

第2回で、TPOTを使う事前準備が終わりました。今回はいよいよ実際にTPOTでAutoMLを体験します。
TPOTは分類と回帰の問題を解くことができます。Jupyter Notebookを使いますので、WindowsもMacも内容は同じです。
今回は分類問題を扱います。
例えば……
- 受注 or 失注
- 継続 or 離反
……などの目的変数Yを分類する問題です。
そのまま、受注予測や離反予測に使えます。
このような予測をするための数理モデルを、TPOTを使い自動で構築してみます。
Contents
データセットの説明
今回はscikit-learnから提供されているサンプルデータセットの、乳がんの診断結果を分類する問題を例に解いてみます。
【今回使用】
scikit-learnから提供されているサンプルデータセット
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_breast_cancer.html#sklearn.datasets.load_breast_cancer
今回使う乳がんの診断結果のデータセットは、カリフォルニア大学アーバイン校から提供されている機械学習用データセットのひとつです。
目的変数Y
胸のしこりの穿刺吸引生検の細胞核の画像を……
- 悪性腫瘍
- 良性腫瘍
……のどちらであるか分類してあります。
目的変数Yは、画像の分類結果良性(=1)と悪性(=0)の2クラス値です。
特徴量(説明変数X)
細胞核の画像を処理して、表にある10個の特徴量(説明変数X)を作り、さらに平均値、標準偏差、最低値を算出し、最終的に30個の特徴量にしています。
| 項目名 | 詳細 |
| radius | 細胞核の中心から外周までの距離 |
| texture | 画像のグレースケールの標準偏差 |
| perimeter | 細胞核周囲の長さ |
| area | 細胞核の面積 |
| smoothness | 細胞核の直径の局所分散値 |
| compactness | perimeter^2/area – 1.0で計算される値 |
| concavity | 輪郭の凹面度の重大度 |
| concave point | 輪郭の凹面部の数 |
| symmetry | 対称性 | fractal dimension | フラクタル次元 |
TPOTは、この30個の特徴量を組み合わせたりし、自動であらたな特徴量を作り出します。
分類問題の解き方
プログラムの流れは次のとおりです。
- 必要なライブラリの読み込み
- データセットの読み込み
- データセットを学習用と検証用に分割する
- TPOTClassifierの設定
- 学習用データセットを使った機械学習モデルの学習
- 検証用データセットを使った予測結果の評価

