

ただし、これだけでは学習済モデルを使って別のデータを予測することができません。
TPOTで学習した数理モデルを他のプログラムで使う方法を説明します。
ここでは第3回で使った乳がんの診断結果データセット(load_breast_cancer)の分類問題を例にとります。
データセットの説明は第3回のデータセットの説明ブロックをご覧ください。
Contents
学習済みモデルを他のプログラムで使う流れ
学習済みモデルを使って予測を行う流れは簡単です。
学習プログラムで「モデルを学習し、その学習済モデルを保存」し、それを予測プログラムで「保存した学習済みモデルを呼び出し使用」します。
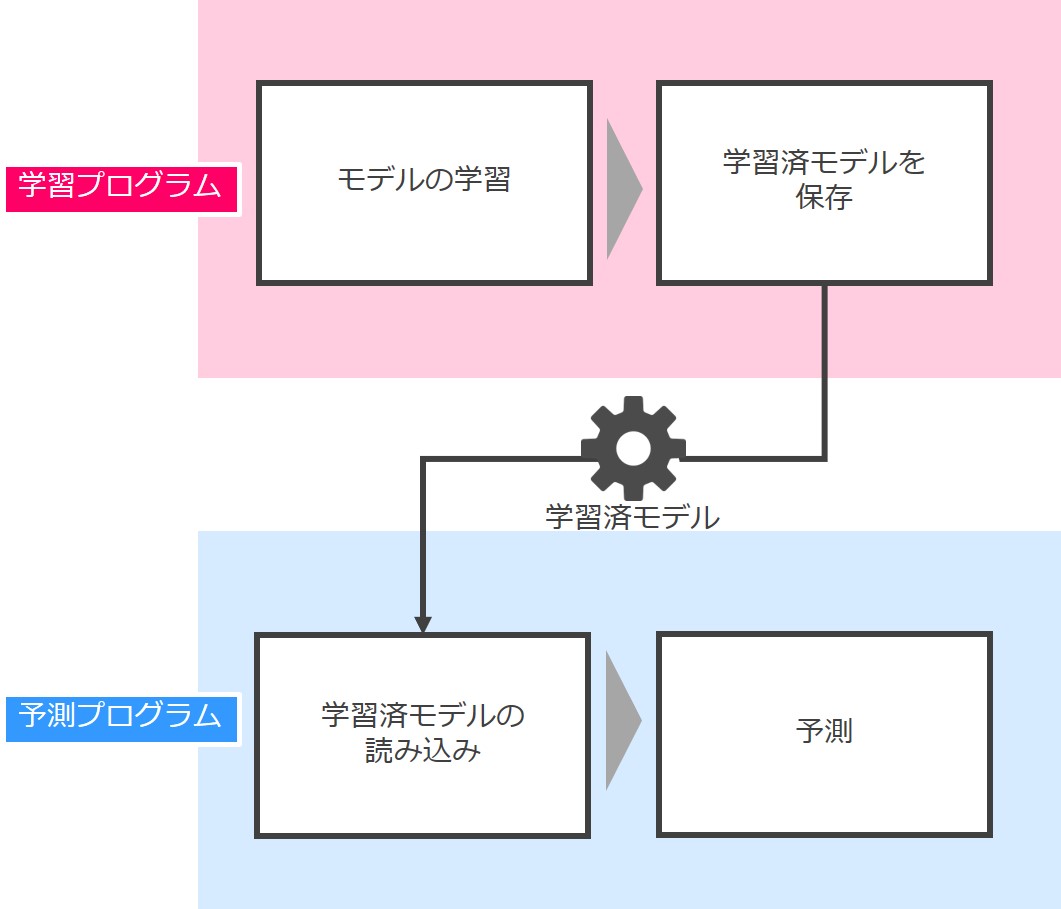
第3回と第4回で紹介したのは学習プログラムですが、今回紹介する学習プログラムは第3回と第4回のものとは少し異なります。
相違点は、今回紹介する学習プログラムの最後に学習済モデルの保存があることです。モデルを保存しておかないと、他のプログラムから呼び出して使えないからです。
では、学習プログラムと予測プログラムの流れを簡単に説明します。その後、それぞれの詳細について説明します。
予想用データセットと学習用データセットの生成
今回は第3回で使った乳がんの診断結果データセット(load_breast_cancer)を使います。
先ずは、必要なライブラリを読み込みます。
以下、コードです。
from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split import pandas as pd
