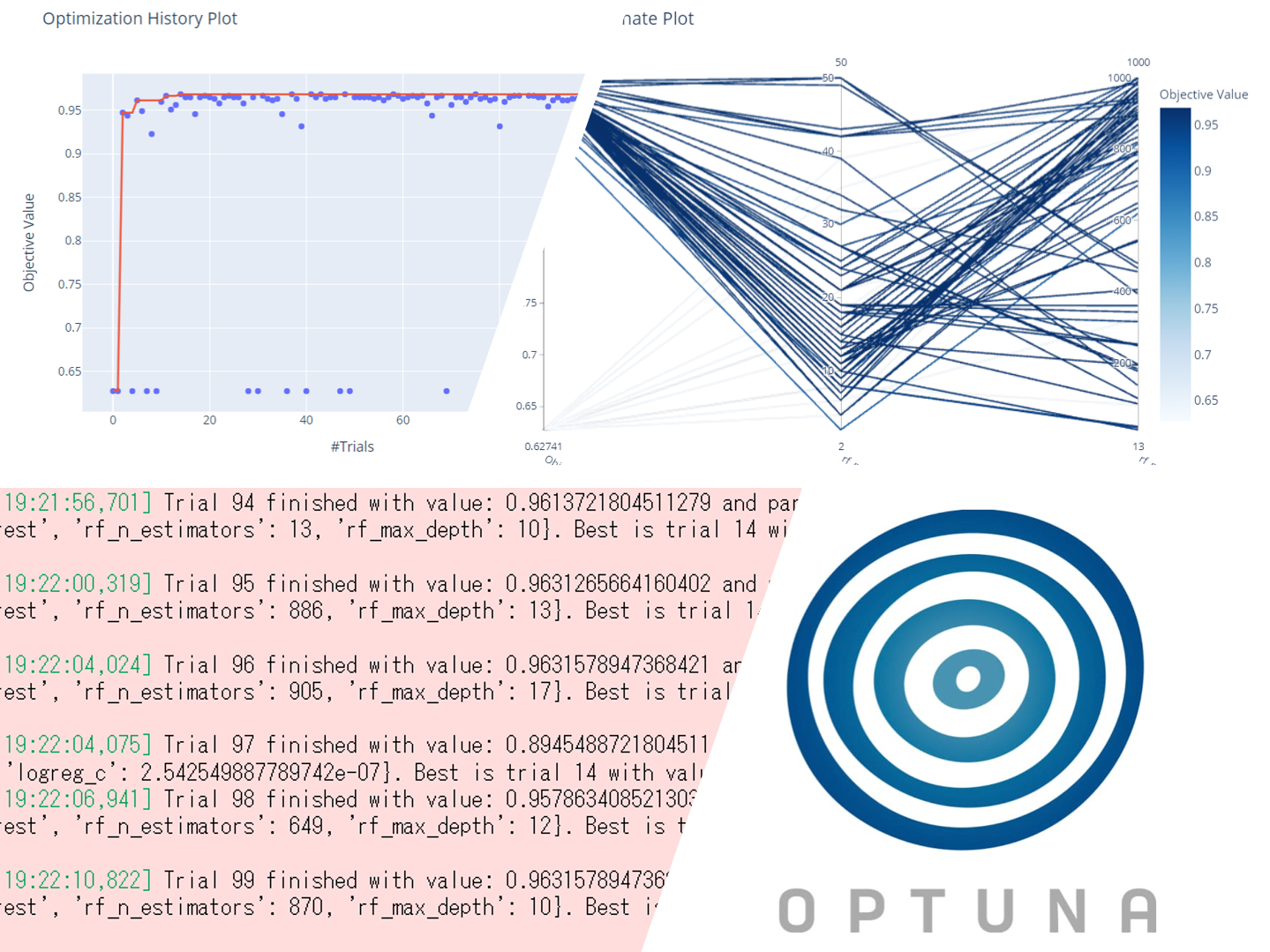
機械学習などの数理モデルには、通常幾つかのハイパーパラメータがあり、そのハイパーパラメータの設定次第で大きく精度が変わります。 このハイパーパラメータを調整し最適な設定を探すタスクを、ハイパーパラメータチューニングと言い...
