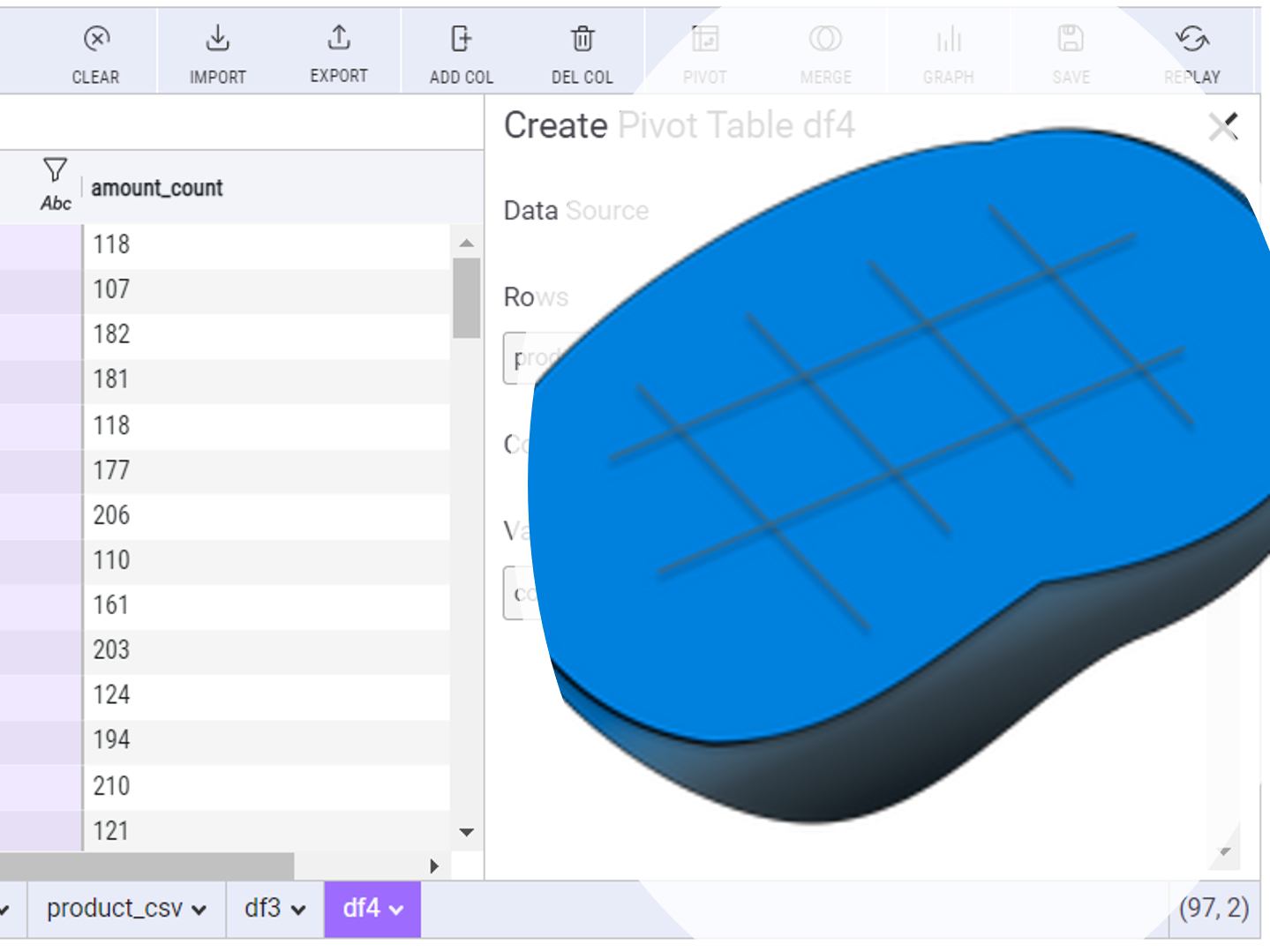
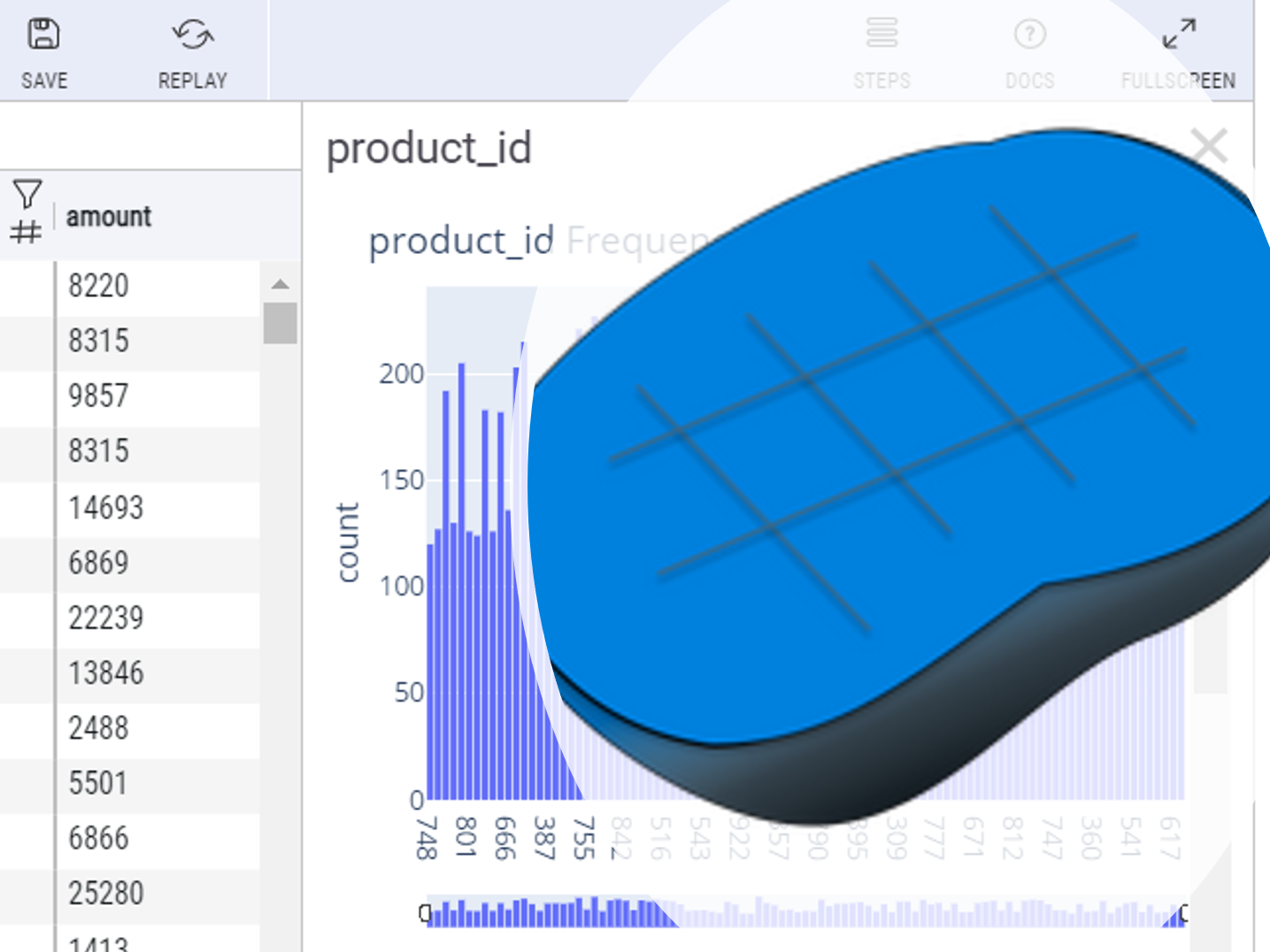
