

ChatGPTモデルは、 OpenAIによってトレーニングされたLLM(大規模な言語モデル)です。
プロンプトで話しかけると、人のように答えてくれます。テキストでですが……
そして何よりこのChatGPTは、優れたデータサイエンティストにもなります。
例えば、プロンプトで以下のセンテンスを冒頭に付け加えることで、優れたデータサイエンティストとして、Pythonのコーディングをしてくれます。
ただ、大きな問題が1つあります。
ChatGPTが理解できるように質問する必要があります。
多少あいまいな表現は理解してくれますが、最低限必要な情報を与えないと、適切な回答が返ってきません。それは、人でも同じことです。
そこで、今回はChatGPTが理解してくれる構文(データ分析の依頼文のフォーマット)を紹介します。
この構文の【******】を、あなたが依頼した内容に変更するだけで、恐らくChatGPTは理解してくれることでしょう。
今回は、「予測モデルの依頼文」です。
ちなみに、まだOpenAIのアカウントを作成していない方は、作成して下さい。
以下の記事で簡単に説明しています。それほど難しいものではありません。
ChatGPTの機能は、OpenAIのサイト(https://chat.openai.com/)でも、上述の記事で紹介したようなJupyter Notebook上のChatGPTでも、どちらでも構いません。ChatGPTが使えればどれでも構いません。
ChatGPT
https://chat.openai.com/
構文(予測モデル構築の依頼文のフォーマット)
以下、予測モデルを構築するときの構文です。
【 1 】 のデータセットを使います。
【 2 】 を構築して下さい。
【 3 】。
- 【 1 】 :データセット
- データセットの概要を記載
- このとき、目的変数は明記
- 【 2 】 :予測モデル
- 構築したい予測モデルの概要を記載
- ここでも、目的変数を明記
- さらに、分類問題なのか回帰問題なのかを明記
- 【 3 】 :追加事項(無ければ記載してくてもOK)
- 【1】および【2】以外の追加事項や補足事項を記載
- 例えば、特定の数理モデルやパッケージ、評価指標などの指定など
ちなみに、PythonではなくR言語でコーディングして欲しいときは、Pythonの個所を次のようにRに変えてください。
【 1 】 のデータセットを使います。
【 2 】 を構築して下さい。
【 3 】。
例1:データセットと予測モデルの概要
例えば、次にように記載します。解約を予測するモデルです。
顧客の特徴と解約(churn)のデータセットを使います。
ある顧客が解約するかどうかを予測する分類モデルを構築して下さい。
- 【 1 】 :データセット ⇒ 顧客の特徴と解約(churn)
- 【 2 】 :予測モデル ⇒ ある顧客が解約するかどうかを予測する分類モデル
- 【 3 】 :追加事項 ⇒ なし
データセットと予測モデルの概要レベルの簡単なものです。
実際に、ChatGPTに聞いてみます。
以下、実行結果です。

