

sktimeはPythonでよく使われている機械学習ライブラリsklearn(scikit-learn)と同じインターフェースで提供されているPythonの時系列ライブラリです。
![]()
sklearnはテーブルデータを扱う上では十分ですが、時系列データを扱う上では不十分です。とは言え、sklearnは機械学習の実装に便利な機能やインターフェースを備えています。
sklearnの便利な機能やインターフェースを踏襲しつつ、時系列データに特化したライブラリがsktimeです。
sktimeでは2022.7.4時点で時系列の4つの時系列機械学習の問題を解くことができます。
| 問題名 | データの種類 | 内容 |
| 1. 時系列予測 Forecasting |
目的変数のみの時系列データ | 過去の時系列データが与えられたときの将来の予測です。 |
| 2. 時系列クラスタリング Time Series Clustering |
特徴量(説明変数)のみの時系列データ | 複数の時系列データを、いくつかの類似のグループに分けます。 |
| 3. 時系列分類 Time Series Classification |
目的変数と特徴量(説明変数)のある時系列データ | 特徴量と目的変数が与えられた分類問題のうち、特徴量に時間的もしくはデータの順番に意味があるときに使います。sktimeでは二値分類および多値分類に対応しています。 |
| 4. 時系列回帰 Time Series Regression |
特徴量と目的変数が与えられたとき、目的変数が時系列かつ連続データであるときの目的変数の予測です。 |
今回は、4つの問題(時系列予測・時系列クラスタリング・時系列分類・時系列回帰)がどのようなものなのか、そのイメージを簡単に説明していきます。
