

前回、精度やメモリ使用量、実行速度に応じたTPOTが用意した構成(Config.)を使う方法を説明しました。
| 構成名 | 内容 | 適用できる問題 |
| Default TPOT | 初期設定の構成です。 | 分類・回帰 |
| TPOT light | Default TPOTに比べて、シンプルで高速な変換器やアルゴリズムが使われています。早く結果がほしいときにはこちらが適しています。 | 分類・回帰 |
| TPOT MDR | ゲノムワイド関連研究(GWAS)に特化した変換器やアルゴリズムの組み合わせが使われます。予測精度を最大化するパイプラインを得ることができます。ただし、特徴量選択を何度も行うので、大規模データセットの場合実行に時間がかかることがあります。 | 分類・回帰 |
| TPOT sparse | 内部で疎行列(sparse matrix)形式を使うことで、メモリを節約しながらパイプラインの最適化をできる構成です。 | 分類・回帰 |
| TPOT NN | Default TPOTに加え、Pytorchのニューラルネットワーク推定器を使うことができます。 | 分類 |
| TPOT cuML | GPU上で動く機械学習ライブラリである、RAPIDS cuMLを使ってパイプラインの最適化ができます。大規模なデータセットを処理するのに向いています。 | 分類・回帰 |
今回は、自分でパイプライン構築に使う関数を指定する方法を説明します。
要は、構成(Config.)をカスタマイズし使用する方法です。
Contents
全体の流れ
以下、構成(Config.)をカスタマイズし使用する場合の流れです。
- 1.必要なモジュールの読み込み
- 2.データセットの読み込み
- 3.データセットを学習用と検証用に分割
- 4.pythonの辞書形式で構成(Config.)作成
- 5.TPOTClassifierの設定(作成したconfigを指定)
- 6.学習用データセットを使った学習
- 7.検証用データセットを使った予測結果の評価
通常のTPOT利用方法と違うのは、4と5です。
それぞれについて、解説していきます。
1.必要なモジュールの読み込み
まずは必要なモジュールを読み込みます。
以下、コードです。
# 1.必要なモジュールの読み込み from tpot import TPOTClassifier from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.metrics import f1_score
読み込んだモジュールは次のとおりです。
- TPOTClassifier … TPOTで分類問題を解くためのモジュールです
- load_breast_cancer … 今回の例で使うデータセットの、乳がんの分類結果です
- train_test_split … データセットを学習用と検証用に分けるためのモジュールです
- f1_score … 予測結果のF値を算出するためのモジュールです
2.データセットの読み込み
分類問題を例にとります。
乳がんのデータセット(特徴量と目的変数)が格納されたload_breast_cancerを読み込みます。特徴量をXに、目的変数をyに格納します。
