
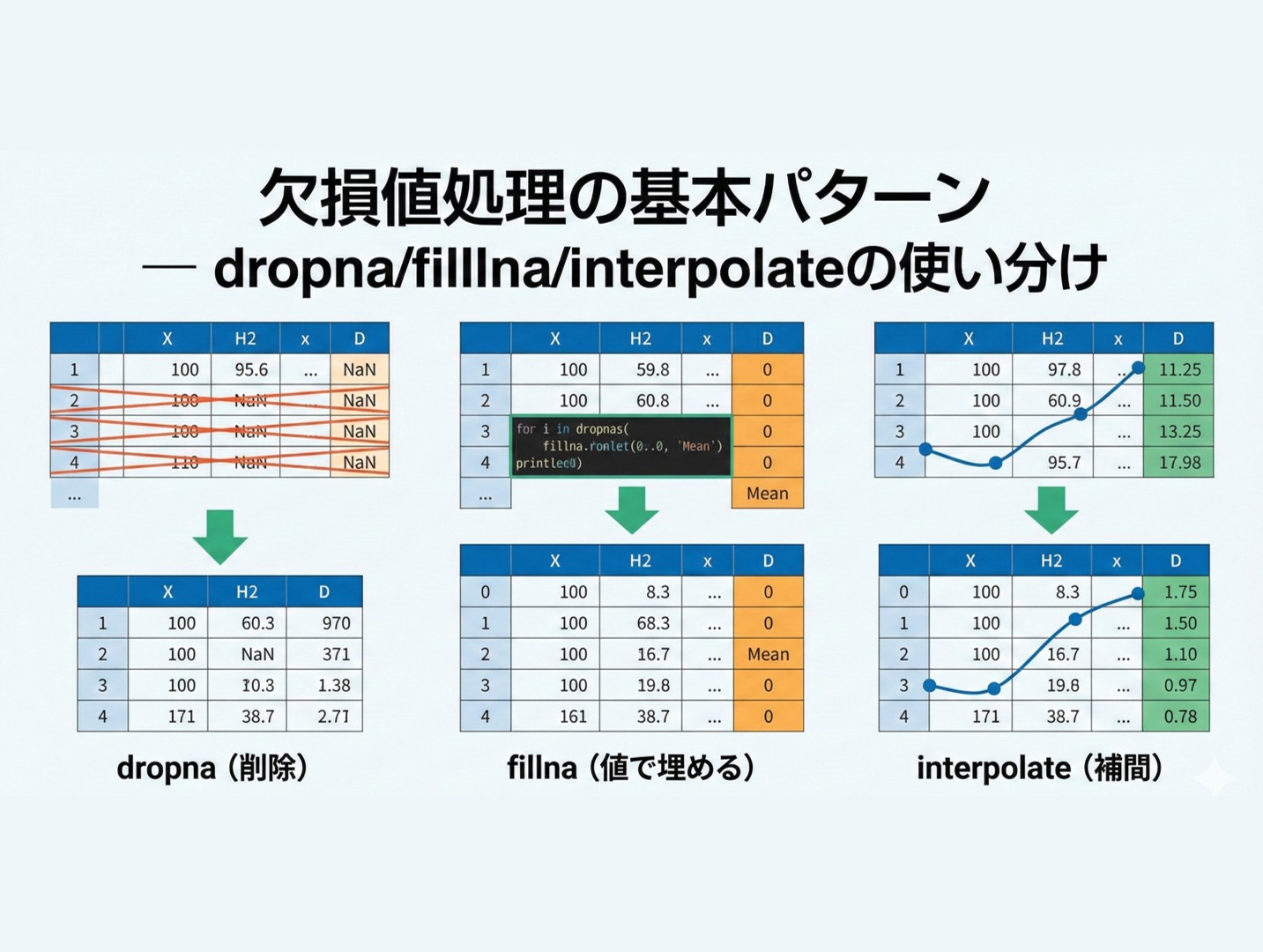
データ分析を始めると、必ず直面するのが 欠損値(NaN) の問題です。
「データが歯抜けになっている」「一部の項目が空欄」といった状況は、実務データでは日常茶飯事です。
欠損値を適切に処理しないと、計算がうまくいかなかったり、分析結果が歪んだりします。
今回は、pandasで欠損値を処理する3つの基本メソッド dropna(), fillna(), interpolate() の使い分けを解説します。
欠損値とは?