機械学習などの数理モデルには、通常幾つかのハイパーパラメータがあり、そのハイパーパラメータの設定次第で大きく精度が変わります。 このハイパーパラメータを調整し最適な設定を探すタスクを、ハイパーパラメータチューニングと言い...
定額課金のサブスクビジネスでよく活用される指標にMRR(Monthly Recurring Revenue)を元に計算するQuick Ratioという指標があります。 このQuick Ratioは、経営分析などで利用され...
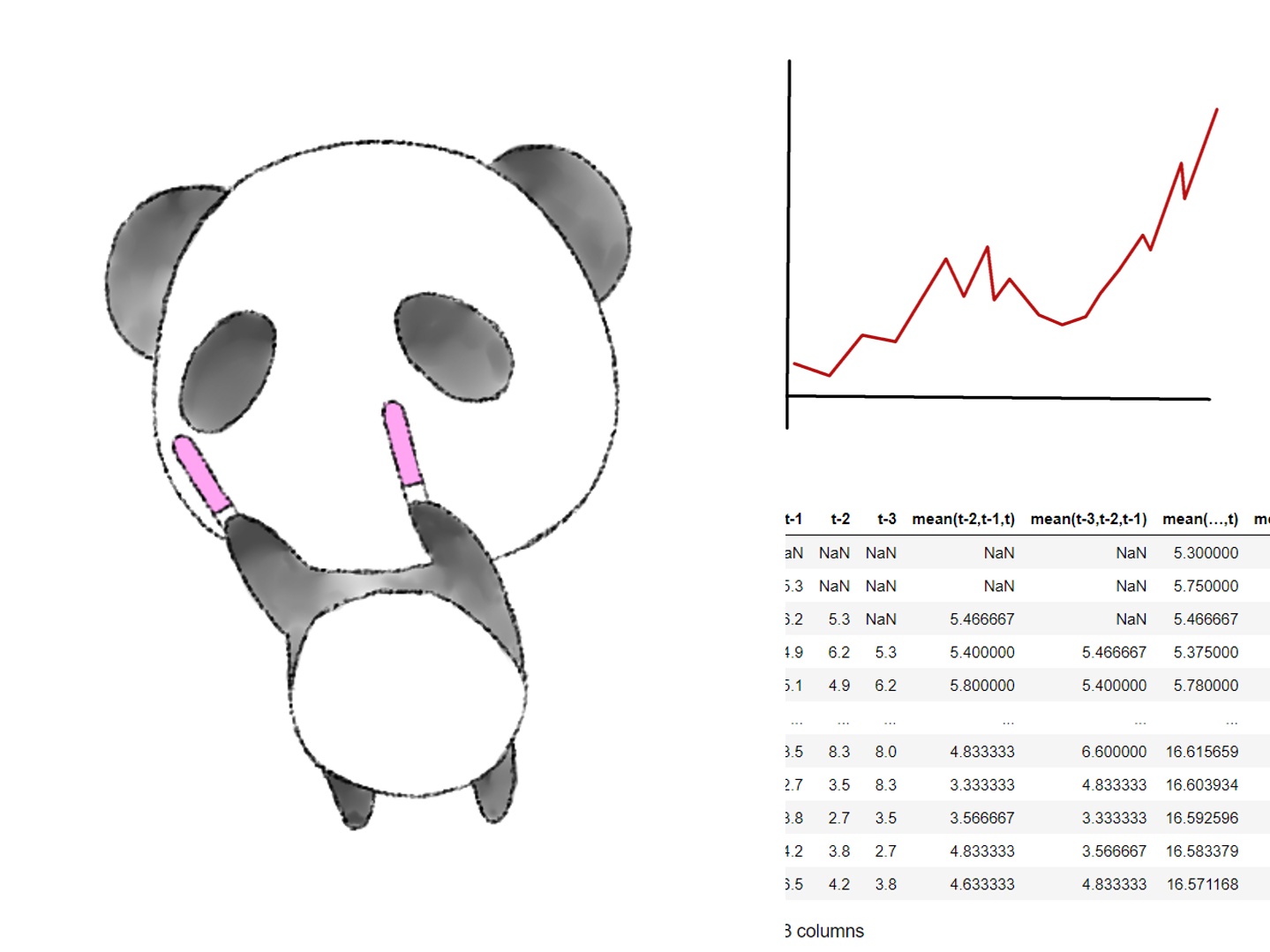
売上などのビジネス系のデータの多くは、時間概念が紐付いた時系列データです。 時間概念を取っ払ったテーブルデータと異なり、時系列データは、過去の値に大きく依存する、という特徴があります。そのため、一工夫必要になります。例え...