- データセットのload_breast_cancer
- データセットを学習プログラム用と予測プログラム用に分割するtrain_test_split
- データ解析モジュールであるpandas
次に、データセットを読み込みます。
以下、コードです。
D = load_breast_cancer(as_frame=True) X = D.data y = D.target
データを変数Dに読み込みます。
特徴量はD.data、目的変数はD.targetに格納されています。それぞれX,yに格納しなおします。
- X:特徴量(説明変数)
- y:目的変数「良性(=1)と悪性(=0)の2クラス値」
Jupyter Notebookに変数名を単体で入力するだけで、中身を確認することができます。
以下、コードです。
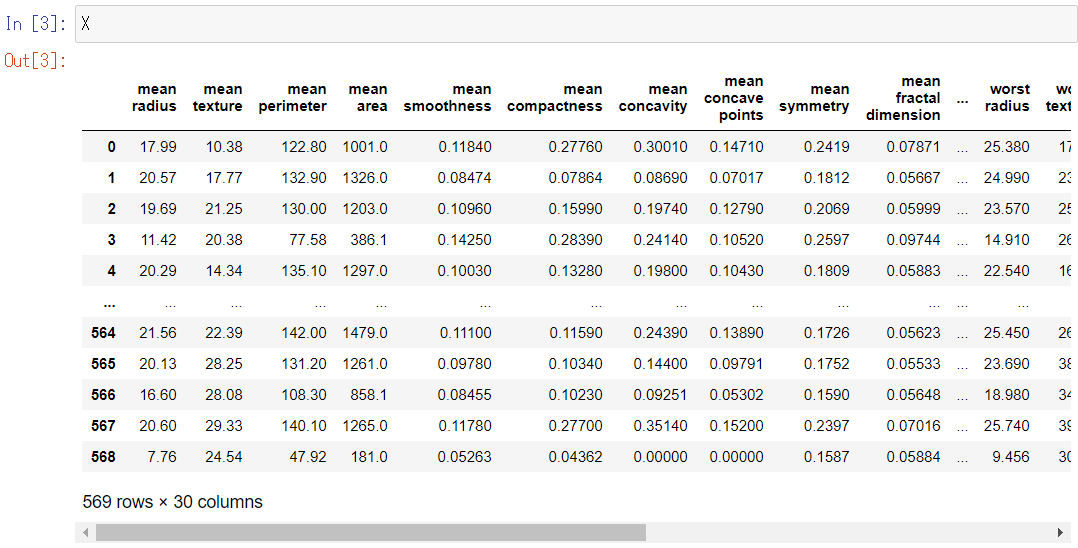
X
以下、実行結果です。
以下、コードです。
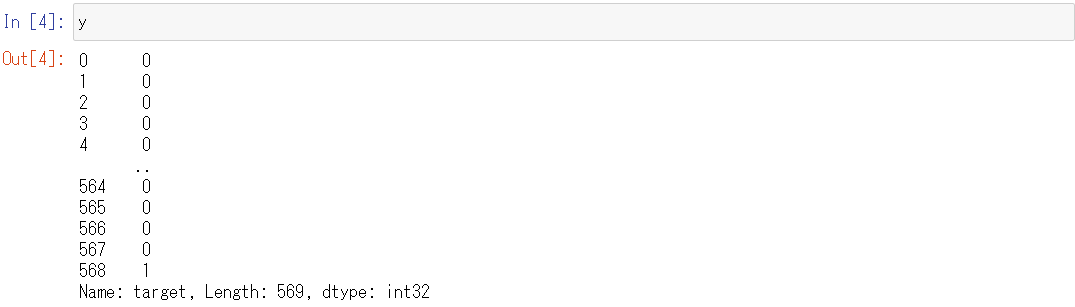
y
以下、実行結果です。
dtypes属性を使うことで、各列のデータ型を確認することができます。
以下、コードです。
print('X')
print(X.dtypes)
print()
print('y')
print(y.dtypes)
以下、実行結果です。
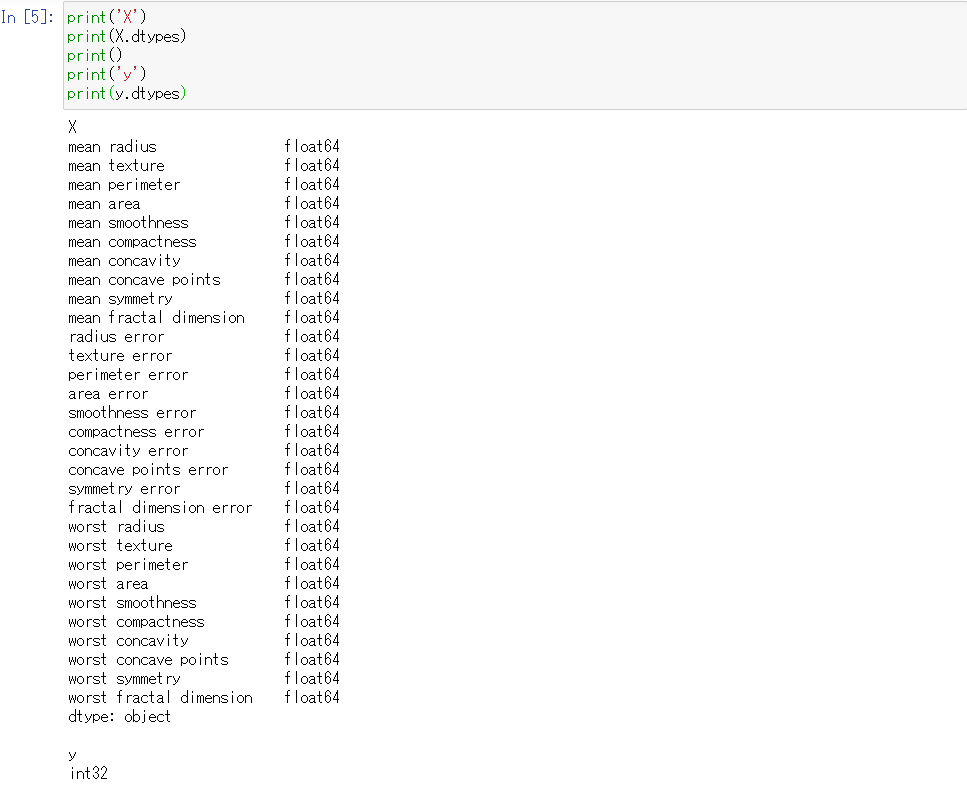