欠損値(Missing Value) とは、データが存在しない、または記録されていない状態のことです。
pandasでは、欠損値は NaN(Not a Number)として表現されます。
欠損値が発生する原因は様々です。
| 原因 | 例 |
|---|---|
| 入力ミス・入力漏れ | アンケートの未回答項目 |
| システムエラー | センサーの故障による計測失敗 |
| データの結合 | 異なるテーブルをマージした際の不一致 |
| 意図的な非公開 |
欠損値の処理方法は、「なぜ欠損しているか」によって変わります。
今回は、3つの基本的な処理方法と、その使い分け方を紹介します。
サンプルデータの準備
サンプルデータとして、架空の気温観測データを使います。
センサーの不具合や通信エラーで一部のデータが欠損しているという設定です。
以下のコードでサンプルデータを作成します。
import pandas as pd
import numpy as np
# 欠損値を含むサンプルデータを作成
data = {
'日付': pd.date_range('2024-01-01', periods=10, freq='D'),
'気温': [5.2, 6.1, np.nan, 7.5, np.nan, np.nan, 9.2, 10.1, 8.5, np.nan],
'湿度': [45, np.nan, 52, 48, 55, np.nan, 60, 58, np.nan, 62],
'風速': [3.2, 2.8, np.nan, np.nan, 4.1, 3.5, np.nan, 2.9, 3.3, 3.0],
'天気': ['晴れ', '曇り', '雨', np.nan, '晴れ', '曇り', np.nan, '晴れ', '晴れ', '曇り']
}
df = pd.DataFrame(data)
print(df)
以下、実行結果です。
日付 気温 湿度 風速 天気 0 2024-01-01 5.2 45.0 3.2 晴れ 1 2024-01-02 6.1 NaN 2.8 曇り 2 2024-01-03 NaN 52.0 NaN 雨 3 2024-01-04 7.5 48.0 NaN NaN 4 2024-01-05 NaN 55.0 4.1 晴れ 5 2024-01-06 NaN NaN 3.5 曇り 6 2024-01-07 9.2 60.0 NaN NaN 7 2024-01-08 10.1 58.0 2.9 晴れ 8 2024-01-09 8.5 NaN 3.3 晴れ 9 2024-01-10 NaN 62.0 3.0 曇り
実行すると、10日分のデータが表示されます。NaN と表示されている箇所が欠損値です。
気温、湿度、風速、天気の各列に欠損値が含まれていることがわかります。
このデータを使って、欠損値処理の方法を学んでいきましょう。
欠損値の確認:まずは現状把握から
欠損値があるかどうかを確認する
処理を始める前に、まずデータにどれくらいの欠損値があるかを把握することが重要です。
isnull() メソッドを使うと、各セルが欠損値かどうかを確認できます。
以下、コードです。
# 各セルが欠損値かどうかを確認(True=欠損) print(df.isnull())
以下、実行結果です。
日付 気温 湿度 風速 天気 0 False False False False False 1 False False True False False 2 False True False True False 3 False False False True True 4 False True False False False 5 False True True False False 6 False False False True True 7 False False False False False 8 False False True False False 9 False True False False False
欠損値の位置が True で表示されます。しかし、大きなデータでは全体を見るのは大変です。
列ごとの欠損値の数を確認する
実務では、よく列ごとの欠損値の数を集計し確認します。
以下、コードです。
# 列ごとの欠損値の数を確認 print(df.isnull().sum())
実行すると、以下のような結果が表示されます。
日付 0 気温 4 湿度 3 風速 3 天気 2 dtype: int64
気温は4件、湿度と風速は3件、天気は2件の欠損があることがわかります。
この情報をもとに、どの列をどのように処理するかを決めていきます。
欠損値の割合を確認する
欠損値の「数」だけでなく「割合」も重要です。
10件中4件が欠損なら40%ですが、1000件中4件なら0.4%です。処理方針は割合によって変わります。
以下、コードです。
# 欠損値の割合を計算(パーセント表示)
missing_ratio = (df.isnull().sum() / len(df)) * 100
print("欠損値の割合(%):")
print(missing_ratio.round(1))
実行すると、各列の欠損率がパーセントで表示されます。
