

TPOTでは、あらかじめパイプラインに使う変換器やアルゴリズム、探索するパラメータの範囲が決まっています。
しかし、あまり探索に時間をかけたくないときや単純な変換器・アルゴリズムを使いたいときがあると思います。

逆に時間がかかっても良いので、精度を高めるためにじっくり探索してほしいときや、複雑だけれど精度の高いアルゴリズムを使ってほしいときもあると思います。

そんなときはTPOTの構成(config.)を適切に設定することで、目的に応じたパラメータ範囲・変換器・アルゴリズムを使い、速く実行できるようにしたり、より高い精度を求めることができます。
構成を変えるに2種類の方法があります。
- TPOTがあらかじめ用意した構成を使う
- 自分で構成を設定する
今回は「TPOTがあらかじめ用意した構成を使う方法」を紹介します。
Contents
構成は6種類用意されています
| 構成名 | 内容 | 適用できる問題 |
| Default TPOT | 初期設定の構成です。 | 分類・回帰 |
| TPOT light | Default TPOTに比べて、シンプルで高速な変換器やアルゴリズムが使われています。早く結果がほしいときにはこちらが適しています。 | 分類・回帰 |
| TPOT MDR | ゲノムワイド関連研究(GWAS)に特化した変換器やアルゴリズムの組み合わせが使われます。予測精度を最大化するパイプラインを得ることができます。ただし、特徴量選択を何度も行うので、大規模データセットの場合実行に時間がかかることがあります。 | 分類・回帰 |
| TPOT sparse | 内部で疎行列(sparse matrix)形式を使うことで、メモリを節約しながらパイプラインの最適化をできる構成です。 | 分類・回帰 |
| TPOT NN | Default TPOTに加え、Pytorchのニューラルネットワーク推定器を使うことができます。 | 分類 |
| TPOT cuML | GPU上で動く機械学習ライブラリである、RAPIDS cuMLを使ってパイプラインの最適化ができます。大規模なデータセットを処理するのに向いています。 | 分類・回帰 |
詳細はこちら(http://epistasislab.github.io/tpot/using/#built-in-tpot-configurations)を参考にして頂ければと思います。
用意されている構成のうち、TPO MDRは、事前にモジュールをインストールする必要があります。事前に scikit-mdr と skrebate をインストールしておきます。
以下、コードです。
pip install scikit-mdr skrebate
構成(config)の選び方
- 高い精度を得たいとき → TPOT NN, TPOT sparse
- 速く実行したいとき → TPOT light
- メモリを節約したいとき → TPOT MDR
- 高い精度で速く実行したいとき → TPOT lightで、generationsパラメータとpopulation_sizeパラメータを指定し実行回数を増やす