すべて数値型で、倍精度浮動小数点型(float64)であることがわかります。
欠損値の存在も確認しておきましょう。isna関数で欠損値の存在有無を出力し(存在する場合True)、sum関数でisnaの結果Trueの数を数えて欠損値の数を算出することができます。
以下、コードです。
print('X')
print(X.isna().sum())
print()
print('y')
print(y.isna().sum())
以下、実行結果です。
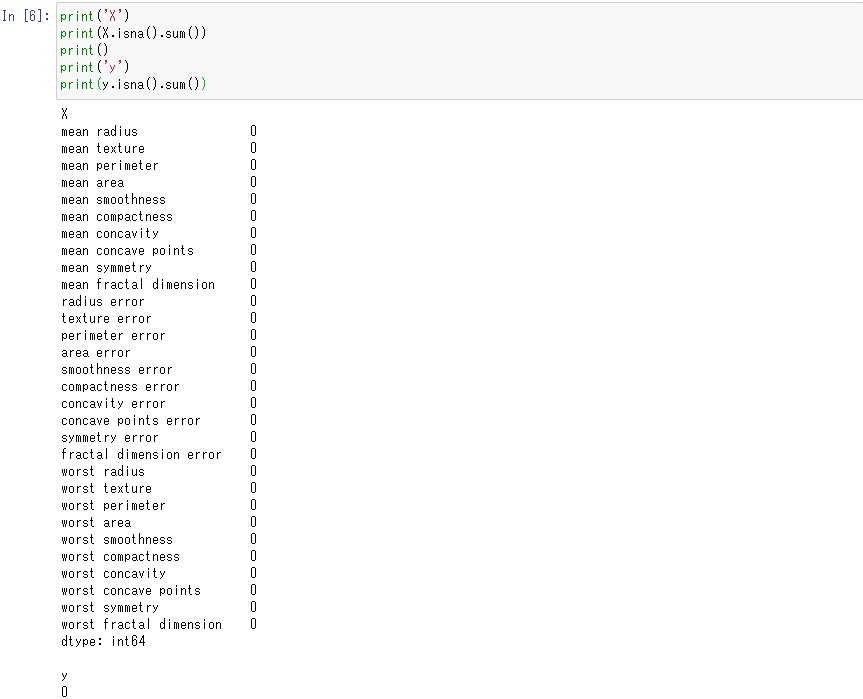
このデータセットには欠損値が存在しないことがわかります。
このデータセットを「学習プログラムで使うデータセット」と「予測プログラムで使うデータセット」の2つに分割します。
X_predict, X_tmp, y_predict, y_tmp = train_test_split(X,
y,
train_size=0.2,
random_state=42,
shuffle=True)
- 学習プログラムで使うデータセット
- X_tmp : 特徴量(説明変数)
- y_tmp : 目的変数
- 予測プログラムで使うデータセット
- X_predict : 特徴量(説明変数)
- y_predict : 目的変数
「学習プログラムで使うデータセット」と「予測プログラムで使うデータセット」の行数を確認します。
以下、コードです。
print(len(X_predict)) print(len(X_tmp))
以下、実行結果です。

