

前回、パイプラインの評価指標を一覧にしました。
実際にTPOTを使うときに、使いたい評価指標が実装されていないこともあると思います。
例えば回帰問題でよく使われるRMSE(Root Mean Squared Error、二乗平均平方根誤差)はTPOTに実装されていません。このようなときには、自分で評価指標を設定することができます。
今回は、「評価指標を自分で作る方法」について説明します。
Contents
ソースコードの概要
以前も例示したfetch_california_housing(カリフォルニアの住宅価格)の回帰問題を使って説明します。
以下は、ソースコードの全体像です。すでに説明した内容も入っていますので、自作の評価指標の使い方だけ知りたい方は、④と⑤の説明だけ読んでも結構です。
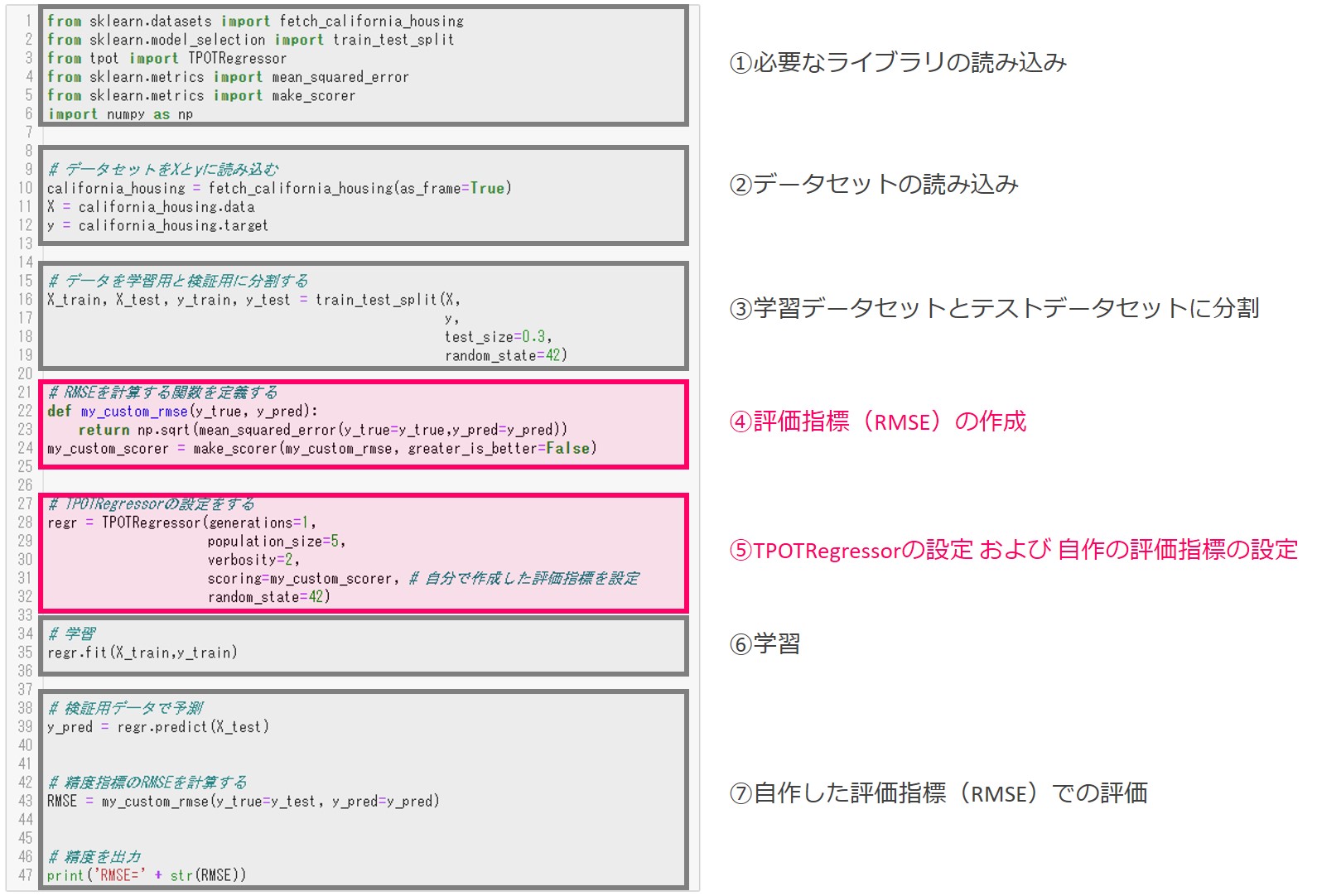
①~⑦まで実行結果も踏まえて詳細に説明します。
ソースコードの説明
①必要なライブラリーの読み込み
先ずは、必要なライブラリーを読み込みます。
以下、コードです。
from sklearn.datasets import fetch_california_housing from sklearn.model_selection import train_test_split from tpot import TPOTRegressor from sklearn.metrics import mean_squared_error from sklearn.metrics import make_scorer import numpy as np