構成の設定方法
分類問題を例にとります。
先ずは、今回の例で利用するプログラムの全体像です。
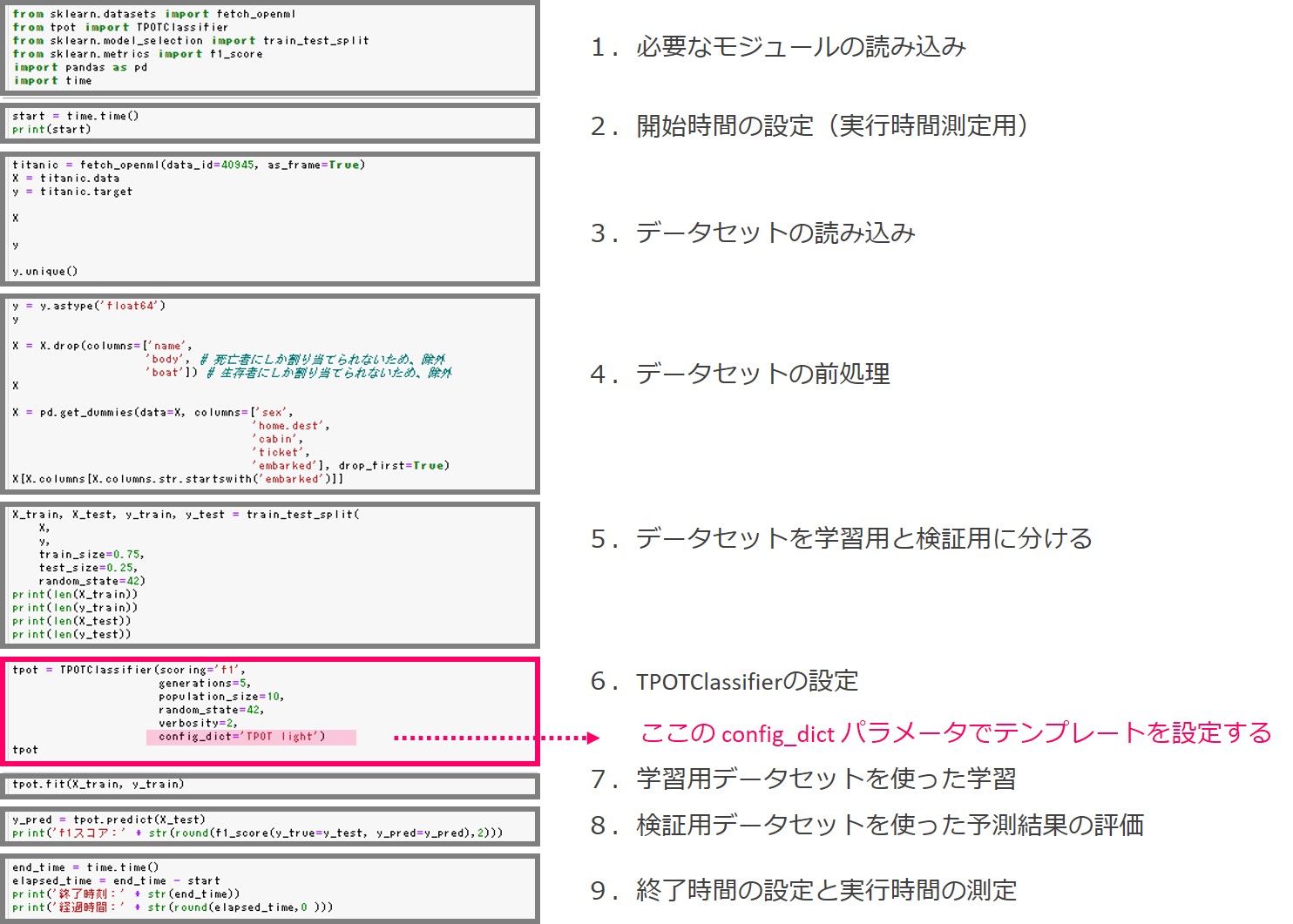
以下、実際のソースコードです。
# 1.必要なモジュールの読み込み
from sklearn.datasets import fetch_openml
from tpot import TPOTClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score
import pandas as pd
import time
# 2.開始時間の設定(実行時間測定用)
start = time.time()
print(start)
# 3.データセットの読み込み
titanic = fetch_openml(data_id=40945, as_frame=True)
X = titanic.data
y = titanic.target
X #確認用
y #確認用
# 4.データセットの前処理
y = y.astype('float64')
y #確認用
X = X.drop(columns=['name',
'body', #死亡者にしか割り当てられないため、除外
'boat']) #生存者にしか割り当てられないため、除外
X #確認用
X = pd.get_dummies(data=X, columns=['sex',
'home.dest',
'cabin',
'ticket',
'embarked'], drop_first=True)
X[X.columns[X.columns.str.startswith('embarked')]]
# 5.データセットを学習用と検証用に分ける
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
train_size=0.75,
test_size=0.25,
random_state=42)
print(len(X_train))
print(len(y_train))
print(len(X_test))
print(len(y_test))
# 6.TPOTClassifierの設定
tpot = TPOTClassifier(scoring='f1',
generations=5,
population_size=10,
random_state=42,
verbosity=2,
config_dict=None)
tpot #確認用
# 7.学習用データセットを使った学習
tpot.fit(X_train, y_train)
# 8.検証用データセットを使った予測結果の評価
y_pred = tpot.predict(X_test)
print('f1スコア:' + str(round(f1_score(y_true=y_test, y_pred=y_pred),2)))
# 9.終了時間の設定と実行時間の測定
end_time = time.time()