1.時系列予測(Forecasting)
取り扱う時系列データは、例えば次のような目的変数のみの時系列データです。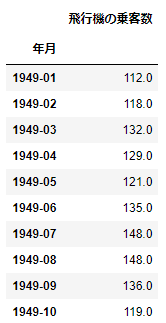
時間のデータに対して、知りたい値(目的変数)が紐づいています。今回、時間は年月の粒度、知りたい値は飛行機の乗客数です。
参考:Box, G. E. P., Jenkins, G. M. and Reinsel, G. C. (1976) Time Series Analysis, Forecasting and Control. Third Edition. Holden-Day. Series G.
http://garfield.library.upenn.edu/classics1989/A1989AV48500001.pdf
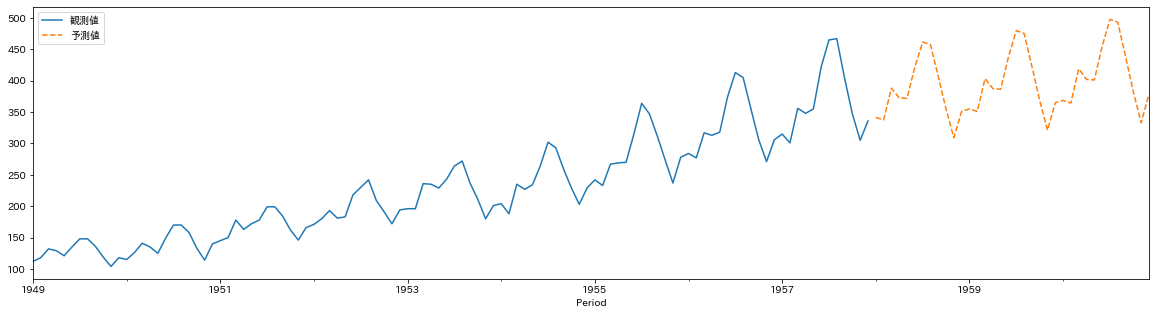
このデータがたとえば1957年12月までしかないときにその翌月から予測したい、というのが時系列予測の問題です。
sktimeを使って例えばこのように予測ができます。青い実線が観測値、オレンジの破線が予測値です。
2.時系列クラスタリング(Time series clustering)
取り扱う時系列データは、次のような横方向に伸びていく時系列データです。計測点に対する矢じりの輪郭の位置を表しています。
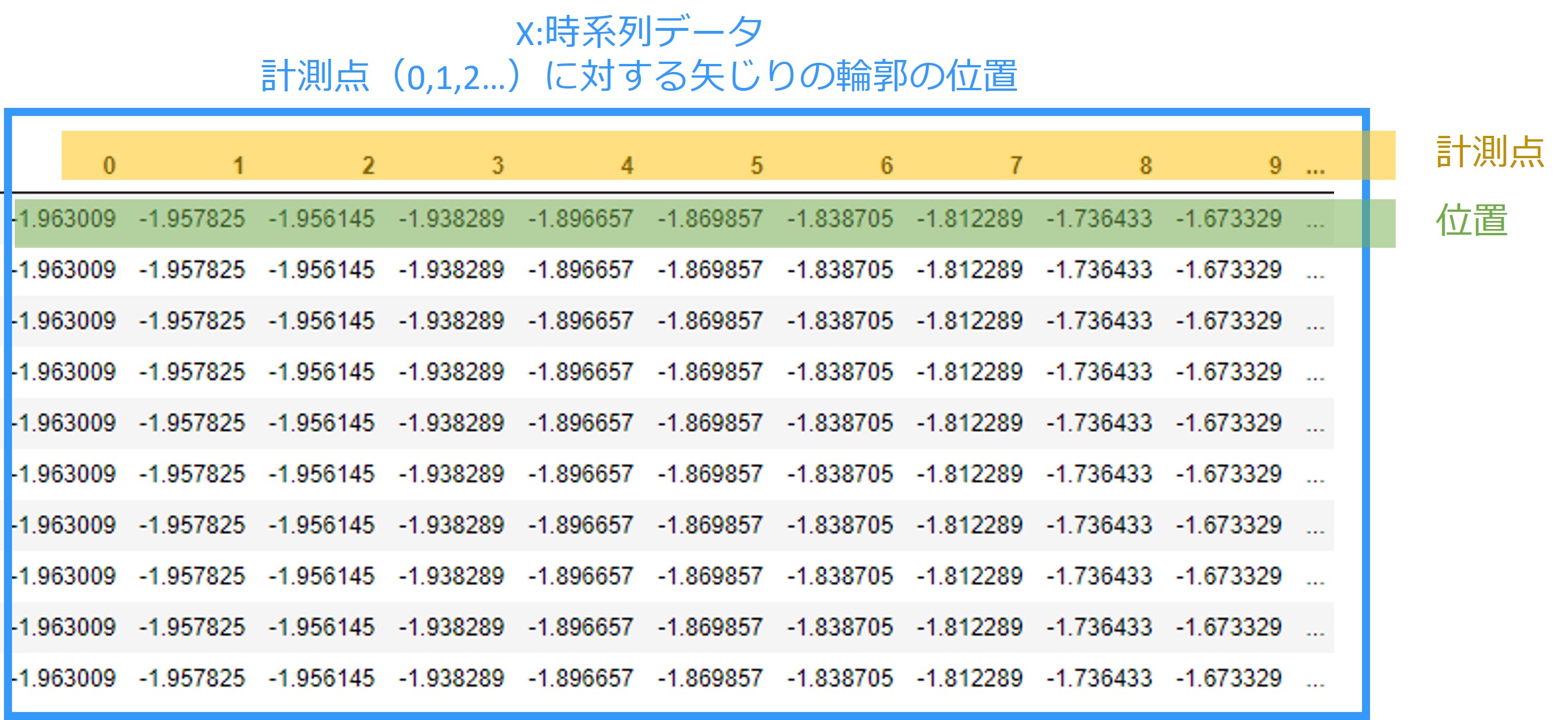
データの出典:http://timeseriesclassification.com/description.php?Dataset=ArrowHead
