、99.7%は μ±3σ の範囲に入る
- rvs で乱数を生成し、シミュレーションに活用できる
- シャピロ・ウィルク検定で、データが正規分布に従うか確認できる
次回は、もう一つの重要な確率分布である 「ポアソン分布」 を紹介します。
正規分布が「量」(身長、点数など)のデータに使われるのに対し、ポアソン分布は「回数」(来客数、故障回数など)のデータに使われます。