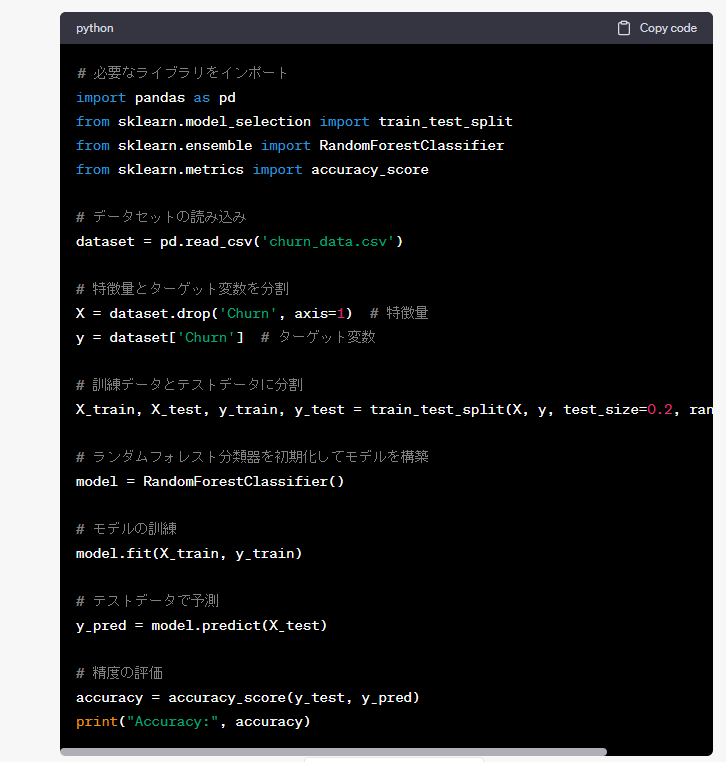

コードの説明まで出力されています。
以下は、ChatGPTが出力したコードをコピペしたものです。
# 必要なライブラリをインポート
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# データセットの読み込み
dataset = pd.read_csv('churn_data.csv')
# 特徴量とターゲット変数を分割
X = dataset.drop('Churn', axis=1) # 特徴量
y = dataset['Churn'] # ターゲット変数
# 訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ランダムフォレスト分類器を初期化してモデルを構築
model = RandomForestClassifier()
# モデルの訓練
model.fit(X_train, y_train)
# テストデータで予測
y_pred = model.predict(X_test)
# 精度の評価
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
Pythonではなく、R言語のコードを作ってもらいます。
例えば、次にように記載します。先ほどのpythonの個所をRに変えただけです。
顧客の特徴と解約(churn)のデータセットを使います。
ある顧客が解約するかどうかを予測する分類モデルを構築して下さい。
実際に、ChatGPTに聞いてみます。
以下、実行結果です。
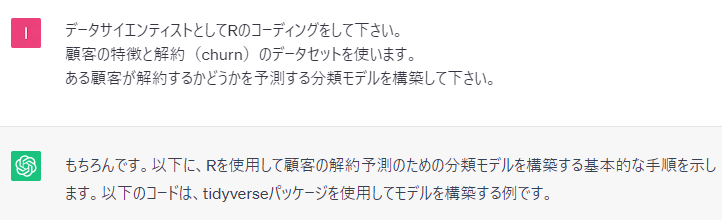
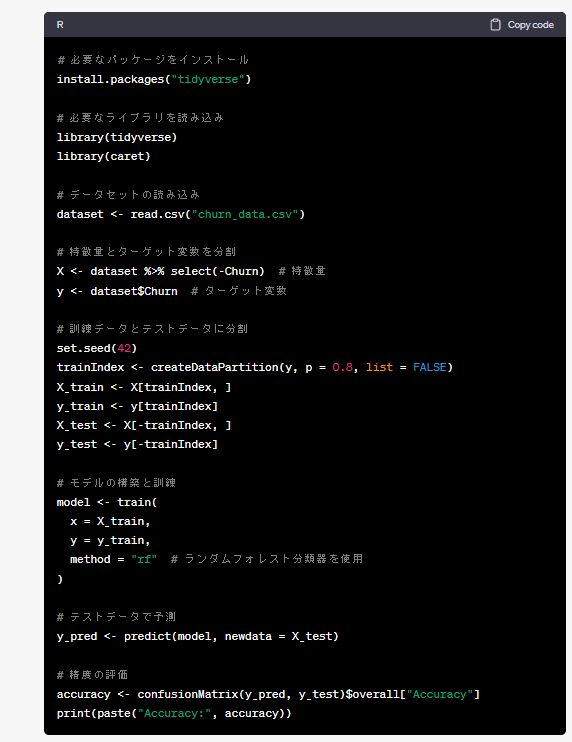