欠損値の割合(%): 日付 0.0 気温 40.0 湿度 30.0 風速 30.0 天気 20.0 dtype: float64
一般的に、欠損率が5%未満なら削除、5〜30%なら補完、30%以上なら列自体の削除を検討することが多いです(あくまで目安)。
info()で全体像を把握する
info() メソッドを使うと、欠損値を含むデータの全体像を一度に確認できます。
# データの概要を表示 df.info()
実行すると、各列のデータ型と「非欠損値の数(non-null count)」が表示されます。
<class 'pandas.core.frame.DataFrame'> RangeIndex: 10 entries, 0 to 9 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 日付 10 non-null datetime64[ns] 1 気温 6 non-null float64 2 湿度 7 non-null float64 3 風速 7 non-null float64 4 天気 8 non-null object dtypes: datetime64[ns](1), float64(3), object(1) memory usage: 532.0+ bytes
たとえば、「10 non-null」と表示されていれば、10件欠損していることがわかります。
dropna():欠損値を含む行・列を削除
dropna()とは?
dropna() は、欠損値を含む行または列を削除するメソッドです。
「欠損値があるデータは信頼できないから除外する」という考え方に基づきます。
欠損値を含む行を削除する
最もシンプルな使い方は、欠損値を含む行をすべて削除することです。
# 欠損値を含む行を削除
df_dropped = df.dropna()
print(f"削除前: {len(df)}行 → 削除後: {len(df_dropped)}行")
print()
print(df_dropped)
実行すると、10行から2行に減ったことがわかります。
削除前: 10行 → 削除後: 2行
日付 気温 湿度 風速 天気
0 2024-01-01 5.2 45.0 3.2 晴れ
7 2024-01-08 10.1 58.0 2.9 晴れ
欠損値が1つでもある行はすべて削除されるため、データが大幅に減少することがあります。
これがdropna()の最大のデメリットです。
特定の列の欠損だけを対象にする
すべての列ではなく、特定の列に欠損がある行だけを削除したい場合は、subset 引数を使います。
# 「気温」列に欠損がある行だけを削除
df_dropped_temp = df.dropna(subset=['気温'])
print(f"削除前: {len(df)}行 → 削除後: {len(df_dropped_temp)}行")
print()
print(df_dropped_temp)
実行すると、気温が欠損している4行だけが削除され、6行が残ります。
削除前: 10行 → 削除後: 6行
日付 気温 湿度 風速 天気
0 2024-01-01 5.2 45.0 3.2 晴れ
1 2024-01-02 6.1 NaN 2.8 曇り
3 2024-01-04 7.5 48.0 NaN NaN
6 2024-01-07 9.2 60.0 NaN NaN
7 2024-01-08 10.1 58.0 2.9 晴れ
8 2024-01-09 8.5 NaN 3.3 晴れ
分析に必須の列だけを指定することで、データの損失を最小限に抑えられます。
「すべて欠損」の行だけを削除する
how 引数を使うと、削除の条件を変更できます。how='all' を指定すると、「すべての値が欠損している行」だけを削除します。
以下、コードです。
# すべての値が欠損している行だけを削除
df_dropped_all = df.dropna(how='all')
print(
f"削除された行数: "
f"{len(df) - len(df_dropped_all)}"
)
実行すると、削除された行数が表示されます。
削除された行数: 0
このサンプルデータでは「すべて欠損」の行はないため、削除される行は0です。
データ入力ミスで完全に空の行ができてしまった場合に便利です。
欠損値を含む列を削除する
行ではなく列を削除したい場合は、axis=1 を指定します。
以下、コードです。
# 欠損値を含む列を削除
df_dropped_cols = df.dropna(axis=1)
print(
"残った列:",
df_dropped_cols.columns.tolist()
)
実行すると、欠損値がない「日付」列だけが残ります。
残った列: ['日付']
欠損が多すぎて使い物にならない列を除外する際に使います。
dropna()の使いどころ
dropna()は以下のような場面で使います。
| 場面 | 理由 |
|---|---|
| 欠損率が非常に低い(5%未満) | 削除してもデータ量への影響が小さい |
| 欠損がランダムに発生している | 削除しても偏りが生じにくい |
| 分析に必須のデータが欠損 | 不完全なデータでは分析できない |
| 欠損値の補完が難しい |
fillna():欠損値を特定の値で埋める
fillna()とは?
