

第9回「AutoML【TPOT】のパイプラインに使われる関数一覧」で、TPOTのパイプライン(特徴量生成・予測)で使われる関数の概要を説明しました。
その中には、TPOT独自の関数がいくつかありました。
分類問題・回帰問題ともに、とく利用されるTPOT独自の変換器は次の3つです。
- tpot.builtins.ZeroCount
- tpot.builtins.OneHotEncoder
- tpot.builtins.StackingEstimator
Scikit-Learn(sklearn)などにも似たようなことのできるものはありますが、独自の工夫がなされています。
今回は、その中で「ZeroCount変換器」について説明します。
ZeroCount変換器とは?
ZeroCountは特徴量生成に使われる関数です。
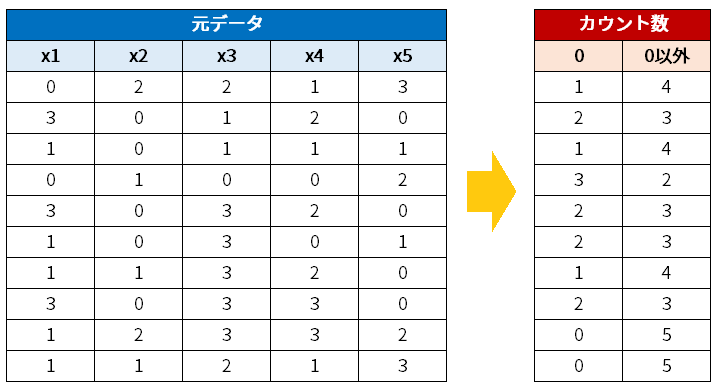
2次元配列を入力として、行ごとにゼロと、ゼロでない値の数を数えて、その数をもとの特徴量に付け加えて新しい特徴量とします。
それでは実際にZeroCountを使ってみましょう。
ZeroCountの挙動を確かめてみよう!
サンプルデータをnumpyで作り、ZeroCountの挙動を確かめます。
先ず、必要なライブラリーを読み込みます。
以下、コードです。
from tpot.builtins import ZeroCount import numpy as np
次に、NumPyでサンプルデータ(2次元配列)を作ります。
例えば、次のようなサンプルデータ(2次元配列)を作ったとします。
X = np.array(
[[0, 10, 2.2],
[0, 0, 5 ],
[0, 0, 0 ]])
print(X)
以下、実行結果です。

ZeroCountの中のfit_transform関数で新しい特徴量を生成します。
以下、コードです。
ZeroCount().fit_transform(X)
以下、実行結果です。
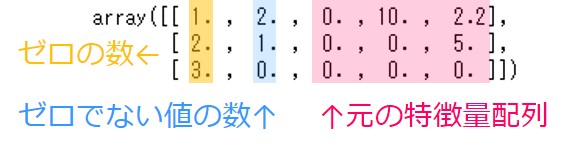
右側3列が元の特徴量配列です。
左から1列目がゼロの数を行ごとに数えた列です。1行目はゼロが1個、2行目はゼロが2個、3行目はゼロが3個です。一番左の列を見るとその通りになっています。
左から2列目がゼロでない値を行ごとに数えた列です。1行目が2個、2行目が1個、3行目が0個で、そのとおりになっています。
ZeroCountの説明で使ったコード全体
from tpot.builtins import ZeroCount
import numpy as np
X = np.array(
[[0, 10, 2.2],
[0, 0, 5 ],
[0, 0, 0 ]])
print(X)
ZeroCount().fit_transform(X)
次回
次回は、とく利用されるTPOT独自の変換器の1つである「OneHotEncoder」について説明します。