1.必要なライブラリの読み込み
 機械学習モデルを作るために必要なライブラリ一式を読み込んでおきます。
機械学習モデルを作るために必要なライブラリ一式を読み込んでおきます。
読み込むライブラリは……
- 分類問題を解くためのTPOTClassifierモジュール
- データセットのload_breast_cancer
- データセットを学習用と検証用に分割するtrain_test_split
- 分類の良さを示す指標であるF1スコアを算出するためのf1_scoreモジュール
- モデルの分類状況を表示する混合行列を作成するconfusion_matrixモジュール
- 数値計算モジュールであるNumPy
- データ解析モジュールであるpandas
……です。
以下、コードです。
from tpot import TPOTClassifier from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.metrics import f1_score from sklearn.metrics import confusion_matrix import numpy as np import pandas as pd
以下、実行結果です。
 ※Torchがインストールされていない場合
※Torchがインストールされていない場合
上記のようなWarningメッセージが
でますが、今回は問題ありません。
2.データセットの読み込み
 今回の数理モデルを作るためのデータを読み込みます。
今回の数理モデルを作るためのデータを読み込みます。
- 特徴量(説明変数)であるload_breast_cancer.dataをXに格納
- 目的変数であるload_breast_cancer.targetをyに格納
以下、コードです。
load_breast_cancer = load_breast_cancer(as_frame=True) X = load_breast_cancer.data y = load_breast_cancer.target
TPOTで使える特徴量は数字と欠損値です。文字列は扱えませんので、ダミー変数を作って数値化しておきましょう。今回使うデータセットはすべて数字を使っているので、ダミー変数は作っていません。
特徴量Xとyの中身を少し見てみましょう。
先ずは、特徴量であるXです。
以下、コードです。
X
以下、実行結果です。
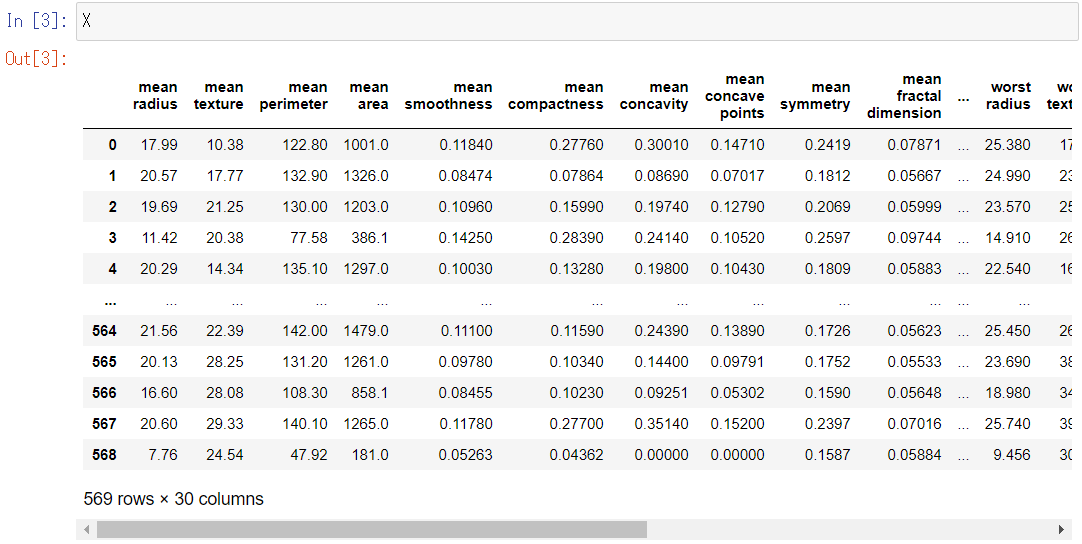
Xの中身は、データセットのセクションで説明したように、30個の特徴量が格納されています。TPOTではこの30個の特徴量を組み合わせたり、自動で統計量を作成したりして、あらたな特徴量を作り出します。
次に、目的変数であるyを見てみます。
以下、コードです。
y
以下、実行結果です。
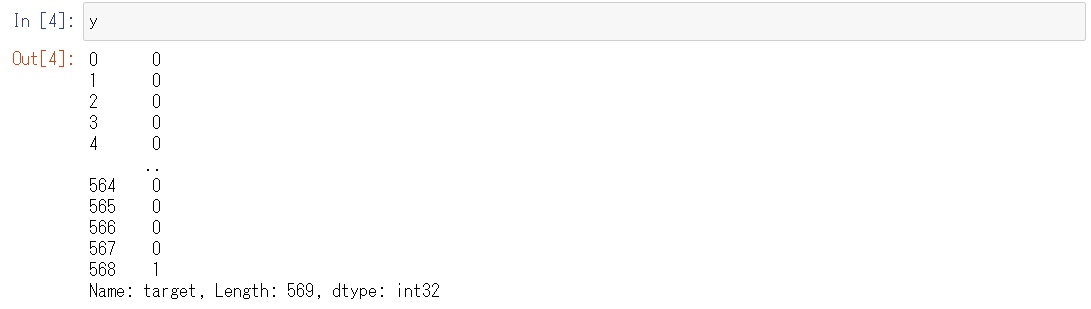
目的変数yの中身は0と1です。
目的変数であるyに格納されている、良性を示す1の数と、悪性を示す0の数をカウントしてみます。
以下、コードです。
print(np.count_nonzero(y == 1)) print(np.count_nonzero(y == 0))
以下、実行結果です。

良性を示す1は357個、悪性を示す0は212個です。
3.データセットを学習用と検証用に分ける
 数理モデルを作成するときは、モデルが一定の性能を満たしているか検証するために、データセットを「学習用のデータセット」と「検証用のデータセット」にわけておきます。
数理モデルを作成するときは、モデルが一定の性能を満たしているか検証するために、データセットを「学習用のデータセット」と「検証用のデータセット」にわけておきます。
- 学習用のデータセット
- 学習用の特徴量をX_trainに格納
- 学習用の目的変数をy_trainに格闘
- 検証用のデータセット
- 検証用の特徴量をX_testに格納
- 検証用の目的変数をy_testに格闘
今回は学習用のデータを75%、検証用のデータを25%に分けます。
以下、コードです。
X_train, X_test, y_train, y_test = train_test_split(X,
y,
train_size=0.75,
test_size=0.25,
random_state=42)
学習用のデータと検証用のデータの数を見てみます。
以下、コードです。
print(len(X_train)) print(len(X_test))
以下、実行結果です。