fillna() は、欠損値を指定した値で埋める(補完する)メソッドです。
データを削除せずに、欠損部分を推定値や代表値で置き換えます。
固定値で埋める
最もシンプルな使い方は、すべての欠損値を同じ値で埋めることです。
以下、コードです。
# すべての欠損値を0で埋める df_filled_zero = df.fillna(0) print(df_filled_zero)
実行すると、すべてのNaNが0に置き換わります。
日付 気温 湿度 風速 天気 0 2024-01-01 5.2 45.0 3.2 晴れ 1 2024-01-02 6.1 0.0 2.8 曇り 2 2024-01-03 0.0 52.0 0.0 雨 3 2024-01-04 7.5 48.0 0.0 0 4 2024-01-05 0.0 55.0 4.1 晴れ 5 2024-01-06 0.0 0.0 3.5 曇り 6 2024-01-07 9.2 60.0 0.0 0 7 2024-01-08 10.1 58.0 2.9 晴れ 8 2024-01-09 8.5 0.0 3.3 晴れ 9 2024-01-10 0.0 62.0 3.0 曇り
ただし、気温や湿度を0で埋めるのは現実的ではありません。
0は「欠損」ではなく「0という値」を意味してしまうからです。
列ごとに異なる値で埋める
列ごとに適切な値で埋めるには、辞書形式で指定します。
以下、コードです。
# 列ごとに異なる値で埋める
fill_values = {
'気温': 7.0, # 適当な推定値
'湿度': 50, # 適当な推定値
'風速': 3.0, # 適当な推定値
'天気': '不明' # カテゴリ変数は「不明」で埋める
}
df_filled_custom = df.fillna(fill_values)
print(df_filled_custom)
実行すると、各列が指定した値で埋められます。
日付 気温 湿度 風速 天気 0 2024-01-01 5.2 45.0 3.2 晴れ 1 2024-01-02 6.1 50.0 2.8 曇り 2 2024-01-03 7.0 52.0 3.0 雨 3 2024-01-04 7.5 48.0 3.0 不明 4 2024-01-05 7.0 55.0 4.1 晴れ 5 2024-01-06 7.0 50.0 3.5 曇り 6 2024-01-07 9.2 60.0 3.0 不明 7 2024-01-08 10.1 58.0 2.9 晴れ 8 2024-01-09 8.5 50.0 3.3 晴れ 9 2024-01-10 7.0 62.0 3.0 曇り
カテゴリ変数(天気)を「不明」で埋めるのは、欠損を明示的に表現する良い方法です。
平均値で埋める
数値データの場合、その列の平均値で埋めるのが一般的な方法です。
以下、コードです。
# 気温の欠損値を平均値で埋める
temp_mean = df['気温'].mean()
print(f"気温の平均値: {temp_mean:.2f}℃")
df_filled_mean = df.copy()
df_filled_mean['気温'] = df['気温'].fillna(temp_mean)
print()
print(df_filled_mean[['日付', '気温']])
実行すると、気温の欠損値が平均値(約7.77℃)で埋められます。
気温の平均値: 7.77℃
日付 気温
0 2024-01-01 5.200000
1 2024-01-02 6.100000
2 2024-01-03 7.766667
3 2024-01-04 7.500000
4 2024-01-05 7.766667
5 2024-01-06 7.766667
6 2024-01-07 9.200000
7 2024-01-08 10.100000
8 2024-01-09 8.500000
9 2024-01-10 7.766667
平均値で埋めると、データ全体の平均は変わりませんが、分散(ばらつき)は小さくなる点に注意が必要です。
中央値で埋める
外れ値がある場合は、平均値より中央値の方が適切なことがあります。
以下、コードです。