しっかり、R言語で記載されています。
以下は、ChatGPTが出力したコードをコピペしたものです。
# 必要なパッケージをインストール
install.packages("tidyverse")
# 必要なライブラリを読み込み
library(tidyverse)
library(caret)
# データセットの読み込み
dataset <- read.csv("churn_data.csv")
# 特徴量とターゲット変数を分割
X <- dataset %>% select(-Churn) # 特徴量
y <- dataset$Churn # ターゲット変数
# 訓練データとテストデータに分割
set.seed(42)
trainIndex <- createDataPartition(y, p = 0.8, list = FALSE)
X_train <- X[trainIndex, ]
y_train <- y[trainIndex]
X_test <- X[-trainIndex, ]
y_test <- y[-trainIndex]
# モデルの構築と訓練
model <- train(
x = X_train,
y = y_train,
method = "rf" # ランダムフォレスト分類器を使用
)
# テストデータで予測
y_pred <- predict(model, newdata = X_test)
# 精度の評価
accuracy <- confusionMatrix(y_pred, y_test)$overall["Accuracy"]
print(paste("Accuracy:", accuracy))
例2:アルゴリズム(数理モデル)などを指定する
先ほどのChatGPTのお願い文に、アルゴリズム(数理モデル)などを指定することもできます。
例えば、次にように記載します。XGBoostによるモデル構築をお願いしています。
顧客の特徴と解約(churn)のデータセットを使います。
ある顧客が解約するかどうかを予測する分類モデルを構築して下さい。
XGBoostを使って下さい。
- 【 1 】 :データセット ⇒ 顧客の特徴と解約(churn)
- 【 2 】 :予測モデル ⇒ ある顧客が解約するかどうかを予測する分類モデル
- 【 3 】 :追加事項 ⇒ XGBoostを使う
実際に、ChatGPTに聞いてみます。
以下、実行結果です。
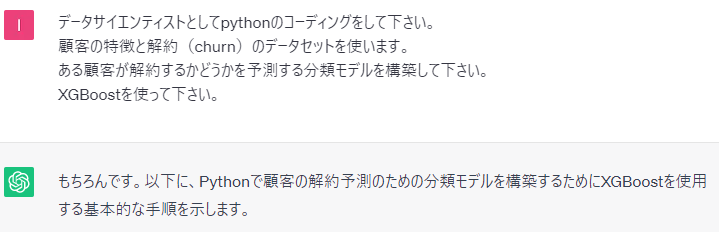
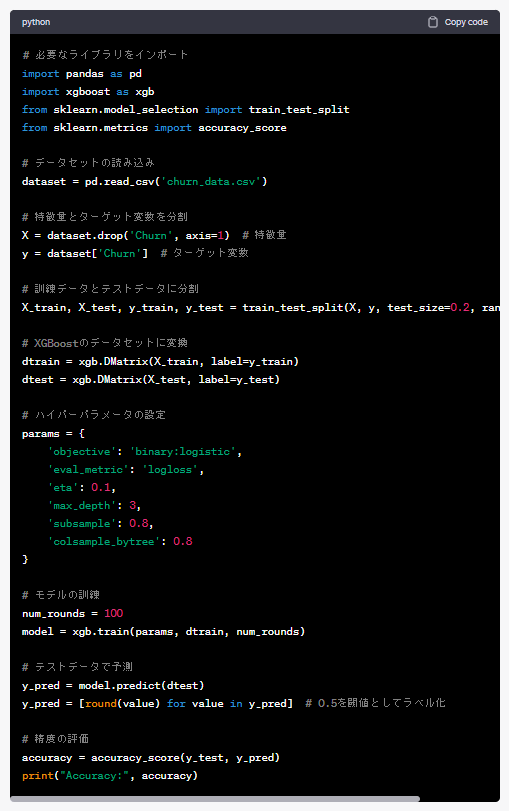