- fetch_california_housing:カリフォルニアの住宅価格のデータセットを読みこむためのモジュールです。
- train_test_split:データセットを学習用と検証用に分割するためのモジュールです。
- TPOTRegressor :TPOTで回帰問題を解くためのモジュールです。
- mean_squared_error:評価指標のMSEです。今回評価指標として使うRMSEを計算するために読み込みます。
- make_scorer:パイプラインの評価で自作の評価指標を使うためのモジュールです。
- numpy:mean_squared_errorからRMSEを計算するために使います。
②データセットの読み込み
次に、データセットを読み込みます。特徴量をXに、目的変数をyに格納します。
以下、コードです。
# データセットをXとyに読み込む california_housing = fetch_california_housing(as_frame=True) X = california_housing.data y = california_housing.target
データを確認してみます。
以下、Xの中を見るコードです。
X
以下、実行結果です。
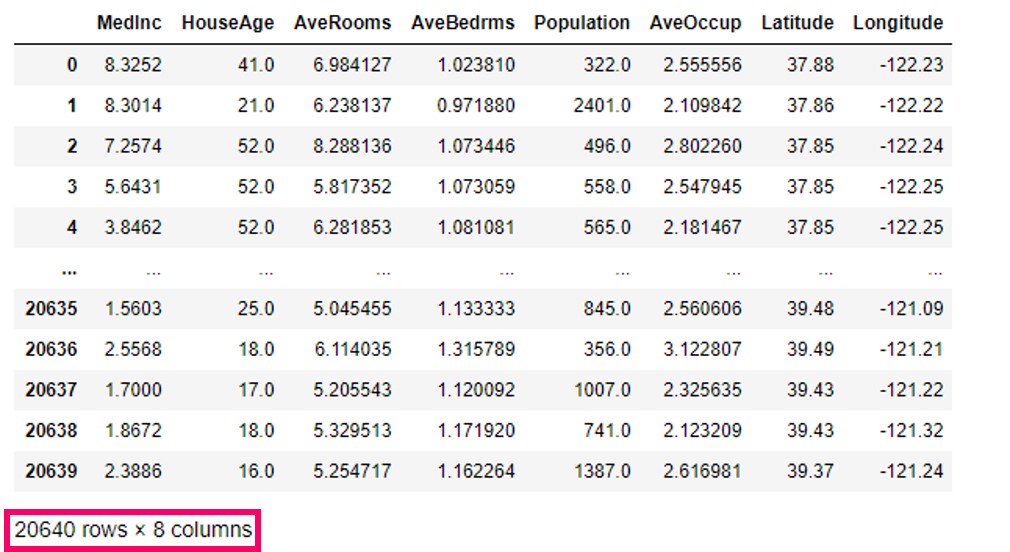
特徴量Xには20,640行×8列のデータが読み込まれていることがわかります。
以下、yの中を見るコードです。
y
以下、実行結果です。