# 気温の欠損値を中央値で埋める
temp_median = df['気温'].median()
print(f"気温の中央値: {temp_median}℃")
df_filled_median = df.copy()
df_filled_median['気温'] = df['気温'].fillna(temp_median)
print()
print(df_filled_median[['日付', '気温']])
実行すると、中央値で埋められます。
気温の中央値: 8.0℃
日付 気温
0 2024-01-01 5.2
1 2024-01-02 6.1
2 2024-01-03 8.0
3 2024-01-04 7.5
4 2024-01-05 8.0
5 2024-01-06 8.0
6 2024-01-07 9.2
7 2024-01-08 10.1
8 2024-01-09 8.5
9 2024-01-10 8.0
平均値は外れ値の影響を受けやすいですが、中央値は外れ値に対して頑健(ロバスト)です。
最頻値で埋める(カテゴリ変数向け)
カテゴリ変数(文字列データ)の場合は、最も頻繁に出現する値(最頻値)で埋めることがあります。
以下、コードです。
# 天気の最頻値を確認
weather_mode = df['天気'].mode()[0] # mode()は複数返す可能性があるので[0]で最初を取得
print(f"天気の最頻値: {weather_mode}")
df_filled_mode = df.copy()
df_filled_mode['天気'] = df['天気'].fillna(weather_mode)
print()
print(df_filled_mode[['日付', '天気']])
実行すると、天気の欠損値が最頻値(「晴れ」)で埋められます。
天気の最頻値: 晴れ
日付 天気
0 2024-01-01 晴れ
1 2024-01-02 曇り
2 2024-01-03 雨
3 2024-01-04 晴れ
4 2024-01-05 晴れ
5 2024-01-06 曇り
6 2024-01-07 晴れ
7 2024-01-08 晴れ
8 2024-01-09 晴れ
9 2024-01-10 曇り
ただし、この方法は「晴れの日が増える」という偏りを生むため、注意が必要です。
前の値で埋める(前方補完)
時系列データでは、直前の値で埋める方法がよく使われます。
以下、コードです。
# 前の値で埋める(前方補完) df_ffill = df.copy() df_ffill['気温'] = df['気温'].ffill() print(df_ffill[['日付', '気温']])
実行すると、欠損値が直前の値で埋められます。
日付 気温 0 2024-01-01 5.2 1 2024-01-02 6.1 2 2024-01-03 6.1 3 2024-01-04 7.5 4 2024-01-05 7.5 5 2024-01-06 7.5 6 2024-01-07 9.2 7 2024-01-08 10.1 8 2024-01-09 8.5 9 2024-01-10 8.5
たとえば、3日目のNaNは2日目の6.1で埋められます。
「急激な変化は少ない」という仮定に基づく方法で、センサーデータなどでよく使われます。
後の値で埋める(後方補完)
逆に、直後の値で埋めることもできます。
# 後の値で埋める(後方補完) df_bfill = df.copy() df_bfill['気温'] = df['気温'].bfill() print(df_bfill[['日付', '気温']])
実行すると、欠損値が直後の値で埋められます。
日付 気温 0 2024-01-01 5.2 1 2024-01-02 6.1 2 2024-01-03 7.5 3 2024-01-04 7.5 4 2024-01-05 9.2 5 2024-01-06 9.2 6 2024-01-07 9.2 7 2024-01-08 10.1 8 2024-01-09 8.5 9 2024-01-10 NaN
先頭に欠損がある場合に、後の値で埋めたい場合に使います。
interpolate():欠損値を補間する
interpolate()とは?
