
- 問題
- 答え
- 解説
Python コード:
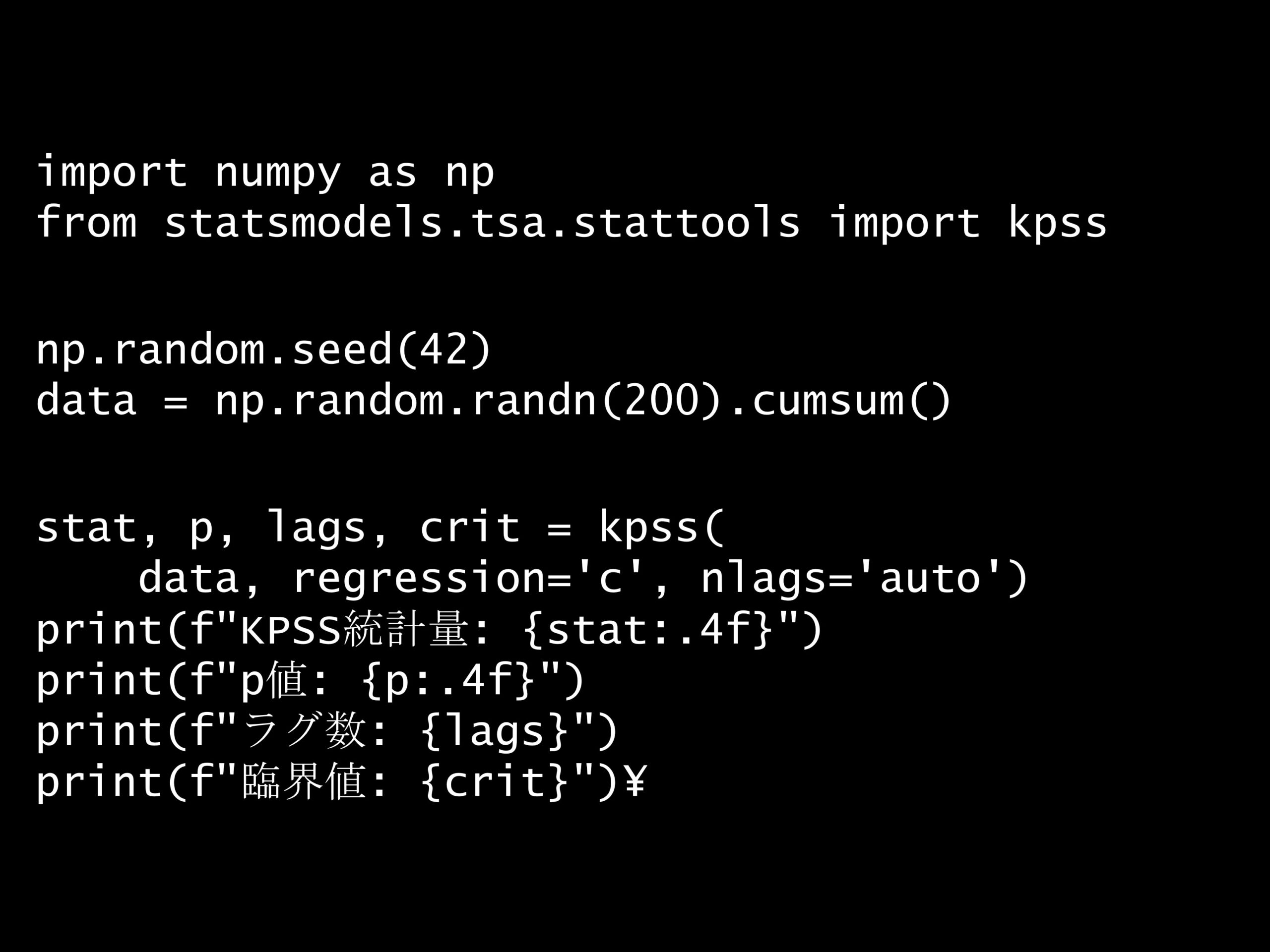
import numpy as np
from statsmodels.tsa.stattools import kpss
np.random.seed(42)
data = np.random.randn(200).cumsum()
stat, p, lags, crit = kpss(
data, regression='c', nlags='auto')
print(f"KPSS統計量: {stat:.4f}")
print(f"p値: {p:.4f}")
print(f"ラグ数: {lags}")
print(f"臨界値: {crit}")
回答の選択肢:
(A) データは非定常である
(B) データは定常である
(C) データに季節性がある
(D) データの平均が0である
KPSS統計量: 0.7001
p値: 0.0135
ラグ数: 9
臨界値: {'10%': 0.347, '5%': 0.463, '2.5%': 0.574, '1%': 0.739}
正解: (B)
KPSS検定の帰無仮説は「データは定常である」です。今回の結果ではp値 = 0.0135で、有意水準5%で帰無仮説が棄却されるため、このデータは非定常であると判断されます。実際、データはcumsum()(累積和)で生成したランダムウォークであり、非定常であることと整合しています。
回答の選択肢:
(A) データは非定常である
(B) データは定常である
(C) データに季節性がある
(D) データの平均が0である
- コードの解説
-
このコードは、時系列データが定常であるかどうかをKPSS検定で判定しています。
import numpy as np from statsmodels.tsa.stattools import kpss np.random.seed(42) data = np.random.randn(200).cumsum() stat, p, lags, crit = kpss( data, regression='c', nlags='auto') print(f"KPSS統計量: {stat:.4f}") print(f"p値: {p:.4f}") print(f"ラグ数: {lags}") print(f"臨界値: {crit}")簡単に説明します。
ライブラリのインポート
numpy:数値計算を行うためのライブラリ。ここでは乱数生成に使用しています。statsmodels.tsa.stattools.kpss:KPSS検定(Kwiatkowski–Phillips–Schmidt–Shin検定)を実行する関数です。
データの生成
np.random.seed(42):乱数のシードを固定し、結果を再現可能にします。np.random.randn(200).cumsum():標準正規分布からの乱数200個の累積和を計算し、ランダムウォークを生成しています。ランダムウォークは代表的な非定常時系列です。
モデルの構築
kpss(data, regression='c', nlags='auto'):KPSS検定を実行します。戻り値は4つです。stat:KPSS検定統計量。この値が臨界値を超えると帰無仮説が棄却されます。p:p値。小さいほど帰無仮説(定常)に反する証拠が強いことを意味します。lags:自己相関の補正に使用されたラグ数。crit:各有意水準に対応する臨界値の辞書。
regression='c':レベル定常性(定数項あり)を検定します。'ct'を指定するとトレンド定常性の検定になります。nlags='auto':ラグ数を自動選択します。
- 選択肢の解説
-
(A) データは非定常である(単位根を持つ) → ×
「データは非定常である」を帰無仮説とするのはADF検定(拡張ディッキー=フラー検定) です。KPSS検定はこれと逆で、「データは定常である」を帰無仮説とします。
(B) データは定常である → ○
正解です。KPSS検定の帰無仮説は「データは定常である」です。p値が有意水準(例:0.05)を下回った場合、帰無仮説が棄却され、データは非定常であると判断されます。
(C) データに季節性がある → ×
KPSS検定は定常性の検定であり、季節性の有無を判定するものではありません。季節性の検出には、コレログラムや時系列分解などの手法を使います。