elapsed_time = end_time - start
print('終了時刻:' + str(end_time))
print('経過時間:' + str(round(elapsed_time,0 )))
TPOTの設定をするTPOTClassifier関数のconfig_dictパラメータを変更することで、構成を選ぶことができます。
ここではNoneを指定しています。Noneを指定すると、’Default TPOT’が使われます。
他の構成を使うときは、以下の表のconfig_dictの設定列のとおり文字列を指定します。回帰問題ではTPOTRegressor関数のconfig_dictに構成名を指定します。
| config_dictの設定 | 使われる構成 |
| config_dict=None | Default TPOT |
| config_dict=’TPOT light’ | TPOT light |
| config_dict=’TPOT MDR’ | TPOT MDR |
| config_dict=’TPOT sparse’ | TPOT sparse |
| config_dict=’TPOT NN’ | TPOT NN |
| config_dict=’TPOT cuML’ | TPOT cuML |
プログラムそのものの説明はAppendixでします。
先ずは、構成を変えることで、予測精度や実行時間などがどのように変わるのかを、GPUの必要なTPOT cuML以外で見てみます。
ちなみに今回は、Titanicの生存者予測データセットを使っています。ただ、データ量が若干少ないので人為的に増やしています。具体的にどのように増やしたのかも合わせてAppendixで説明します。
実行結果と速度
では、Titanicの生存者予測データセットに対しconfig_dictの設定(つまり、構成)を色々変えながら、それぞれの構成の予測精度とや実行速度、メモリ使用量を計測してみました。
以下、結果です(○は成績が最も良いもの)。
| 構成 | 予測精度 (f1スコア) |
実行時間 | 最大メモリ使用量 |
| Default TPOT | 0.72 | 1,623秒 | 10,587MB |
| TPOT light | 0.69 | ○95秒 | 259MB |
| TPOT MDR | 0.76 | 8,978秒 | ○247MB |
| TPOT sparse | ○0.77 | 954秒 | 615MB |
| TPOT NN | ○0.77 | 2,026秒 | 691MB |
| TPOT cuML※2 | – | – | – |
| 【参考】TPOT light※1 | 0.77 | 669秒 | 282MB |
- ※1:generations=10, population_size=50
- ※2:GPUが必要なため割愛します
精度
精度はTPOT sparse, TPOT NNが並んで成績が良いです。
メモリ使用量
メモリ使用量が最も少ないのはTPOT MDRです。