以下は、ChatGPTが出力したコードをコピペしたものです。
# 必要なライブラリをインポート
import pandas as pd
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# データセットの読み込み
dataset = pd.read_csv('churn_data.csv')
# 特徴量とターゲット変数を分割
X = dataset.drop('Churn', axis=1) # 特徴量
y = dataset['Churn'] # ターゲット変数
# 訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# XGBoostのデータセットに変換
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
# ハイパーパラメータの設定
params = {
'objective': 'binary:logistic',
'eval_metric': 'logloss',
'eta': 0.1,
'max_depth': 3,
'subsample': 0.8,
'colsample_bytree': 0.8
}
# モデルの訓練
num_rounds = 100
model = xgb.train(params, dtrain, num_rounds)
# テストデータで予測
y_pred = model.predict(dtest)
y_pred = [round(value) for value in y_pred] # 0.5を閾値としてラベル化
# 精度の評価
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
例3:AutoML(自動機械学習)で構築して
色々なアルゴリズム(数理モデル)でモデル構築し、最も高精度なモデルを探索することがあります。
ただ非常に面倒です。そこで、AutoML(自動機械学習)です。
例えば、次にように記載します。TPOTを使っています。
顧客の特徴と解約(churn)のデータセットを使います。
ある顧客が解約するかどうかを予測する分類モデルを構築して下さい。
TPOTの自動機械学習を使って下さい。
- 【 1 】 :データセット ⇒ 顧客の特徴と解約(churn)
- 【 2 】 :予測モデル ⇒ ある顧客が解約するかどうかを予測する分類モデル
- 【 3 】 :追加事項 ⇒ TPOTの自動機械学習を使う
実際に、ChatGPTに聞いてみます。
以下、実行結果です。
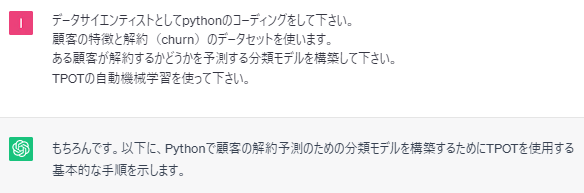
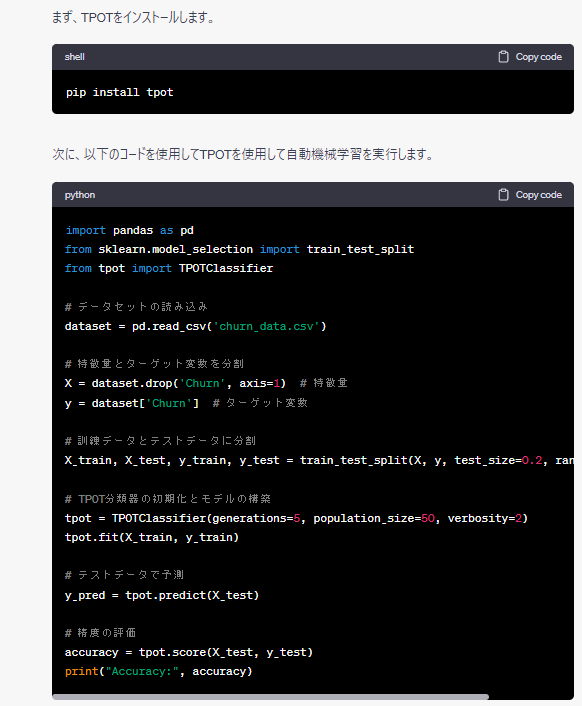

以下は、ChatGPTが出力したコードをコピペしたものです。
pip install tpot
import pandas as pd
from sklearn.model_selection import train_test_split
from tpot import TPOTClassifier
# データセットの読み込み
dataset = pd.read_csv('churn_data.csv')
# 特徴量とターゲット変数を分割
X = dataset.drop('Churn', axis=1) # 特徴量
y = dataset['Churn'] # ターゲット変数
# 訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# TPOT分類器の初期化とモデルの構築
tpot = TPOTClassifier(generations=5, population_size=50, verbosity=2)
tpot.fit(X_train, y_train)
# テストデータで予測
y_pred = tpot.predict(X_test)
# 精度の評価
accuracy = tpot.score(X_test, y_test)
print("Accuracy:", accuracy)
ちなみに、TPOTは遺伝的アルゴリズムを活用したAutoML(自動機械学習)のPythonパッケージです。
興味のある方は、以下を参考にして下さい。
ちょっと古いかもしれませんが、、、 TPOTのマニュアル(当時は不完全???)やPythonコードそのものを読み込んで解説しています。
例4:AutoML(自動機械学習)+評価指標指定
AutoML(自動機械学習)はどの評価指標を使うかで、最良な予測モデルが変わってきます。
そこで、評価指標を指定してみます。
例えば、次にように記載します。評価指標としてAUCを指定しています。
顧客の特徴と解約(churn)のデータセットを使います。
ある顧客が解約するかどうかを予測する分類モデルを構築して下さい。
TPOTの自動機械学習を使い、テストデータのAUCスコアが最も高い分類モデルを見つけて下さい。
- 【 1 】 :データセット ⇒ 顧客の特徴と解約(churn)
- 【 2 】 :予測モデル ⇒ ある顧客が解約するかどうかを予測する分類モデル
- 【 3 】 :追加事項 ⇒ TPOT+AUCスコア
実際に、ChatGPTに聞いてみます。
以下、実行結果です。