interpolate() は、欠損値を前後のデータから「推測」して埋めるメソッドです。
fillna()が固定値や代表値で埋めるのに対し、interpolate()はデータの傾向を考慮した補間を行います。
線形補間の基本
最も基本的な補間方法は「線形補間」です。
前後の値を直線で結び、その中間点を推定します。
以下、コードです。
# 線形補間 df_interp = df.copy() df_interp['気温'] = df['気温'].interpolate(method='linear') print(df_interp[['日付', '気温']])
実行すると、欠損値が前後の値から推定された値で埋められます。
日付 気温 0 2024-01-01 5.200000 1 2024-01-02 6.100000 2 2024-01-03 6.800000 3 2024-01-04 7.500000 4 2024-01-05 8.066667 5 2024-01-06 8.633333 6 2024-01-07 9.200000 7 2024-01-08 10.100000 8 2024-01-09 8.500000 9 2024-01-10 8.500000
たとえば、2024-01-02が6.1℃、2024-01-04が7.5℃の場合、2024-01-03は中間の6.8℃と推定されます。
補間の仕組みを可視化する
線形補間の仕組みをグラフで確認してみましょう。
以下、コードです。
import matplotlib.pyplot as plt
# 元データと補間後データを比較
fig, ax = plt.subplots(figsize=(8, 5))
# 補間後のデータ(線グラフ)
ax.plot(
df_interp['日付'],
df_interp['気温'],
marker='o',
linestyle='-',
label='Interpolated',
color='blue'
)
# 元データ(欠損していない点だけ)
original = df[df['気温'].notna()]
ax.scatter(
original['日付'],
original['気温'],
color='red',
s=100,
zorder=5,
label='Original'
)
ax.set_xlabel('Date')
ax.set_ylabel('Temperature (℃)')
ax.set_title('Linear Interpolation Example')
ax.legend()
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
実行すると、赤い点が元のデータ、青い線が補間後のデータを示すグラフが表示されます。
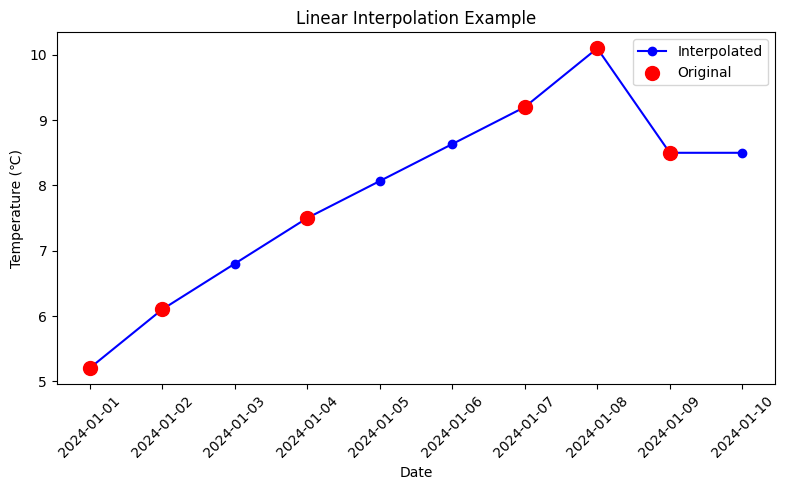
欠損値が前後の点を滑らかにつなぐ位置に補間されていることがわかります。
時系列データ向けの補間
時系列データでは、時間間隔を考慮した補間が可能です。
以下、コードです。
# 時間ベースの補間(インデックスを日付に設定)
df_time = df.copy()
df_time = df_time.set_index('日付')
df_time['気温'] = df_time['気温'].interpolate(method='time')
print(df_time['気温'])
実行すると、日付の間隔を考慮した補間が行われます。
日付 2024-01-01 5.200000 2024-01-02 6.100000 2024-01-03 6.800000 2024-01-04 7.500000 2024-01-05 8.066667 2024-01-06 8.633333 2024-01-07 9.200000 2024-01-08 10.100000 2024-01-09 8.500000 2024-01-10 8.500000 Name: 気温, dtype: float64
等間隔のデータなら線形補間と同じ結果になりますが、不等間隔のデータでは時間を考慮した正確な補間ができます。
多項式補間
より滑らかな補間を行いたい場合は、多項式補間を使います。