以下、コードです。
# 2.データセットの読み込み load_breast_cancer = load_breast_cancer(as_frame=True) X = load_breast_cancer.data y = load_breast_cancer.target
3.データセットを学習用と検証用に分割
データセットを学習用と検証用に分けます。
以下、コードです。
# 3.データセットを学習用と検証用に分割
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
train_size=0.75,
test_size=0.25,
random_state=42)
print('X_trainの行数:' + str(len(X_train))) #確認用
print('y_trainの行数:' + str(len(y_train))) #確認用
print('X_testの行数:' + str(len(X_test))) #確認用
print('y_testの行数:' + str(len(y_test))) #確認用
X_trainとy_trainが学習データ、X_testとy_testが検証用データです。
以下、実行結果です。
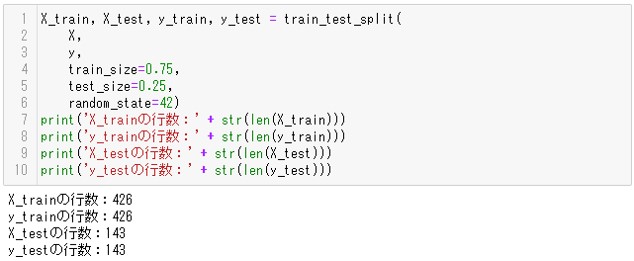
print文でデータの行数を表示することで、約75%の学習用データと約25%の検証用データに分かれたことがわかります。
4.pythonの辞書形式で構成(Config.)作成
簡単に前回の復習をします。
TPOTで構成(config.)を指定するには、TPOTClassifierのconfig_dictパラメータに構成(config.)を指定します(回帰問題の場合はTPOTRegressorのconfig_dictパラメータです)。
例えば下図は、TPOTがあらかじめ用意している構成(config.)である’TPOT light’を使うときの設定例です。

このconfig_dictに自分が作った構成(config.)を指定することで、好きな関数を使うことができます。
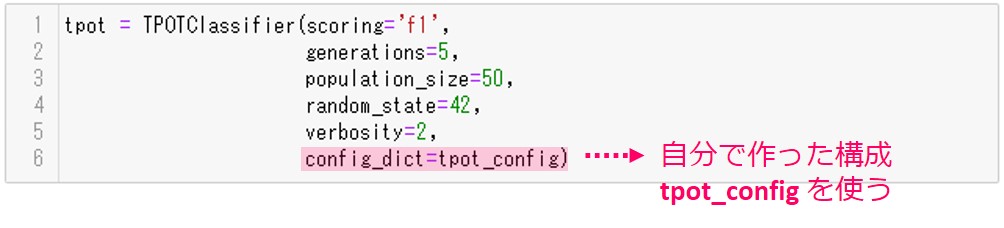
下図は、自分が作った構成(config.)を使うときの設定例です。自分が作った構成(config.)は’tpot_config’に格納しています。
では、構成(config.)の作り方を説明します。今回は、自分が作った構成(config.)は’tpot_config’に格納します。
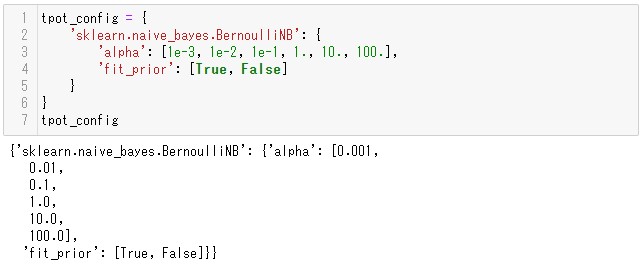
tpot_configの中身は2つの階層を意識して作ります。
第1階層には、使いたい関数(ここでは’sklearn.naive_bayes.BernoulliNB’)を指定します。
第2階層には、第1階層で指定した関数(’sklearn.naive_bayes.BernoulliNB’)の探索したいパラメータ範囲を指定します。

今回の例は、パラメータalphaとfit_priorについて、探索してほしい値を指定しています。