実行時間
実行時間が一番短いのはTPOT lightですが、その代わりに精度が5つの構成の中でもっとも低いです。ただし、TPOT lightのパラメータを変更し、generations=10、population_size=50にして実行回数を増やすと、精度が0.77まで向上しました。実行時間も669秒と、ほかの構成に比べて短いままです。これを踏まえて使用シーンをまとめると次のようになるでしょう。
Appendix :プログラムの各パートの説明
プログラムの全体像を再掲します。
1.必要なモジュールの読み込み
今回は以下のモジュールを読み込みます。
- fetch_openml … OpemML.orgという、機械学習の研究開発のためのデータや機械学習アルゴリズムの実装がされているWebサイトから、データをダウンロードするモジュールです。今回はこれを使ってTitanicの線損者予測用のデータを取得します。
- TPOTClassifier … TPOTを使って分類問題を解くためのモジュールです。
- train_test_split … データセットを学習用と検証用に分けるためのモジュールです。
- f1_score … 分類結果を評価するF値を算出するためのモジュールです。
- pandas …データサイエンスでデータを処理するためによく使われるモジュールです。
- time … 実行時間を計測するためのモジュールです。
以下、コードです。
# 1.必要なモジュールの読み込み from sklearn.datasets import fetch_openml from tpot import TPOTClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import f1_score import pandas as pd import time
2.開始時間の設定(実行時間測定用)
今回は構成間の比較をするために、実行時間を計測しておきます。
timeモジュールのtime関数で現在の時刻をUNIX時間(エポック秒)として取得します。単位は秒です。
変数startに現在の時刻を格納します。print文で出力することで、取得したUNIX時間を確認できます。
以下、コードです。
# 2.開始時間の設定(実行時間測定用) start = time.time() print(start)
以下、実行結果です。

協定世界時(UTC)の1970年1月1日午前0時0分秒から1619690239.054206秒経過していることがわかります。
プログラムの最後にもう一度UNIX時間を取得し、この値を差し引くことで実行時間を取得することができます。
3.データセットの読み込み
OpenMLからTitanicの生存者予測用のデータを読み込みます。
以下、コードです。
# 3.データセットの読み込み titanic = fetch_openml(data_id=40945, as_frame=True) X = titanic.data y = titanic.target
Xに特徴量を格納し、yに目的変数を格納しています。
