

スタッキングは機械学習のアンサンブル学習の一つです。複数の学習器の出力を特徴量とし、さらに別の学習器で予測する方法です。
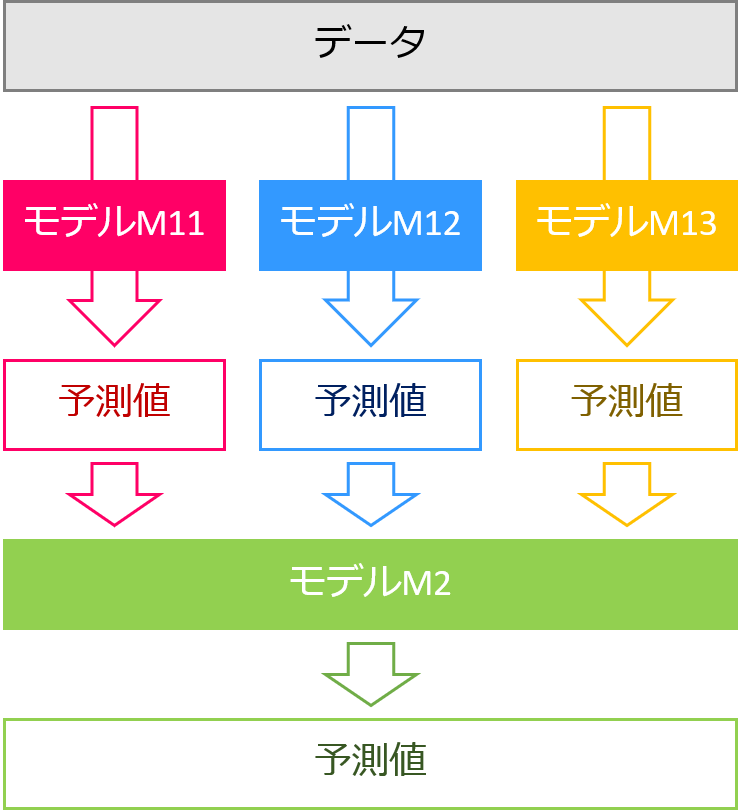
TPOTのスタッキングは、指定のアルゴリズムで予測した結果とそのアルゴリズムに入力した特徴量を組み合わせて新しい特徴量を生成し、その特徴量を使い別の学習器で予測します。
そのための変換器が、StackingEstimatorです。
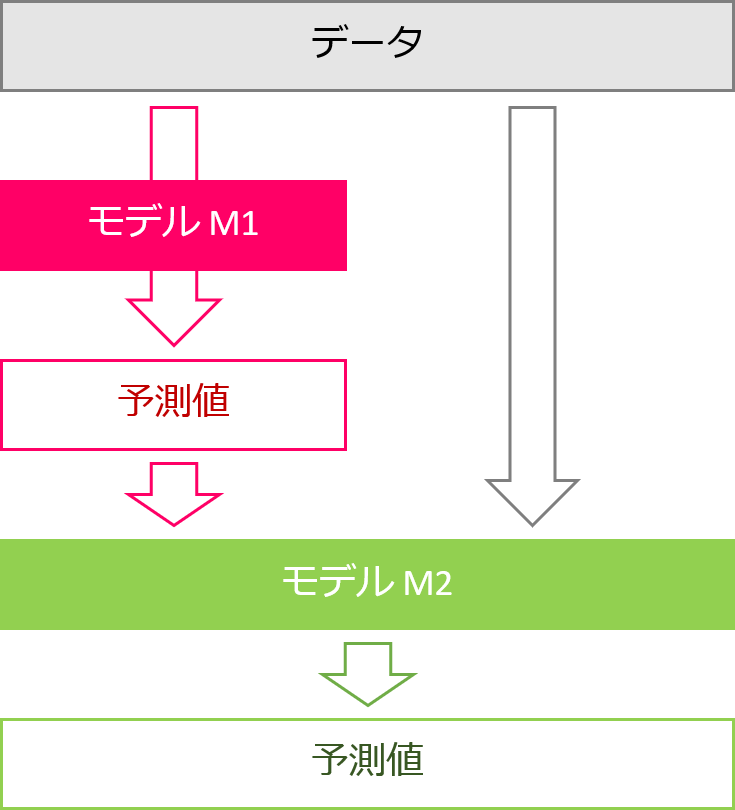
TPOTのStackingEstimatorを使うには、入力の特徴量と予測器の両方を用意する必要があります。分類問題と回帰問題で少し挙動が異なるので別々に説明します。
今回は「分類問題でのStackingEstimatorの挙動」について説明します。
Contents
利用データ
分類問題ではおなじみの乳がんの診断結果(load_breast_cancer)のデータを使います。
データの内容は「第3回AutoML【TPOT】で分類問題を解く」を見てください。
予測器はランダムフォレスト(sklearn.ensemble.RandomForest)を使うことにします。
全体の流れ