データを手に入れたとき、集計や分析、数理モデル構築などをする前に、前処理をしデータをキレイにする必要があります。 前処理を適切に行わないと、間違った何かを出力することになります。 では実際どのようなことをするのか? 今回...
最近色々な自動機械学習 AutoML(Automated Machine Learning)が登場しています。TPOT、MLBox、Auto-Sklearnなどの様々なAutoML(自動機械学習)Pythonライブラリー...
売上などのビジネス系のデータの多くは、時間概念が紐付いた時系列データです。 時間概念を取っ払ったテーブルデータと異なり、時系列データは、過去の値に大きく依存する、という特徴があります。 そのため、一工夫必要になります。例...
法人相手のビジネスやECサイト、個別面談を通すようなビジネスなどでは、顧客をIDベースで追えるケースが多いです。 運が良ければ、リード(見込み顧客)の段階で、何かしらデータを得ているケースもあります。法人相手のビジネスな...
最近色々な自動機械学習 AutoML(Automated Machine Learning)が登場しています。 AutoML(自動機械学習)は、機械学習パイプライン(データセット→特徴量エンジニアリング→学習→評価など)...
需要予測はビジネスの現場では非常に重要なことです。ただ、データによらない経験と勘といい加減による予測が蔓延っている世界でもあります。 面倒だから、昨年と一緒、昨年の売上を1.1倍する、取り急ぎ右肩上がりに描く、みたいない...
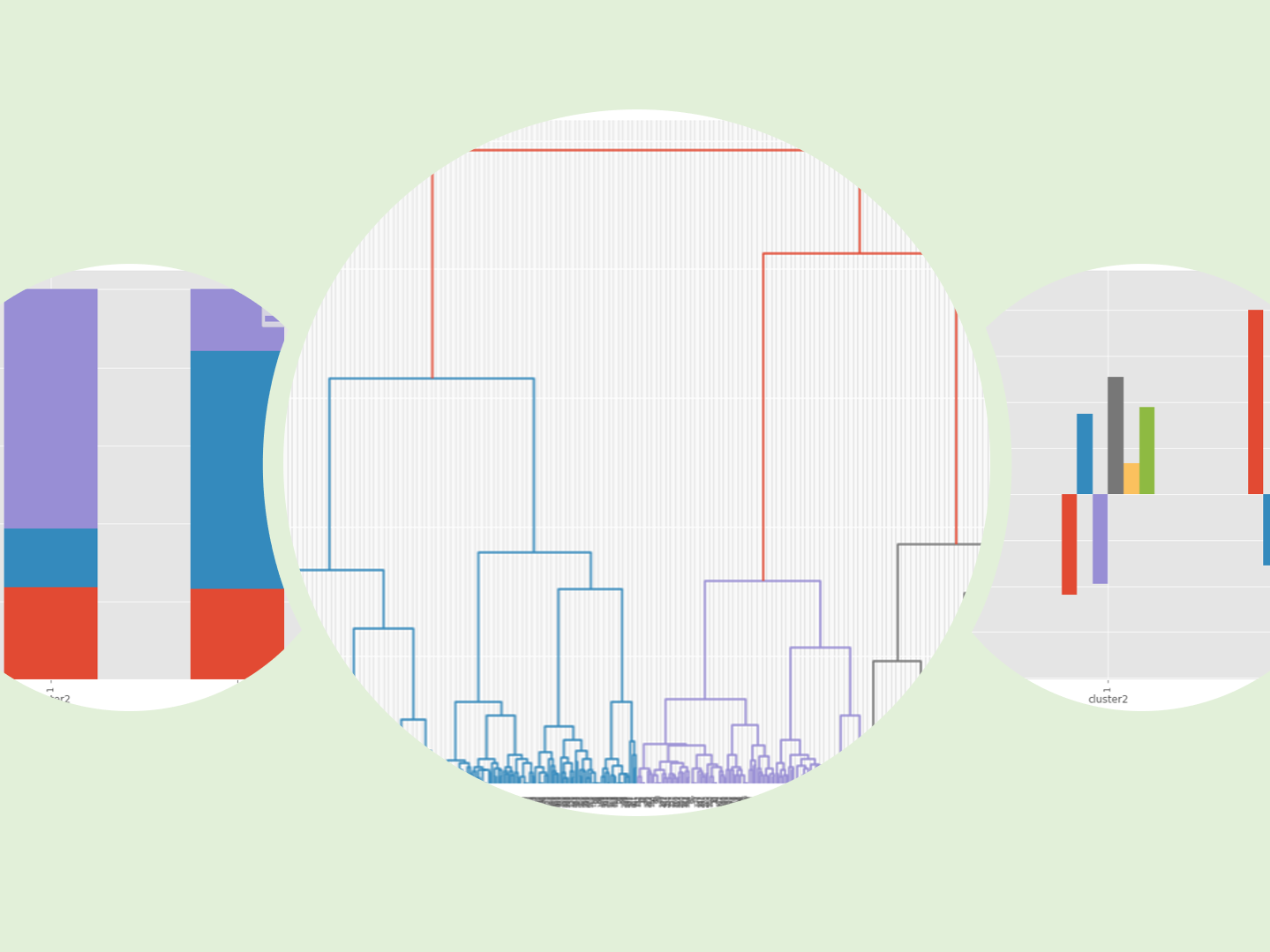
クラスター分析で利用されるメジャーなアルゴリズムは、非階層型クラスタリングのk-means法か、階層型のWard法がよく使われます。 問題は、量的データ(数値変数)のみを使うというところにあります。質的データ(カテゴリカ...
よくあるデータ活用のテーマの1つに、顧客のチャーン予測(離反予測)というものがあります。離反率をはじき出すことができます。 離反率は、顧客満足度の重要な指標です。離反率が低いということは、顧客が満足しているということです...
市場反応分析(Market Response Analysis)では、広告・価格変更・販促・営業などのマーケティング活動に対する反応(売上や購買行動など)を分析します。 比較的やりやすく、多くの人に関心をもられやすいデー...
