

第5回で、欠損値を「決まった値」で埋める定数補完についてお話ししました。
そこで、age をゼロで埋めると分布が不自然に歪む様子を見ました。
その問題を解決するのが、今回扱う 平均値・中央値・最頻値による補完 です。
これらは「その列のデータ自身が持つ代表値で埋める」という、単変量補完の 王道 ともいえる手法です。
実装はシンプルですが、「いつ平均を使い、いつ中央値を使うか」 や 「データ漏洩をどう防ぐか」 といったことを、適切に押さえ必要があります。
平均・中央値・最頻値とは?
まず、3つの代表値の意味をおさらいしておきます。
| 代表値 | 英語 | 意味 | 主な対象 |
|---|---|---|---|
| 平均値 | mean | すべての値の合計 ÷ 個数 | 数値変数 |
| 中央値 | median | 値を並べたときの真ん中の値 | 数値変数 |
| 最頻値 | mode | 最も頻繁に出現する値 |
補完の基本的な考え方は「欠損箇所を、その列の代表値で埋める」というものです。
たとえば年齢の欠損を、年齢列の中央値(たとえば28歳)で埋める、といった具合です。
平均値 vs 中央値:どちらを使うべきか
数値変数を補完するとき、最初に悩むのが 「平均値と中央値、どちらを使うか」 です。
判断の鍵は 外れ値(outlier) と 分布の歪み(skewness) にあります。
| 推奨 | 理由 | |
|---|---|---|
| 分布がほぼ左右対称(正規分布に近い) | 平均値 | 平均値が分布の中心をよく表す |
| 外れ値が多い/分布が大きく歪んでいる | 中央値 |
実務では、「迷ったら中央値」 という考え方が広く使われます。
現実のデータは正規分布から外れていることが多く、外れ値も珍しくないためです。
ただし、必ず分布を確認してから判断するのがいいでしょう。
サンプルデータと分布の確認
これまで通り、seaborn の Titanic データセットを使います。
まず、補完対象である age と fare の分布を確認しましょう。
以下、コードです。
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# Titanicデータセットの読み込み
df = sns.load_dataset('titanic')
# 平均値と中央値を数値で比較
print(
f"age - 平均: {df['age'].mean():.2f}, "
f"中央値: {df['age'].median():.2f}"
)
print(
f"fare - 平均: {df['fare'].mean():.2f}, "
f"中央値: {df['fare'].median():.2f}"
)
# age と fare の分布を確認
fig, axes = plt.subplots(2, 1, figsize=(8, 10))
axes[0].hist(
df['age'].dropna(), # 欠損値を除外後の age データ
bins=30, # ヒストグラムの棒の数
color='steelblue', edgecolor='black'
)
axes[0].set_title('Age Distribution')
axes[0].set_xlabel('Age')
axes[0].set_ylabel('Frequency')
axes[1].hist(
df['fare'].dropna(), # 欠損値を除外後の fare データ
bins=30, # ヒストグラムの棒の数
color='seagreen', edgecolor='black'
)
axes[1].set_title('Fare Distribution')
axes[1].set_xlabel('Fare')
plt.tight_layout()
plt.show()