個々の説明
ライブラリーの読み込み
まずはモジュールやパッケージを読み込みます。
以下、コードです。
# ライブラリーの読み込み from tpot.builtins import StackingEstimator from sklearn.datasets import load_breast_cancer from sklearn.ensemble import RandomForestClassifier import numpy as np
- StackingEstimator … 今回説明する、TPOT特有の変換器StackingEstimatorです。
- load_breast_cancer … 例として使う乳がんの診断結果データです。
- RandomForestClassifier … StackingEstimatorで使う予測器(分類器)です。今回はランダムフォレストを使います。
- numpy … 配列や数式を扱うパッケージです。
ここで、torchというパッケージが入っていないと警告が出ますが、なくても今回のコードは動きます。
データの読み込みと確認
次にデータを読み込みます。
以下、コードです。
## データの読み込み data = load_breast_cancer() X = data.data # 特徴量をXに格納 y = data.target # 目的変数をyに格納
特徴量はload_breast_cancerのdataをキーとして取り出すことができます。変数Xに特徴量を格納します。目的変数はload_breast_cancerのtargetをキーとして取り出すことができます。変数yに目的変数を格納します。
データX,yの中身を見てみます。見やすいように最初の10行だけ表示させています。
以下、コードです。
## データの中を見る X = X[:,:3] # 3列だけ取り出している print(X[:10,:]) # Xの中身を10行だけ表示する
以下、実行結果です。

ここで、X[:,:3]として特徴量Xの3列だけ残しています。今回はStackingEstimatorの処理内容を確認しやすいように、今回は特徴量Xを3列だけ使うことにします。
予測器(分類器)の設定と学習、その結果の確認
StackingEstimatorに使う予測器(分類器)を用意します。
RandomForestを使います。
分類問題の場合は分類器、回帰問題の場合は回帰器を使いましょう。今回は分類問題なので、分類器を用意します。結果を確認したいので、実行ごとに結果が変わらないように乱数のシードをrandom_stateパラメータで固定しておきます。
以下、コードです。
## 予測器(分類器)の設定 random_forest = RandomForestClassifier(random_state=42)
変数random_forestに予測器(分類器)が格納されました。設定内容はprint文で確認できます。
以下、コードです。
## 予測器(分類器)の設定を見る print(random_forest)
以下、実行結果です。
![]()
ここでいったん、このRandomForestClassifierを使って学習と予測をしてみましょう。
学習はfit関数、クラスの予測はpredict関数、確率の予測はpredict_proba関数を使います。
以下、コードです。
## 予測器(分類器)の学習 random_forest.fit(X,y) ## クラスと確率の予測 y_predict = random_forest.predict(X) # クラスの予測 y_probability = random_forest.predict_proba(X) # 確率の予測
学習と予測の結果を見ます。
まずはクラスの分類結果です。見やすいように最初の10サンプルだけ表示しています。最初の10サンプルは0に分類されていることがわかります。
以下、コードです。
print(y_predict[:10]) # クラスの予測
以下、実行結果です。
![]()
予測確率も見てみましょう。
以下、コードです。
print(y_probability[:10,:]) # 確率の予測
以下、実行結果です。

2列表示されます。左が0である確率、右が1である確率です。
StackingEstimatorの設定と学習、その結果の確認
それではいよいよStackingEstimatorを作っていきます。
estimatorパラメータで使いたい予測器(分類器)を設定できます。今回用意したrandom_forestを使います。
以下、コードです。
## StackingEstimatorの設定 stacking_estimator = StackingEstimator(estimator=random_forest)
print文で設定内容を確認できます。
以下、コードです。
## StackingEstimatorの設定を見る print(stacking_estimator)
以下、実行結果です。