目的変数yには20,640行のデータが読み込まれていることがわかります。
③学習データとテストデータに分割
読み込んだデータセットを、学習データとテストデータに分割します。
以下、コードです。
# データを学習用とテスト用に分割する
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size=0.3,
random_state=42)
- X_train:学習データの特徴量
- X_test:テストデータの特徴量
- y_train:学習データの目的変数
- y_test:テストデータの目的変数
test_sizeパラメータに0.3を指定しているので、テストデータ30%、学習データ70%に分割します。
次のソースコードで、X_train, X_test, y_train ,y_testにどれだけデータが格納されたか確認することができます。
以下、コードです。
print(np.shape(X_train)) # X_trainの行数と列数を確認 print(np.shape(y_train)) # y_trainの行数と列数を確認 print(np.shape(X_test)) # X_testの行数と列数を確認 print(np.shape(y_test)) # y_testの行数と列数を確認
以下、実行結果です。

学習データX_train, y_trainは14,448行で14,448÷20,640=70%のデータ、テストデータX_test,y_testは6,192行で6,192÷20,640=30%のデータが格納されていることがわかります。test_train_split関数のtest_sizeパラメータで指定したとおりです。
④評価指標(RMSE)の作成
今回は評価指標としてRMSE(Root Mean Squared Error、二乗平均平方根誤差)を使います。
RMSEは予測結果と実際の値がどれだけ離れているか測る指標です。小さいほど予測が良いことを示します。
RMSEの関数をmy_custom_rmseという名前で作ります。
def my_custom_rmse(y_true, y_pred):
return np.sqrt(mean_squared_error(y_true=y_true,y_pred=y_pred))
RMSE(Root Mean Squared Error)はその名のとおり、MSE(Mean Squared Error)の平方根です。
なので、まずはsklearnに実装されている評価指標MSEを、mean_squared_error関数で計算します。y_trueが目的変数の正解データ、y_predが目的変数の予測データです。np.sqrtで平方根を計算できます。
試しに……
- 目的変数の正解データ(y_true):0, 0
- 目的変数の予測データ(y_pred):2, 2
……のデータで計算してみましょう。
以下、コードです。
my_custom_rmse(y_true=[0,0], y_pred=[2,2])
以下、実行結果です。
![]()
2が返ってきました。
計算し確かめてみます。
RMSE = \sqrt{\frac{1}{n}\sum_{i=1}^n(y_i^{true}-{y_i^{pred}})^2} = \sqrt{\frac{1}{2} \{ (0-2)^2 + (0-2)^2 \} } = 2
次に、my_scorer関数を使ってTPOTへ自作のRMSEを渡します。
TPOTはsklearnのcross_val_score関数を使ってパイプラインの評価をします。このcross_val_scoreに自作の評価指標の関数を渡すために使うのがmake_scorerです。
以下、コードです。
my_custom_scorer = make_scorer(my_custom_rmse, greater_is_better=False)
⑤TPOTRegressorの設定および自作の評価指標の設定
TPOTRegressorの設定をします。
scoreパラメータに④で自作したmy_custom_scorerを指定すると、RMSEでパイプラインを評価してくれます。
以下、コードです。regrと入力すると、設定されたパラメータを確認できます。
# TPOTRegressorの設定をする
regr = TPOTRegressor(generations=1,
population_size=5,
verbosity=2,
scoring=my_custom_scorer, # 自分で作成した評価指標を設定
random_state=42)
regr
以下、実行結果です。

scoringパラメータに自作のRMSE関数が渡されたことがわかります。
⑥学習
TPOTを学習データで学習します。
以下、コードです。
# 学習 regr.fit(X_train,y_train)
以下、実行結果です。

⑦自作した評価指標(RMSE)での評価
自作したRMSEを算出するmy_custom_rmse関数を使って精度を算出してみます。
以下、コードです。
# 検証用データで予測
y_pred = regr.predict(X_test)
# 精度指標のRMSEを計算する
RMSE = my_custom_rmse(y_true=y_test, y_pred=y_pred)
# 精度を出力
print('RMSE=' + str(RMSE))
以下、実行結果です。
![]()
RMSEは約0.52となりました。
ソースコード全体
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from tpot import TPOTRegressor
from sklearn.metrics import mean_squared_error
from sklearn.metrics import make_scorer
import numpy as np
# データセットをXとyに読み込む
california_housing = fetch_california_housing(as_frame=True)
X = california_housing.data
y = california_housing.target
# データを学習用とテスト用に分割する
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size=0.3,
random_state=42)
# RMSEを計算する関数を定義する
def my_custom_rmse(y_true, y_pred):
return np.sqrt(mean_squared_error(y_true=y_true,y_pred=y_pred))
my_custom_scorer = make_scorer(my_custom_rmse, greater_is_better=False)
# TPOTRegressorの設定をする
regr = TPOTRegressor(generations=1,
population_size=5,
verbosity=2,
scoring=my_custom_scorer, # 自分で作成した評価指標を設定
random_state=42)
# 学習
regr.fit(X_train,y_train)
# 検証用データで予測
y_pred = regr.predict(X_test)
# 精度指標のRMSEを計算する
RMSE = my_custom_rmse(y_true=y_test, y_pred=y_pred)
# 精度を出力
print('RMSE=' + str(RMSE))
次回
次回は、とく利用されるTPOT独自の変換器について説明します。