データの中身を確認してみましょう。
先ずは、特徴量Xです。以下、コードです。
X
以下、実行結果です。
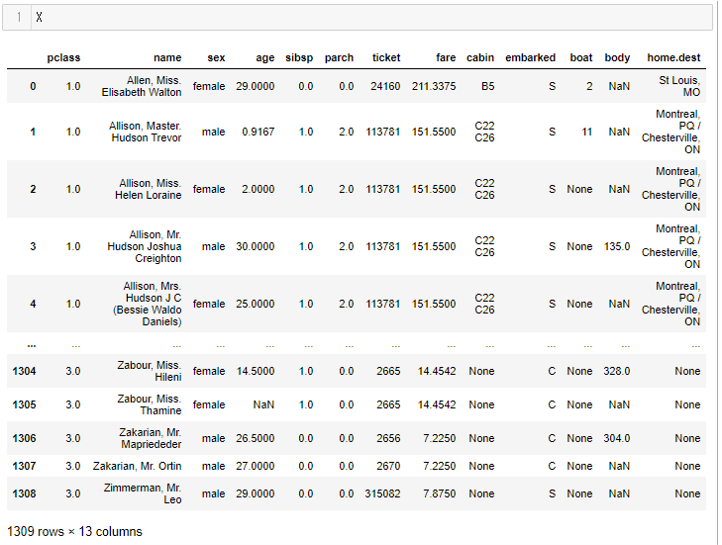
13個の特徴量が存在し、1,309行のレコードがあることがわかります。また、数値で格納されているものもあれば、文字列で格納されているものもあることがわかります。
データセット(Titanic)の生存者予測データセットの中身は次の通りです。
| 列名 | 内容 | データの説明 |
| pclass | 乗客の階級を示します。 | 文字列。1=上級, 2=中級 3=下級 |
| name | 乗客の名前です。 | 文字列。 |
| sex | 乗客の性別です。 | 文字列。male=男性、female=女性 |
| age | 乗客の年齢です。 | 数値。1歳未満の子供は小数で示されます。年齢が推定値の場合、xx.5の形式で記載されています。 |
| sibsp | 乗船している、乗客の兄弟もしくは配偶者の数です。 | 数値。 |
| parch | 乗船している、乗客の両親もしくは子供の数です。 | 数値。 |
| ticket | チケット番号 | 文字列として読み込まれます。 |
| fare | 運賃 | 数値。 |
| cabin | 客室番号 | 文字列。 |
| embarked | 出港地 | 文字列。 |
| boat | 生存した場合の、割り当てられた救命ボートの番号。今回は予測から除外します。 | 文字列。 |
| body | 死亡した場合の、身体識別番号。今回は予測から除外します。 | 文字列。 |
| home.dest | 出身地 | 文字列 |
次に、目的変数yの中身も確認してみましょう。以下、コードです。
y
以下、実行結果です。
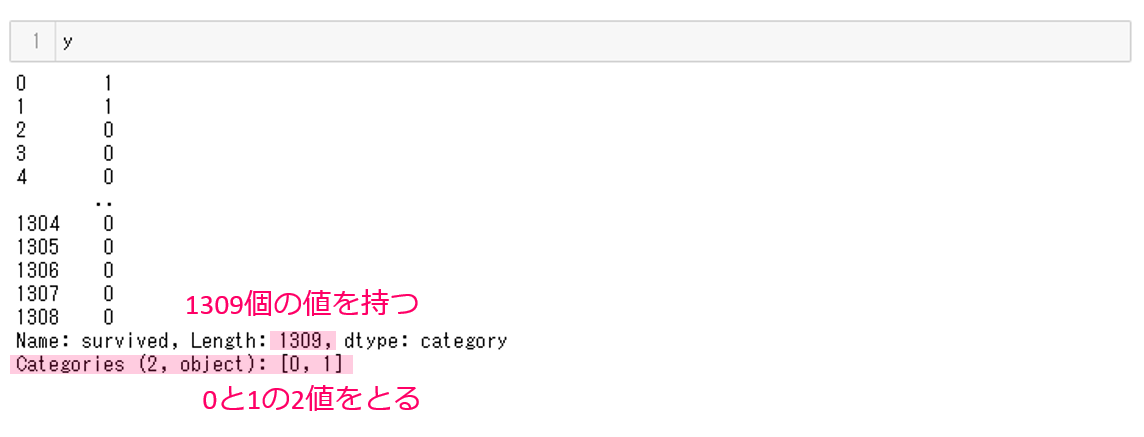
1309個の値が格納されており、0と1の2値をとることがわかります。
4.データセットの前処理
TPOTは数値の特徴量しか取り扱うことができないので、名義尺度であるカテゴリ型(category)や文字列で格納されている特徴量は数値に変換しておきます。
以下の3つの前処理を実施します。
- 前処理1:目的変数yを数値型に変換
- 前処理2:特徴量Xから不要な変数を除外
- 前処理3:特徴量Xの文字列をダミー変数に変換
前処理1:目的変数yを数値型に変換
先ず、yが名義尺度であるカテゴリ型(category)で格納されていますので、数値に変換します。
以下、コードです。
# 4.データセットの前処理
y = y.astype('float64')
y
astype関数は引数のデータ型に変換してくれる関数です。カテゴリ型(category)であるyを、float64型(倍精度浮動小数点型という数値型の1つ)に変換しています。
2行目では変換後のyの中身を表示しています。
以下、実行結果です。
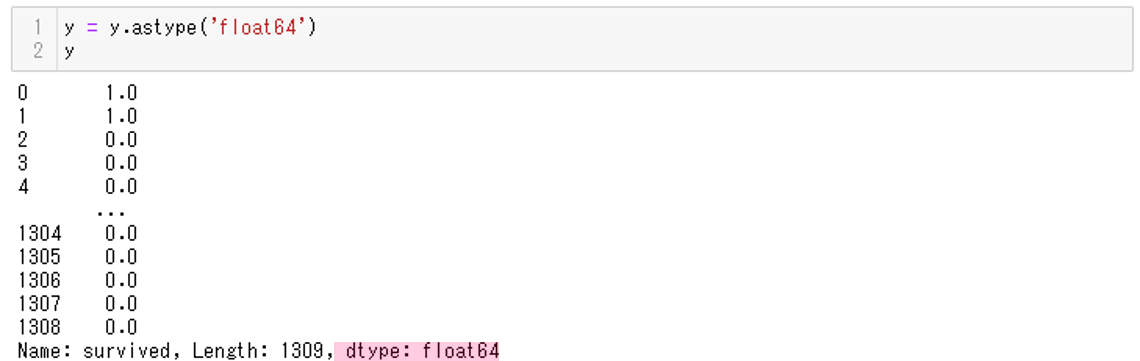