以下、実行結果です。
age - 平均: 29.70, 中央値: 28.00 fare - 平均: 32.20, 中央値: 14.45
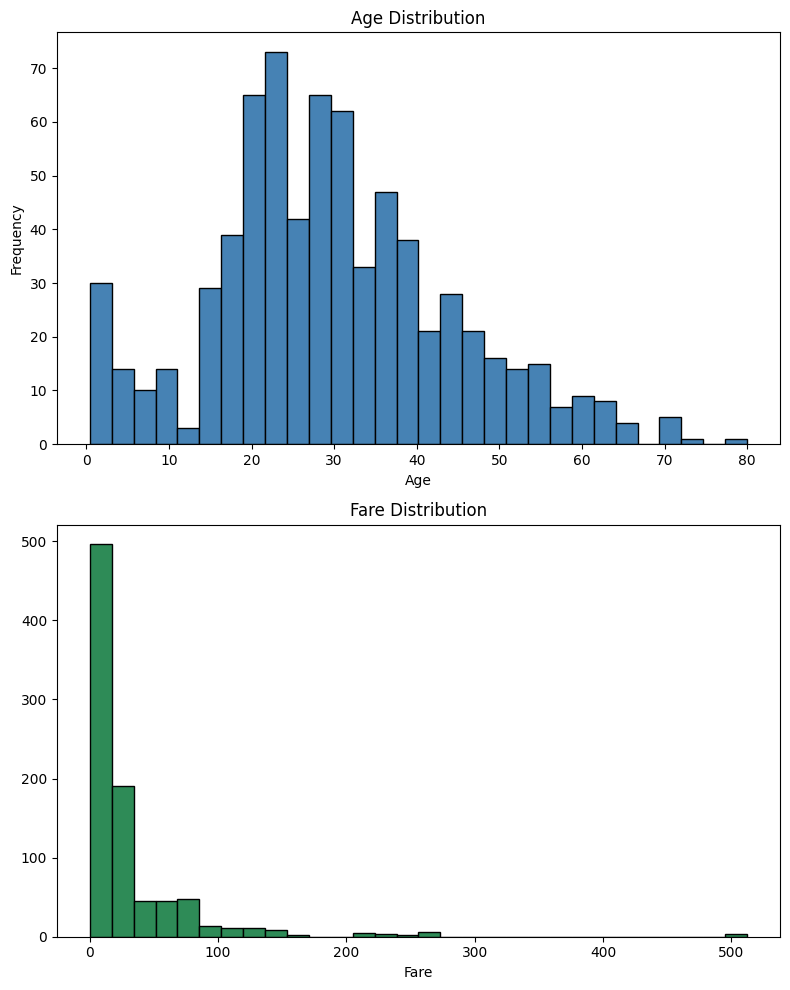
age はおよそ左右対称に近い分布(平均約29.7、中央値約28)なのに対し、fare は 強く右に歪んだ分布(平均約32.2、中央値約14.5)であることがわかります。
fare は平均と中央値が大きく食い違っており、外れ値(高額運賃の乗客)の影響 を受けているサインです。
pandas での中央値補完(データ漏洩に注意)
ここで、シリーズを通して最重要のテーマである データ漏洩(data leakage) を実装レベルで体験します。
まず、間違った例を示します。
全データの中央値で埋めます。
以下、コードです。
from sklearn.model_selection import train_test_split
# 学習用とテスト用に分割
df_train, df_test = train_test_split(
df,
test_size=0.2,
random_state=42
)
# 【間違い】全データ(train+test)の中央値で埋めてしまう
wrong_median = df['age'].median() # ← test も含めて計算している
print(
"全データの中央値(使ってはいけない): "
f"{wrong_median:.2f}"
)
以下、実行結果です。
全データの中央値(使ってはいけない): 28.00
この df['age'].median() は、テストデータも含めた全体 から中央値を計算しています。
これをテストデータの補完に使うと、テストデータの情報が補完値に紛れ込み、モデルの性能を過大評価してしまいます。
これが データ漏洩 です。
次に、正しい例を示します。
学習データの中央値だけを使います。
以下、コードです。
# 【正しい】学習データだけから中央値を計算
median_age = df_train['age'].median()
print(
"学習データの中央値(これを使う): "
f"{median_age:.2f}"
)
# 学習データ・テストデータの両方に「学習データの中央値」を適用
df_train_imputed = df_train.copy()
df_test_imputed = df_test.copy()
df_train_imputed['age'] = (
df_train_imputed['age']
.fillna(median_age)
)
df_test_imputed['age'] = (
df_test_imputed['age']
.fillna(median_age)
)
print(
"学習データの欠損: "
f"{df_train_imputed['age'].isnull().sum()}"
)
print(
"テストデータの欠損: "
f"{df_test_imputed['age'].isnull().sum()}"
)
median_age = df_train['age'].median():学習データだけ から中央値を計算- その値を学習データにもテストデータにも適用する
以下、実行結果です。
学習データの中央値(これを使う): 28.00 学習データの欠損: 0 テストデータの欠損: 0
両方のデータで age の欠損がゼロになります。
ポイントは「テストデータの欠損も、学習データの中央値で埋める」 ことです。
テストデータ自身の中央値は決して使いません。
scikit-learn の SimpleImputer で実装する
第5回で登場した SimpleImputer を使うと、データ漏洩を防ぐ流れが自然に書けます。
strategy を変えるだけで平均・中央値・最頻値を切り替えられます。