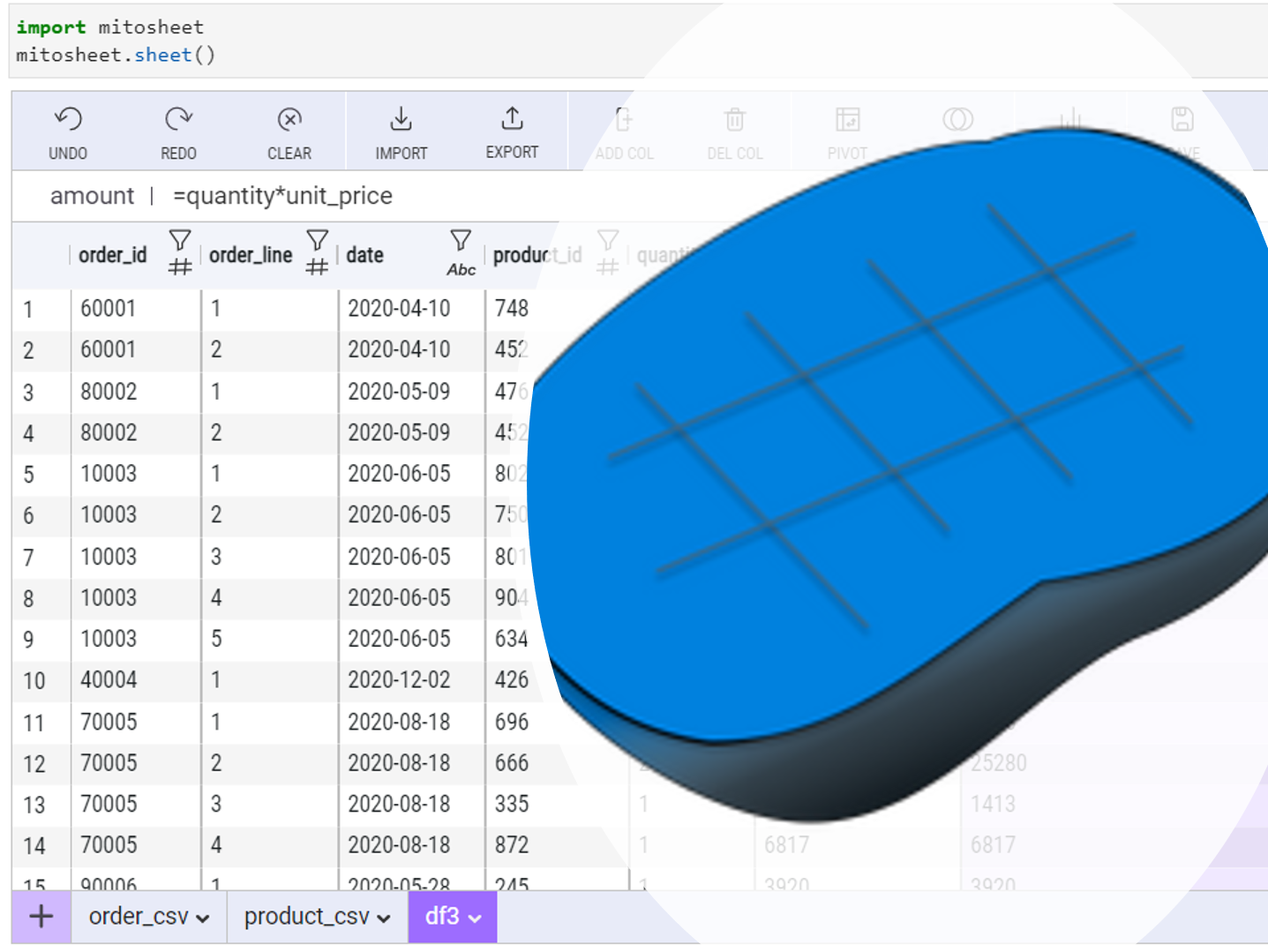