元のデータが569件なので、およそ20%、80%に分割されたことが分かります。
2つのデータセットをCSV形式(カンマ区切りのテキストファイル)で保存します。
以下、コードです。
X_predict.to_csv('X_predict.csv')
X_tmp.to_csv('X_tmp.csv')
y_predict.to_csv('y_predict.csv')
y_tmp.to_csv('y_tmp.csv')
- 学習プログラムで使うCSVファイル
- X_tmp.csv : 特徴量(説明変数)
- y_tmp.csv : 目的変数
- 予測プログラムで使うCSVファイル
- X_predict.csv : 特徴量(説明変数)
- y_predict.csv : 目的変数
後で、学習プログラムと予測プログラムから読み込んで利用します。
学習プログラムと予測プログラムの流れの概要
以下が学習プログラムの流れです。
- 必要なライブラリの読み込み
- データセットの読み込み
- データセットを学習用・検証用に分割する
- 学習用データセットでモデルを学習する
- 検証用データセットで学習したモデルを検証する
- 学習したモデルを保存する

先ほどお話ししましたが、第3回と第4回で紹介したのは学習プログラムとの違いは、最後に学習済モデルの保存があることです。
モデルを学習したら、次にそのモデルを呼び出して使います。そのプログラムが予測プログラムです。
以下が予測プログラムの流れです。
- 必要なライブラリの読み込み
- データセットの読み込み
- 学習済モデルの読み込み
- 予測用データセットを学習済モデルで予測

非常に簡単です。予測プログラムから学習済モデルを読み込み予測するだけです。
学習プログラム
1.必要なライブラリの読み込み

機械学習モデルを作るために必要なライブラリ一式を読み込んでおきます。
読み込むライブラリは……
- 分類問題を解くためのTPOTClassifierモジュール
- データセットを学習用と検証用に分割するtrain_test_split
- 分類の良さを示す指標であるF1スコアを算出するためのf1_scoreモジュール
- モデルの分類状況を表示する混合行列を作成するconfusion_matrixモジュール
- 数値計算モジュールであるNumPy
- データ解析モジュールであるpandas
……です。
{kind=link}
from tpot import TPOTClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import f1_score from sklearn.metrics import confusion_matrix import numpy as np import pandas as pd
2.データセットの読み込み

以下、コードです。
X_tmp = pd.read_csv('X_tmp.csv',index_col=[0])
y_tmp = pd.read_csv('y_tmp.csv',index_col=[0],squeeze=True)
- X_tmp : 特徴量(説明変数)
- y_tmp : 目的変数
Jupyter Notebookに変数名を単体で入力するだけで、中身を確認することができます。
以下、コードです。
X_tmp
以下、実行結果です。
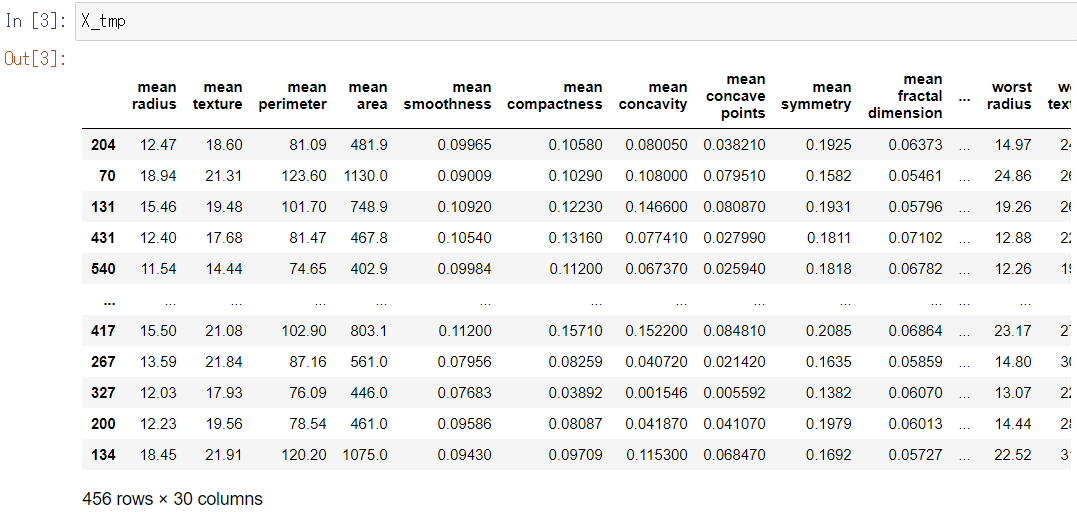
以下、コードです。
y_tmp
以下、実行結果です。
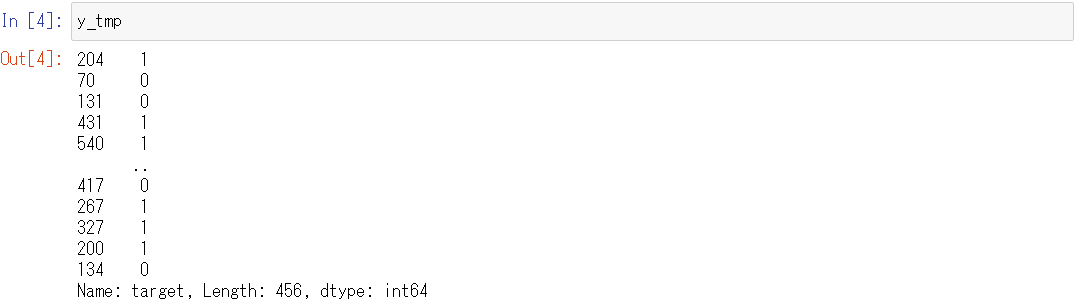
3.データセットを学習用・検証用に分割する