それでは設定したStackingEstimatorを使ってみましょう。
StackingEstimatorに特徴量と目的変数を入力して学習します。中では、StackingEstimatorで使われるRandomForestClassifierを学習させています。
以下、コードです。
## StackingEstimatorの学習 stacking_estimator.fit(X, y)
学習したStackingEstimatorを使って、特徴量Xを変換します。
transform関数を使うと変換できます。
以下、コードです。
## StackingEstimatorによる特徴量の生成 X_transformed = stacking_estimator.transform(X)
print文で、X_transformedの中身を見てみましょう。ここでもわかりやすいように最初の10行だけ表示しています。
以下、コードです。
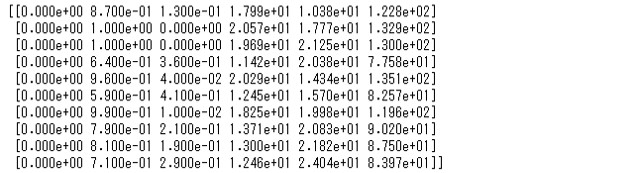
## StackingEstimatorが生成した特徴量を見る print(X_transformed[:10,:])
以下、実行結果です。
中身を説明します。
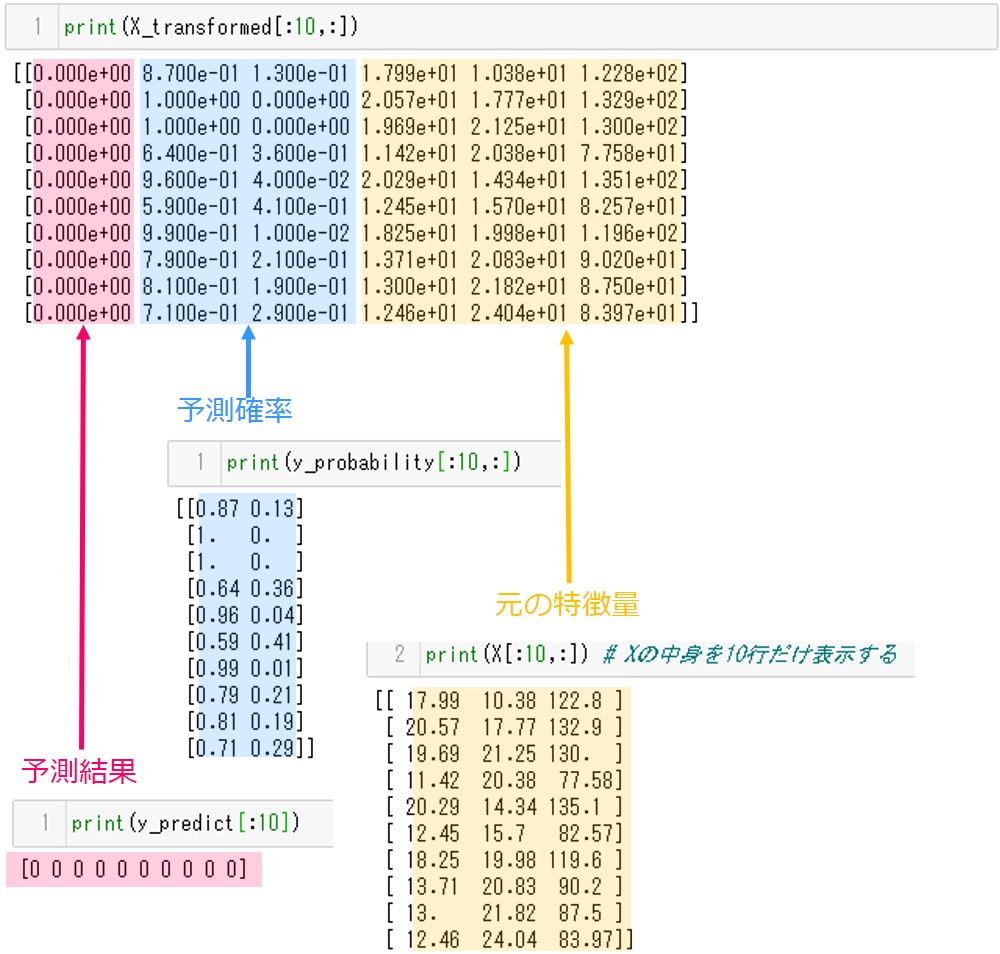
X_transformedの左から1列目は予測結果が格納されています。2列目~3列目は予測確率です。4列目以降に元の特徴量が格納されています。それぞれ値が一致することを確認してみてください。
最後にStackingEstimatorの仕組みをまとめておきます。
- StackingEstimatorで使うestimator(今回はRandomForestClassifier)を、引数で与えた特徴量Xとyで学習する。
- 学習済みのestimatorで、引数で与えたXにより予測する。
- 引数で与えた特徴量Xと予測結果の分類結果と予測確率を結合して出力し、新たな特徴量とする。
ソースコードの全体像
# ライブラリーの読み込み from tpot.builtins import StackingEstimator from sklearn.datasets import load_breast_cancer from sklearn.ensemble import RandomForestClassifier import numpy as np # データの読み込みと確認 ## データの読み込み data = load_breast_cancer() X = data.data # 特徴量をXに格納 y = data.target # 目的変数をyに格納 ## データの中を見る X = X[:,:3] # 3列だけ取り出している print(X[:10,:]) # Xの中身を10行だけ表示する # 予測器(分類器)の設定と学習、その結果の確認 ## 予測器(分類器)の設定 random_forest = RandomForestClassifier(random_state=42) ## 予測器(分類器)の設定を見る print(random_forest) ## 予測器(分類器)の学習 random_forest.fit(X,y) ## クラスと確率の予測 y_predict = random_forest.predict(X) # クラスの予測 y_probability = random_forest.predict_proba(X) # 確率の予測 ## 予測結果(最初の10個を表示) print(y_predict[:10]) # クラスの予測 print(y_probability[:10,:]) # 確率の予測 # StackingEstimatorの設定と学習、その結果の確認 ## StackingEstimatorの設定 stacking_estimator = StackingEstimator(estimator=random_forest) ## StackingEstimatorの設定を見る print(stacking_estimator) ## StackingEstimatorの学習 stacking_estimator.fit(X, y) ## StackingEstimatorによる特徴量の生成 X_transformed = stacking_estimator.transform(X) ## StackingEstimatorが生成した特徴量を見る print(X_transformed[:10,:])
次回
今回は「分類問題でのStackingEstimatorの挙動」について説明しました。
次回は「回帰問題でのStackingEstimatorの挙動」について説明します。