# 2次多項式(放物線)で補間
df_poly = df.copy()
df_poly['気温'] = df['気温'].interpolate(
method='polynomial',
order=2
)
print(df_poly[['日付', '気温']].round(2))
実行すると、2次多項式(放物線)による補間が行われます。
日付 気温 0 2024-01-01 5.20 1 2024-01-02 6.10 2 2024-01-03 6.87 3 2024-01-04 7.50 4 2024-01-05 7.97 5 2024-01-06 8.38 6 2024-01-07 9.20 7 2024-01-08 10.10 8 2024-01-09 8.50 9 2024-01-10 NaN
直線補間より滑らかな変化を表現できます。
欠損値の種類と処理方法の選択
欠損値の3つのタイプ
欠損値は、発生メカニズムによって3種類に分類されます。適切な処理方法を選ぶために、この分類を理解しておきましょう。
| 特徴 | 例 | 代表的な処理方法 | |
|---|---|---|---|
| MCAR Missing Completely At Random (完全にランダムな欠損) | 欠損がどの変数とも無関係に発生する | アンケートの回答を誤って消去してしまった | dropna() で削除しても問題になりにくい |
| MAR Missing At Random (条件付きランダムな欠損) | 欠損が他の変数に依存して発生する | 高齢者ほど収入を回答しない傾向がある | 他の変数を使った補完(回帰補完、多重代入など)が有効 |
| MNAR Missing Not At Random (ランダムでない欠損) | 欠損が欠損値そのものに依存して発生する | 高収入の人ほど収入を回答しない |
実行すると、3種類の欠損値とその特徴が表示されます。
実務では「なぜ欠損しているか」を考え、適切な処理方法を選ぶことが重要です。
処理方法の選択ガイド
| 手法 | 使う場面・判断基準 | 欠損メカニズムとの対応 |
|---|---|---|
dropna() |
・欠損率が低い(5%未満) ・データ量に余裕がある ・欠損値の補完が困難、または不適切 | MCAR の場合にのみ基本的に安全 MAR / MNAR ではバイアスが生じやすい |
fillna() |
・カテゴリ変数の欠損(「不明」などで埋める) ・明確なデフォルト値がある(0、平均値など) ・時系列データで直前/直後の値が妥当(ffill / bfill) ・欠損率がやや高い(5〜30%) |
MCAR / MAR では条件付きで使用可能 MNAR では意味づけを誤る危険が高い |
interpolate() |
・連続した数値データ ・時系列データで緩やかな変化が期待される ・前後のデータから推定可能 ・線形または多項式的な変化が妥当 | MCAR / MAR(特に時間に依存する MAR)と相性が良い |
実行すると、処理方法の選択ガイドが表示されます。この基準を参考に、データの特性に応じた処理を選びましょう。
まとめ
最後に、この記事で学んだ3つのメソッドを整理します。
| メソッド | 動作 | |
|---|---|---|
dropna() |
欠損行・列を削除 | 欠損率が低く、欠損がランダム(MCAR)な場合 |
fillna() |
固定値で補完 | カテゴリ変数の欠損、平均値・中央値・0 など代表値での補完 |
interpolate() |
推定値で補完 | 時系列データや連続した数値データ |
欠損値処理で最も重要なのは、いきなり埋めないことです。
欠損は単なる「穴」ではなく、データが失われた理由そのものが情報になっている場合があります。
そのため、次の順序で考えるのが基本です。
- STEP 1:欠損値の確認:
df.isnull().sum() - STEP 2:欠損率の計算:
df.isnull().sum() / len(df) * 100 - STEP 3:欠損の原因を考える(MCAR/MAR/MNAR)
- STEP 4:適切な処理方法を選択
- STEP 5:処理後の確認:
df.isnull().sum()
これで、欠損値処理の基本パターンは一通り紹介しました。