数理モデルを作成するときは、モデルが一定の性能を満たしているか検証するために、データセットを「学習用のデータセット」と「検証用のデータセット」にわけておきます。
- 学習用のデータセット
- 学習用の特徴量をX_trainに格納
- 学習用の目的変数をy_trainに格闘
- 検証用のデータセット
- 検証用の特徴量をX_testに格納
- 検証用の目的変数をy_testに格闘
今回は学習用のデータを75%、検証用のデータを25%に分けます。
以下、コードです。
X_train, X_test, y_train, y_test = train_test_split(X_tmp,
y_tmp,
train_size=0.75,
random_state=42,
shuffle=True)
「学習用のデータセット」と「検証用のデータセット」の行数を確認します。
以下、コードです。
print(len(X_train)) print(len(X_test))
以下、実行結果です。

4.学習用データセットでモデルを学習する

以下、コードです。
tpot = TPOTClassifier(scoring='f1',
generations=5,
population_size=50,
random_state=42,
verbosity=2,
n_jobs=-1)
tpot.fit(X_train, np.array(y_train))
分離問題ですので、TPOTClassifierを設定します。学習はtpot.fit関数でします。詳細は、第3回をご覧ください。
以下、実行結果です。
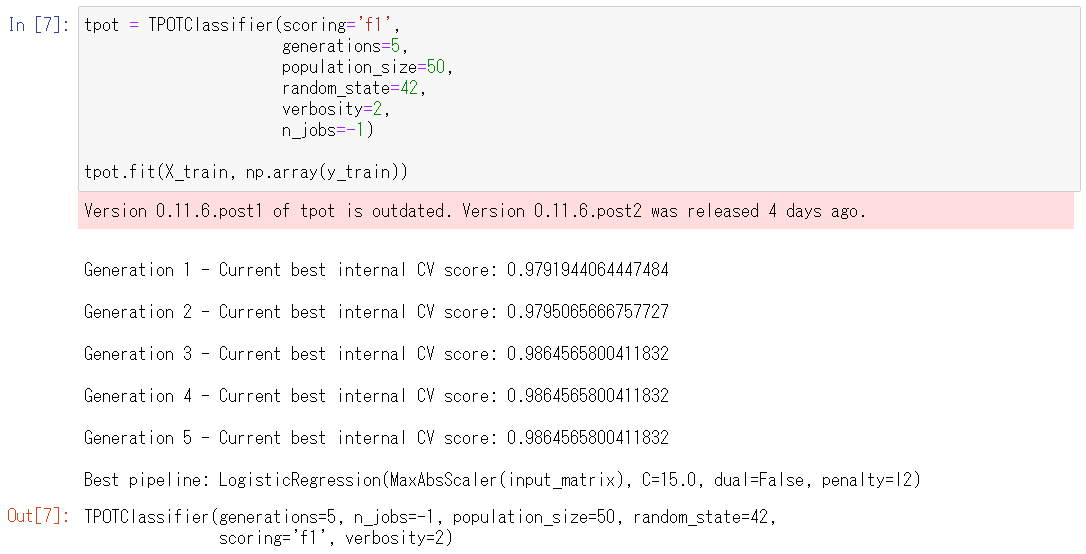
5.検証用データセットで学習したモデルを検証する

学習済みモデルの検証です。
検証用データセットを学習済みモデルで予測してみて、分類問題の評価指標の一つであるF1スコアを計算します。F1スコアが望む性能を満たせば機械学習モデルの作成は完了です。
以下、コードです。
y_pred = tpot.predict(X_test) f1_score(y_true=y_test, y_pred=y_pred)
以下、実行結果です。