これは、複数の矢じりの輪郭を角度法(Angle Based Method)という画像処理の手法で計測点と位置の情報に分解して特徴量としています。このデータには、矢じりの種類に関する情報がありません。
予測結果はこのようになります。Kmeans法で、仮にクラスタの数(矢じりの種類の数)を5つと置いたものです。線の色でクラスタを示しています。
データで表すとこのような形になります。
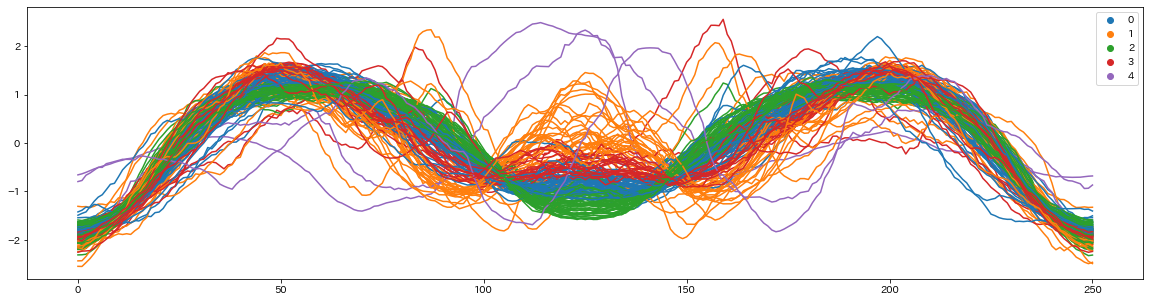
時系列クラスタリング(Time series clustering)は、このように時系列の特徴量のみを使いクラスタリングしていきます。
3.時系列分類(Time series classification)
以下は、時系列分類のデータ例です。
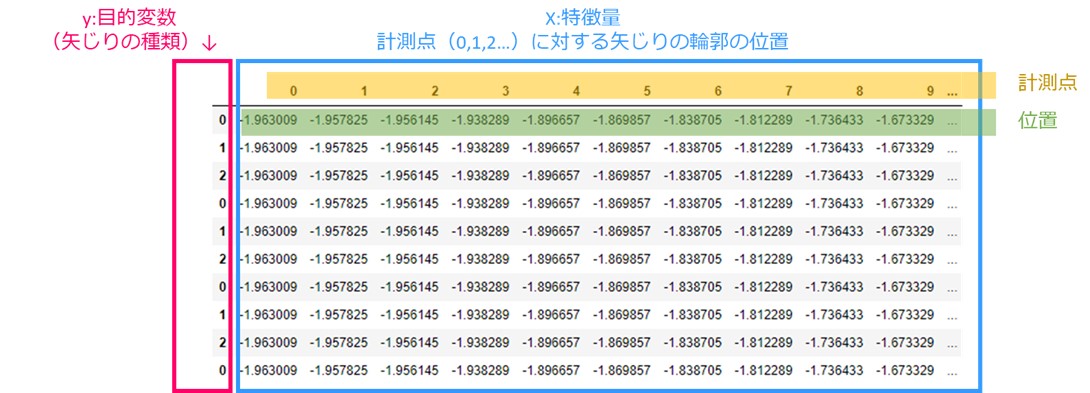
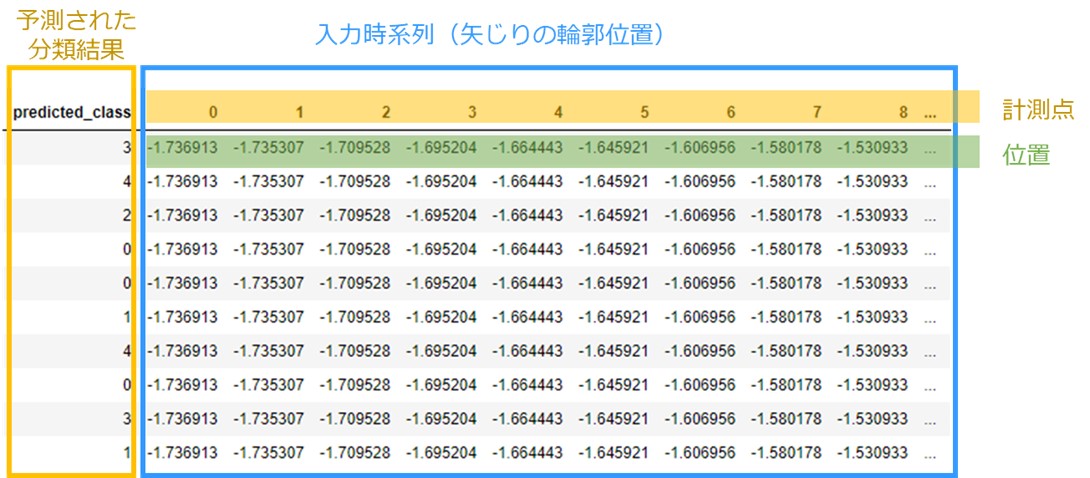
これは、先ほど説明した時系列クラスタリングのデータとほぼ同じものですが、大きな違いは教師データである分類結果y:矢じりの種類があることです。
矢じりは0,1,2の3つの種類が存在しますのでそれを目的変数(Class)としています。
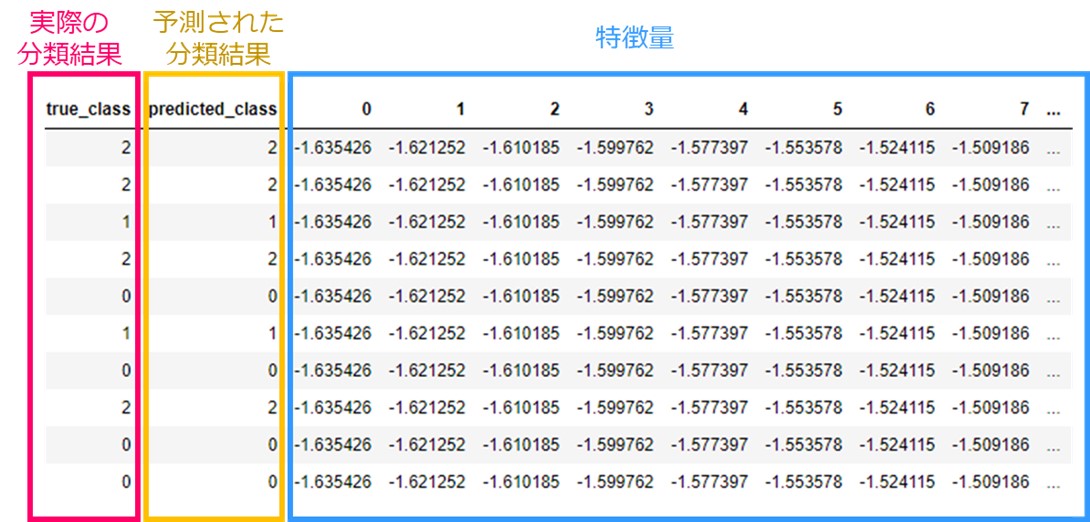
この問題を解くとこのようになります。一本一本の線がそれぞれ輪郭の観測値、予測された矢じりつの種類を色で分けています。

表形式で予測結果を表すとこのような形です。
4.時系列回帰(Time series regression)
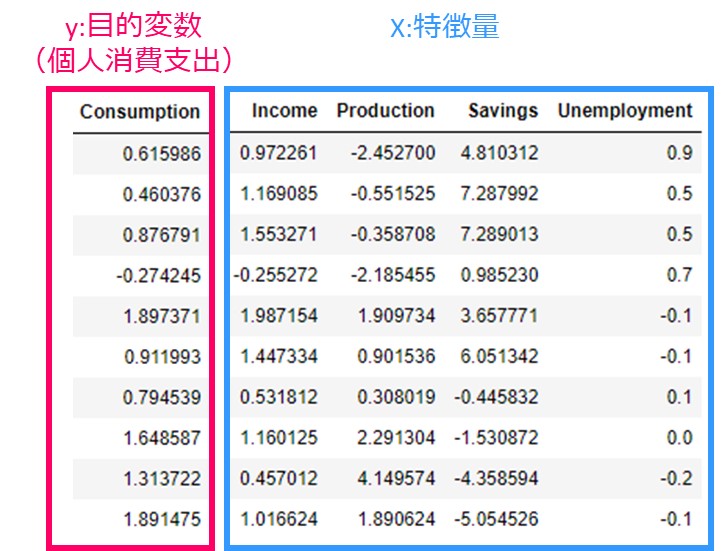
元になるデータは、次のような形をしています。時系列分類と似ていますが、目的変数が連続値であるところが異なります。