以下、コードです。
from sklearn.impute import SimpleImputer
# 中央値で補完するインピュータ
median_imputer = SimpleImputer(strategy='median')
# 学習データで fit_transform(ここで中央値を学習)
df_train_imp = df_train.copy()
df_train_imp['age'] = (
median_imputer.fit_transform(
df_train[['age']]
).ravel()
)
# テストデータには transform のみ(学習データの中央値を適用)
df_test_imp = df_test.copy()
df_test_imp['age'] = (
median_imputer.transform(
df_test[['age']]
).ravel()
)
# 学習された中央値を確認
print(
"SimpleImputer が学習した中央値: "
f"{median_imputer.statistics_[0]:.2f}"
)
print(
"学習データの欠損: "
f"{df_train_imp['age'].isnull().sum()}"
)
print(
"テストデータの欠損: "
f"{df_test_imp['age'].isnull().sum()}"
)
SimpleImputer(strategy='median'):中央値で補完するインピュータfit_transform:学習データから中央値を学び、同時に変換するtransform:テストデータに学習済みの中央値を適用するmedian_imputer.statistics_:インピュータが学習した補完値を確認できる属性
以下、実行結果です。
SimpleImputer が学習した中央値: 28.00 学習データの欠損: 0 テストデータの欠損: 0
statistics_ に学習データの中央値が格納されており、fit_transform と transform の流れだけで 自動的にデータ漏洩が防がれている ことがわかります。
strategy を 'mean' にすれば平均値、'most_frequent' にすれば最頻値補完に切り替わります。
カテゴリ変数の最頻値補完
カテゴリ変数(文字列など)は平均値や中央値が計算できないため、最頻値(most frequent value) で補完するのが基本です。
以下、コードです。
# embarked(乗船港)はカテゴリ変数
print("embarked の値の出現回数:")
print(df_train['embarked'].value_counts())
# 最頻値で補完するインピュータ
mode_imputer = SimpleImputer(strategy='most_frequent')
# 学習データで fit_transform(ここで最頻値を学習)
df_train_cat = df_train.copy()
df_train_cat['embarked'] = (
mode_imputer.fit_transform(
df_train[['embarked']]
).ravel()
)
# テストデータには transform のみ(学習データの最頻値を適用)
df_test_cat = df_test.copy()
df_test_cat['embarked'] = (
mode_imputer.transform(
df_test[['embarked']]
).ravel()
)
print(
"\n学習された最頻値: "
f"{mode_imputer.statistics_[0]}"
)
print(
"補完後の欠損(train): "