計算されたF1スコアを出力してみると、95%で、評価指標からも非常によく分類できていることがわかります(※数値は状況によって微妙に異なります)。
最後に、TPOTが作成したモデルがどのように予測したのか見てみましょう。
y_predに予測結果が格納されています。
予測結果y_predと正解データであるy_testの結果を比べてみます。
以下、コードです。
pd.DataFrame(data={'y_pred':y_pred,'y_test':y_test})
以下、実行結果です。
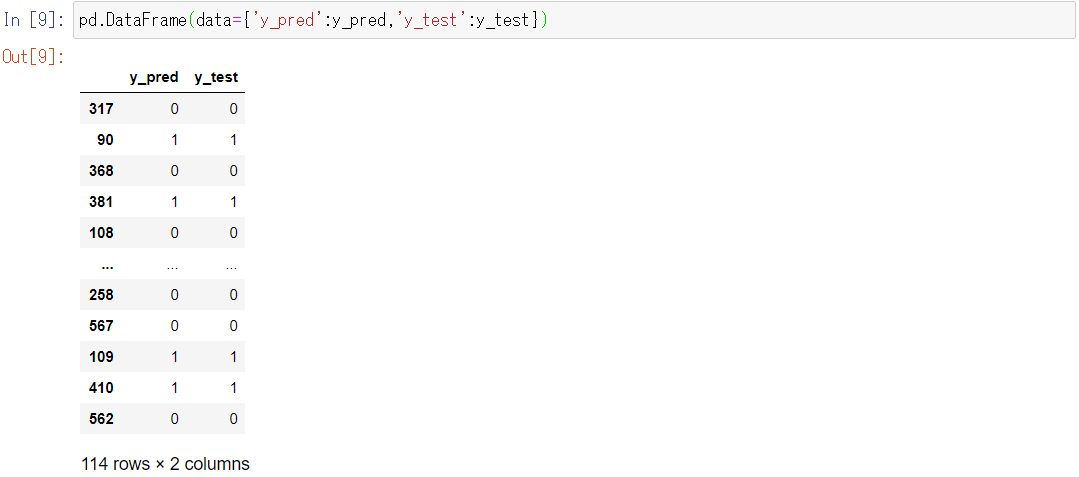
表示される範囲では、予測結果y_predと正解データのy_testがほぼ一致しています。
実際にどれだけ一致しているか、混同行列を作成してみてみます。
以下、コードです。
confusion_matrix(y_pred=y_pred,y_true=y_test)
以下、実行結果です。
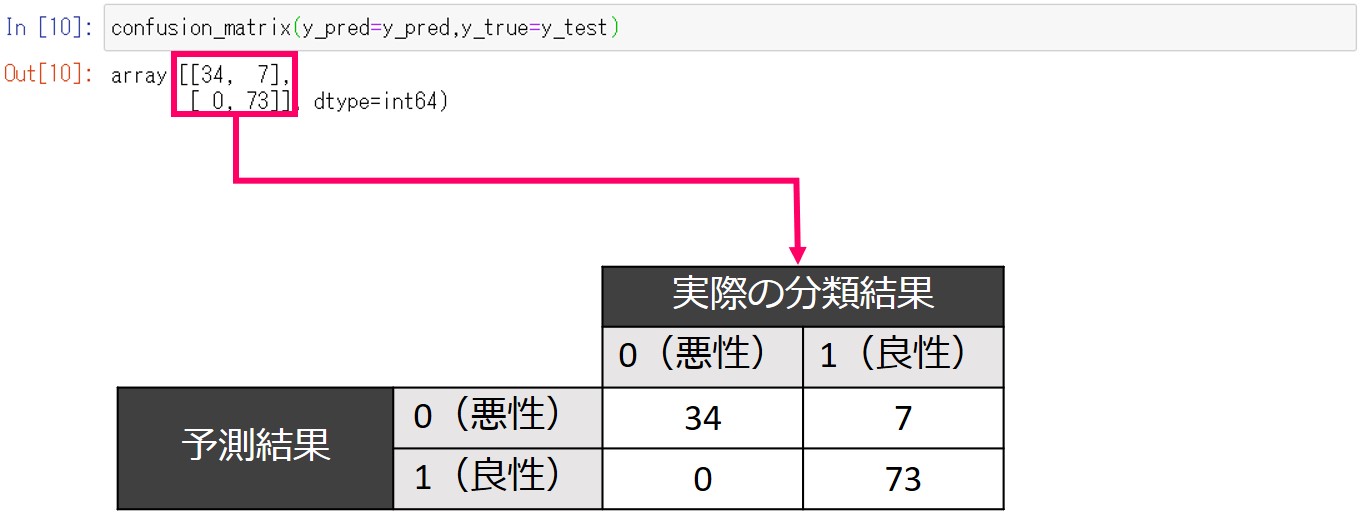
6.学習したモデルを保存する