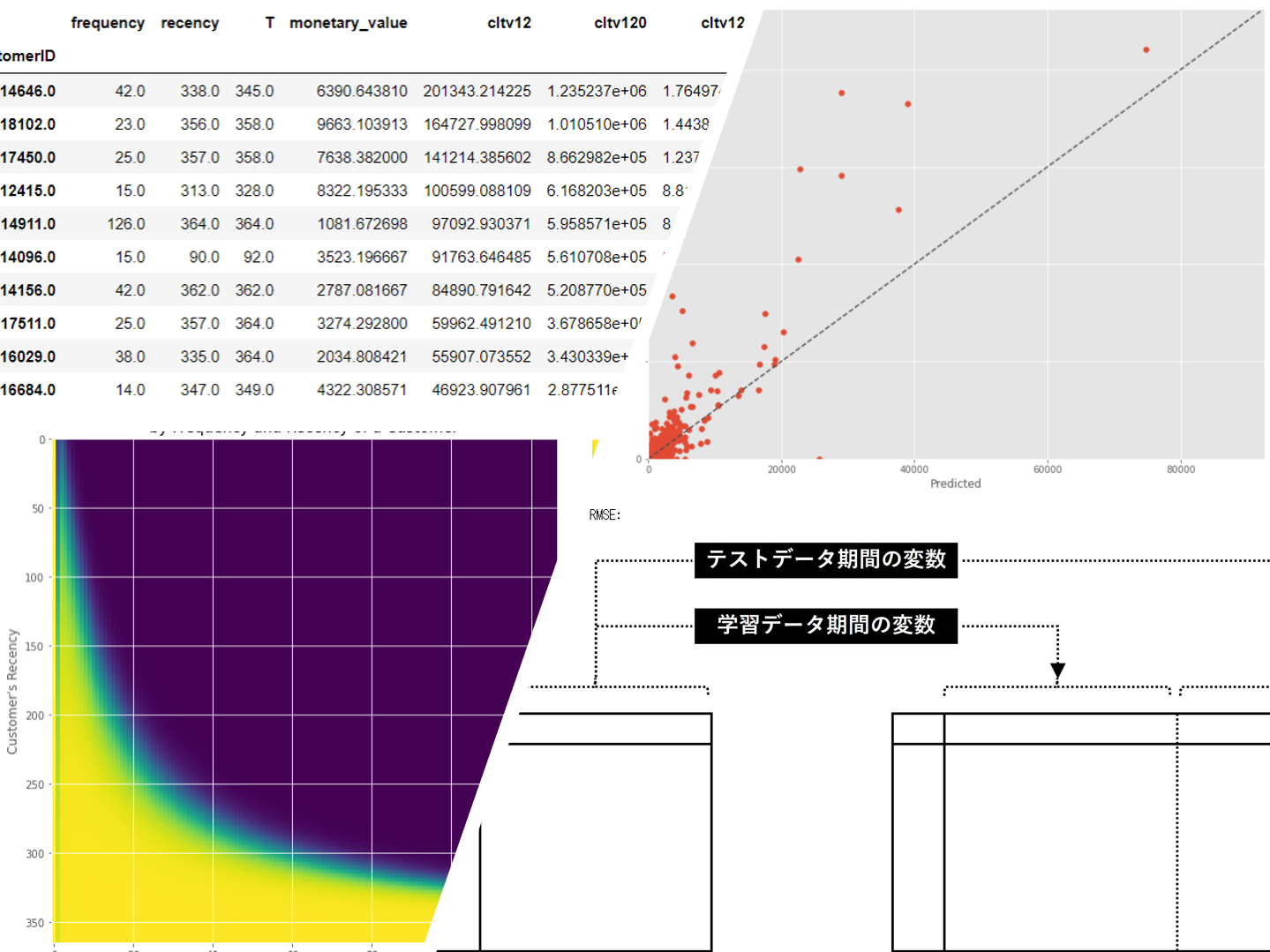
顧客別CLTV(Individual CLTV)とは、顧客の金銭的価値のことで、将来行う取引に基づいて算出されます。 個々の顧客が将来どのくらいの利益を生み出すかがわかれば、価値の高い顧客に対し、マーケティング活動などを...