- alphaについては、0.001(1e-3)、0.01(1e-2)、0.1(1e-1)、1、10、100のうちどれが最適であるか探索します
- fit_priorについては、TrueとFalseのどちらが最適であるか探索します
使いたい関数を増やすには、以下のように辞書の第1階層にどんどん関数を追加します。そして、それぞれの2階層にそれぞれの関数のパラメータの探索範囲を記載します。

今回は説明を簡単にするために、tpot_configに’sklearn.naive_bayes.BernoulliNB’だけを指定して使ってみることにします。
以下、コードです。
# 4.pythonの辞書形式で構成(Config.)作成
tpot_config = {
'sklearn.naive_bayes.BernoulliNB': {
'alpha': [1e-3, 1e-2, 1e-1, 1., 10., 100.],
'fit_prior': [True, False]
}
}
tpot_config #確認用
以下、実行結果です。
5.TPOTClassifierの設定(作成したConfig.を指定)
TPOTClassifierのconfig_dictパラメータに、先ほど作った構成(Config.)を指定します(今回はtpot_config)。
そうすると、その構成(Config.)を使ってパイプラインを最適化してくれます。
以下、コードです。
# 5.TPOTClassifierの設定(作成したconfigを指定)
tpot = TPOTClassifier(scoring='f1',
generations=5,
population_size=50,
random_state=42,
verbosity=2,
config_dict=tpot_config)
tpot #確認用
以下、実行結果です。
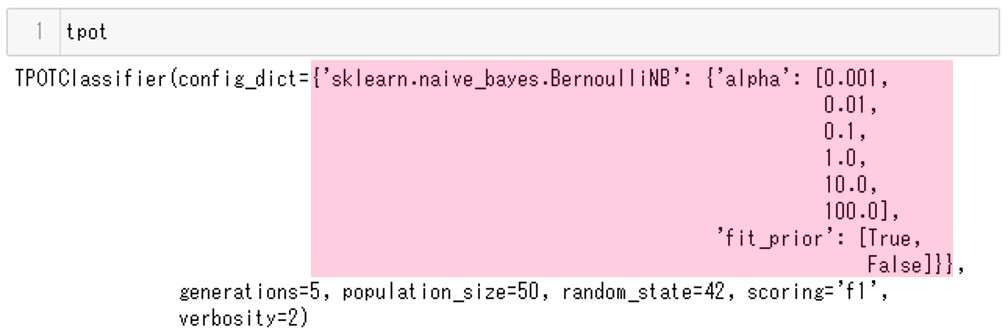
’sklearn.naive_bayes.BernoulliNB’がconfig_dictとして設定されていることがわかります。
6.学習用データセットを使った学習
では、学習してみましょう。
以下、コードです。
# 6.学習用データセットを使った学習 tpot.fit(X_train, y_train)
以下、実行結果です。
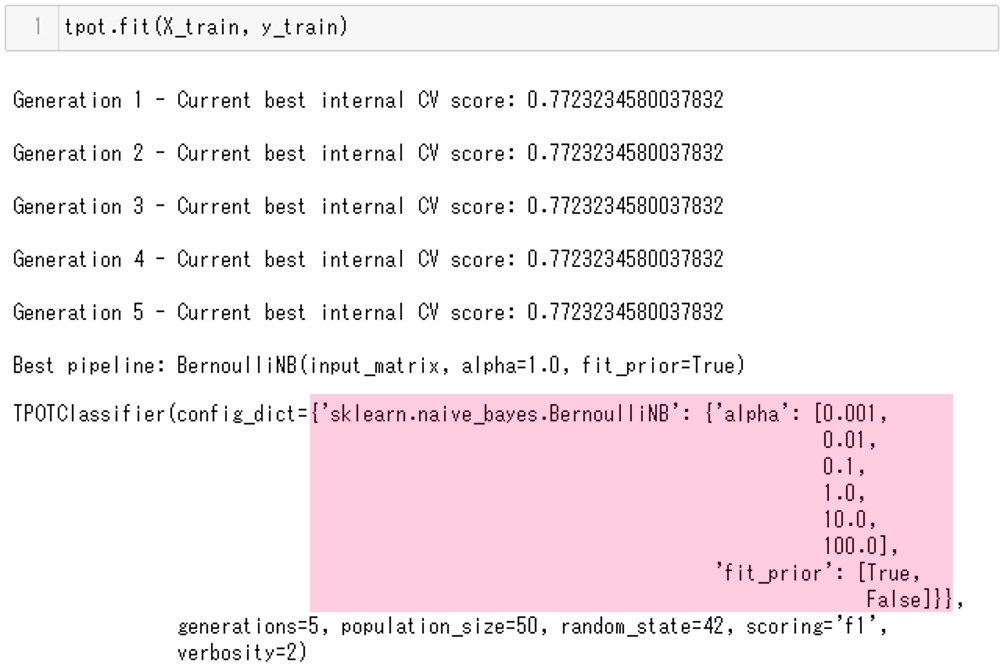
本当に’sklearn.naive_bayes.BernoulliNB’だけ使われたのでしょうか。
AutoML【TPOT】で学習し評価されたすべてのパイプラインを確認してみます。
以下、コードです。
tpot.evaluated_individuals_
以下、実行結果です。
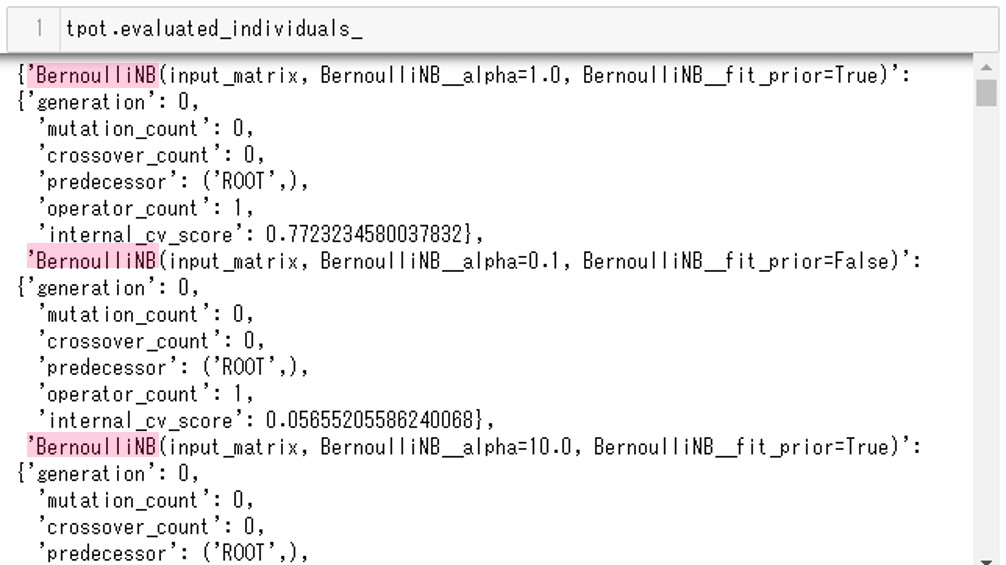
確かにBernoulliNBが毎回使われていることがわかります。今回は途中までしか表示させていませんが、最後まで見てもBernoulliNBのみが使われています。
7.検証用データセットを使った予測結果の評価
検証用データセット(テストデータ)を使って、予測結果を評価します。
以下、コードです。