前準備が長くなりましたが、ここが今回の肝です。
学習済みモデルをプログラムの外部に保存しておきます。
以下、コードです。
pd.to_pickle(obj=tpot.fitted_pipeline_,
filepath_or_buffer='tpot_classiffier_breast_cancer.pkl')
学習済モデルはtpot.fitted_pipeline_に保存されています。
これをpickle形式で保存しておくことで、予測プログラムからこの学習済モデルを読み込むことができます。
to_pickle関数でtpot.fitted_pipeline_を保存しておきましょう。filepath_or_bufferで保存先のファイル名を指定できます。
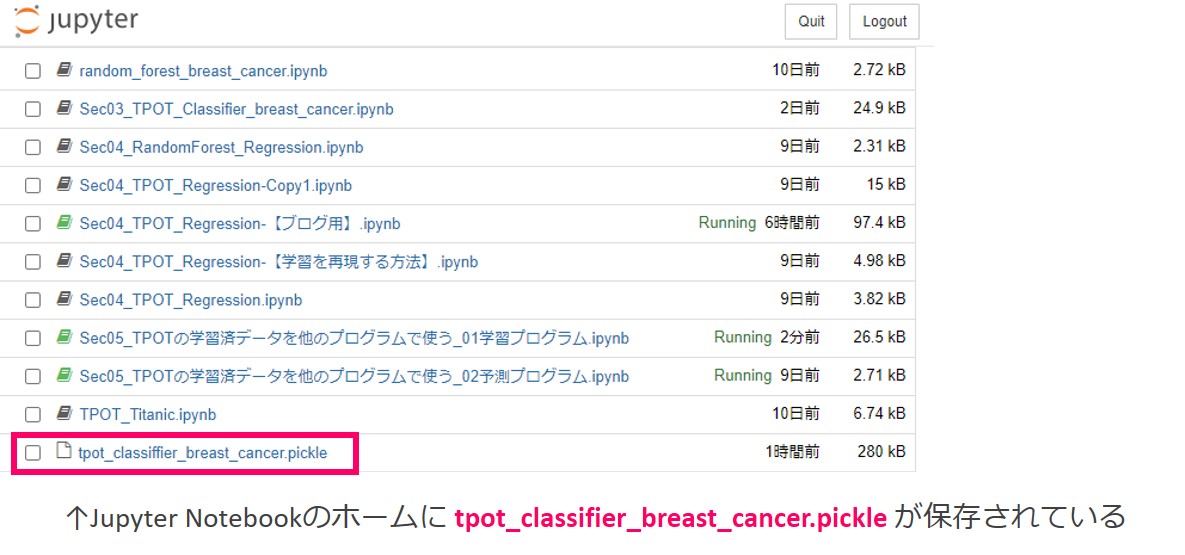
Jupyter Notebookのホームで、保存されたtpot_classifier_breast_cancer.pickleを確認することができます。
予測プログラム
1.必要なライブラリの読み込み

必要なライブラリ一式を読み込んでおきます。
読み込むライブラリは……
- 分類問題を解くためのTPOTClassifierモジュール
- 分類の良さを示す指標であるF1スコアを算出するためのf1_scoreモジュール
- モデルの分類状況を表示する混合行列を作成するconfusion_matrixモジュール
- 数値計算モジュールであるNumPy
- データ解析モジュールであるpandas
……です。
以下、コードです。
from tpot import TPOTClassifier from sklearn.metrics import f1_score from sklearn.metrics import confusion_matrix import numpy as np import pandas as pd
2.データセットの読み込み

以下、コードです。
X_predict = pd.read_csv('X_predict.csv',index_col=[0])
y_predict = pd.read_csv('y_predict.csv',index_col=[0],squeeze=True)
- X_predict : 特徴量(説明変数)
- y_predict : 目的変数
Jupyter Notebookに変数名を単体で入力するだけで、中身を確認することができます。
以下、コードです。
X_predict
以下、実行結果です。
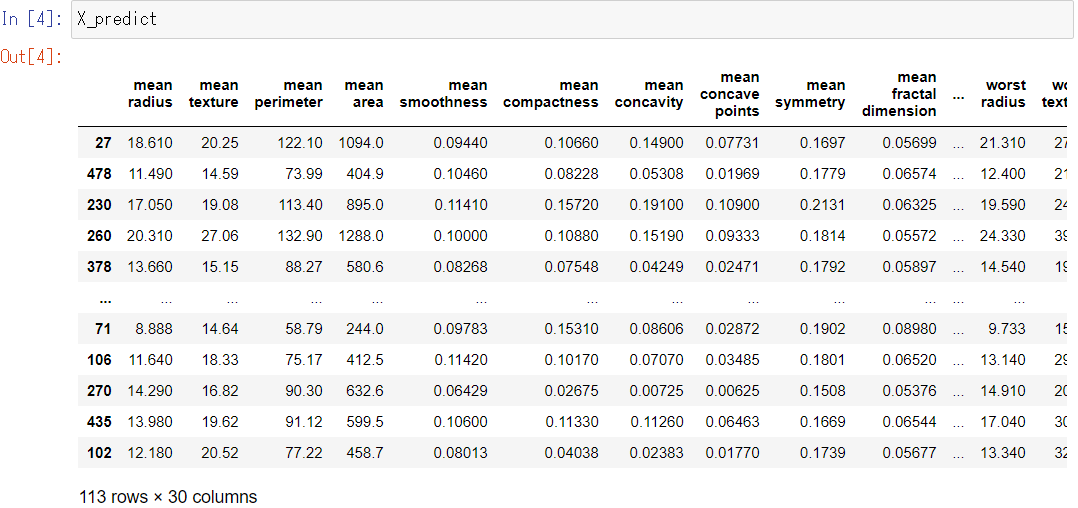
以下、コードです。
y_predict
以下、実行結果です。