元のデータセットが569件あるため、実際に約75%と約25%になっていることがわかります。
ここまでが前準備でした。
4.TPOTClassifierの設定
 TPOTClassifierの設定をします。
TPOTClassifierの設定をします。
以下、コードです。
tpot = TPOTClassifier(scoring='f1',
generations=5,
population_size=50)
すべて初期値のままでも動作しますが、scoringパラメータとrandom_stateパラメータの設定をしておくと良いでしょう。
- scoringパラメータでは、分類問題のどの評価指標を用いてモデルを最適化するかを指定することができます。ここの例ではf1スコアを使います。指定できる評価指標は多数ありますので、TPOTのリファレンスページの(http://epistasislab.github.io/tpot/api/)Parameters>scoringの説明文をご覧ください。
- random_stateパラメータは乱数の種です。この値を固定しておくと、毎回同じ結果が得られます。
- generationsパラメータでは特徴量の最適化とパラメータチューニングの最適化を繰り返す回数を指定できます。
- population_sizeではTPOTが使っている遺伝的アルゴリズム内のパラメータです。
generationsパラメータとpopulation_sizeパラメータの数が大きくなれば学習に時間がかかりますので、開発時には小さい数を設定しておくと良いでしょう。ただし、本学習のときは初期値のままをお勧めします。学習時間はかかりますが、初期値が最も良い学習をしてくれます。
TPOTClassifierの設定が終わったらあと少しです。
5.学習用データセットを使った機械学習モデルの学習
 tpot.fit関数を使ってモデルを学習します。
tpot.fit関数を使ってモデルを学習します。
関数の引数として、学習用の特徴量X_trainと目的変数y_trainを指定します。
学習には少し時間がかかります。
以下、コードです。
tpot.fit(X_train, y_train)
以下、実行結果です。

最終的な検討結果(数理モデル)を知りたい場合には、次のコードを入力し実行します。
tpot.fitted_pipeline_
以下、実行結果です。

今回の例ですと、特徴量(説明変数)に「外れ値に頑健な標準化」(RobustScaler)という標準化を行った後に、「ロジスティック回帰」(LogisticRegression)という数理モデルを構築するのが、検討した結果最良であるということになります。
ちなみに、「外れ値に頑健な標準化」(RobustScaler)とは、中央値が0で四分位範囲が1に変換することです。代表的な標準化の方法の1つです。
最終的な検討結果(数理モデル)だけでなく、検討途中のものも詳しくを知りたい場合には、次のコードを入力し実行します。
tpot.evaluated_individuals_
検討内容が詳細に表示されるため、例えばTPOTなどのAutoMLに頼らず自力で数理モデルを作るときの参考になります。ただ、読み解くのは大変です。
そもそも、数理モデルの構築中に進捗状況など、もう少し情報が欲しい(味気が欲しい)と思われた方は、以下のようにverbosityを設定し数理モデルを構築するといいでしょう。
6.検証用データセットを使った予測結果の評価
 最後は学習済みモデルの検証です。
最後は学習済みモデルの検証です。
検証用データセットを学習済みモデルで予測してみて、分類問題の評価指標の一つであるF1スコアを計算します。F1スコアが望む性能を満たせば機械学習モデルの作成は完了です。
以下、コードです。
y_pred = tpot.predict(X_test) f1_score(y_true=y_test, y_pred=y_pred)
以下、実行結果です。