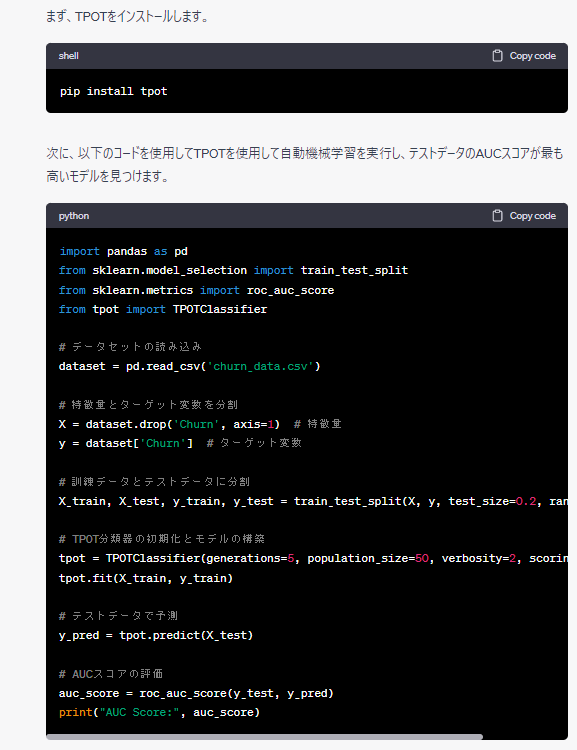

以下は、ChatGPTが出力したコードをコピペしたものです。
pip install tpot
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
from tpot import TPOTClassifier
# データセットの読み込み
dataset = pd.read_csv('churn_data.csv')
# 特徴量とターゲット変数を分割
X = dataset.drop('Churn', axis=1) # 特徴量
y = dataset['Churn'] # ターゲット変数
# 訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# TPOT分類器の初期化とモデルの構築
tpot = TPOTClassifier(generations=5, population_size=50, verbosity=2, scoring='roc_auc')
tpot.fit(X_train, y_train)
# テストデータで予測
y_pred = tpot.predict(X_test)
# AUCスコアの評価
auc_score = roc_auc_score(y_test, y_pred)
print("AUC Score:", auc_score)
例5:ハイパーパラメータチューニング
予測モデルを作るとき、ハイパーパラメータチューニングをすることがあります。
もちろん、ChatGPTにお願いすると、考慮しくてれます。
今回は、あえて「データセットの説明抜き」でお願いしてみます。
どうなるのでしょうか?
先ずは、分類問題です。
例えば、次にように記載します。
scikit-learnのdecision treeの分類モデルのハイパーパラメータを調整するためのコードを書いて下さい。
実際に、ChatGPTに聞いてみます。
以下、実行結果です。
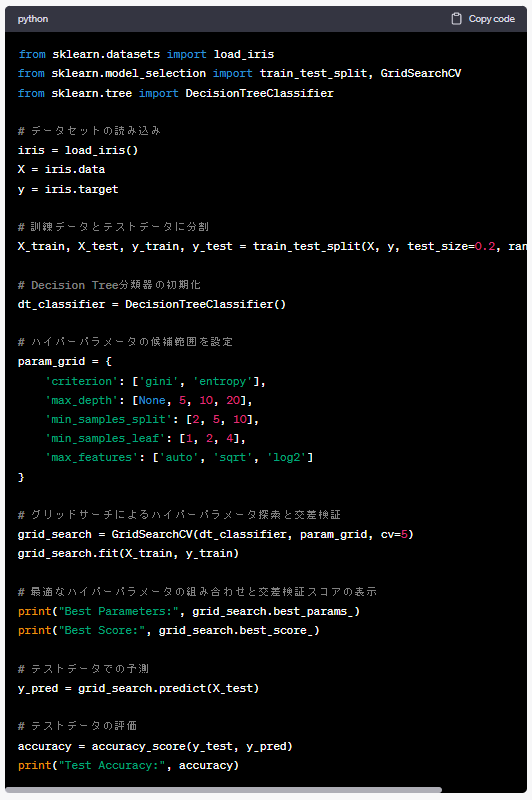