yのdtype(データ型)がfloat64なので、数値型に変換されたことがわかります。
前処理2:特徴量Xから不要な変数を除外
次に、Xを数値に変換していきます。
Xの中にいくつか間接的に予測の答え(目的変数y)を示すデータが格納されているので、そのような変数を除外します。
例えば、身体識別番号bodyは死亡者にしか割り当てられないため、これを見るだけで死亡を推定できてしまいます。
同様に救命ボートboatは生存者にしか割り当てられないため、これを見るだけで生存を推定できてしまいます。
予測問題としてはふさわしくないので、この2つbodyとboatを除外します。
また、nameは乗客それぞれに固有ですので、こちらは予測にまったく役に立ちません。
したがって、次の3つの変数をXから除外します。
- body
- boat
- name
drop関数のcolumnsパラメータに列名を渡すことで、Xから除外できます。
以下、コードです。
X = X.drop(columns=['name',
'body', #死亡者にしか割り当てられないため、除外
'boat']) #生存者にしか割り当てられないため、除外
X
以下、実行結果です。
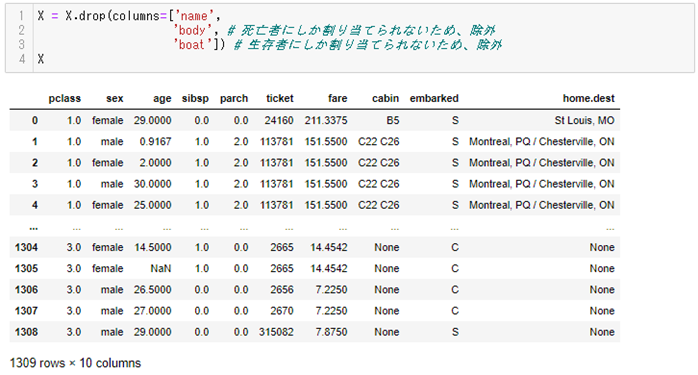
name, body, boat列が除外されていることがわかります。
前処理3:特徴量Xの文字列をダミー変数に変換
次に、pandasのget_dummies関数を使って、文字列をダミー変数に変換します。
以下、コードです。
X = pd.get_dummies(data=X, columns=['sex',
'home.dest',
'cabin',
'ticket',
'embarked'], drop_first=True)
X[X.columns[X.columns.str.startswith('embarked')]]
drop_first=Trueを指定することで、変換前の列を削除しておくことができます。
また、最後のXで中身を表示します。そして最後の行で、例えばembarked列がどのように変換されたかを表示しています。
以下、実行結果です。
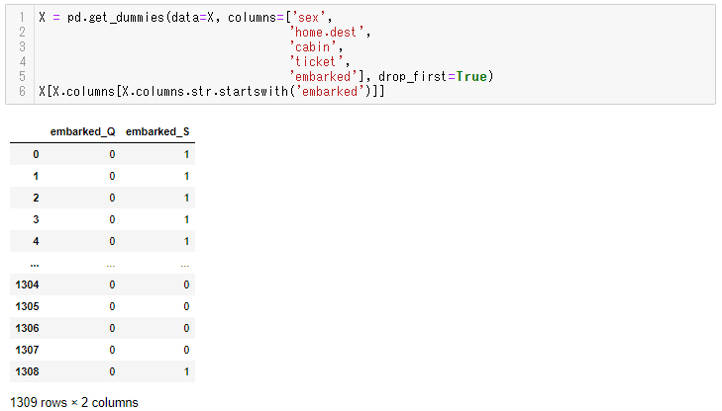
embarked列はembarked_Qとembarked_Sの2つの列に分かれて、それぞれ該当するレコードは1が格納されていることがわかります。
例えば元のレコードがembarked=Qの場合はembarked_Q列に1が格納され、embarked_Sには0が格納されます。
5.データセットを学習用と検証用に分ける
train_test_split関数で、Xとyを学習用データと検証用データに分けます。
以下、コードです。
# 5.データセットを学習用と検証用に分ける
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
train_size=0.75,
test_size=0.25,