f"{df_train_cat['embarked'].isnull().sum()}"
)
value_counts():各カテゴリの出現回数を多い順に表示SimpleImputer(strategy='most_frequent'):最頻値で補完(カテゴリにも数値にも使える)
以下、実行結果です。
embarked の値の出現回数: embarked S 525 C 125 Q 60 Name: count, dtype: int64 学習された最頻値: S 補完後の欠損(train): 0
embarked の最頻値が 'S'(Southampton)であることがわかり、欠損がその値で埋められます。
グループ別の中央値で精度を上げる
ここまでは「列全体の代表値」で補完してきました。
しかし、もっと賢い方法があります。それが グループ別補完 です。
たとえば、fare(運賃)が欠損がある乗客が「3等船室・男性・家族なし」であれば、「列全体の中央値」ではなく「3等船室・男性・家族なしの乗客の中央値」 で補完する、という方法です。
同じ条件の乗客に絞ったほうが、より妥当な推定値になるからです。
以下、コードです。
# fare に欠損のある乗客の属性を確認(例として人工的に1件欠損を作る)
df_demo = df.copy()
# デモのため、ある3等船室・男性・家族なしの乗客の fare を欠損にする
mask = (
(df_demo['pclass'] == 3) &
(df_demo['sex'] == 'male') &
(df_demo['sibsp'] == 0) &
(df_demo['parch'] == 0)
)
target_idx = df_demo[mask].index[0]
df_demo.loc[target_idx, 'fare'] = np.nan
print(f"欠損を作った乗客のインデックス: {target_idx}")
# 【方法A】列全体の中央値
overall_median = df_demo['fare'].median()
print(
"\n方法A: 列全体の中央値 = "
f"{overall_median:.4f}"
)
# 【方法B】同じ属性グループの中央値
group_median = df_demo[
(df_demo['pclass'] == 3) &
(df_demo['sex'] == 'male') &
(df_demo['sibsp'] == 0) &
(df_demo['parch'] == 0)
]['fare'].median()
print(
"方法B: 3等船室・男性・家族なしの中央値 = "
f"{group_median:.4f}"
)
mask:複数条件を&で組み合わせ、特定属性の乗客を抽出- 方法Aは列全体、方法Bは同じ属性グループだけから中央値を計算
以下、実行結果です。
欠損を作った乗客のインデックス: 4 方法A: 列全体の中央値 = 14.4542 方法B: 3等船室・男性・家族なしの中央値 = 7.8958
方法A(列全体の中央値、約14.5)と方法B(3等船室・男性・家族なしの中央値、約7〜8程度)で、補完値が大きく異なることがわかります。
方法Bのほうが、その乗客の実態に近い妥当な値 といえます。
平均値補完の落とし穴:分散が縮小する
平均値・中央値補完には、見落としがちな重要な副作用があります。
それは データの分散(ばらつき)が小さくなる ことです。
すべての欠損を1つの値(平均値)で埋めると、その値の周辺にデータが不自然に集中し、本来あったばらつきが失われます。
これを数値とグラフで確認してみましょう。
以下、コードです。
# age の欠損を平均値で補完
df_mean = df.copy()
mean_age = df_mean['age'].mean()
df_mean['age'] = df_mean['age'].fillna(mean_age)