1960年から2016年までの米国の四半期ごとの……
- 個人消費支出(Consumption)
- 個人可処分所得(Income)
- 生産量(Production)
- 貯蓄(Savings)
- 失業率(Unemployment)
……が格納されています。
どれを目的変数ととってもいいですが、ここでは個人消費支出(Consumption)を目的変数、それ以外を特徴量としています。
データの出典:https://www.sktime.org/en/stable/api_reference/auto_generated/sktime.datasets.load_uschange.html
出典:Data for “Forecasting: Principles and Practice” (2nd Edition)
このデータを使って時系列回帰をした結果です。青実線が観測値、オレンジ破線が予測値です。
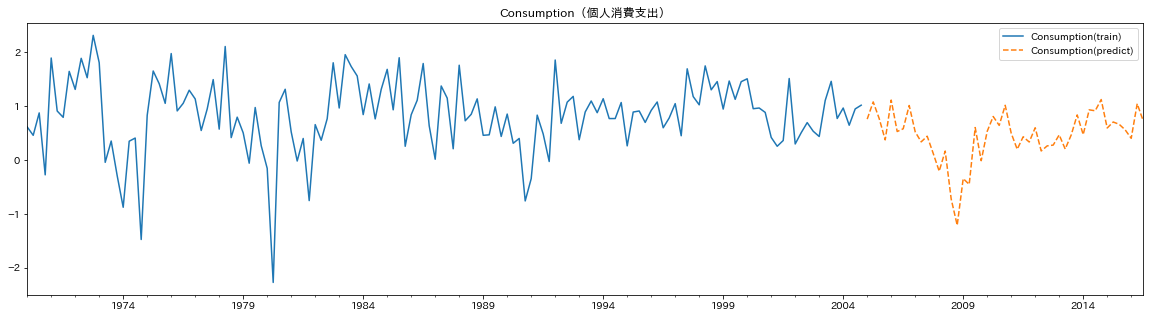
「1.時系列予測」と異なるのは、特徴量を予測に使っているという点です。特徴量をプロットしてみました。
まとめ
今回は、4つの問題(時系列予測・時系列クラスタリング・時系列分類・時系列回帰)がどのようなものなのか、そのイメージを簡単に説明しました。
- 時系列予測
- 時系列クラスタリング
- 時系列分類
- 時系列回帰
次回から、Pythonのsktimeを利用し、具体的にどのように実施していくのかを、例を使いながらステップByステップで説明していきます。
Python ライブラリー「sktime」で学ぶ らくらくビジネス時系列機械学習 Web講座 – 第2回:sktimeのインストール –