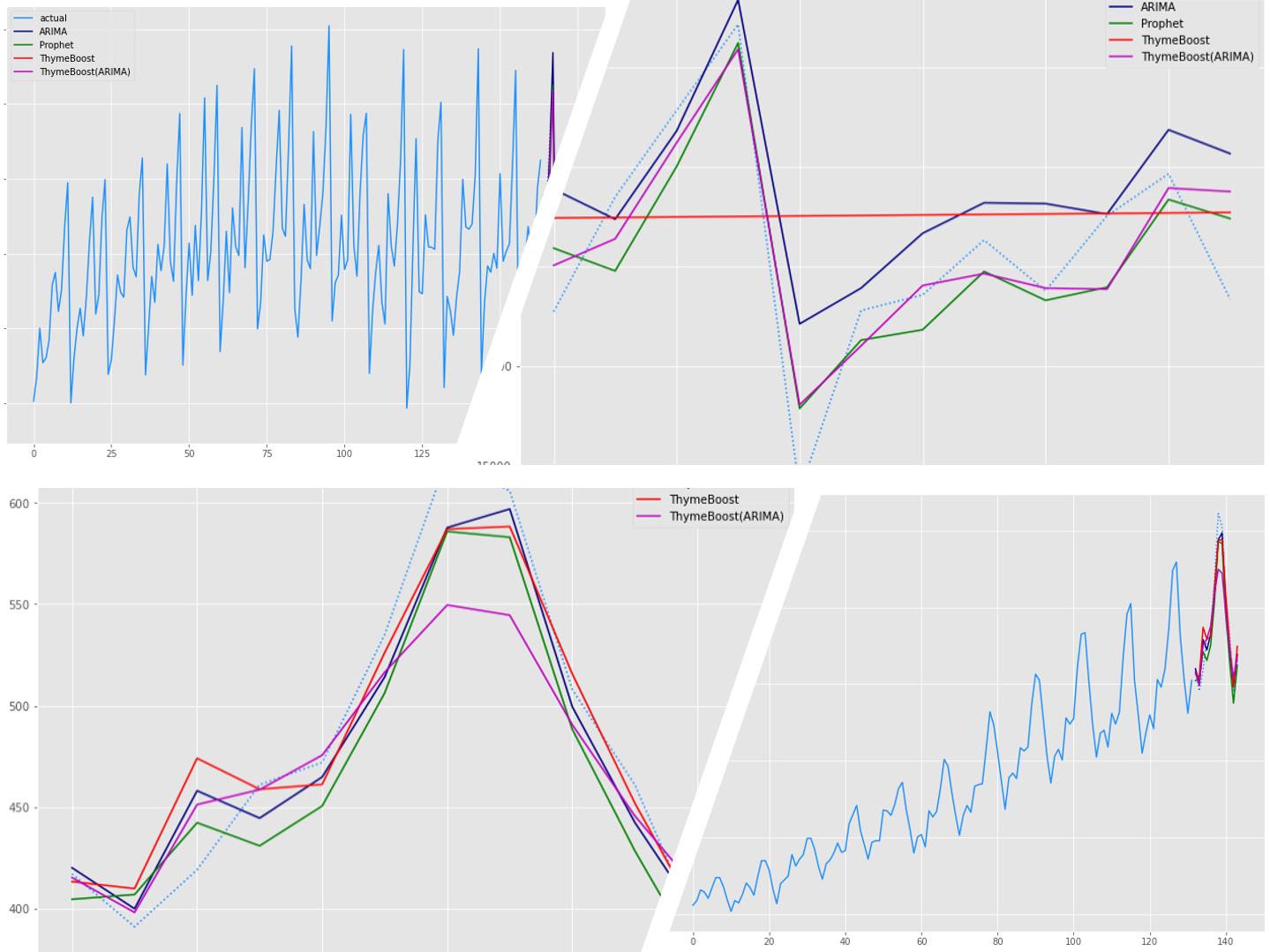
時系列モデルと言えば、ARIMAモデルです。最近では、FacebookのProphetモデルも人気です。 ThymeBoostは、時系列分解(トレンド成分・季節成分・など)と勾配ブースティング(XGBoostなど)を組み...
CLTV(顧客生涯価値)には全体レベル(集計レベル)と個人レベル(個々の顧客レベル)のものがあります。 全体レベル(集計レベル)のCLTV(顧客生涯価値)である(Aggregate CLTV)は、多くの場合驚くほどの予測...