# 補完前(欠損行を除く)と補完後の標準偏差を比較
std_before = df['age'].dropna().std()
std_after = df_mean['age'].std()
print(
"補完前の標準偏差: "
f"{std_before:.4f}"
)
print(
"補完後の標準偏差: "
f"{std_after:.4f}"
)
print(
"標準偏差の減少率: "
f"{(1 - std_after / std_before) * 100:.2f}%"
)
std():標準偏差(ばらつきの大きさ)を計算- 補完前は欠損行を除いた
age、補完後は平均値で埋めたage
以下、実行結果です。
補完前の標準偏差: 14.5265 補完後の標準偏差: 13.0020 標準偏差の減少率: 10.49%
補完後の標準偏差が補完前より 明らかに小さく なっていることがわかります。
177件の欠損がすべて平均値(約29.7)に置き換わったことで、ばらつきが人工的に減ってしまったのです。
分布を描き確認してみます。
以下、コードです。
fig, axes = plt.subplots(2, 1, figsize=(8, 8))
# 補完前のヒストグラム
axes[0].hist(
df['age'].dropna(),
bins=30,
color='steelblue', edgecolor='black'
)
axes[0].set_title('Before Imputation')
axes[0].set_xlabel('Age')
axes[0].set_ylabel('Frequency')
# 補完後のヒストグラム
axes[1].hist(
df_mean['age'],
bins=30,
color='coral', edgecolor='black'
)
axes[1].set_title('After Mean Imputation')
axes[1].set_xlabel('Age')
plt.tight_layout()
plt.show()
以下、実行結果です。
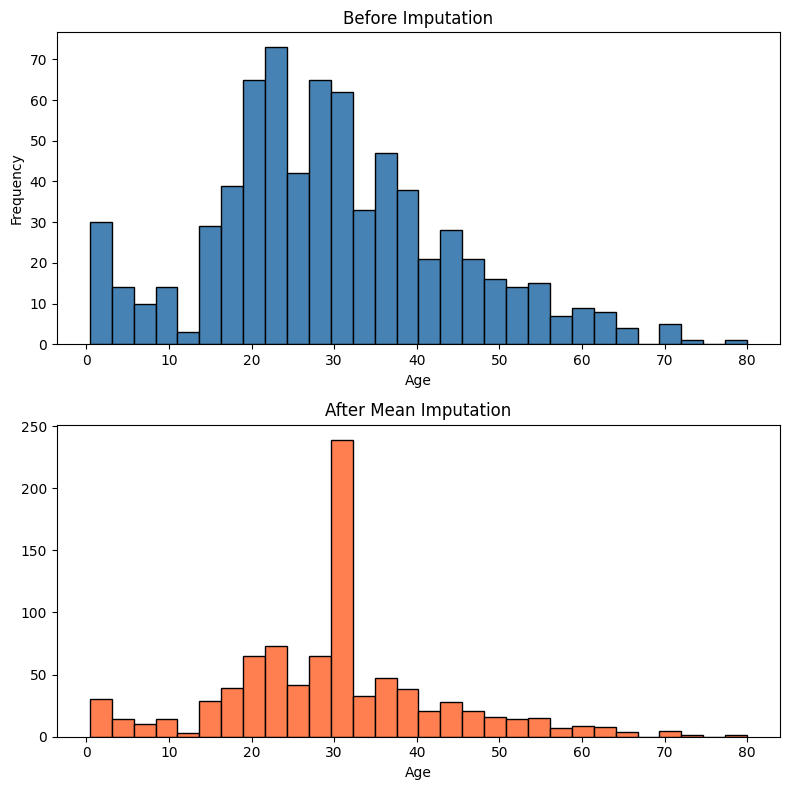
補完後のヒストグラムでは 平均値(約30付近)に異常に高い棒 が出現します。
これは欠損177件すべてがそこに集中した結果です。
第5回の定数補完(ゼロ埋め)ほど極端ではありませんが、やはり 分布の自然さが失われている ことがわかります。
補完手法の比較表
第5回・第6回で扱った単変量補完を整理します。
| 手法 | 対象 | 長所 | 短所 |
|---|---|---|---|
| 定数補完(第5回) | 数値・カテゴリ | 「未回答」を明示できる | 数値では分布を強く歪める |
| 平均値補完 | 数値 | 実装が簡単、正規分布向き | 外れ値に弱い、分散が縮小 |
| 中央値補完 | 数値 | 外れ値に頑健 | 分散が縮小 |
| 最頻値補完 | カテゴリ・数値 | カテゴリに使える | 最頻カテゴリが過大になる |
| グループ別補完 | 数値・カテゴリ | 精度が高い |
まとめ
今回のポイントを振り返りましょう。
- 数値変数は 平均値(正規分布向け)か 中央値(外れ値に頑健)で補完する。迷ったら中央値が安全
- カテゴリ変数は 最頻値 で補完するのが基本
- データ漏洩を防ぐため、補完値は学習データだけから計算し、テストデータにも同じ値を適用する
- scikit-learn の
SimpleImputerを使えば、fit_transform/transformの流れで自然に漏洩を防げる
- グループ別補完 は他の変数の情報を使い、より妥当な推定ができる(多変量補完の入口)
- 平均値・中央値補完は 分散を縮小させる 副作用があり、統計分析にバイアスを生む