以下は、ChatGPTが出力したコードをコピペしたものです。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.tree import DecisionTreeClassifier
# データセットの読み込み
iris = load_iris()
X = iris.data
y = iris.target
# 訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Decision Tree分類器の初期化
dt_classifier = DecisionTreeClassifier()
# ハイパーパラメータの候補範囲を設定
param_grid = {
'criterion': ['gini', 'entropy'],
'max_depth': [None, 5, 10, 20],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4],
'max_features': ['auto', 'sqrt', 'log2']
}
# グリッドサーチによるハイパーパラメータ探索と交差検証
grid_search = GridSearchCV(dt_classifier, param_grid, cv=5)
grid_search.fit(X_train, y_train)
# 最適なハイパーパラメータの組み合わせと交差検証スコアの表示
print("Best Parameters:", grid_search.best_params_)
print("Best Score:", grid_search.best_score_)
# テストデータでの予測
y_pred = grid_search.predict(X_test)
# テストデータの評価
accuracy = accuracy_score(y_test, y_pred)
print("Test Accuracy:", accuracy)
次に、回帰問題です。
例えば、次にように記載します。
scikit-learnのdecision treeの回帰モデルのハイパーパラメータを調整するためのコードを書いて下さい。
実際に、ChatGPTに聞いてみます。
以下、実行結果です。
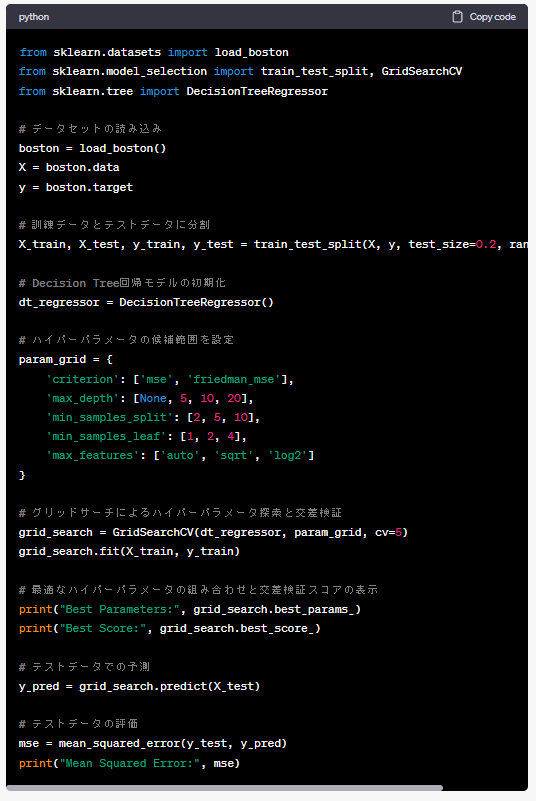

以下は、ChatGPTが出力したコードをコピペしたものです。
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.tree import DecisionTreeRegressor
# データセットの読み込み
boston = load_boston()
X = boston.data
y = boston.target
# 訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Decision Tree回帰モデルの初期化
dt_regressor = DecisionTreeRegressor()
# ハイパーパラメータの候補範囲を設定
param_grid = {
'criterion': ['mse', 'friedman_mse'],
'max_depth': [None, 5, 10, 20],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4],
'max_features': ['auto', 'sqrt', 'log2']
}
# グリッドサーチによるハイパーパラメータ探索と交差検証
grid_search = GridSearchCV(dt_regressor, param_grid, cv=5)
grid_search.fit(X_train, y_train)
# 最適なハイパーパラメータの組み合わせと交差検証スコアの表示
print("Best Parameters:", grid_search.best_params_)
print("Best Score:", grid_search.best_score_)
# テストデータでの予測
y_pred = grid_search.predict(X_test)
# テストデータの評価
mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error:", mse)
「データセットの説明抜き」なので、ChatGPTがどこからかサンプルデータを見つけてきて、それを使ったコードを提示してくれています。
まとめ
今回は、ChatGPTに予測モデル構築のための依頼文の例を示しました。
最初に……
「データサイエンティストとしてpythonのコーディングをして下さい。」
……を入れると、ほぼ確実にコーディングしてくれます。
このセンテンスを入れなくても、コーディングしてくれることもあるのですが、そうでないときもあります。
単にコードを作るときの流れを説明する回答が返ってくることがあります。
以下、実際にChatGPTから返ってきた回答です。

ChatGPTのすごいところは、最初に役割(今回はデータサイエンティスト)を与えると、その役割を演じて返答を返してくれるところです。
例えば、次のような構文で歴史の偉人(例:二宮尊徳など)や専門職(例:心理カウンセラーなど)を指定し質問すると回答してくれます。
例えば、次にように記載します。
ChatGPTの回答です。
過去の偉人を召喚することができそうです。
さらに、別の時代の偉人同士でディスカッションも実現できそうです。