random_state=42)
print(len(X_train))
print(len(y_train))
print(len(X_test))
print(len(y_test))
print文でそれぞれどれぐらいの行数に分かれたか表示します。
以下、実行結果です。
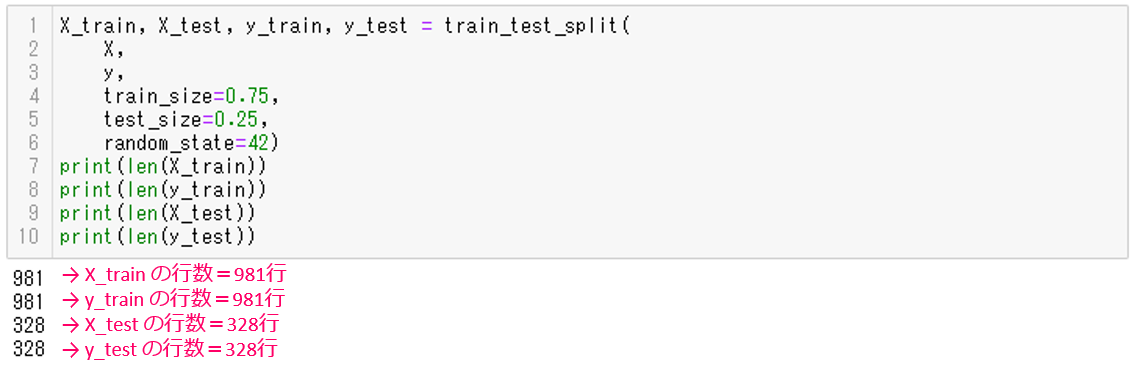
学習用データは981行、検証用データは328行なので、約75%と約25%に分かれたことがわかります。
6.TPOTClassifierの設定
TPOTClassifierの設定をします。
今回使う構成はTPOT lightです。構成を変えるときは、変えてみましょう。
以下、コードです。
# 6.TPOTClassifierの設定
tpot = TPOTClassifier(scoring='f1',
generations=5,
population_size=10,
random_state=42,
verbosity=2,
config_dict=None)
tpot
最後の行のtpotコマンドで、設定内容を表示できます。
以下、実行結果です。
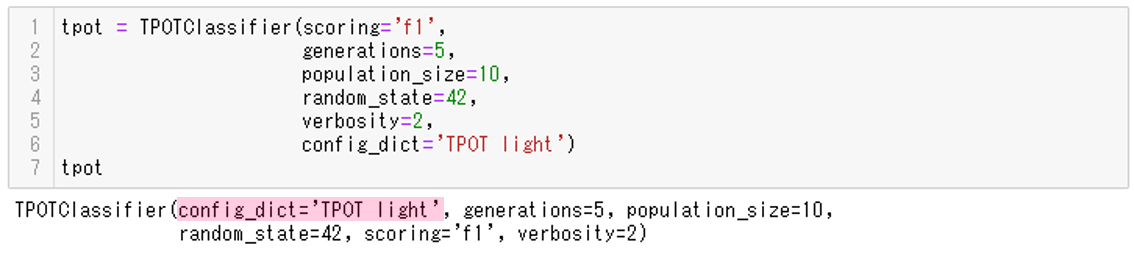
7.学習用データセットを使った学習
学習用データセットで学習します。
以下、コードです。
# 7.学習用データセットを使った学習 tpot.fit(X_train, y_train)
実行結果です。
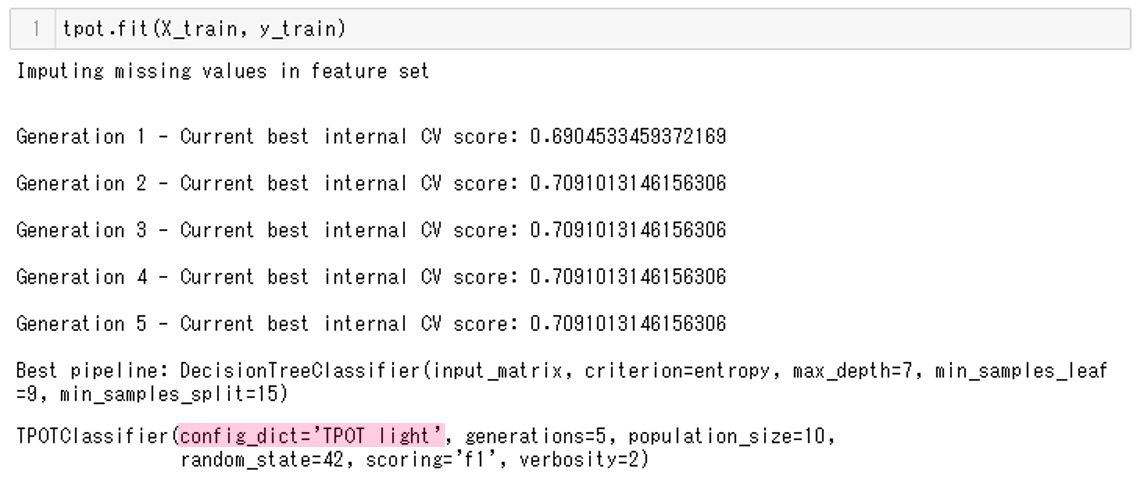
ここでも構成として’TPOT light’が使われていることがわかります。
8.検証用データセットを使った予測結果の評価
検証用データを使って、予測がどの程度の精度が出たかを確かめます。
以下、コードです。
# 8.検証用データセットを使った予測結果の評価
y_pred = tpot.predict(X_test)
print('f1スコア:' + str(round(f1_score(y_true=y_test, y_pred=y_pred),2)))
f1_score関数でF値を算出し、print文でF値を表示しています。
以下、実行結果です。

今回はF値が0.69であることがわかります。
9.終了時間の設定と実行時間の測定
最後に経過時間を取得します。
以下、コードです。
# 9.終了時間の設定と実行時間の測定
end_time = time.time()
elapsed_time = end_time - start
print('終了時刻:' + str(end_time))
print('経過時間:' + str(round(elapsed_time,0 )))
time関数で終了時間を取得し変数end_timeに格納します。start変数に格納した開始時間を差し引くことで実行時間を取得します。
以下、実行結果です。

経過時間は93秒だったことがわかります。
プログラムの全体像
プログラムの全体像を再度記載しておきます。