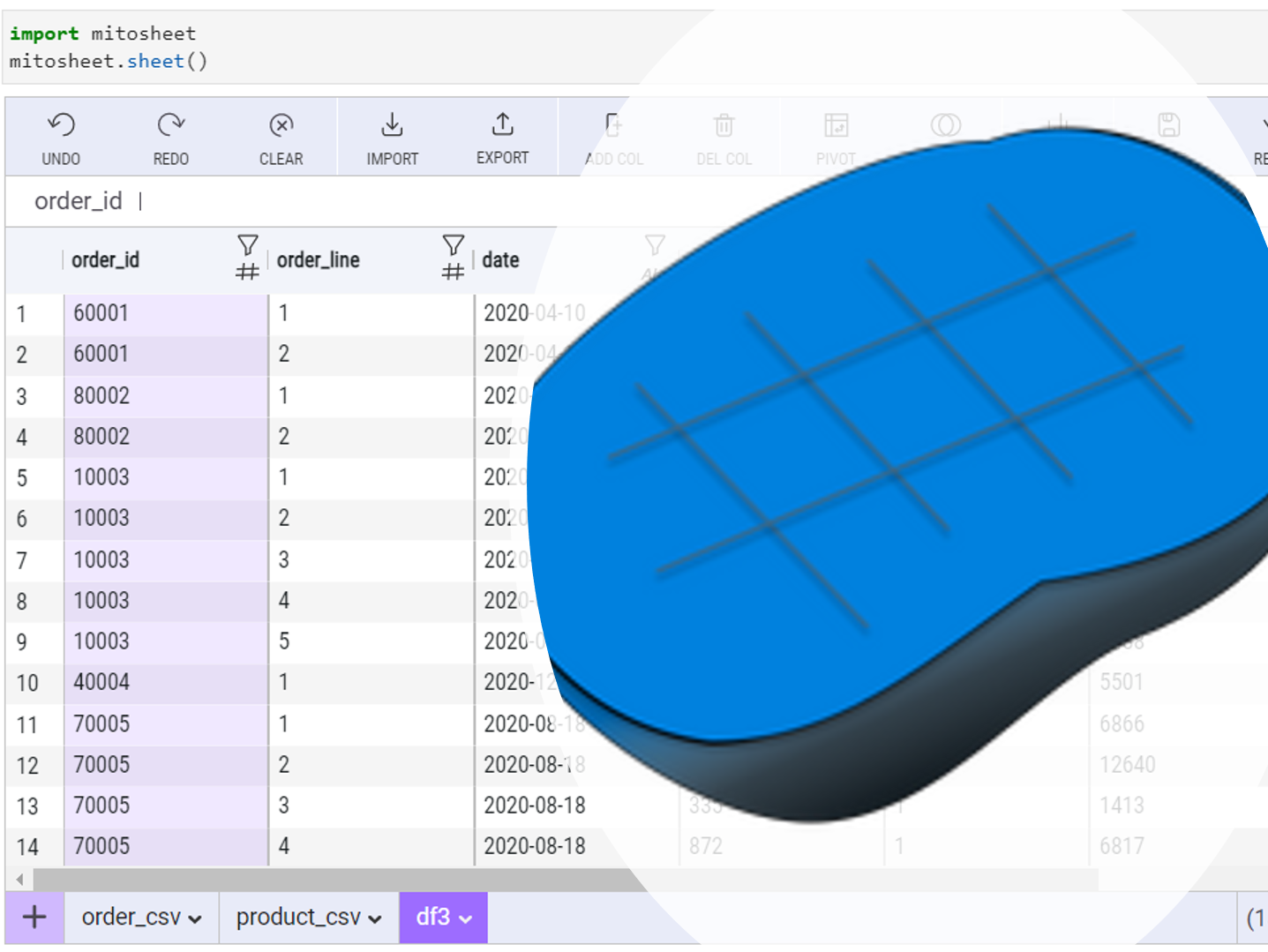
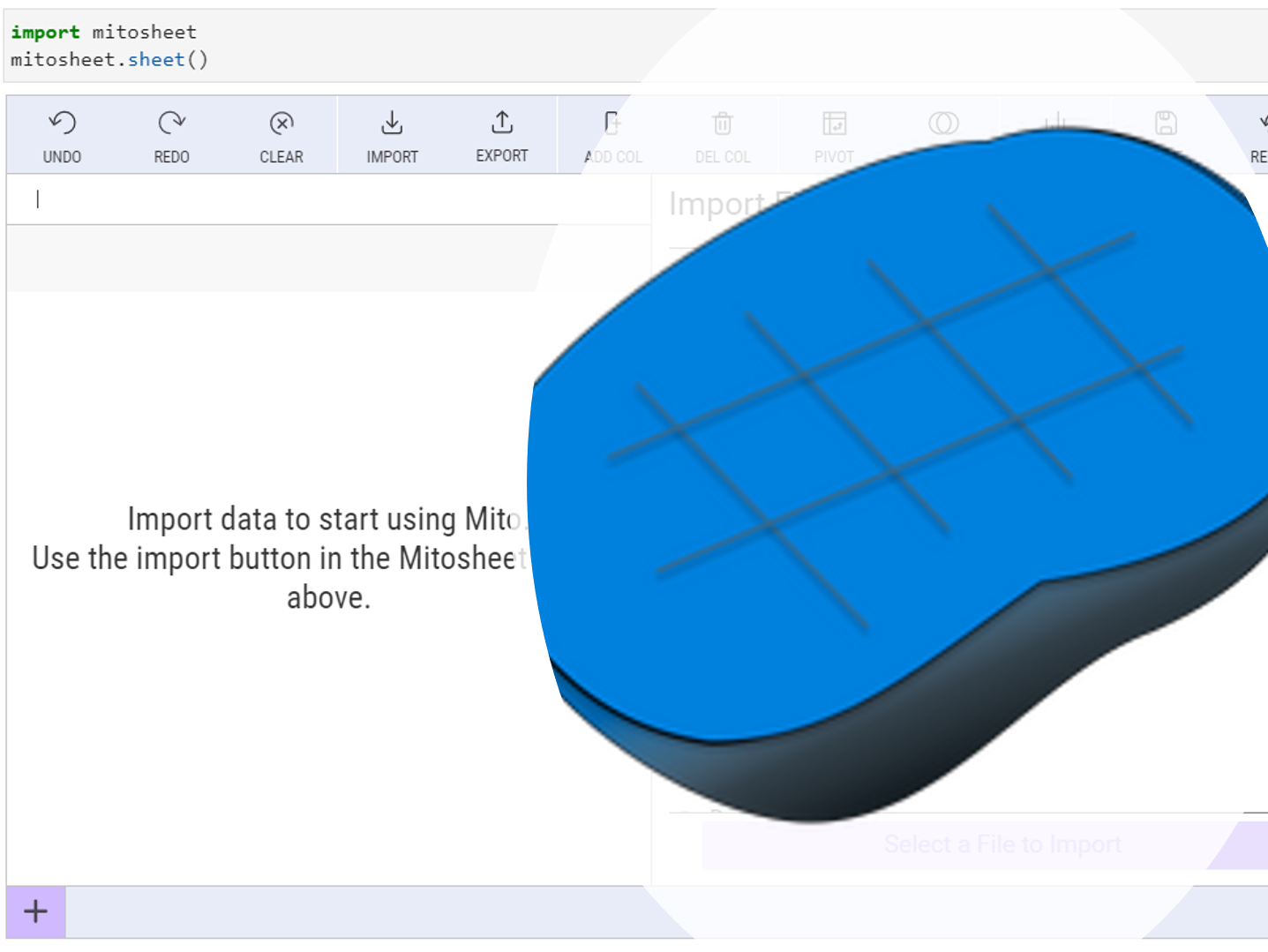
PythonのピボットテーブルをExcelのように操作できないものだろうか、そう思った方も多いことでしょう。 そして、その操作結果をPythonコードで掃き出せないものだろうかと、そう思った方も多いことでしょう。 その2...