# 7.検証用データセットを使った予測結果の評価
y_pred = tpot.predict(X_test)
f1 = f1_score(y_true=y_test, y_pred=y_pred)
print('f1_score=' + str(f1))
以下、実行結果です。

F値は約0.77であることがわかります。
config_dictを指定せずTPOTのデフォルトの構成’Default TPOT’を使ったときは、f1=0.98程度の精度だったので、BernoulliNBだけではあまり精度が出ないことがわかります。
プログラムの全体像
# 1.必要なモジュールの読み込み
from tpot import TPOTClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score
# 2.データセットの読み込み
load_breast_cancer = load_breast_cancer(as_frame=True)
X = load_breast_cancer.data
y = load_breast_cancer.target
# 3.データセットを学習用と検証用に分割
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
train_size=0.75,
test_size=0.25,
random_state=42)
print('X_trainの行数:' + str(len(X_train))) #確認用
print('y_trainの行数:' + str(len(y_train))) #確認用
print('X_testの行数:' + str(len(X_test))) #確認用
print('y_testの行数:' + str(len(y_test))) #確認用
# 4.pythonの辞書形式で構成(Config.)作成
tpot_config = {
'sklearn.naive_bayes.BernoulliNB': {
'alpha': [1e-3, 1e-2, 1e-1, 1., 10., 100.],
'fit_prior': [True, False]
}
}
tpot_config #確認用
# 5.TPOTClassifierの設定(作成したconfigを指定)
tpot = TPOTClassifier(scoring='f1',
generations=5,
population_size=50,
random_state=42,
verbosity=2,
config_dict=tpot_config)
tpot #確認用
# 6.学習用データセットを使った学習
tpot.fit(X_train, y_train)
tpot.evaluated_individuals_
# 7.検証用データセットを使った予測結果の評価
y_pred = tpot.predict(X_test)
f1 = f1_score(y_true=y_test, y_pred=y_pred)
print('f1_score=' + str(f1))
次回
次回は、TPOTの仕組みをかんたんに説明しようと思います。