(D) データの平均が0である → ×
平均が0であるかどうかの検定はt検定などで行います。KPSS検定は、平均や分散などの統計的性質が時間に依存せず一定であるか(定常性)を検定します。
- ADF検定とKPSS検定の違い
-
定常性の検定にはADF検定とKPSS検定がよく使われますが、帰無仮説が逆である点が重要です。
ADF検定 KPSS検定 帰無仮説 非定常(単位根あり) 定常 対立仮説 定常 非定常 棄却 → 結論 定常と判断 非定常と判断 棄却できず → 結論 非定常とは言えない 定常とは言えない 帰無仮説が異なるため、両検定を併用することでより信頼性の高い判断ができます。
- 両検定の併用による判断
-
ADF検定とKPSS検定は、どちらも「この時系列は定常かどうか」を調べるための検定です。ただし、2つは出発点が逆です。
ADF検定は、「この系列は非定常ではないか?」という立場から調べます。一方、KPSS検定は、「この系列は定常ではないか?」という立場から調べます。
そのため、2つを一緒に使うと、1つだけでは分かりにくい系列の性質を、少し丁寧に見ることができます。ただし、検定結果だけで機械的に決めつけるのではなく、どんな特徴を持つ系列なのかを考えるヒントとして使うことが大切です。
Contents
パターン1: ADF棄却 かつ KPSS棄却せず → 定常の可能性が高い
この場合、ADF検定では「非定常とは言いにくい」となり、KPSS検定でも「定常を否定できない」という結果になっています。つまり、2つの検定がそろって、定常である可能性を支持していると考えられます。
この4つの中では、もっとも分かりやすいパターンです。系列の平均やばらつきが大きく変わらず、安定している可能性が高いといえます。
パターン2: ADF棄却せず かつ KPSS棄却 → 非定常の可能性が高い
この場合、ADF検定では「非定常かもしれない」という見方を否定できず、KPSS検定でも「定常とは言いにくい」という結果になっています。つまり、2つの検定がそろって、非定常である可能性を示していると考えられます。
たとえば、ランダムウォークのように、時間がたつにつれて値がふらふらとずれていく系列は、このパターンになりやすいです。
パターン3: ADF棄却 かつ KPSS棄却 → すぐには決めつけず、追加で確認する
このパターンは少しややこしいです。ADF検定では「非定常とは言いにくい」と出ているのに、KPSS検定では「定常とも言いにくい」と出ているからです。
一見すると矛盾しているようですが、これは2つの検定が少し違う見方をしているために起こります。そのため、この結果が出たときは、「どちらかに決める」のではなく、何か別の要因があるのではないかと考えるのが大切です。
たとえば、データがゆっくり右肩上がりになっていると、全体としては安定して見えません。このようなときは、トレンドの影響で、そのままでは定常とは言えないことがあります。また、途中で傾向が変わる構造変化がある場合にも、このような結果になることがあります。
ですから、このパターンが出たら、「トレンドがあるのかもしれない」「系列の途中で動き方が変わったのかもしれない」と考えて、グラフを見たり、トレンドを取り除いて調べたりして、もう一度確認します。
パターン4: ADF棄却せず かつ KPSS棄却せず → はっきりしたことが言えない
この場合、ADF検定では非定常をはっきり否定できず、KPSS検定でも定常をはっきり否定できていません。つまり、どちらの検定も決め手を出せていない状態です。
こういうときは、データの数が少なかったり、系列の特徴があいまいだったりする可能性があります。そのため、この結果だけを見て「定常です」「非定常です」と言い切るのは避けたほうがよいです。
- regression パラメータの選び方
-
KPSS検定の
regressionパラメータは、定常性の種類を指定します。regression='c'(レベル定常性)帰無仮説は「データは定数平均の周りで定常である」です。データに確定的なトレンドがないと想定する場合に使います。
regression='ct'(トレンド定常性)帰無仮説は「データは確定的トレンドの周りで定常である」です。データに線形トレンドがあるが、トレンドを除けば定常であるかを検定します。
どちらを選ぶべきかは、データの可視化や分析の目的によって判断します。トレンドの有無が不明な場合は、まず
'c'で検定し、必要に応じて'ct'も試すことが一般的です。