3.学習済モデルの読み込み

ここが重要なところです。
学習プログラム内のread_pickle関数で保存した学習済モデルを読み込みます。
読み込んだモデルを変数tpotに格納します。学習プログラムのfilepath_or_bufferで指定したファイル名を引数に指定しましょう。
以下、コードです。
tpot = pd.read_pickle('tpot_classiffier_breast_cancer.pkl')
4.予測用データセットを学習済モデルで予測

学習済みモデルを使って予測をします。
以下、コードです。
y_pred = tpot.predict(X_predict) f1_score(y_true=y_predict, y_pred=y_pred)
以下、実行結果です。

計算されたF1スコアを出力してみると、96%で、評価指標からも非常によく分類できていることがわかります(※数値は状況によって微妙に異なります)。
最後に、TPOTが作成したモデルがどのように予測したのか見てみましょう。
y_predに予測結果が格納されています。
予測結果y_predと正解データであるy_testの結果を比べてみます。
以下、コードです。
pd.DataFrame(data={'y_pred':y_pred,'y_true':y_predict})
以下、実行結果です。
表示される範囲では、予測結果y_predと正解データのy_predictがほぼ一致しています。
実際にどれだけ一致しているか、混同行列を作成してみてみます。
以下、コードです。
confusion_matrix(y_pred=y_pred,y_true=y_predict)
以下、実行結果です。

ソースコードの全体像
予想用データセットと学習用データセットの生成
#1.必要なライブラリの読み込み
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
import pandas as pd
#2.データセットの読み込み
D = load_breast_cancer(as_frame=True)
X = D.data
y = D.target
#3.データセットを予測用と学習用に分割する
X_predict, X_tmp, y_predict, y_tmp = train_test_split(X,
y,
train_size=0.2,
random_state=42,
shuffle=True)
#4.生成した予測用データセットと学習用データセットを保存する
X_predict.to_csv('X_predict.csv')
X_tmp.to_csv('X_tmp.csv')
y_predict.to_csv('y_predict.csv')
y_tmp.to_csv('y_tmp.csv')
学習プログラム
#1.必要なライブラリの読み込み
from tpot import TPOTClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score
from sklearn.metrics import confusion_matrix
import numpy as np
import pandas as pd
#2.データセットの読み込み
X_tmp = pd.read_csv('X_tmp.csv',index_col=[0])
y_tmp = pd.read_csv('y_tmp.csv',index_col=[0],squeeze=True)
#3.データセットを学習用・検証用に分割する
X_train, X_test, y_train, y_test = train_test_split(X_tmp,
y_tmp,
train_size=0.75,
random_state=42,
shuffle=True)
#4.学習用データセットでモデルを学習する
tpot = TPOTClassifier(scoring='f1',
generations=5,
population_size=50,
random_state=42,
verbosity=2,
n_jobs=-1)
tpot.fit(X_train, np.array(y_train))
#5.検証用データセットで学習したモデルを検証する
y_pred = tpot.predict(X_test)
f1_score(y_true=y_test, y_pred=y_pred)
#6.学習したモデルを保存する
pd.to_pickle(obj=tpot.fitted_pipeline_,
filepath_or_buffer='tpot_classiffier_breast_cancer.pkl')
予測プログラム
#1.必要なライブラリの読み込み
from tpot import TPOTClassifier
from sklearn.metrics import f1_score
from sklearn.metrics import confusion_matrix
import numpy as np
import pandas as pd
#2.データセットの読み込み
X_predict = pd.read_csv('X_predict.csv',index_col=[0])
y_predict = pd.read_csv('y_predict.csv',index_col=[0],squeeze=True)
#3.学習済モデルの読み込み
tpot = pd.read_pickle('tpot_classiffier_breast_cancer.pkl')
#4.予測用データセットを学習済モデルで予測
y_pred = tpot.predict(X_predict)
f1_score(y_true=y_predict, y_pred=y_pred)
次回
今回は、TPOTで学習した最適な数理モデルをそのまま活用する方法を説明しました。
TPOTは、単に最適な数理モデルを構築するだけでなく、その前の特徴量生成やその選定を含めたパイプライン(特徴量生成・特徴量選定・モデル学習など)を最適化するものです。
そのため、正確には「TPOTで学習した最適な数理モデル」ではなく「TPOTで構築した最適なパイプライン」という表現が適切です。
そうなると、どのようなパイプラインになったのか気になるところです。
次回は、TPOTで構築した最適なパイプライン(特徴量生成・特徴量選定・モデル学習など)の見方などについて説明します。
このパイプライン見ることで、自力で数理モデルを構築するときの参考になります。