計算されたF1スコアを出力してみると、98%で、評価指標からも非常によく分類できていることがわかります(※数値は状況によって微妙に異なります)。
最後に、TPOTが作成したモデルがどのように予測したのか見てみましょう。
y_predに予測結果が格納されています。
予測結果y_predと正解データであるy_testの結果を比べてみます。
以下、コードです。
pd.DataFrame(data={'y_pred':y_pred,'y_test':y_test})
以下、実行結果です。
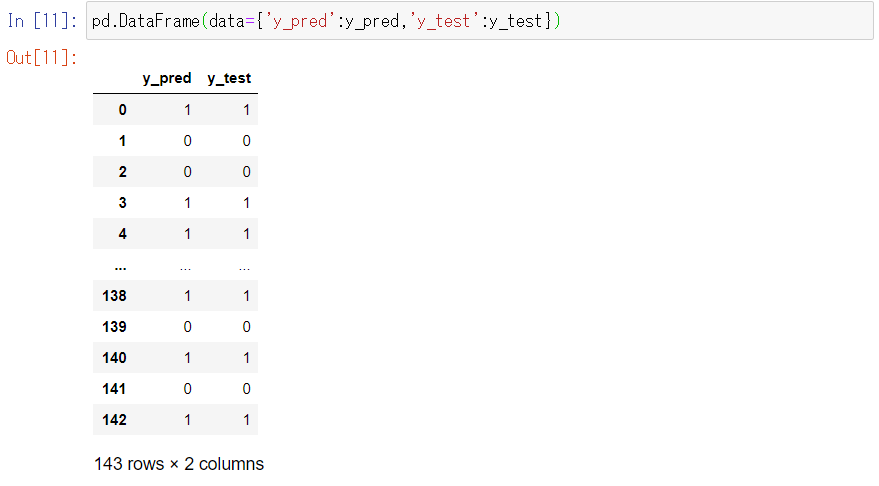
表示される範囲では、予測結果y_predと正解データのy_testがほぼ一致しています。
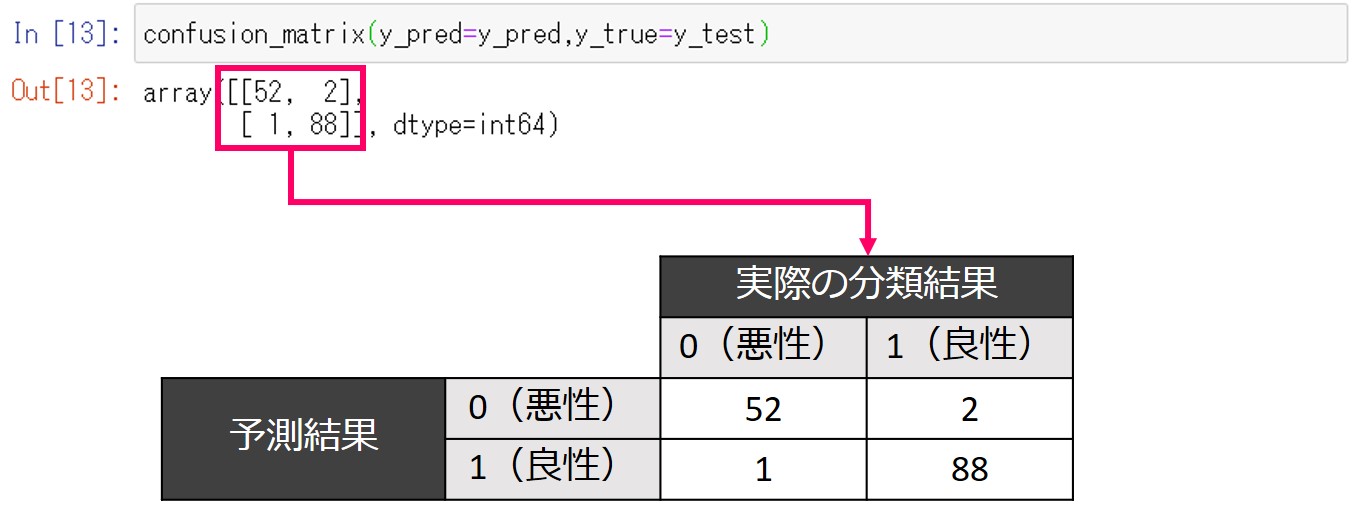
実際にどれだけ一致しているか、混同行列を作成してみてみます。
以下、コードです。
confusion_matrix(y_pred=y_pred,y_true=y_test)
以下、実行結果(※数値は状況によって微妙に異なります)です。
{kind=link}
{kind=link}
ソースコードの全体像
#1.必要なライブラリの読み込み
from tpot import TPOTClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score
from sklearn.metrics import confusion_matrix
import numpy as np
import pandas as pd
#2.データセットの読み込み
load_breast_cancer = load_breast_cancer(as_frame=True)
X = load_breast_cancer.data
y = load_breast_cancer.target
#3.データセットを学習用と検証用に分割する
X_train, X_test, y_train, y_test = train_test_split(X,
y,
train_size=0.75,
test_size=0.25,
random_state=42)
#4.TPOTClassifierの設定
tpot = TPOTClassifier(scoring='f1',
generations=5,
population_size=50)
#5.学習用データセットを使った機械学習モデルの学習
tpot.fit(X_train, y_train)
#6.検証用データセットを使った予測結果の評価
y_pred = tpot.predict(X_test)
f1_score(y_true=y_test, y_pred=y_pred)
次回
次回は回帰の問題をTPOTで解いてみます。