# 1.必要なモジュールの読み込み
from sklearn.datasets import fetch_openml
from tpot import TPOTClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score
import pandas as pd
import time
# 2.開始時間の設定(実行時間測定用)
start = time.time()
print(start)
# 3.データセットの読み込み
titanic = fetch_openml(data_id=40945, as_frame=True)
X = titanic.data
y = titanic.target
X #確認用
y #確認用
# 4.データセットの前処理
y = y.astype('float64')
y #確認用
X = X.drop(columns=['name',
'body', #死亡者にしか割り当てられないため、除外
'boat']) #生存者にしか割り当てられないため、除外
X #確認用
X = pd.get_dummies(data=X, columns=['sex',
'home.dest',
'cabin',
'ticket',
'embarked'], drop_first=True)
X[X.columns[X.columns.str.startswith('embarked')]]
# 5.データセットを学習用と検証用に分ける
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
train_size=0.75,
test_size=0.25,
random_state=42)
print(len(X_train))
print(len(y_train))
print(len(X_test))
print(len(y_test))
# 6.TPOTClassifierの設定
tpot = TPOTClassifier(scoring='f1',
generations=5,
population_size=10,
random_state=42,
verbosity=2,
config_dict=None)
tpot #確認用
# 7.学習用データセットを使った学習
tpot.fit(X_train, y_train)
# 8.検証用データセットを使った予測結果の評価
y_pred = tpot.predict(X_test)
print('f1スコア:' + str(round(f1_score(y_true=y_test, y_pred=y_pred),2)))
# 9.終了時間の設定と実行時間の測定
end_time = time.time()
elapsed_time = end_time - start
print('終了時刻:' + str(end_time))
print('経過時間:' + str(round(elapsed_time,0 )))
次回
次回は自分で構成を作る方法を説明します。