成果のでるデータ活用の多くは、複雑なデータ分析をすることでもなく、精度の高い機械学習モデルを構築し使うことではありません。 単にデータを集計し見てアクションを起こすだけで、成果がでるパターンが多いです。 俗に言うと「見え...
PythonのピボットテーブルをExcelのように操作できないものだろうか、そう思った方も多いことでしょう。 そして、その操作結果をPythonコードで掃き出せないものだろうかと、そう思った方も多いことでしょう。 その2...
AI、データサイエンス、DX、ビッグデータなどのキーワードと共に、データ活用にチャレンジする企業が増えています。 ただ、チャレンジすれば必ず上手く行くわけではありません。 上手くいったかどうかを、どのように確かめればいい...
前回まででH2Oを使う準備が整いました。 H2Oをインストールする(Python編) H2Oをインストールする(R編) いよいよH2OのAutoMLを使ってみましょう。 今回は、「H2OのAutoMLでできること」につい...
PythonのピボットテーブルをExcelのように操作できないものだろうか、そう思った方も多いことでしょう。 そして、その操作結果をPythonコードで掃き出せないものだろうかと、そう思った方も多いことでしょう。 その2...
よくデータサイエンスなどのデータ活用のテーマ設定は、現場で上手くいっていないこと、要は出来ていないことが設定されます。 しかし、設定されたテーマ(現場で出来ていないこと)を見て、「そんなこと出来ている」と言う方がたまにい...
H2O(エイチツーオー)は、H2O.ai社によって開発された、インメモリ型の機械学習プラットフォームです。 教師あり学習や教師なし学習などの機械学習系の数理モデルを構築することができます。 嬉しいのが、ノンコードで機械学...
PythonのピボットテーブルをExcelのように操作できないものだろうか、そう思った方も多いことでしょう。 そして、その操作結果をPythonコードで掃き出せないものだろうかと、そう思った方も多いことでしょう。 その2...
データによる裏付けのあるファクト(事実)を、人はそのまま受け入れられないことは多々あります。 臭いものには蓋をするかのような態度にでます。 都合のいい偽ファクト(事実)をデータから作り、上手くことを運ぼうとする人も、まぁ...
H2O(エイチツーオー)は、H2O.ai社によって開発された、インメモリ型の機械学習プラットフォームです。 教師あり学習や教師なし学習などの機械学習系の数理モデルを構築することができます。 嬉しいのが、ノンコードで機械学...
PythonのピボットテーブルをExcelのように操作できないものだろうか、そう思った方も多いことでしょう。 そして、その操作結果をPythonコードで掃き出せないものだろうかと、そう思った方も多いことでしょう。 その2...
15年以上前の顧客データ分析は、性別や年代、居住地などの顧客のハードな特性を活用したものが多い印象があります。 マーケティングの世界のペルソナ設定(架空のユーザー像)で登場するような特性です。 実際、マーケティングの世界...
H2Oは、PythonやR、その他多数のプラットフォームで動きます。 前回は、H2O AutoML とは何なのか、というお話しをしました。 H2O AutoML とは? 今回は、WindowsのRにH2Oをインストールす...
議論や報告書などで…… 何かしらの事実(ファクト)を元にしているのか 予測した結果(もしくは推論した結果)から導き出したものなのか、 単なる感想なのか ……よく分からないことがあります。 受け手(聞き手や読み手など)は、...
H2Oは、PythonやR、その他多数のプラットフォームで動きます。 前回は、H2O AutoML とは何なのか、というお話しをしました。 H2O AutoML とは? 今回は、WindowsのPythonにH2Oをイン...